파이썬의 dictionary는 Hash Table을 이용하여 구현된 자료구조이다.
그러면 Hash Table 자료구조는 어떻게 만들어질까?
먼저 해시(Hash)에 대해 알아야한다.
해시(Hash)란?
해시는 임의의 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한 것이다.
원본 데이터를 키(Key), 매핑 하는 과정을 해싱(Hashing), 결괏값은 해시 값이라고 한다.
특징
- 고정된 길이
- 해시 값으로부터 key를 역산할 수 없음
- key가 다르면 해시 값도 달라야 함
key를 해시 값으로 매핑하기 위한 방법이 해시 함수이다.
해시 함수란?
임의의 길이를 갖는 데이터(key)에 대해 고정된 길이의 데이터(index==해시값)를 출력하는 함수
특징
- 해시 값을 고속으로 계산 가능
- 입력 데이터의 크기와 관계없이 항상 동일한 길이의 해시 값을 출력함
- 동일한 입력에 대해 항상 같은 해시 값을 출력함
해시 함수의 종류
- 나눗셈법
- key를 테이블의 크기로 나눈 나머지를 해시 값으로 사용한다.
- 곱셈법
- 키에 특정 상수 A(0 < A < 1)를 곱한 후 소수 부분을 테이블 크기를 곱해서 해시값을 생성한다.
(간단하게 2개만 알아보았지만 더 많이 있다. 더 알아보고싶다면 여기를 참조하자)
위의 해시 함수는 key가 숫자일때 함수의 입력값으로 사용가능한데 key가 문자열인 경우에는 문자를 숫자로 변환하고(ASCII) 이 숫자들을 다항식의 값으로 변환하여 사용하는 ‘문자열 해싱’을 통해서 key로 지정한다.
해시 테이블이란?
: 해시 함수를 사용해서 키를 해시값으로 매핑하고 이 고유한 인덱스 주소값에 key-value를 저장하는 자료구조

hash table은 bucket 배열로 생성된다.
bucket은 인덱스 주소값 위치에 key-value가 저장되는 곳이다.
해시 함수의 목표는 배열에서 키를 균등하게 분배하는것이다. (좋은 해시 함수일 수록 충돌 횟수를 최소화 시킨다.)
그러나 해시 함수에서 서로 다른 입력값에 대해 해시 함수의 결괏값이 같을 수도 있는데 이것을 해시 충돌이라고 부른다.
테이블의 크기가 5 이고 해시 함수는 나눗셈 법을 이용하여 해시 충돌 예시를 들어보겠다.
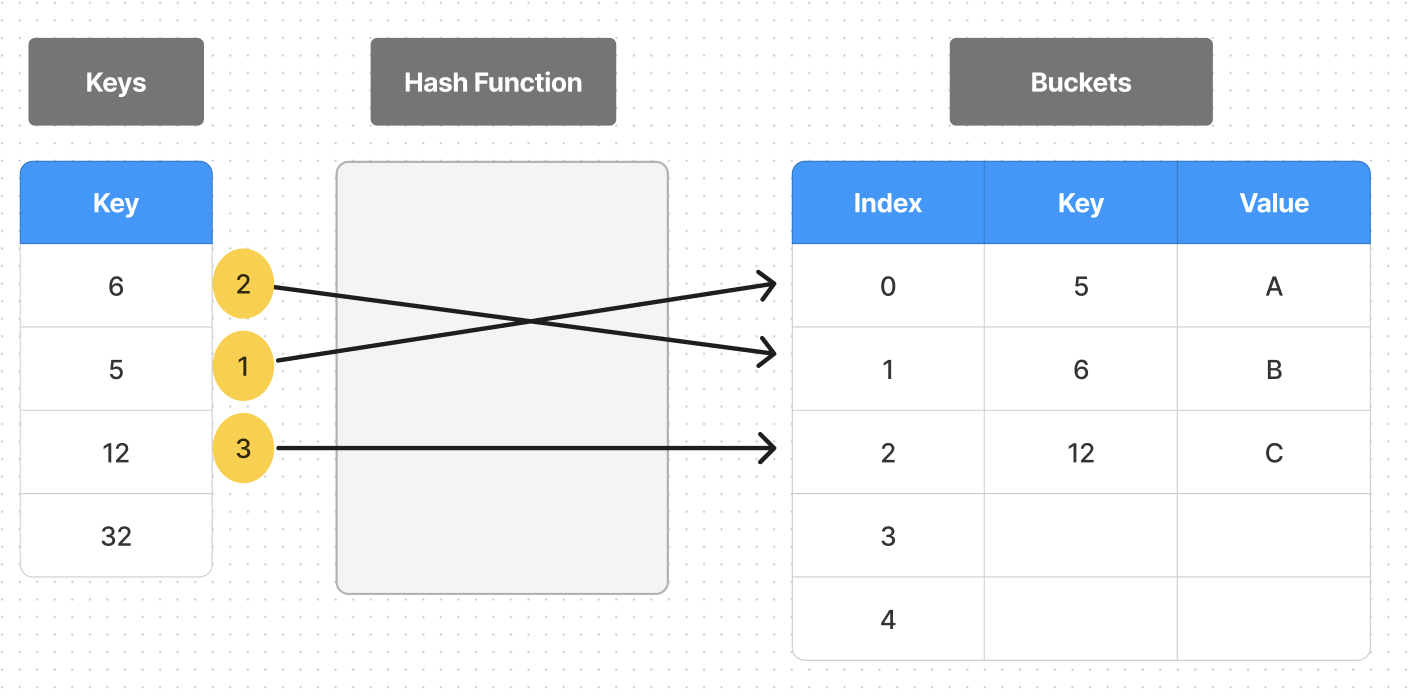
- key-value (5,A)를 저장
- key값 5는 테이블의 크기로 나눈 나머지값 (5 % 5) 0을 인덱스로 하여 A를 저장한다.
- key-value (6,B)를 저장
- 위와 같은 방법으로 (6 % 5) 1을 인덱스로하여 B를 저장한다.
- key-value (12,C)를 저장
- 위와 같은 방법으로 (12 % 5) 2를 인덱스로 C를 저장한다.
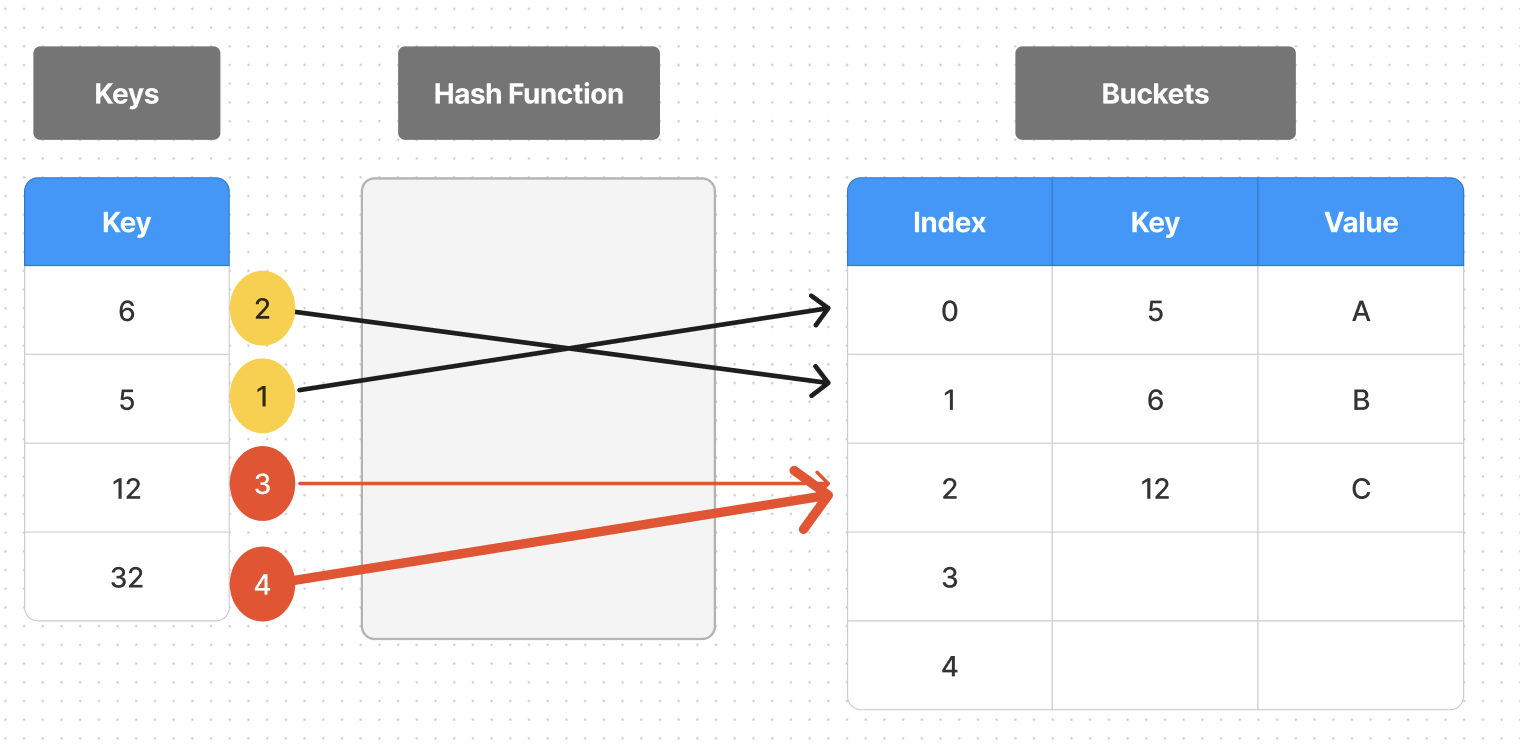
- key-value (32, D)를 저장
- 위와 같은 방법으로 인덱스를 계산하면 (32 % 5 = 2) 3번과 인덱스가 겹친다.
→ 두 개 이상의 키가 동일한 인덱스에 매핑되어 해시 충돌이 일어나는 문제가 있다.
해시 충돌 해결방법
- 체이닝 (Separate Chaining)

한 bucket에 들어갈 수 있는 엔트리 수에 제한을 두지 않는 방법으로 충돌하는 key-value를 저장하기 위해 연결리스트 또는 다른 적합한 데이터 구조(연결리스트,트리,동적배열 등)를 이용하여 체이닝 하는 방법
- 장점
- 유연한 저장 구조 : 충돌하는 요소의 수 만큼 동적으로 조절 가능하다.
- 효율적인 삽입 및 삭제 : 새로운 값을 추가 삭제가 효율적이고 연결된 요소가 많지 않을 경우 탐색의 평균 시간 복잡도는 O(1)이다.
- 단점
- 추가 메모리 비용 : 추가적인 데이터 구조를 이용하여 해결하는 방법이다.
- 포인터 추적 : 요소가 많아지면 포인터를 따라가야 하므로 추가적인 시간이 필요해진다.
( linked list의 단점을 생각해보면 된다. ) - 캐시 성능 : 데이터가 메모리 전체에 분산되어있어 상대적으로 캐시 성능이 떨어질 수 있다.
- 개방 주소법 (Open Addressing)
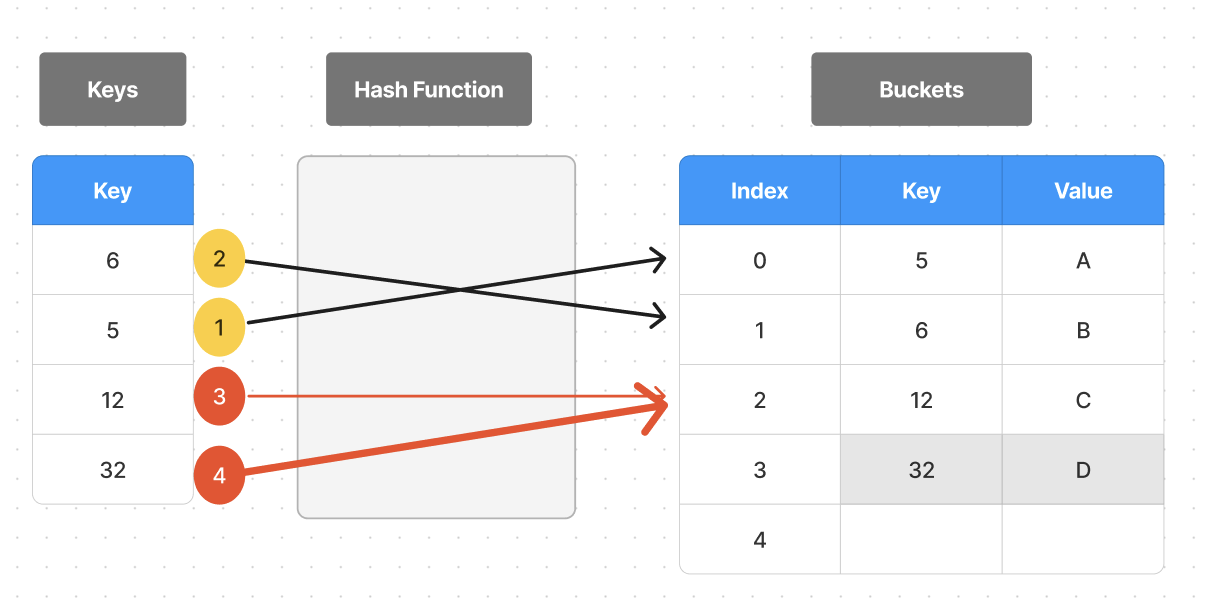
한 bucket에 들어갈 수 있는 엔트리가 하나뿐인 방법으로 해시 태이블 배열의 빈 공간을 사용하는 방법
선형 탐색, 2차 탐색, 이중 해싱 등 다양한 방법이 있다.
선형 탐색은 해당 충돌 인덱스부터 사용되지 않는 곳을 찾을 때 까지 순차적으로 내려가며 탐색한다. (그림 예시)
- 장점
- 메모리 사용 효율성 : 추가적인 데이터 구조가 필요하지 않다.
- 캐시 성능 : 모든 데이터가 동일한 테이블에 저장되어 있다.
- 단점
- 테이블의 크기 제한: 테이블이 가득 차면 더 이상 요소를 추가할 수 없다.
- 클러스터링 : 해시 테이블의 특정 영역에 데이터가 집중되는 현상으로 검색, 삽입, 삭제 연산의 성능이 저하될 수 있다. 특히 새로운 데이터를 삽입할 때 연쇄적인 충돌이 발생할 수 있다.
시간 복잡도
| 연산 | 평균 | 최악 |
|---|---|---|
| 삽입 | O(1) | O(n) |
| 삭제 | O(1) | O(n) |
| 검색 | O(1) | O(n) |
해시 함수의 성능, 초기 테이블의 크기, 충돌 방법이 시간복잡도에 영향을 줄 수 있다.
해시 함수가 키를 고르게 분산시키지 못하면 충돌이 많이 나서 O(n)의 시간 복잡도를 보여준다.
느낀점
해시 함수와 해시 테이블에 대해 깊이 이해할 수 있었다.
해시 테이블에서 해시함수를 사용할 때 해시 함수를 이용해서 key-value 쌍을 관리하는데 고유한 key에 대한 index값이 충돌할 수 있는 문제가 있다. 충돌 가능성이 있지만 이를 해결하는 방법에 대해 알게되었고 각각의 장단점을 비교해 볼 수 있었다.
다음에는 파이썬의 딕셔너리는 어떤 방식으로 해시 테이블을 이용해서 구현되었는지 알아보아야겠다.
-> Python Dictionary 내부 구조 (+hashtable)
참고 자료
https://mathcenter.oxford.emory.edu/site/cs171/collisionResolution/
https://medium.com/@MakeComputerScienceGreatAgain/separate-chaining-a-hashtables-collision-resolution-technique-7d94e96393e3
https://www.algolist.net/Data_structures/Hash_table/Open_addressing
https://mangkyu.tistory.com/102
https://velog.io/@taeha7b/datastructure-hashtable
https://growth-msleeffice.tistory.com/93
