Price Suggestion for Online Second-hand Items (2021) - Liang Han
I. introduction
기존 물품 가격 예측 모델은 동일(identical) 한 제품들 혹은 유사한 제품들의 데이터를 기반으로 prediction 을 진행하였다면, 본 Paper 에서는 non-identical 하고, numerous 한 다양한 category 가 존재하는 second-hand item 들에 적합한 모델을 제안한다.
플랫폼 판매자의 편의성을 극대화 하기 위하여, Vision-based price suggestion 을 통해 image 만으로 가격 예측을 할 수 있는 것을 첫 번째 목표로 하며, 정확하게 예측하지 못하는 상황에서는 item 에 대한 detailed text description 을 추가로 받아, multimodal item retrieval module 을 진행한다.
Key word 으로는,
1. Vision-based price suggestion
2. multimodal item retrieval module
images, one-click features 받기 -> qualified images 인지 확인 -> 아니라면, user 에게 추가적인 text description 작성 요청 -> qualified image 라면, vision based 를 통해 가격 예측, 그게 아니라면 multimodal 로 가격 예측.
소비자로 부터 받는 데이터는 다음과 같다.
(a) item image
(b) one-click features (0,1)
1. whether the item is free-shipping
2. whether the item is bought from another platform
(c) text descriptions on item
-
Vision-based price suggestion module
- binary classification model ( image 로 가격 예측을 하기에 적절한 지 0,1 로 구별 )
- Regression model ( qualified image 에 대해서만 가격 예측 진행 )
- Truncate loss ( 공통 사용 )
-
Multimodal retrieval algorithm
- proposed for not-qualified images
- takes images + one-click features + complementary text features
II. Price Suggestion System

A. Data Preparation
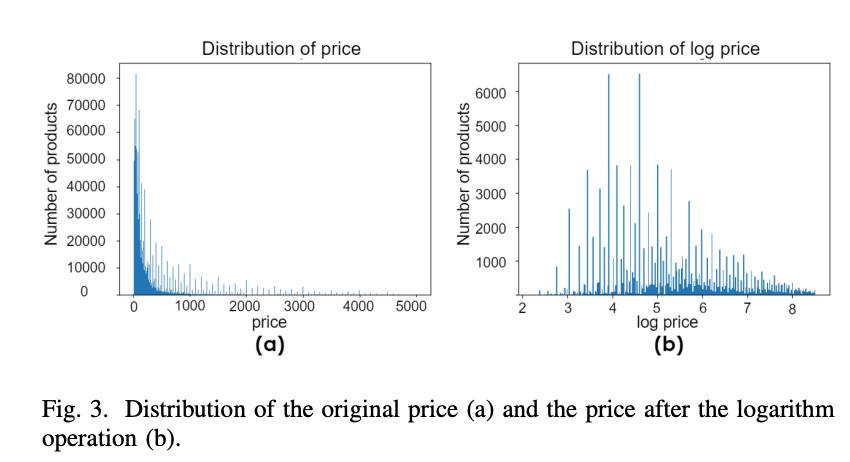
온라인 중고 물품 거래 내역 Dataset 을 모았으며, 가격 분포를 Gaussian distribution 으로 만들기 위해 (adeqtuate to train loss function), Logarithm algorithm 적용.
B. Vision-based Price Suggestion
1) Feature Extraction and Processing
pre-trained CNN model ( image 로 부터 representative feature 추출 )
feature embedding ( convert parse, categorical features -> dense real-valued vectors )
2) The Design of Vision-based Price Suggestion
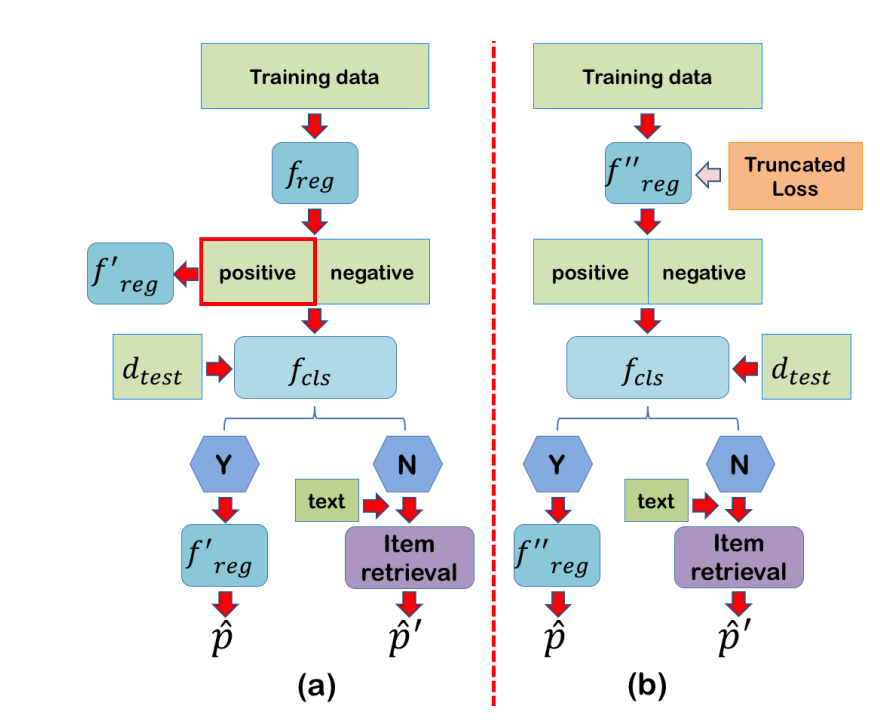
: Price prediction model
- Train 과정 : 에서 1이 나온 positive data 들로만 학습 진행
: binary classification model
- Train 과정 : 실제 판매된 가격과 예측 가격의 L2-distance 를 threshold 와 비교하여 qualified image 인지 0,1 로 구분.
Test 과정 : 새로 들어온 테스트 데이터 에 대해 을 진행하여, 1이 (qualified image) 나왔을 때에는 그대로 을 통해 가격을 예측하여 사용자에게 Return. 0 (not-qualified ) 이 나왔을 때에는 후에 나오는 multimodal 로 exta texst-description 과 함께 전달.
간단화를 위해 (각각 두 번 학습하는 것을 줄이기 위해), binart classification 을 학습하기 위한 와 , positive item 들에 대해서만 가격을 예측하는 을 하나로 통합.
- Generating training data for binary classifier + Offering price suggestion for positive itmes

=> 가 Threshold 에 의해 positive items 에 의해서만 train 되는 것을 보장
- N: The number of training samples
- : threshold ( in this expereiment, = 0.4)
- : sold price of item i
- : predicted price of item i by
는 같은 모델 구조 ( final layer 차이, Parameter 공유 x )
C. Multimodal Price Suggestion

1) Multimodal Feature Extraction
Multil-task Deep Neural Network (DNN)
: not-qualified image 로 판단된 Item 들에 대해서는 text description 을 추가로 받아서, C(Category), P(Price) 산출. 여기서 유사한 representative feature (마지막 두번째 vector '512-d') 을 가지는 items 들은 같은 카테고리 뿐만 아니라, 제품 상태도 유사한 조건.
- text : max length = 32 로, padding 과 truncating 진행하여 길이 32 고정
Word corpus from dataset, Embedding 진행 - discrete feature : free shipping (위와 동일)
- continuous features : 전체 second-hand item price 경향성에 대한 통계적 features (위와 동일)
각 4개의 input ( embedded text feature, image feature, embedded discrete features, continuous features ) 에 대해서 Fully connection operation, ReLu (비선형성 증가) , Batch Normalization (학습 가속화 및 안정화) , Dropuout (과적합 방지)

2) Item Retrieval
- Item Recall
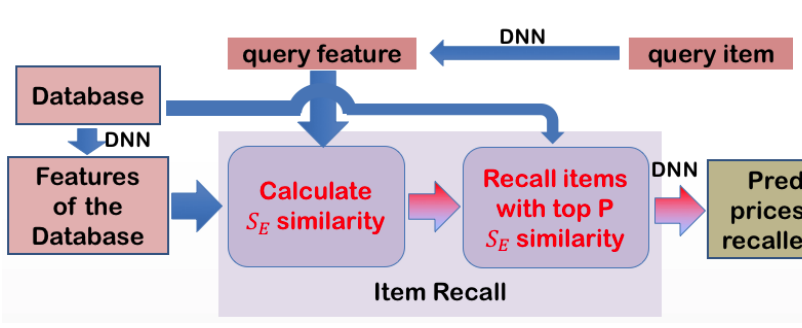
: 위 과정으로, 512-d 으로 item 의 Feature 를 추출한 후에, 유사한 item 을 데이터 베이스에서 추출 based on Euclidean distance (Similarity)
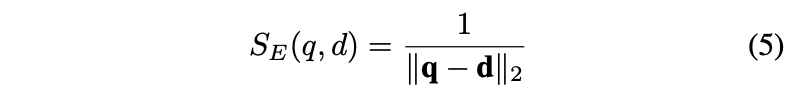
- 각각 DNN 에서 Feature 추출 (query, item from database)
- 가장 높은 유사도를 보인 P 개의 item 추출 (search space 를 줄이기 위해, 같은 category 내에서만 Search)
-
Re-ranking the recalled items
: Feature 기반으로 유사한 P 개의 item 들에 대해서 가격 유사도를 기반으로 다시 한번 더 ranking (우리는 기본적으로 유사한 feature 를 갖는 item 들이 유사한 가격을 가진다고 생각할 수 있지)
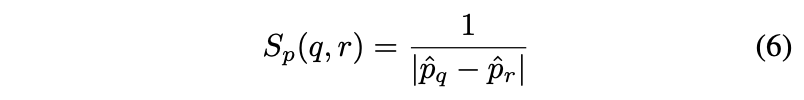
-
Kernel Regression for Price Prediction
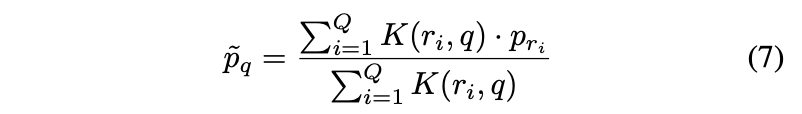
:Price Similarity 가 높은 Q 개의 Items 를 뽑아 고려하여, query item 의 최종 가격을 예측
- : 가격 유사도가 높은 Q개의 items
- : Database 의 items 들의 sold price (실제 판매된 가격)
- (In this expriments,
IV. Expriments
A. Dataset
Xianyu platform 으로 부터 13 Categories 에 대한 데이터를 받았으며, 데이터 습득할 때에는 qualified image classification 와 관계없이 image 와 text description 을 받았음.
B. Evaluation Metric
Absolute error 가 아닌, relative prediction error (Root Mean Square Log Error, Mean Absolute Log Error) 사용 (M 은 Testing data sample 개수)

C. Evaluation of Vision-based Price Suggestion (for positive items)
Baseline model : DNN-based regression model (Inputs : 1. image feature 2. discrete features 3. continuous features) [SOTA].
잠깐만 모델 구조는 똑같고, 논문 모델 : truncate loss, SOTA 모델 : mean square loss 만 다르게 한 듯? 아... 핵심은 truncate loss 였던 것인가..?

: 데이터 셋은 대략 (4,457,908 / 132,012 / 975,677 ) 로 구성이 되어 있군
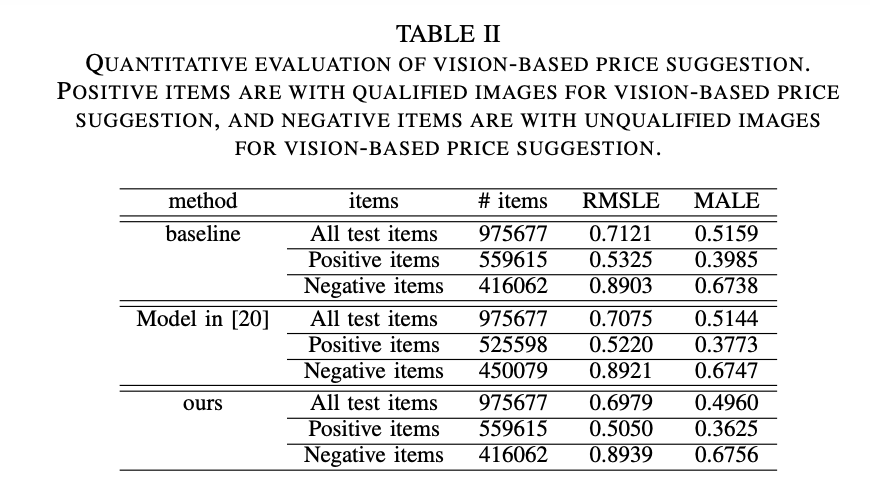
: 어쨌든, (threshold ) = 0.4 로 동일하게 실험 진행. (negative items 들에 대한 자료는 중요하지 않음)
우리 Vision based model 로 57% ( 559615 / 975677 ) 아이템을 positive item 으로 분류했고, positive item 들에 대한 vision-based regression 성능이 baseline 보다 좋았음. (RMSLE, MALE)
D. Evaluation of Multimodal Price Suggestion (for negative items)
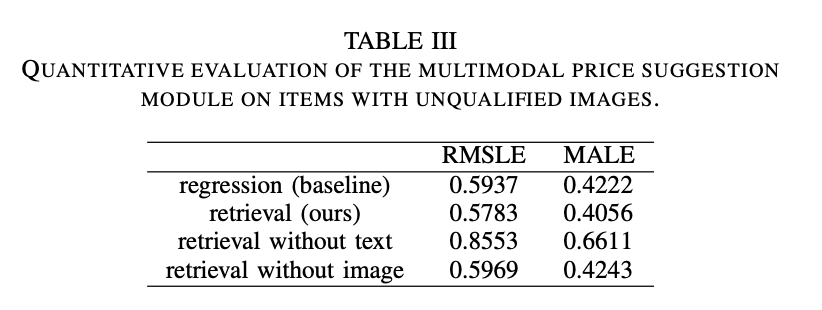
baseline model : Regression
: 일단 전반적으로 vision based regression for positive itmes 에 비해서 성능이 떨어지는 모습을 보였음 (RMSLE, MALE) 당연히, vision based regression for negative items 보다는 높고.
E. Ablation study on text and image for negative items
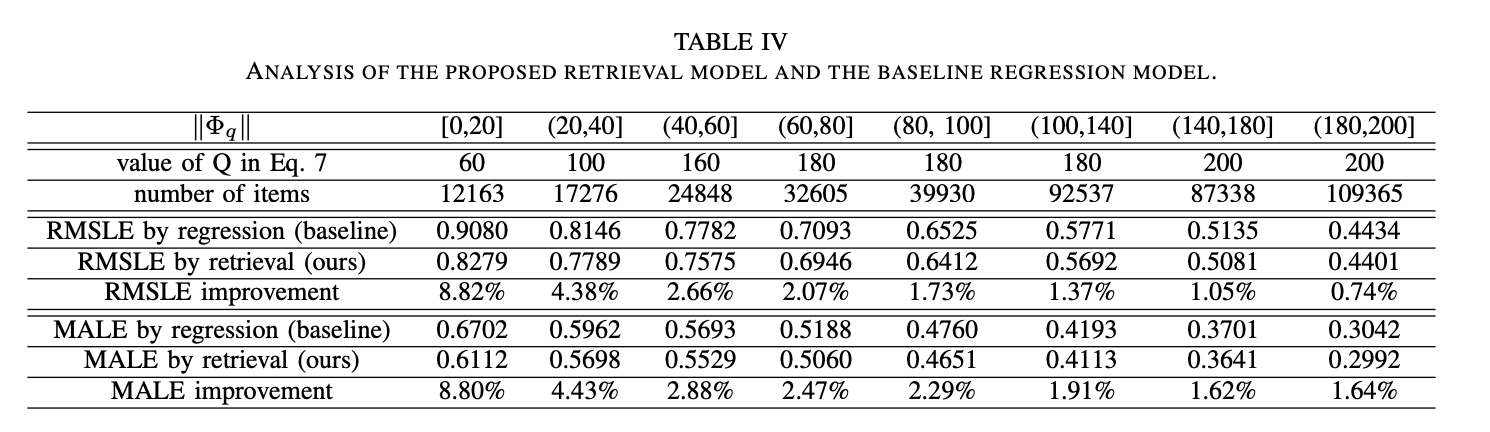
: q item 과 유사도가 10 이하인 database item 들의 개수, ( 12163 : 유사한 아이템이 10개 이하를 갖는 마이너 아이템들의 개수)
여기서 갖는 의미 : 위의 표만 봤을 때는 성능 향상이 미미한 것처럼 보이지만, 유사한 item 이 database 에 없을 때 ranking 방식이 단순 regression 보다 비약적인 성능을 보였음. 중고 장터 같이, 다양한 카테고리의 품목들이 쏟아지기 때문에 데이터 확보가 어려운 상황에서 효율적일 것으로 보임.

공감하며 읽었습니다. 좋은 글 감사드립니다.