import openai
import json
import os
import nlptutti as metrics
import csv
with open('./config.json', 'r') as f:
config = json.load(f)
openai.api_key = config['DEFAULT']['API_KEY']
predict = []
script = []
audio_folder_path = './New_Sample/source_data/TS_kor_free_01/kor_free/2022-01-22/8515'
audio_files = os.listdir(audio_folder_path)
script_folder_path = './New_Sample/labeling_data/TL_kor_free_01/2022-01-22/8515'
script_files = os.listdir(script_folder_path)
print('검증 데이터 개수 : ',len(audio_files),len(script_files))
- AI Hub 에 있는 아동 음성 데이터(576개)로 성능을 측정합니다.
#STT 결과 예측 Text를 리스트에 담기
for audio_file in audio_files:
with open(os.path.join(audio_folder_path,audio_file),'rb') as f:
transcript = openai.Audio.transcribe("whisper-1", f)
text = transcript['text']
predict.append(text)
#597개 동작시간이 너무 오래걸려서, csv 파일에 예측값 저장
with open("predict_list.csv",'w',newline='') as f:
writer = csv.writer(f)
writer.writerow(predict)
- 차례 대로, 음성 데이터 예측 text 를 저장해 줍니다. (시간이 오래 걸리니까요..)
#Json 파일에 있는 labeled Text를 리스트에 담기
for script_file in script_files:
with open(os.path.join(script_folder_path,script_file),'rb') as f:
json_obj = json.load(f)
text = json_obj['Transcription']['LabelText']
script.append(text)
#csv 파일에 있는 예측 값 불러오기
with open('predict_list.csv','r',newline='') as f:
reader = csv.reader(f)
predict=list(reader)
#List 2차원 -> 1차원 Squeeze
predict = sum(predict,[])- 저장해 두었던 예측 Text 배열과, AI Hub 에서 함께 받은 labeled real Text 를 받아옵니다.
cers = 0
wers = 0
crrs = 0
#한국어 자동 음성 인식 평가를 위한 유사도 측정 함수
for i in range(len(predict)):
refs = script[i]
preds = predict[i]
result_cer_1 = metrics.get_cer(refs, preds)
result_cer = result_cer_1['cer']
result_wer_1 = metrics.get_wer(refs, preds)
result_wer = result_wer_1['wer']
result_crr_1 = metrics.get_crr(refs, preds)
result_crr = result_crr_1['crr']
cers += result_cer
wers += result_wer
crrs += result_crr
#전체 instance 로 나누어, 평균 내주기
print('평균 CER : ',cers/len(predict), '\n평균 WER : ', wers/len(predict), '\n평균 CRR : ', crrs/len(predict))

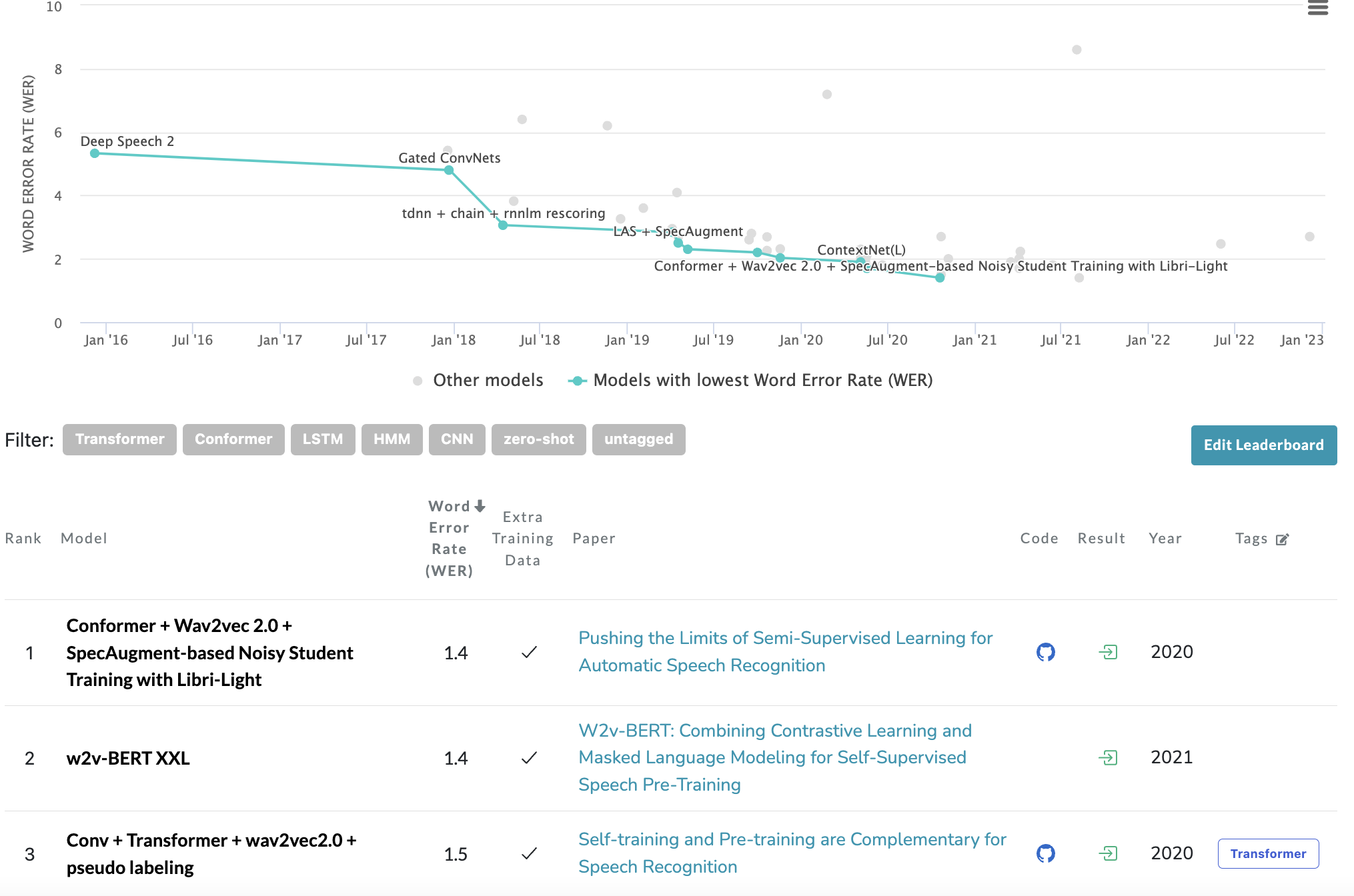
- 결과 값이 왜 SOTA 보다 높게 나올까요? ( Whisper 의 위대함인가..?)

2022.08.13~
안녕하세요! 유익한 게시물 감사합니다. 저도 동일한 데이터로 실험 진행 중인데, 혹시 처음의 "with open('./config.json', 'r') as f:
config = json.load(f)" 에서 config.json 은 어떤 파일인지 알 수 있을까요?