
모의면접으로 학습하는 CS 스터디
- 운영체제 5주차
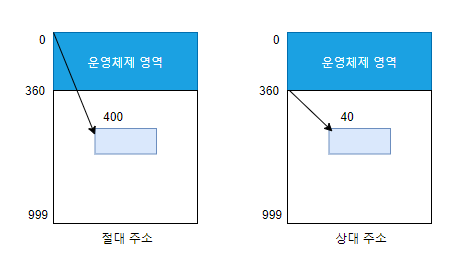
절대 주소 지정 & 상대 주소 지정
-
절대 주소
- 메모리 관리자 입장에서 바라본 주소
- 컴퓨터에 꽂힌 램 메모리의 실제 주소
-
상대 주소
- 사용자 프로세스 입장에서 바라본 주소
- 절대 주소와 관계없이 항상 0번지부터 시작
-
상대 주소 <-> 절대주소
- 절대주소 = 상대주소 + 재배치 레지스터값
- 과정
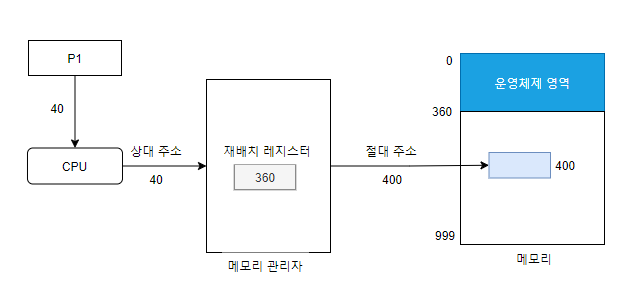
- 사용자 프로세스 상대 주소 40번지 데이터 요청
- cpu는 메모리 관리자에게 40번지 내용을 가져오라고 명령
- 메모리 관리자는 재배치 레지스터 사용
- 상대 주소 40번지 -> 400번지로 변환
- 메모리 400번지에 있는 데이터를 가져옴
메모리 분할
- 종류
- 가변 분할 방식(=세그먼테이션 메모리 관리 기법)
- 고정 분할 방식(=페이지 메모리 관리 기법)
-
가변 분할 방식
- 정의
- 프로세스 크기에 따라 메모리를 나눔
- 구현
- 한 프로세스가 메모리의 연속된 공간에 배치됨 -> 연속 메모리 할당
- 물리 메모리에서 하나의 프로세스에 해당하는 주소 공간이 연속적으로 이어짐
- 장단점
- 하나의 프로세스를 연속된 공간에 배치할 수 있음
- 메모리 관리가 복잡함
- 빈 공간의 크기가 일정하지 않음
- 특징
- 외부 단편화 발생
- 외부 단편화 : 프로세스 바깥쪽에 위치한 작은 빈 공간
- 해결 방법 : 메모리 배치 방식, 조각 모음
- 메모리 배치 방식(선처리) : 작은 조각이 발생하지 않도록 프로세스를 배치함
- 조각 모음(후처리) : 작은 조각들을 모아 큰 덩어리로 만드는 작업
- 외부 단편화 발생
- 정의
-
고정 분할 방식
- 정의
- 프로세스 크기 상관없이 메모리를 같은 크기로 나눔
- 구현
- 하나의 프로세스가 여러 개로 나뉘어 배치됨 -> 비연속 메모리 할당
- 40CB인 프로세스 A가 20KB의 프로세스 A1, 20KB 프로세스 A2로 나뉘어 배치됨
- 만약 물리 메모리가 부족하면 둘 중 하나는 스왑 영역에 있을 수도 있음
- 장단점
- 메모리 관리가 편함
- 하나의 프로세스가 여러 곳으로 나뉠 수 있음
- 정의
메모리 배치 기법
-
용도
- 가변 분할 방식의 외부 단편화 문제를 해결하기 위한 방식
- 가변 분할 방식의 외부 단편화 문제를 해결하기 위한 방식
-
종류
- 최초 배치
- 최적 배치
- 최악 배치
- 버디시스템
-
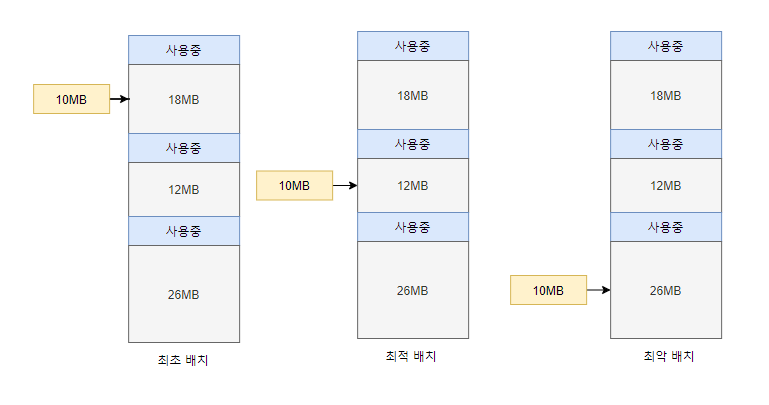
최초 배치
- 프로세스를 메모리의 빈 공간에 배치 시 메모리 적재 가능한 공간을 순서대로 찾아 첫번째로 발견한 공간에 배치하는 방법
- 단편화를 고려하지 않음
- 위의 경우 10MB 크기 프로세스는 처음 빈 공간 18MB에 배치됨
- 장점
- 빈 공간을 찾아다닐 필요가 없음
- 빈 공간을 찾아다닐 필요가 없음
-
최적 배치
- 메모리의 빈 공간을 모두 확인한 후 크기가 가장 비슷한 곳에 프로세스 배치하는 방법
- 위의 경우 10MB 크기 프로세스는 12MB에 배치됨
- 장점
- 딱 맞는 공간을 찾을 경우 단편화가 일어나지 않음
- 단점
- 공간이 없으면 아주 작은 조각을 만들어냄. 이런 공간은 버려질 가능성이 큼
- 공간이 없으면 아주 작은 조각을 만들어냄. 이런 공간은 버려질 가능성이 큼
-
최악 배치
- 빈 공간 모두 확인한 후 가장 큰 공간에 프로세스 배치
- 위의 경우 10MB 크기 프로세스는 26MB에 배치됨
- 장점
- 프로세스 배치 후 남은 공간이 커서 쓸모가 있음
- 단점
- 빈 공간 크기가 작으면 최적 배치 처럼 작은 조각을 만들어내서 효과가 떨어짐
colaescing & compaction
-
colaescing
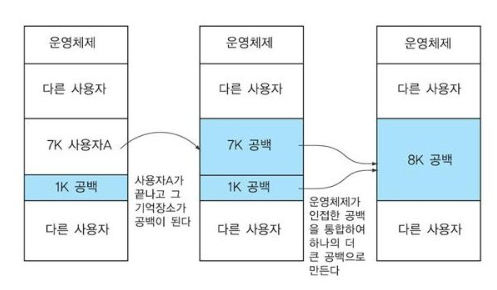
- 특정 두 프로세스 사이의 외부 단편화 현상 제거
- 프로그램 재배치 필요 없음
-
compaction
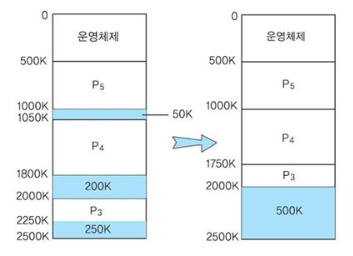
- 메모리 전체에서 외부 단편화 현상 제거
- 프로그램 재배치 필요
버디 시스템
-
정의
- 외부 단편화를 완화하는 방법
- 외부 단편화를 완화하는 방법
-
특징
- 가변 분할 방식과 고정 분할 방식의 특징을 모두 가지고 있음
- 가변 분할 방식 : 메모리가 프로세스 크기대로 나뉨
- 고정 분할 방식 :" 하나의 구역에 다른 프로세스 들어갈 수 없고, 내부 단편화 발생
- 가변 분할 방식에 비해 비슷한 크기의 덩어리가 서로 모여 있어 통합하기 쉬움
- 효율적인 공간 관리 측면에서 보면 고정 분할 방식과 버디 시스템은 비슷하나 고정 분할 방식이 단순해서 더 많이 사용됨
- 가변 분할 방식과 고정 분할 방식의 특징을 모두 가지고 있음
-
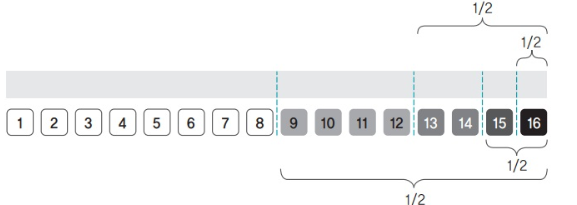
과정
- 프로세스 크기에 맞게 메모리를 1/2로 자르고 프로세스를 메모리에 배치
- 나뉜 메모리의 각 구역엔 프로세스 1개만 들어감
- 프로세스가 종료되면 주변의 빈 조각을 합쳐서 하나의 큰 덩어리를 만듦
-
예
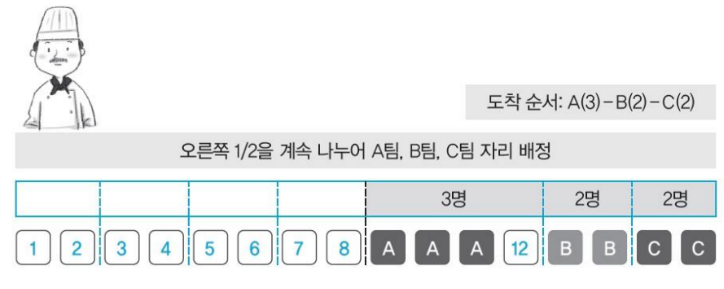

- 3명인 한 팀이 오면 의자 16개를 반으로 나눔
- 오른쪽 의자 8개를 다시 반으로 나눈 후 9~11번 의자에 앉힘
- 2명인 팀이 오면 오른쪽 의자 4개를 1/2로 나누어 B팀 2명 13~14번에 앉힘
- C팀 2명을 남은 의자 15~16번에 앉힘
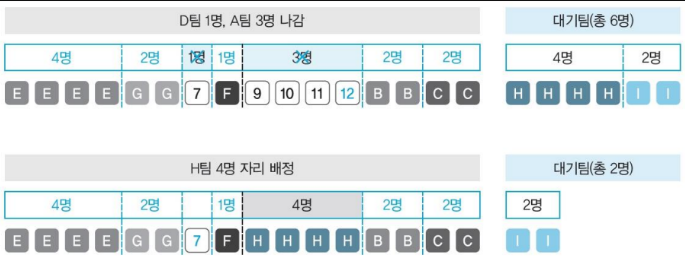
- D팀 1명의 경우 이미 오른쪽 8개에는 의자가 없음
- 12번이 비어있지만 이미 나누어진 구역이라 다른 팀이 들어갈 수 없음
- 왼쪽 의자 8개를 1/2로 나누어 7번 의자에 앉힘
- E팀 4명은 1~4번, F팀 1명 8번, G팀 2명 5~6번에 앉음
- H팀 4명, I팀 2명은 자리가 없어 대기하게 됨
- 기존 A팀 3명, D팀 1명이 나갈 경우 9~12번에 H팀 앉음
페이징
- 정의
- 프로세스를 일정 크기로 잘라 메모리에 적재하는 고정 분할 방식
- 페이지 : 프로세스의 일정 크기
- 특징
- 외부 단편화가 발생하지 않음
- 별도의 Compation 과정이 필요하지 않음
- 현대 메모리 관리는 페이징을 기본으로 함
- 단점
- 일정하게 나뉜 메모리 크기보다 작은 프로세스가 배치될 경우 낭비되는 내부 단편화 발생
- 내부 단편화가 발생할 경우 해결 방법이 없기 때문에 메모리를 어떤 크기로 나눌지 신중하게 결정해야함
- 구현
- 물리 메모리 -> 고정된 크기의 프레임으로 나눔
- 논리적 메모리 -> 동일한 크기의 페이지로 나눔
- 페이지 테이블 이용
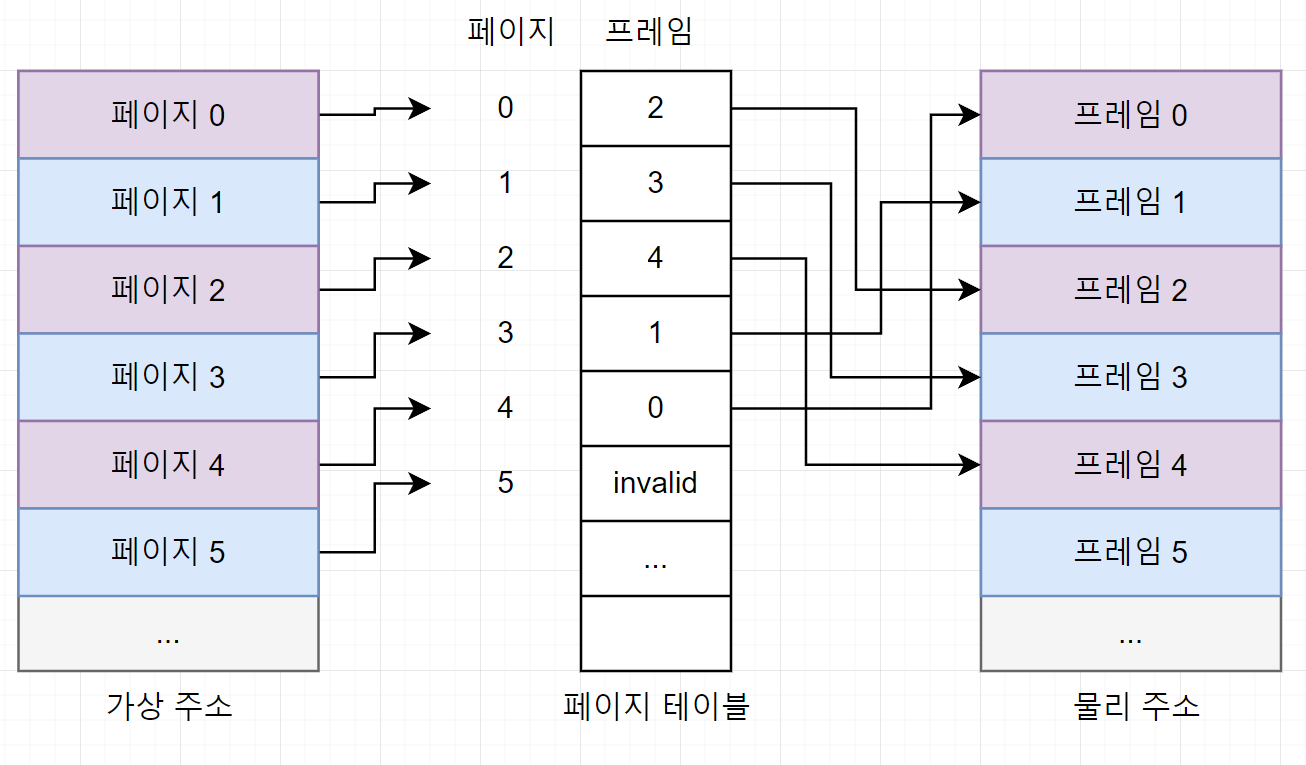
- 하나의 열로 구성
- 모든 페이지의 정보를 순서대로 가지고 있음
- 만약 페이지가 없을 경우 페이지 테이블엔 invalid로 표시됨.
- 스왑 영역에 있다는 의미
- 스왑 영역에 있다는 의미
- 주소 변환 과정
- 가장 주소 공간, 물리 주소 공간 : 10B
- 한 페이지 또는 한 프레임 : 총 10개의 주소를 가짐
- 프로세스가 30번 내용을 읽으려고 하는 경우
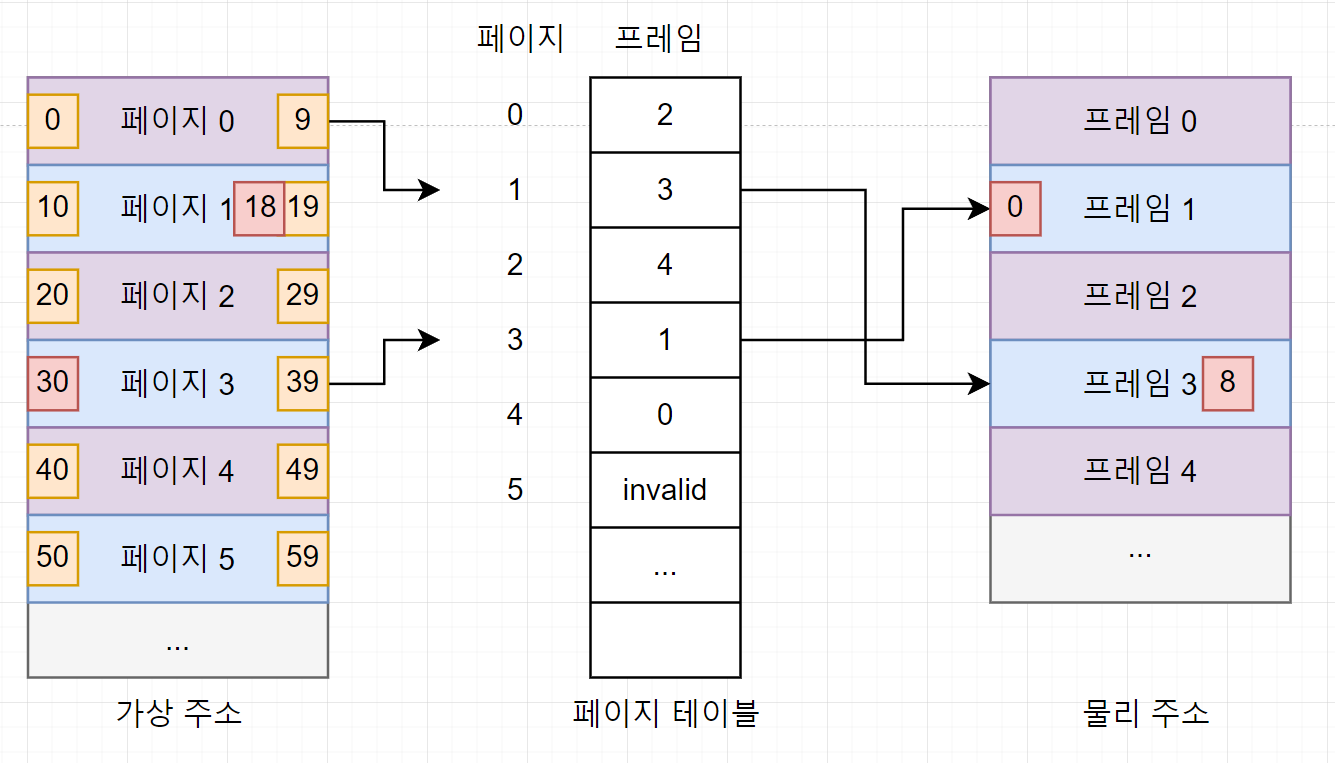
- 가상 주소 30번이 있는 페이지를 찾음
- 페이지 3의 0번 위치에 있음
- 페이지 테이블의 페이지 3으로 가서 해당 페이지가 프레임 1에 있다는 것을 알아냄
- 최종적으로 물리 메모리 프레임 1의 0번 위치에 접근
- 이 주소가 가상주소 30번의 물리 주소
- 주소 변환 정형화
- VA = <P,D> -> PA = <F,D>
- P : 페이지 D : 페이지 처음 위치 ~ 해당 주소까지의 거리
- F : 프레임
- 가상 주소 30번 : VA=<3,0>
- VA = <P,D> -> PA = <F,D>
세그멘테이션
-
정의
- 프로세스 크기에 따라 메모리를 나누는 가변 분할 방식
- 세그먼트 : 각 프로세스의 단위
-
특징
- 내부 단편화 문제가 발생하지 않음
- 메모리 효율을 개선
- 동적 분할을 통한 오버헤드 감소
- 단점
- 중간에 메모리 해제 시 외부 단편화가 발생할 수 있음
- 중간에 메모리 해제 시 외부 단편화가 발생할 수 있음
-
구현
-
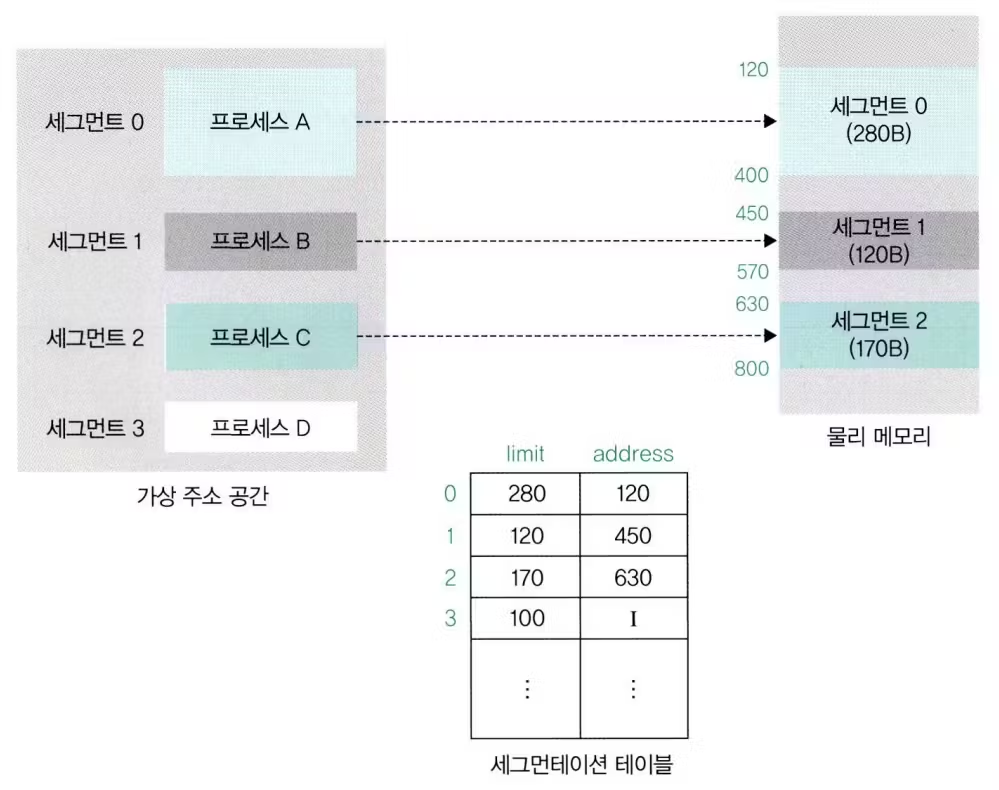
세그먼테이션 테이블 또는 세그먼테이션 매핑 테이블 사용
-
세그먼테이션 기법에선 프로세스 크기 따라 메모리를 분할하므로 크기 정보가 포함됨
-
세그먼트의 크기 정보에는 제한을 뜻하는 limit가 사용됨
-
주소 변환 과정
- 프로세스 A는 세그먼트0, 프로세스 B는 세그먼트 1, 프로세스 C는 세그먼트 2로 분할되어있음
- 프로세스 A의 32번 접근하려는 경우
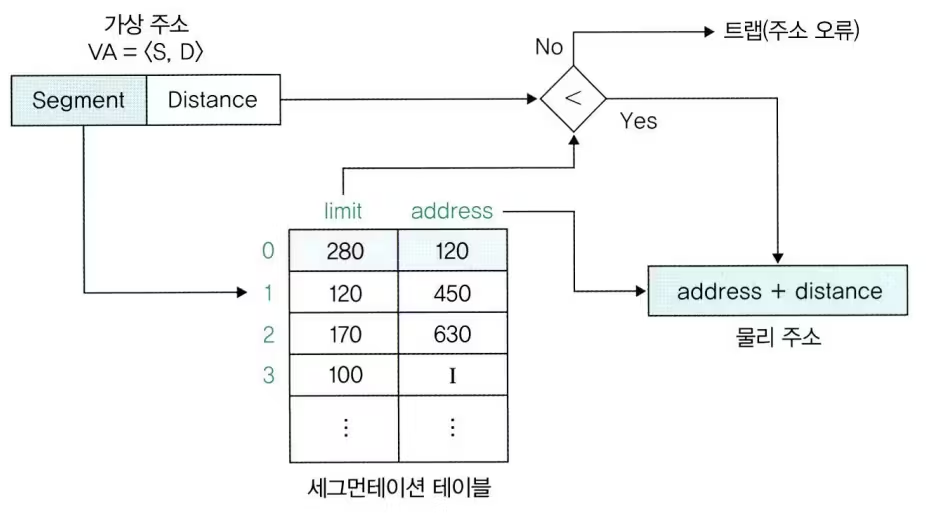
- 프로세스 A는 세그먼트 0으로 분리되었으므로 S=0, D=32임. 따라서 VA=<0,32>
- 세그먼테이션 테이블에서 세그먼트 0의 시작주소는 120을 알아냄
- 거리 32를 더해 물리 주소 152번을 구함
- 이때 메모리 관리자는 거리가 세그먼트의 크기보다 큰지 점검
- 크다면 메모리 오류 출력. -> 세그먼테이션 오류
- 물리 주소 152번에 접근
- 주소 변환 정형화
- VA = <S,D> -> PA = <F,D>
- S : 세그먼트 번호 D : 세그먼트 시작 지점 ~ 해당 주소까지의 거리
- VA = <S,D> -> PA = <F,D>
-
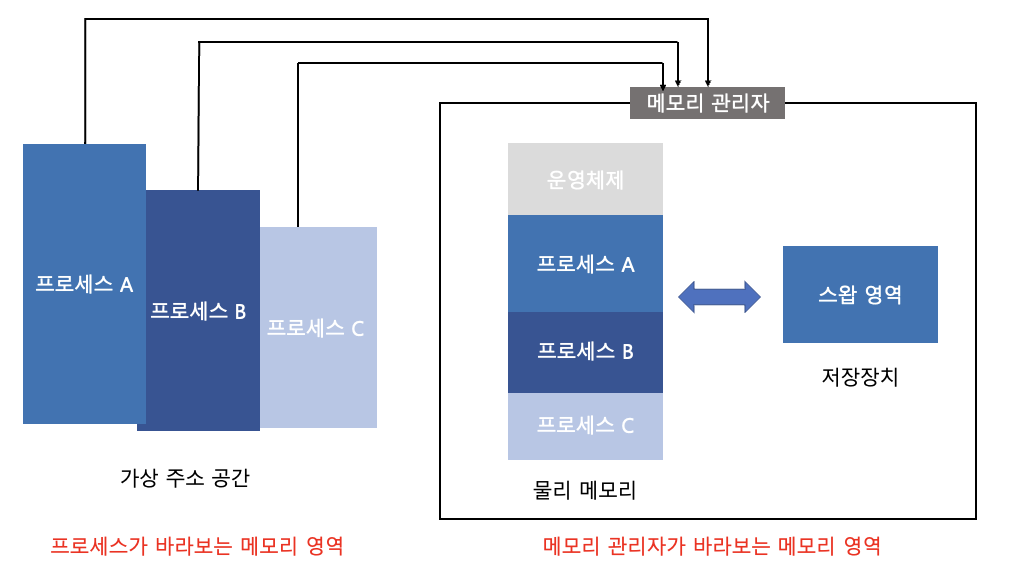
가상 메모리
- 정의
- 크기가 다른 물리 메모리에서 일관되게 프로세스를 실행할 수 있는 기술
- 물리 메모리 크기와 프로세스가 올라갈 메모리의 위치를 신경쓰지 않고 프로그래밍하도록 지원하는 시스템
- 특징
- 모든 프로세스는 0번부터 시작하는 연속된 메모리 공간을 가짐
- 가상의 주소 공간을 가짐
- 구조
- 프로세스가 바라보는 메모리 영역, 메모리관리자가 보는 메모리 영역으로 나뉨
- 이론적으로 가상 메모리크기는 무한대이나 실제 가상 메모리 최대 크기는 컴퓨터 시스템이 가진 물리 메모리의 최대 크기
- 32bit CPU의 경우 32bit로 표현할 수 있는 최대값 2^32-1. 약 4GB가 메모리의 최대 크기. 가상메모리의 최대 크기도 약 4GB
- 스왑영역을 이용해 실제 사용할 수 있는 물리 메모리의 크기를 넘어서 메모리를 사용할 수 있음
- 즉, 크기 = 물리메모리+스왑영역
- 스왑 영역
- 하드디스크에 존재하지만 메모리 관리자가 관리하는 영역.
- 가상메모리의 일부분
- 메모리관리자는 메모리의 부족한 부분을 스왑 영역으로 보충
- 물리메모리가 꽉 찼을 경우
- 스왑아웃 : 일부 프로세스를 스왑 영역으로 내보냄
- 스왑인 : 스왑 영역에 있는 프로세스 메모리로 가져옴
가상 주소 & 물리 주소
- 가상 주소
- 정의
- 프로세스가 바라보는 메모리 영역
- 특징
- 실제 위치에 관계없이 0번지부터 시작하는 연속 메모리 공간을 가짐
- 정의
- 물리주소
- 정의
- 실제 메모리 주소
- 정의
Swapping
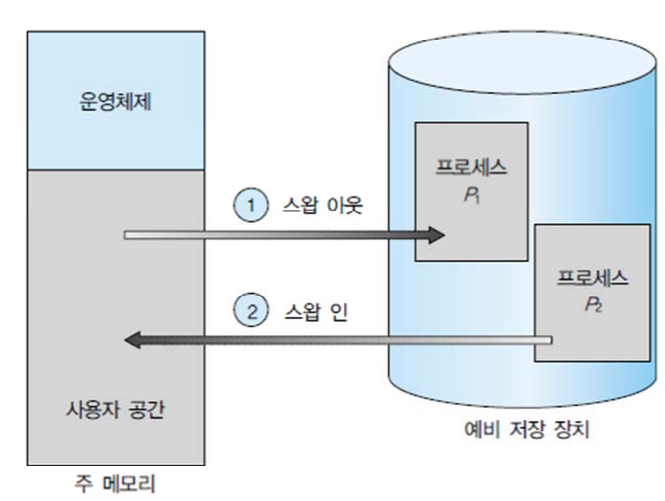
- 정의
- 현재 메모리에 올라온 프로세스를 잠시 저장공간에 옮기는 것
- 현재 메모리에 올라온 프로세스를 잠시 저장공간에 옮기는 것
- 특징
- 스왑영역 : 메모리가 모자라 쫓겨난 프로세스를 저장하는 저장장치의 특별한 공간
- 스왑인 : 스왑 영역에서 메모리로 데이터를 가져오는 작업
- 스왑아웃 : 메모리에서 스왑 영역으로 데이터를 내보내는 작업
- 스왑 영역은 메모리 관리자가 관리함
페이지 부재
-
정의
- 메모리에 적재된 페이지 중 요청한 페이지가 없는 상황
-
특징
- 페이지 테이블을 이용
- 페이지 부재가 발생했을 경우 스왑 영역에서 물리 메모리로 옮겨야함
- 메모리 관리자는 유효 비트 확인. 1이면 페이지 부재
- 빈 프레임이 없을 때는 메모리에 있는 프레임 중 하나를 내보내야함
- 이때 사용하는 알고리즘 : 페이지 교체 알고리즘
- 선택되는 페이지 : 대상 페이지
-
과정
-
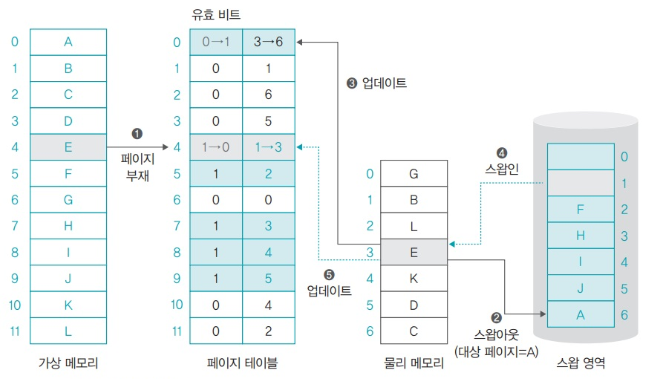
페이지 4를 요청했다고 가정
-
해당 페이지의 유효 비트 1. 페이지 부재 발생
-
메모리가 꽉 차 있으므로 메모리 페이지 중 하나를 스왑 영역으로 내보내야함
-
물리메모리 프레임 3에 저장된 페이지가 대상페이지로 선정. 스왑 영역으로 내보냄
-
대상 페이지 PTE의 유효 비트는 1, 주소 필드 값이 프레임 3에서 스왑 주소 6으로 변경
-
스왑 영역 1번에 있던 페이지 E가 프레임 3으로 올라감
-
이에 따라 PTE 4의 유효비트 1, 주소 필드 값이 스왑 주소 1에서 프레임 3으로 변경
-
FIFO 페이지 교체 알고리즘
- 정의
- 처음 메모리에 올라온 페이지를 스왑 영역으로 내보내는 방식
- 대상 페이지 : 메모리에 올라온 지 가장 오래된 페이지
- 특징
- 큐로 구현
- 메모리 맨 위에 있는 페이지가 대상페이지
- 메모리가 꽉 차면 위 페이지가 스왑 영역으로 이동
- 단점
- 지역성을 고려하면 이 방식이 옳으나 오래 되었더라도 자주 사용하는 페이지일 수 있음
- 그래서 성능이 떨어짐
- 이 문제를 개선한 알고리즘 : 2차 기회 페이지 교체 알고리즘
- 과정
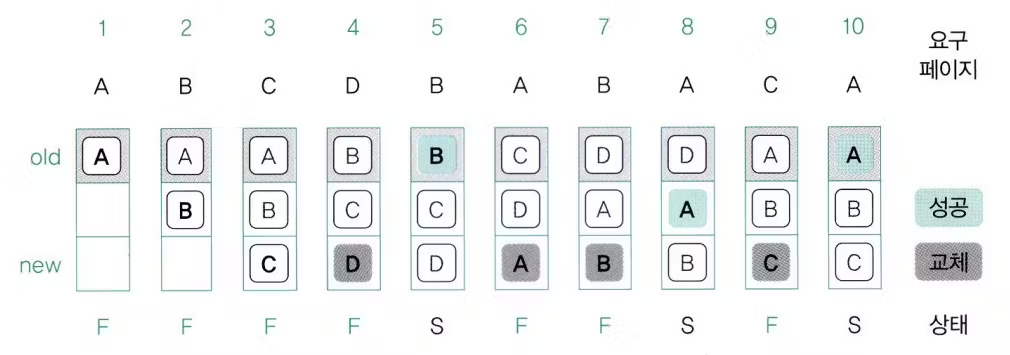
- 오래된 페이지 A 스왑 영역으로 이동
- 맨 아래 D가 남은 공간에 들어옴
- 이 순서 반복
- 결과
- 10번의 페이지 요구 중 3번 성공
- 페이지 부재 7번 발생
LRU 페이지 교체 알고리즘
-
정의
- 시간적으로 멀리 떨어진 페이지를 스왑 영역으로 내보내는 알고리즘
- 대상 페이지 : 가장 오랫동안 사용되지 않은 페이지
-
특징
- 2가지의 구현 방식 존재
- 페이지 접근 시간 기록
- 페이지 읽기, 쓰기, 실행과 같은 연산이 이루어지는 시간 기준
- 참조 비트 시프트 방식 이용
- 각 페이지에 일정 크기 참조 비트를 만듦
- 초깃값은 0, 페이지 접근할 때마다 1로 변경
- 주기적으로 오른쪽 한칸씩 이동
- 페이지 접근 시간 기록
- 일반적으로 FIFO 페이지 교체 알고리즘보다 성능이 우수함
- 페이지 접근 시간이 아닌 카운터에 기반해서 구현할 수도 있음
- 2가지의 구현 방식 존재
-
페이지 접근 시간에 기반한 경우
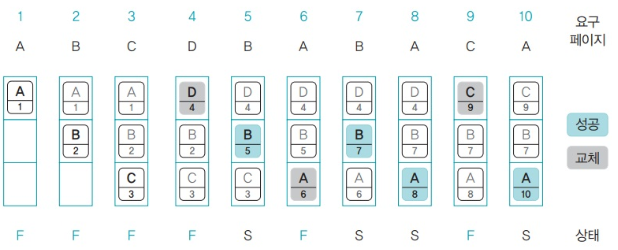
- 3번부터 설명
- 페이지 C는 3초에 메모리에 올라왔으므로 숫자가 3
- 5초에는 페이지 B가 접근했으므로 B 아래 2가 5로 변경됨
- 페이지 A를 올리기 위해 가장 오랫동안 접근하지 않았던 C를 스왑 영역으로 옮김
- 8초에 페이지 A에 접근했으므로 A아래의 6이 8로 변경됨
- 페이지 C를 올리기 위해 가장 오랫동안 접근하지 않았던 D를 스왑영역으로 옮김
- 결과적으로 페이지 성공 횟수 4번
-
참조 비트 시프트 방식을 이용한 경우
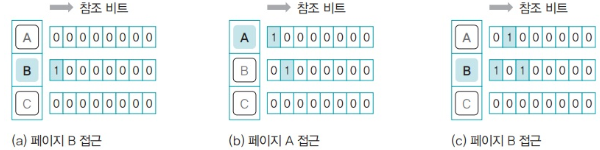
- 페이지 B에 접근하면 페이지 B의 참조 비트 맨 앞이 1됨
- 페이지 A에 접근하면 모든 참조 비트가 오른쪽으로 한 칸 이동
- 페이지 A의 맨 앞 참조 비트 1로 변경
- 페이지 B에 다시 접근. 모든 참조 비트가 오른쪽으로 한 칸 이동
- 페이지 B의 맨 앞 참조 비트가 1이 됨
- 대상 페이지 선정 시 참조 비트 중 가장 작은 값이 대상이 됨
- 위의 경우 C가 대상 페이지
LFU 페이지 교체 알고리즘
- 정의
- 페이지가 몇 번 사용되었는지를 기준으로 대상 페이지 선정하는 알고리즘
- 대상 페이지 : 페이지 횟수가 가장 적은 페이지
- 특징
- 처음 메모리에 올라온 페이지의 사용 빈도는 1
- 페이지 사용시마다 1씩 증가
- 페이지 부재 발생 시 사용 빈도가 같은 페이지가 있으면 맨 처음 페이지가 스왑 영역으로 내보내짐
- FIFO 교체 알고리즘보다 성능이 우수함
- 단점
- 낭비되는 메모리공간이 많음
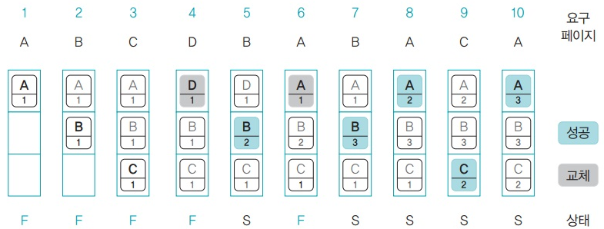
- 과정
- 5번부터 설명
- 페이지 B의 사용 빈도가 1 증가
- 6번에서 페이지 부재 발생
- 페이지 B는 대상 페이지에서 제외. 사용 빈도가 같은 페이지 C,D 중 맨 처음에 있는 D가 스왑 영역으로 보내짐
- 결과적으로 페이지 성공 횟수 5번임
클럭 알고리즘
-
정의
- 2차 기회 페이지 교체 알고리즘과 유사한 알고리즘
-
특징
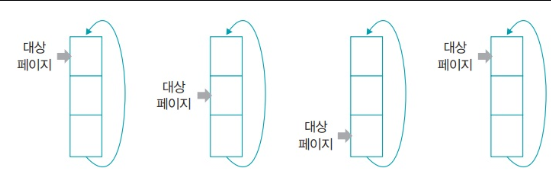
- 2차 기회 페이지 교체 알고리즘과 유사하나 클럭 알고리즘은 원형 큐 사용
- 스왑 영역으로 옮길 대상 페이지를 가리키는 포인터 사용
- 포인터가 큐 맨 아래로 내려가면 다음번에는 다시 처음을 가리키게 됨
- 단점
- 알고리즘이 복잡하고 계산량이 많음
-
과정
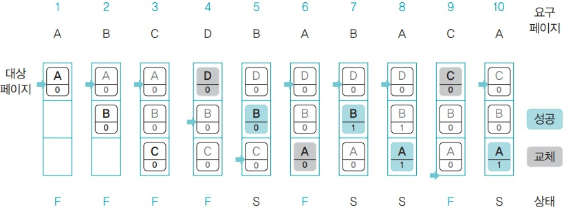
- 1번에서 페이지 A가 메모리 올라오면 대상 포인터는 A를 가리킴
- 2,3 번에서 페이지 B,C가 메모리에 올라옴
- 4번에서 대상포인터가 가리키는 페이지 A가 스왑영역으로 이동
- 페이지 D 가 메모리에 올라옴
- 대상 포인터는 한 칸 아래인 페이지B로 이동
- 5번에서 페이지 B가 페이지 참조 성공
- 페이지 B의 참조비트 1로 변경
- 대상 포인터는 참조 비트가 1인 페이지는 건너뜀
- 대상 포인터는 페이지 B의 참조비트 0으로 만든 후 한 칸 아래인 페이지 C로 이동
- 6번에서 대상 포인터가 가리키는 페이지 C가 스왑 영역으로 이동 페이지 A가 메모리에 올라옴
- 대상 포인터는 메모리 맨 위인 페이지 D로 이동
- 7,8 번에서 페이지 B와 A를 성공적으로 참조하여 참조 비트를 1로 바꿈
- 9번에서 대상 포인터가 가리키는 페이지 D가 스왑 영역으로 가고 페이지 C가 메모리에 올라옴
- 대상포인터는 밑으로 이동하는데 B,A는 참조비트가 1이므로 0으로 변경한 뒤 건너뜀
쓰레싱
-
정의
- 하드디스크의 입출력이 너무 많아 잦은 페이지 부재로 작업이 멈춘 것 같은 상태
- 하드디스크의 입출력이 너무 많아 잦은 페이지 부재로 작업이 멈춘 것 같은 상태
-
특징
-
하드디스크 입출력이 증가하면 프로그램이 정지된 것처럼 보임
-
새로운 프로그램을 메모리에 올릴려면 기존 프로그램을 스왑영역으로 옮겨야함
-
이 횟수가 잦아져서 쓰레싱이 발생하는 것
-
메모리의 크기가 일정할 경우 프로그램 수와 밀접한 관계가 있음
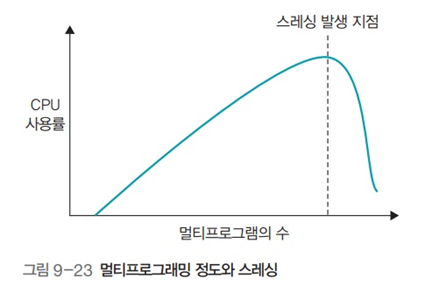
- 멀티프로그래밍 정도 : 동시에 실행하는 프로그램 수
- 멀티프로그래밍 정도가 너무 높으면 쓰레싱 발생
-
멀티프로그래밍 정도 - CPU 사용률
- 프로그램 수가 적음 -> CPU 사용량 증가
- 프로그램 수가 많음 -> CPU 작업 시간보다 스왑영역으로 보내고 메모리로 가져오는 작업이 빈번해짐 -> CPU가 작업할 수 없는 상태가 됨 -> 쓰레싱 발생
-
프레임 할당 문제와도 연관이 있음
- 여러 프로세스에게 프레임을 얼마나 자주 나눠주냐에 따라 시스템 성능이 달라짐
- 너무 적은 프레임을 할당해 페이지 부재가 빈번히 일어날 수 있음
- 또는, 너무 많은 프레임을 할당해 메모리 낭비가 발생할 수 있음
- 따라서 적당한 정책이 필요
- 동적할당
- 정적할당
-
워킹 알고리즘
-
정의
- 최근 일정시간 동안 참조된 페이지들을 집합으로 만들고, 이 집합에 있는 페이지들을 물리메모리에 유지해 프로세스의 실행을 돕는 알고리즘
- 최근 일정시간 동안 참조된 페이지들을 집합으로 만들고, 이 집합에 있는 페이지들을 물리메모리에 유지해 프로세스의 실행을 돕는 알고리즘
-
특징
-
지역성 이론을 전제로 함
- 지역성 이론 : 기억장치에 접근하는 패턴이 메모리 전체가 아니라 특정 영역에 집중되는 성질
-
가장 최근에 접근한 프레임이 이후에도 참조될 가능성이 높다는 가정이 있음
-
작업집합 크기 : 물리메모리에 유지할 페이지의 크기, 작업집합에 들어갈 최대 페이지 수
- 얼마나 자주 작업집합을 갱신할 것인지 의미함
-
작업집합 윈도우 : 작업집합에 포함되는 페이지의 범위
-
단점
- 충분한 페이지를 할당하지 않으면 작업집합에 있는 페이지를 물리 메모리에 유지하기 힘듦
- 쓰레싱을 해결하지 못함
-
-
과정
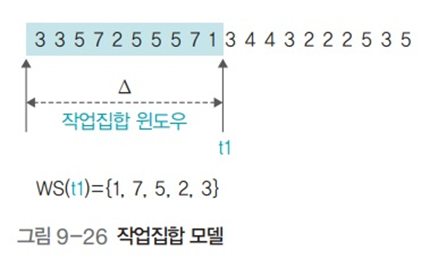
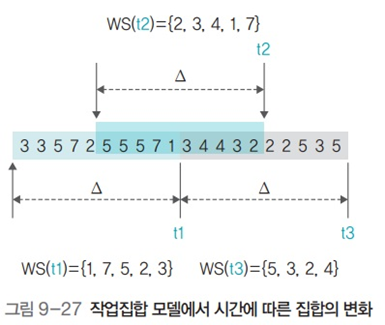
- 작업집합 크기 : 5, 작업집합 윈도우 : 10
- 첫번째 작업집합 WS(t1) = {1,7,5,2,3} 현재 시점부터 시간적으로 가까운 페이지부터 삽입됨
- 작업집합 크기가 5개이므로 t1 시점 이후 5개 페이지 접근
- t2시점 작업집합 갱신. WS(t2) = {2,3,4,1,7}. 5번페이지는 멀리 있어서 속하지 못함
- t2 시점 이후 5개 페이지 접근
- t3시점 작업집합 갱신. WS(t3) = {5,3,2,4}.
페이지 부재 빈도 알고리즘
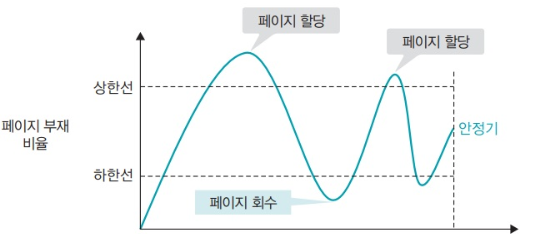
- 정의
- 페이지 부재 횟수를 기록해 페이지 부재 비율을 계산하는 알고리즘
- 특징
- 작업집합 모델의 단점을 보완하기 위해 페이지의 양을 동적으로 결정하는 부재 빈도 알고리즘 등장
- 페이지 부재 비율의 상한선, 하한선을 정함
- 상한선 초과 -> 할당한 프레임이 적음 -> 프레임 추가
- 하한선 미달 -> 메모리가 낭비됨 -> 할당한 프레임 회수
- 프로세스 실행하면서 추가적으로 페이지를 할당하거나 회수해 적정 페이지 할당량 조절
- 처음 프로세스 시작할 땐 페이지 할당량 예측하기 어려움
