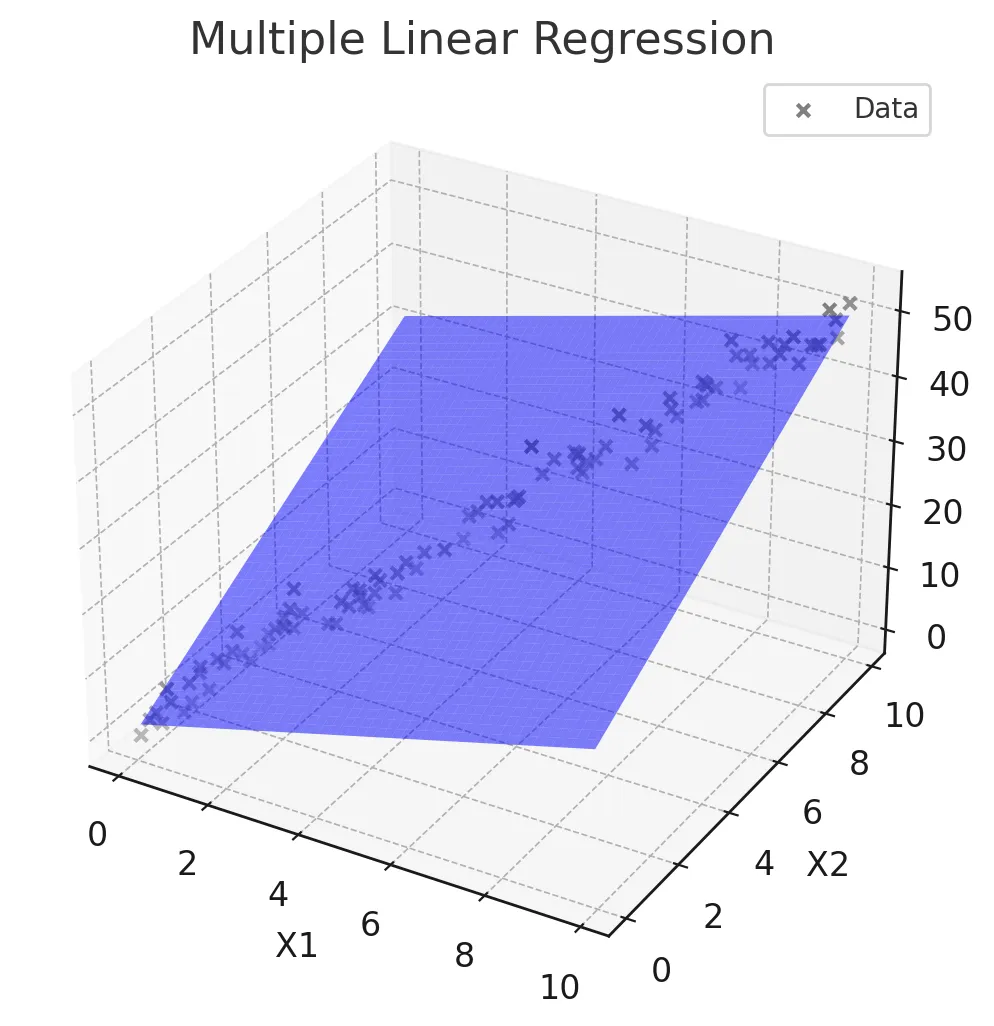
다중선형회귀
- 두 개 이상의 독립변수와 하나의 종속변수 간의 관계를 모델
회귀식
특징
- 여러 독립 변수의 변화를 고려하여 종속 변수를 설명하고 예측
- 종속 변수에 영향을 미치는 여러 독립 변수가 있을 때 사용
- 여러 변수의 영향을 동시에 분석할 수 있음
- 변수들 간의 다중공선성 문제가 발생할 수 있음
다중공선성 multicolinearity
- 회귀분석에서 독립 변수들 간에 높은 상관관계가 있는 경우
- 회귀분석 모델의 성능과 해석에여러 문제를 일으킬 수 있음
- 독립 변수들이 서로 강하게 상관되어 있으면 각 변수의 개별적인 효과를 분리하기 어려워 해석이 어려움
- 실제로 중요한 변수가 통계적으로 유의하지 않게 나타날 수 있음
진단
- 상관계수를 계산하여 상관계수가 높은 (>0.7) 변수들이 있는지 확인해볼 수 있음
- 분산팽창계수(VIF) 값이 10보다 높다면 다중공선성이 높다고 판단할 수 있음
해결방법
- 높은 상관계수를 가진 변수 중 하나를 제거하기
- 주성분분석(PCA)과 같이 변수를 효과적으로줄이는 차원분석 방법 적용
실습
# 예시 데이터 생성
data = {'TV': np.random.rand(100) * 100,
'Radio': np.random.rand(100) * 50,
'Newspaper': np.random.rand(100) * 30,
'Sales': np.random.rand(100) * 100}
df = pd.DataFrame(data)
# 독립 변수(X)와 종속 변수(Y) 설정
X = df[['TV', 'Radio', 'Newspaper']]
y = df['Sales']
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 다중선형회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 회귀 계수 및 절편 출력
print("회귀 계수:", model.coef_)
print("절편:", model.intercept_)
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("평균 제곱 오차(MSE):", mse)
print("결정 계수(R2):", r2)결과:
회귀 계수: [-0.02208636 -0.04524956 0.36955755]
절편: 47.47458066489462
평균 제곱 오차(MSE): 953.8458662397383
결정 계수(R2): -0.14044120780448188

To Dare is To Do