서브쿼리 subquerry
- SQL 내부에서 실행되는 중첩된 쿼리
- 복잡한 데이터를 단순하게 만들어주고, 중간 결과를 생성해 외부 쿼리에서 활용
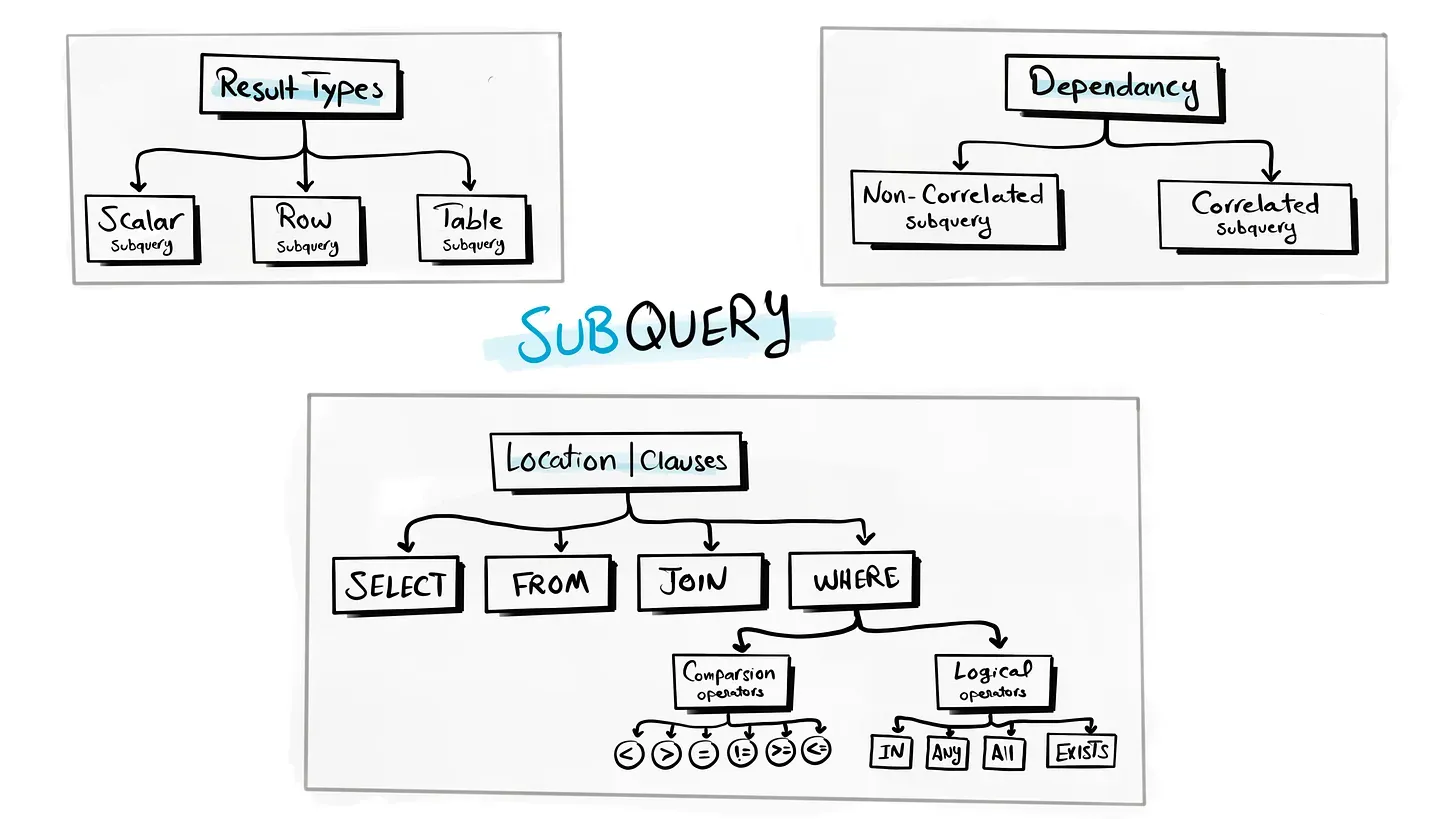
특징
- 위치: SELECT, FROM, WHERE, JOIN 등
- 독립성: 외부 쿼리와 상관 없이 독립적으로 실행될 수도, 외부를 참조하여 실행될 수도 있음 (상관-비상관)
- 실행 순서: 서브쿼리는 외부쿼리보다 먼저 실행되며, 반환된 결과는 외부 쿼리에서 사용됨.
반환 타입에 따른 분류
1. 스칼라 서브쿼리
- 스칼라 값(숫자, 문자열) 등을 반환
- 주로 SELECT, WHERE, HAVING 절에 사용
SELECT customer_id,
(SELECT MAX(payment_value) FROM payments) AS max_payment
FROM customers;2. 다중 행 서브쿼리
- 한 개의 칼럼, 여러 행 반환
- 주로 IN, ANY, ALL 등의 연산자와 함께 사용
SELECT customer_id
FROM customers
WHERE customer_id IN (
SELECT customer_id
FROM orders
WHERE order_status = 'delivered'
);3. 다중 열 서브쿼리
- 여러 열, 여러 행으로 구성된 결과 반환. 가상 테이블처럼 동작.
- FROM, JOIN에서 사용
SELECT customer_id, total_payment
FROM (
SELECT customer_id, SUM(payment_value) AS total_payment
FROM payments
GROUP BY customer_id
) AS payment_summary;위치에 따른 분류
1. SELECT 절에 사용
- SELECT 절의 서브쿼리는 단일값만을 반환하며, 외부 쿼리의 결과에 새로운 파생변수 생성
SELECT customer_id,
(SELECT COUNT(*)
FROM orders
WHERE orders.customer_id = customers.customer_id) AS order_count
FROM customers;2. FROM 절에 사용 "인라인 뷰"
- 복잡한 데이터 집합을 가상 테이블로 구조화하여 외부 쿼리에서 활용
SELECT customer_id, SUM(payment_value) AS total_payment
FROM (
SELECT customer_id, payment_value
FROM payments
WHERE payment_date >= '2023-01-01'
) AS recent_payments
GROUP BY customer_id;3. WHERE 절에 사용
- 비교 연사자 혹은 논리 연산자와 함께 특정 조건 필터링
비교 연산자
- 부등호 (>, <, >=, <=, =, !=)
SELECT customer_id
FROM customers
WHERE age > ( -- 고객의 나이가 모든 고객의 평균 나이보다 큰 경우
SELECT AVG(age)
FROM customers
);논리 연산자
- ANY: 서브쿼리 결과 중 하나라도 조건을 만족하면 참
- ALL: 서브쿼리 결과의 모든 값에 대해 조건을 만족해야 함
- IN: 서브쿼리 결과 값 중 하나와 일치하면 참
- EXISTS: 서브쿼리의 결과가 한 행이라도 존재하면 참
SELECT customer_id
FROM customers
WHERE customer_id IN ( --서브쿼리 결과값 중 하나라도 매칭되면 true
SELECT customer_id
FROM orders
WHERE order_status = 'shipped'
);
SELECT customer_id
FROM customers
WHERE age > ANY ( --서브쿼리 결과값 중 하나라도 조건을 만족하면 true
SELECT age
FROM customers
WHERE city = 'Seoul'
);
SELECT customer_id
FROM customers
WHERE age <= ALL ( -- 서브쿼리 결과값의 모든 조건을 만족해야 true
SELECT age
FROM customers
WHERE city = 'Seoul'
) AND city = 'Busan';
SELECT customer_id, name
FROM customers c
WHERE EXISTS ( -- 고객이 주문 기록이 있는 경우 참!
SELECT 1 -- SELECT * 와 동일하다는 점, 꼭 기억해주세요!
FROM orders o
WHERE o.customer_id = c.customer_id
);
-- 서브쿼리 결과가 한 행이라도 존재하면 True의존성에 따른 분류
1. 비상관 서브쿼리 Independent Subquery
- 서브쿼리가 외부 쿼리와 독립적으로 1번만 실행
- 내부 쿼리 결과가 외부 쿼리에서 사용됨
SELECT customer_id
FROM customers
WHERE age > (
SELECT AVG(age)
FROM customers
);2. 상관 서브쿼리 Correlated Subquery⚠️⚠️⚠️
- 내부 쿼리가 외부 쿼리의 데이터를 참조하며, 외부 쿼리의 각 행에 대해 반복적으로 실행
- 각 행 별로 동적으로 조건 비교 가능
상관 서브쿼리의 특징
- 외부 데이터를 참조: 내부 쿼리가 외부 쿼리의 데이터 사용
- 반복 실행: 외부 쿼리가 실행될 때마다 내부 쿼리도 반복 실행
- 성능 고려 필요: 반복 실행으로 인한 성능 저하. 이를 완화하기 위해 상관 서브쿼리를 JOIN 혹은 윈도우 함수로 변환하기도.
예시 1
-- 상관 서브쿼리의 예1
SELECT order_id, customer_id, order_amount
FROM orders o1
WHERE order_amount > (
SELECT AVG(order_amount)
FROM orders o2
WHERE o1.customer_id = o2.customer_id
);
-- 상관 서브쿼리의 예1: JOIN으로 변환
SELECT o1.order_id, o1.customer_id, o1.order_amount
FROM orders o1
JOIN (
SELECT customer_id, AVG(order_amount) AS avg_order_amount
FROM orders
GROUP BY customer_id
) avg_orders
ON o1.customer_id = avg_orders.customer_id
WHERE o1.order_amount > avg_orders.avg_order_amount;
예시 2
-- 상관 서브쿼리의 예2
SELECT customer_id,
(SELECT COUNT(*)
FROM orders
WHERE orders.customer_id = customers.customer_id) AS order_count
FROM customers;
-- 상관 서브쿼리의 예2: JOIN으로 변환
SELECT c.customer_id, COUNT(o.order_id) AS order_count
FROM customers c
LEFT JOIN orders o
ON c.customer_id = o.customer_id
GROUP BY c.customer_id;
-- 상관 서브쿼리의 예2: 윈도우 함수로 변환!
SELECT customer_id, COUNT(order_id) OVER(PARTITION BY customer_id) AS order_count
FROM orders;
To Dare is To Do