문제 1
stores 테이블은 각 매장에 대한 정보를 담고 있습니다. 테이블 구조는 다음과 같으며, STORE_NAME, REGION_NAME, SALES, EMPLOYEES, OPEN_DATE, TYPE은 각각 매장 ID, 지역 이름, 매출, 직원 수, 개점일, 매장 유형을 나타냅니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| STORE_ID | VARCHAR | 매장 ID (PK) |
| REGION_NAME | VARCHAR | 지역 이름 |
| SALES | NUMERIC | 매출 |
| EMPLOYEES | INT | 직원 수 |
| OPEN_DATE | DATE | 개점일 |
| TYPE | VARCHAR | 매장 유형 |
지역별로 매출이 가장 높은 매장의 매출을 조회하는 SQL 문을 작성해주세요.
단, 해당 지역에 매장이 두 개 이상인 경우만 결과에 포함해주세요.
결과는 지역 이름을 기준으로 오름차순으로 정렬해주세요.
풀이
- 지역별로 그룹화한다.
- 집계함수를 이용하여 가장 높은 매출을 조회한다.
- HAVING절로 조건을 걸고 정렬한다.
SELECT REGION_NAME, MAX(SALES) AS HIGHEST_SALES
FROM stores s
GROUP BY REGION_NAME
HAVING COUNT(DISTINCT STORE_ID) >= 2
ORDER BY REGION_NAME;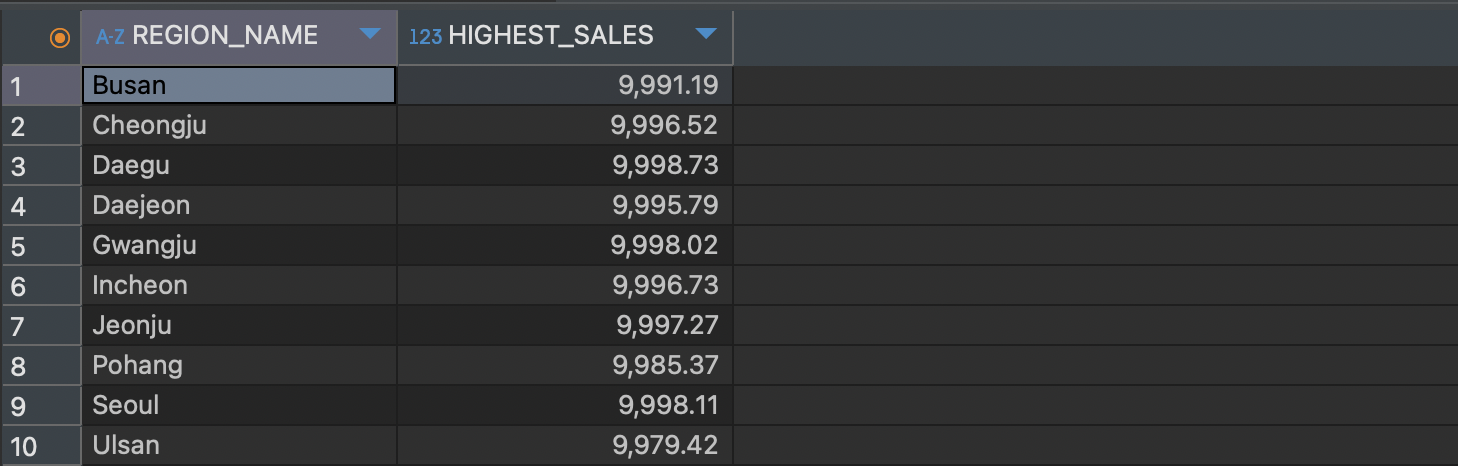
문제 2
payments 테이블은 사용자의 결제 정보를 포함합니다. 테이블 구조는 다음과 같으며, ID, USER_ID, AMOUNT, PAY_DATE, 그리고 PAYMENT_TYPE은 각각 결제 ID, 사용자 ID, 결제 금액, 결제 날짜, 결제 유형(카드, 현금 등)을 나타냅니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| ID | INT | 결제 ID (PK) |
| USER_ID | VARCHAR | 사용자 ID |
| AMOUNT | INT | 결제 금액 |
| PAY_DATE | DATETIME | 결제 날짜 |
| PAYMENT_TYPE | INT | 결제 유형(0:현금, 1:카드) |
orders 테이블은 사용자의 상품 배송 정보를 포함합니다. 테이블 구조는 다음과 같으며,
ID, USER_ID, ORDER_DATE, 그리고 ITEM은
각각 주문 ID, 사용자 ID, 주문 날짜, 주문한 상품명을 나타냅니다.
해당 테이블의 USER_ID 는 payments 테이블의 USER_ID랑 동일합니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| ID | INT | 주문 ID (PK) |
| USER_ID | VARCHAR | 사용자 ID |
| ORDER_DATE | DATETIME | 주문 날짜 |
| ITEM | VARCHAR | 주문한 상품명 |
최근 특정 사용자들이 결제를 하지 않고 상품을 주문하거나,
결제를 하지 않은 시점에 이미 상품을 주문하는 버그가 발견되었습니다. 🐞
해당 버그를 악용한 사용자를 파악하기 위해 SQL 문을 작성해주세요.
다음 조건에 해당되는 사용자 수를 출력해주세요 :
- 결제를 하지 않고 상품을 주문한 사용자
- 첫 번째 결제일보다 이전에 상품을 주문한 사용자
풀이
- 결제를 하지 않고 상품을 주문한 사용자 리스트 구하기
- 첫 번째 결제일 이전에 상품을 주문한 사용자 구하기
- 중복을 방지하기 위해 UNION 하여 집계하기
결제를 하지 않고 상품을 주문한 사용자 리스트 구하기
- orders에는 있고 payments에는 없는 USER_ID 구하기 with JOIN
SELECT DISTINCT o.USER_ID
FROM orders o LEFT JOIN payments p ON o.USER_ID = p.USER_ID
WHERE p.USER_ID IS NULL 
첫 번째 결제일 이전에 상품을 주문한 사용자 구하기
- 유저별 첫 결제 날짜 구하기
SELECT USER_ID, MIN(PAY_DATE) AS FIRST_DATE
FROM payments p
GROUP BY USER_ID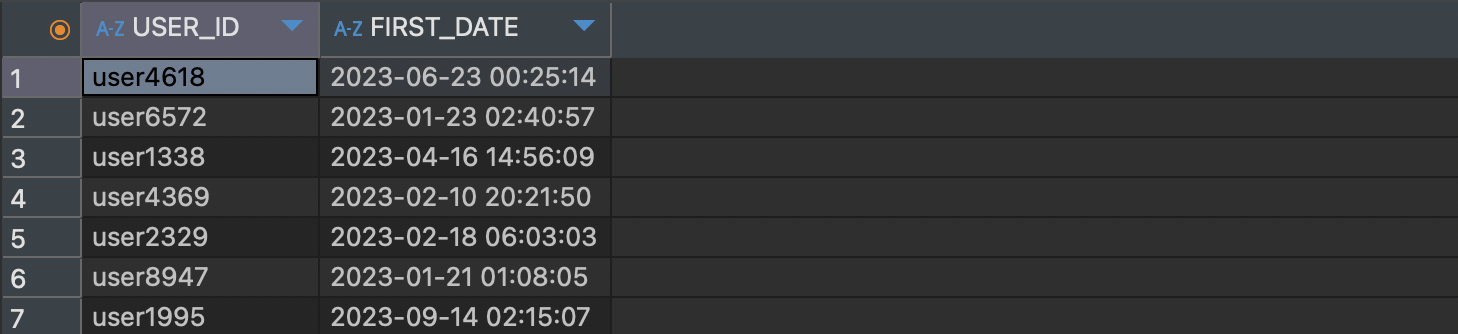
- orders 테이블과 첫 결제 날짜 테이블 조인하기
SELECT *
FROM orders o
LEFT JOIN (SELECT USER_ID, MIN(PAY_DATE) AS FIRST_DATE
FROM payments p
GROUP BY USER_ID) f
ON o.USER_ID = f.USER_ID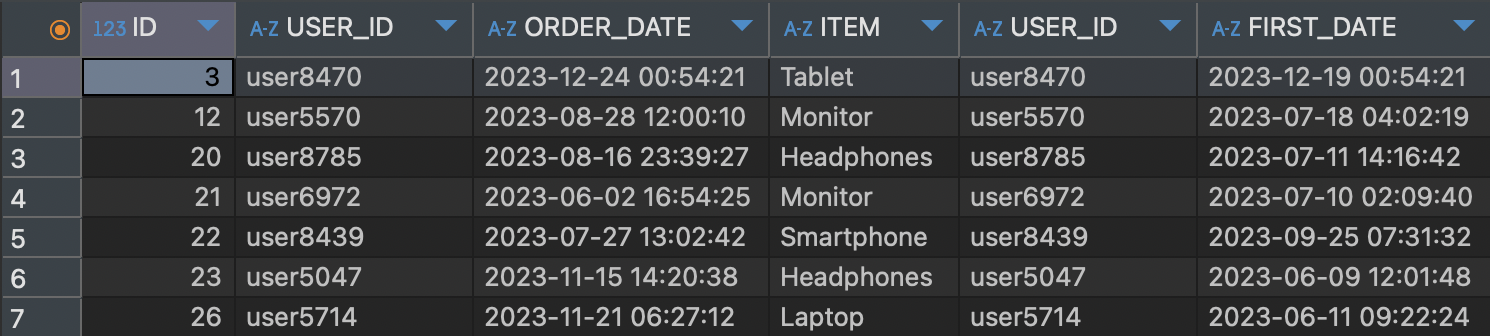
- 상품 주문 날짜가 첫 번째 결제 날짜 이전인 USER_ID 구하기
SELECT DISTINCT o.USER_ID
FROM orders o
LEFT JOIN (SELECT USER_ID, MIN(PAY_DATE) AS FIRST_DATE
FROM payments p
GROUP BY USER_ID) f
ON o.USER_ID = f.USER_ID
WHERE o.ORDER_DATE < f.FIRST_DATE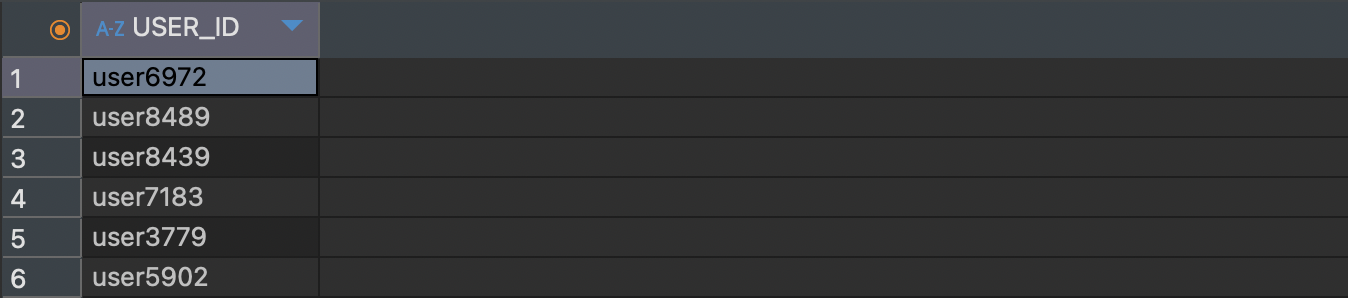
두 USER_ID 테이블을 합하여 중복 제거하고 개수 구하기
WITH cte AS ( -- UNION으로 두 테이블 중복 없이 합치기
SELECT DISTINCT o.USER_ID
FROM orders o LEFT JOIN payments p ON o.USER_ID = p.USER_ID
WHERE p.USER_ID is null
UNION
SELECT DISTINCT o.USER_ID
FROM orders o
LEFT JOIN (SELECT USER_ID, MIN(PAY_DATE) AS FIRST_DATE
FROM payments p
GROUP BY USER_ID) f
ON o.USER_ID = f.USER_ID
WHERE o.ORDER_DATE < f.FIRST_DATE
)
SELECT COUNT(DISTINCT USER_ID) AS cnt -- USER_ID 수 세기
FROM cte;
문제 3
cart_products 테이블은 쇼핑 카트에서 주문된 아이템에 대한 정보를 담고 있습니다. 테이블 구조는 다음과 같으며, ID, CART_ID, NAME, PRICE는 각각 제품 ID, 주문 번호, 제품 이름, 개별 제품 가격을 나타냅니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| ID | INT | 제품 ID |
| CART_ID | INT | 주문 번호 |
| NAME | VARCHAR | 제품 이름 |
| PRICE | INT | 제품 가격 (원) |
데이터 분석팀은 고객이 특정 상품 X를 구매했을 때 상품 Y도 함께 구매할 확률을 분석하고자 합니다.
이를 위해, 쇼핑 카트 데이터에서 서로 다른 두 제품 X와 Y가 같은 주문(CART_ID)에 포함된 주문 수를 확인하려고 합니다.
- 제품 X와 Y가 같은 주문에 포함된 경우를 계산합니다.
- 두 제품은 서로 다른 이름이어야 하며, 한 쌍의 경우(예: Coffee와 Sausages)는 다른 순서(예: Sausages와 Coffee)로도 포함됩니다.
- 결과는 각 제품 쌍과 해당 제품이 함께 포함된 주문 수를 반환해야 합니다.
- 제품 이름 X와 Y를 기준으로 알파벳 순으로 오름차순 정렬합니다.
풀이
- SELF JOIN or CROSS JOIN 등으로 CART_ID 기준 조인하기 ⭐️
- 두 제품명이 같은 경우는 제외하기
- 두 제품명 쌍을 이용하여 그룹화 후 개수 집계하기
SELECT cp.NAME AS name_x,
cp2.NAME AS name_y,
COUNT(*) AS orders
FROM cart_products cp CROSS JOIN cart_products cp2 ON cp.CART_ID = cp2.CART_ID
WHERE cp.NAME != cp2.NAME
GROUP BY cp.NAME, cp2.NAME
ORDER BY 1, 2;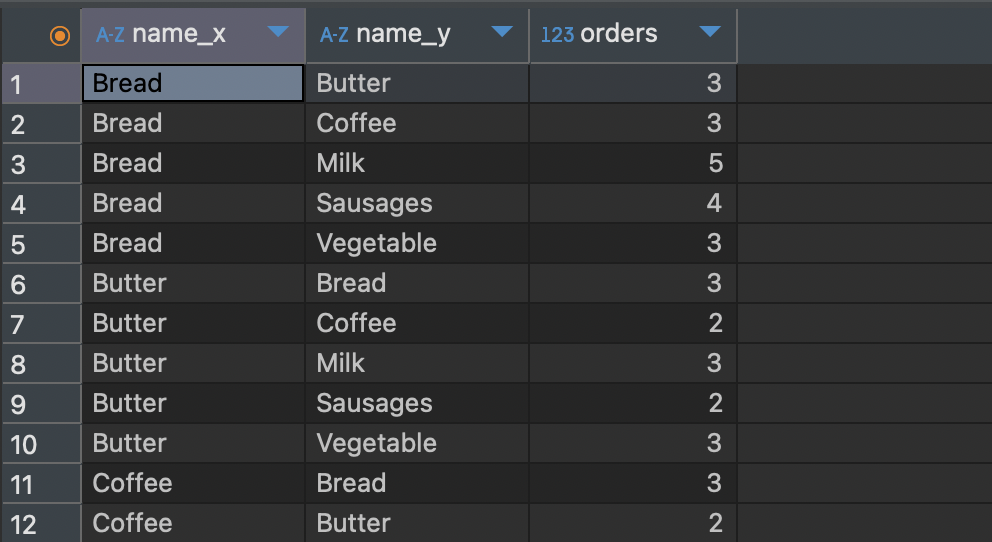
- CROSS JOIN 대신 SELF JOIN도 같은 결과.
+) 만약 중복을 제거하고 싶다면?
- WHERE절 조건을 '같지 않다 (!=)' 대신 부등호 (< or >)로 바꿔주기
SELECT cp.NAME AS name_x,
cp2.NAME AS name_y,
COUNT(*) AS orders
FROM cart_products cp CROSS JOIN cart_products cp2 ON cp.CART_ID = cp2.CART_ID
WHERE cp.NAME < cp2.NAME
GROUP BY cp.NAME, cp2.NAME
ORDER BY 1, 2;- 부등호를 이용함으로 중복 결과 중 하나만 출력할 수 있다.
