오늘 프로젝트 진행 내용
컬럼별 분포 확인
# ex) CreditScore
plt.figure(figsize=(8,6))
sns.histplot(data = df['CreditScore'], palette='Blues')
plt.title("Credit Score Distribution", fontdict={'fontsize':16})
plt.show()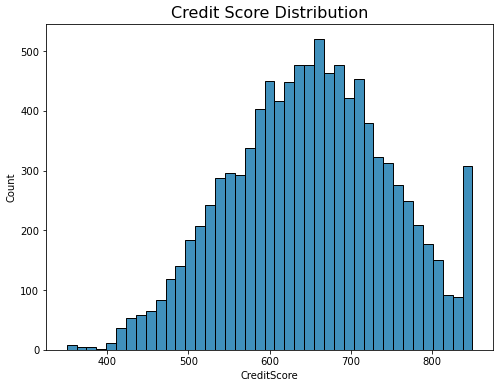
컬럼간의 관계 확인
sns.barplot(x = 'NumOfProducts', y = 'Balance', data = df)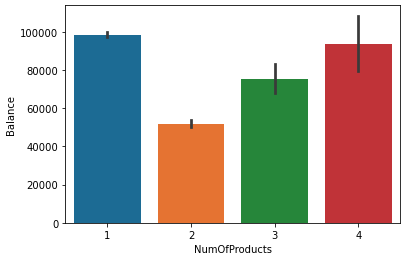
베이스모델 학습시키기
from sklearn.metrics import accuracy_score,f1_score, auc
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
model_gbm = GradientBoostingClassifier(random_state= 42)
model_xgb = XGBClassifier(random_state= 42)
model_lgb = LGBMClassifier(random_state= 42)
model_gbm.fit(X_train, y_train)
model_xgb.fit(X_train, y_train)
model_lgb.fit(X_train, y_train)
y_gbm_pred = model_gbm.predict(X_test)
y_xgb_pred = model_xgb.predict(X_test)
y_lgb_pred = model_lgb.predict(X_test)
def get_score(model_name, y_test, y_pred):
acc = round(accuracy_score(y_test, y_pred), 3)
f1 = round(f1_score(y_test,y_pred), 3)
auc = round(auc(y_test, y_pred), 3)
print(model_name, 'accuracy: ', acc, 'f1_score: ', f1, 'AUC: ', auc)
get_score('gbm', y_test, y_gbm_pred)
get_score('xgb', y_test, y_xgb_pred)
get_score('lgb', y_test, y_lgb_pred)
# gbm accuracy: 0.868 f1_score: 0.597
# xgb accuracy: 0.852 f1_score: 0.565
# lgb accuracy: 0.857 f1_score: 0.573데이터 분균형을 해결하기 위한 오버샘플링 with SMOTE
SMOTE_ins = SMOTE(k_neighbors = 5, random_state = 42)
oX_train, oy_train = SMOTE_ins.fit_resample(X_train, y_train)
oX_train = pd.DataFrame(oX_train, columns=X_train.columns)
oy_train = pd.Series(oy_train)
model_gbm = GradientBoostingClassifier(random_state= 42)
model_xgb = XGBClassifier(random_state= 42)
model_lgb = LGBMClassifier(random_state= 42)
model_gbm.fit(oX_train, oy_train)
model_xgb.fit(oX_train, oy_train)
model_lgb.fit(oX_train, oy_train)
y_gbm_pred = model_gbm.predict(X_test)
y_xgb_pred = model_xgb.predict(X_test)
y_lgb_pred = model_lgb.predict(X_test)
get_score('gbm', y_test, y_gbm_pred)
get_score('xgb', y_test, y_xgb_pred)
get_score('lgb', y_test, y_lgb_pred)
# gbm accuracy: 0.837 f1_score: 0.623
# xgb accuracy: 0.851 f1_score: 0.606
# lgb accuracy: 0.856 f1_score: 0.622회고
잘한 점
- 프로젝트 진행에 집중했다.
- 컬럼별 히스토그램+박스플랏 or 카운트플랏 시각화하였다.
개선점
- 우선순위를 잘 정해서 시간 배분 잘 하기
배운 점
- automl, autogluon 등의 툴을 이용해 모델 학습을 테스트해볼 수 있다.
- SMOTE는 단순히 기존의 마이너 데이터를 복사하는 것이 아니라 알고리즘을 이용해 비슷한 새로운 데이터를 생성한다.

To Dare is To Do