Python SQL alchemy
- SQL로 데이터를 추출하다 보면 사용자 정의 함수나 데이터 전처리가 필요한 경우가 있다.
- 파이썬에서 RDB에 접근하게 해주는 모듈이 바로 SQLAlchemy
로컬 MySQL에 연결하기
from sqlalchemy import create_engine
import pandas as pd
# 데이터베이스 접속 정보
DATABASE_TYPE = 'mysql'
DBAPI = 'pymysql'
HOST = 'localhost'
USER = 'root'
PASSWORD = 'dlawjd' # 본인 mysql 의 데이터베이스 비밀번호
DATABASE = 'sc5'
PORT = '3306'
# 데이터베이스 URI 설정 (경로 설정)
DATABASE_URI = f'{DATABASE_TYPE}+{DBAPI}://{USER}:{PASSWORD}@{HOST}:{PORT}/{DATABASE}'
engine = create_engine(DATABASE_URI)
# Connection 객체를 사용하여 쿼리 실행
query = "SELECT * FROM orders LIMIT 10"
df = pd.read_sql_query(query, engine)
# 결과 출력
display(df)AWS MySQL에 연결하기
from sqlalchemy import create_engine, text
import pandas as pd
# 데이터베이스 접속 정보
DATABASE_TYPE = 'mysql'
DBAPI = 'pymysql'
HOST = 'sparta.cbt9ceqjwlr9.ap-northeast-2.rds.amazonaws.com'
USER = 'sparta_student'
PASSWORD = 'sparta99'
DATABASE = 'sparta'
PORT = '3306'
# 데이터베이스 URI 설정
DATABASE_URI = f'{DATABASE_TYPE}+{DBAPI}://{USER}:{PASSWORD}@{HOST}:{PORT}/{DATABASE}'
engine = create_engine(DATABASE_URI)
# Connection 객체를 사용하여 쿼리 실행
query = "SELECT * FROM checkins LIMIT 10"
df = pd.read_sql_query(query, engine)
# 결과 출력
display(df)오픈 API 가져오기
API란?
Application Programming Interface
- 두 소프트웨어 구성요소가 서로 통신할 수 있도록 하는 매커니즘
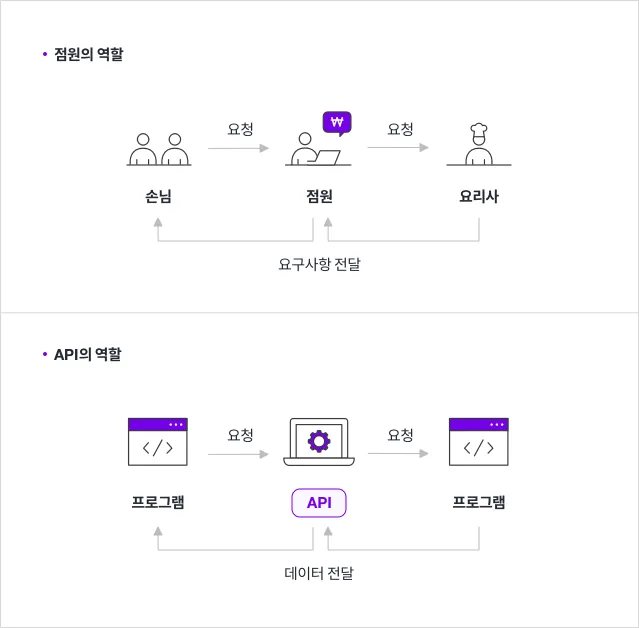
Open-API란?
- 누구나 사용할 수 있도록 공개된 API (<-> private API)
- 보통 무료.
- 일일 호출량 정해져 있음. 너무 많은 호출은 밴될 수 있음
- API 접근을 위해서는 '허락'이 필요하기 때문에 인증키를 부여받음.
- 인증키는 개인정보이기 때문에 블로그, 깃허브 등에 올리면 안 됨!
- github 연동 시 'gitignore' 파일에 추가하면 연동 막을 수 있음.
데이터 명세서 읽기
- API는 내가 원하는 정보를 서버에 요청하고 수신하여 받는 형태
데이터 요청 방법

데이터 출력 결과

- 보통 API는 XML 혹은 JSON 형태로 데이터를 전달해주기 때문에 전처리 필요.
XML
- eXtensible Markup Language
- 웹에서 데이터를 전송할 목적으로미리 약속해둔 형식으로 만들어진 언어. HTML.
- 계층 구조
- HTML: Hyper Text Markup Language로 웹페이지 구조 정의
기능 구현하기
호출하기
- Python 모듈 중 request 모듈을 사용할 예정
- 메소드( Create, Read, Update, Delete 에 상응하는)
- POST: 생성하기
- GET: 가져오기 → 데이터 수집 관점에서 일반적으로 씀.
- PUT: 수정하기
- DELETE: 삭제하기
- 200 응답이 돌아오면 정상 작동하는 것
- 404 등 4, 5로 시작하는 것은 작동하지 않은 것
1. API 신청하여 key 불러오기
- 사이트에서 정보 입력 후 API 서비스 키 발급받기
- 절대 노출 금지!
- 코랩 환경변수에 저장하여 불러올 수 있다.

2. 요청 request하여 데이터 받아오기
- 현재 이용하는 api의 요청 변수는 'serviceKey' 하나뿐.
import pandas as pd
import requests
from google.colab import userdata
import xml.etree.ElementTree as ET
# request
url = 'http://api.kcisa.kr/openapi/service/rest/meta5/getKFCC0502'
params = {
('serviceKey', userdata.get('boxoffice_api_key'))
}
response = requests.get(url, params)3. 받아온 데이터 정제하여 데이터프레임 만들기
# XML parsing
root = ET.fromstring(response.text)
data = []
for item in root.findall('.//item'):
item_data = {}
for child in item:
item_data[child.tag] = child.text
data.append(item_data)
df = pd.DataFrame(data)
df.head()결과

추가 실습 - 기상청 기상특보 데이터
- ServiceKey encoding과 decoding 중 decoding 이용해야 함!
import pandas as pd
import requests
from google.colab import userdata
import xml.etree.ElementTree as ET
# request
url = 'http://apis.data.go.kr/1360000/WthrWrnInfoService/getWthrWrnList'
params = {
('ServiceKey', userdata.get('weather_api_decoding')),
('pageNo', '1'),
('numOfRows', '30'),
('fromTmFc', '20250113'),
('toTmFc', '20250118')
}
response = requests.get(url, params)
# 확인용
#print(response.text)
# XML parsing
root = ET.fromstring(response.text)
data = []
for item in root.findall('.//item'):
item_data = {}
for child in item:
item_data[child.tag] = child.text
data.append(item_data)
df = pd.DataFrame(data)
df.head()결과:

데이터 parsing 방법 2
- 출력변수 딕셔너리 직접 정의하기
root = ET.fromstring(response.text)
row_dict = {'item_name':[],
'item_code':[],
'kind_name':[],
'kind_code':[],
'rank':[],
'rank_code':[]}
#data/item 계층 밑의 값을 list으로 가져와 iteration
for i in root.findall('./data/item'):
# item_name부터 텍스트를 가져와 딕셔너리에 저장
for j in i:
row_dict[j.tag].append(j.text)
df = pd.DataFrame(row_dict)
To Dare is To Do