
👾 JPQL : Java Persistence Query Language
- 엔티티 객체를 조회하는 객체지향 쿼리
- SQL을 추상화해서 특정 DB에 의존하지 않는다. -> DB Dialect만 변경해주면 JPQL을 수정하지 않고 DB 변경 가능
객체지향 쿼리
- 테이블을 대상으로 쿼리하는 것이 아니라 엔티티 객체를 대상으로 쿼리한다.
기본 문법
select_문 :: =
select_절
from_절
[where_절]
[group_절]
[having_절]
[orderby_절]
update_문 :: = update_절 [where_절]
delete_문 :: = delete_절 [where_절]🐰 select 문
기본 문법 및 특징
SELECT m FROM Member AS m where m.username = 'Hello'-
대소문자 구분 : 엔티티와 속성만
-
엔티티 이름 : Member는 클래스 명이 아니라 엔티티 명 @Entity(name="")
-
별칭(식별 변수)은 필수 : Member에 m이라는 별칭 -> 없으면 잘못된 문법
-
AS 생략 가능
-
JPQL 을 실행하려면 쿼리 객체를 만들어야함
-
TypeQuery : 반환타입을 명확하게 지정할 수 있을때
-
Query : 반환 타입을 명확히 할 수 없을 때
-
파라미터 바인딩
- 이름 기준 파라미터 : 파라미터를 이름으로 구분하는 방법 -> 명확 !!
- 위치 기준 파라미터 : ? 다음에 위치 값을 준다. 위치 값은 1부터 시작
- 왜 사용하는가?
- 직접 문자를 더해 만들어 넣으면 악의적인 사용자에 의해 SQL 인젝션 공격을 당할 수 있다.
SELECT m FROM Member m WHERE m.username = '" + usernameParam +'" - 성능이슈
-> 파라미터 값이 달라도 같은 쿼리로 인식하여 JPQL을 SQL로 파싱한 결과를 재사용할 수 있다.
-> DB 내부에서 실행한 SQL을 파싱해서 사용하는데 같은 쿼리는 파싱한 결과를 재사용할 수 있다.
->즉, 애플리케이션과 DB 모두 해당 쿼리의 파싱 결과를 재사용할 수 있다.
- 직접 문자를 더해 만들어 넣으면 악의적인 사용자에 의해 SQL 인젝션 공격을 당할 수 있다.
- 공격이 비교적 쉬운 편이고 공격에 성공할 경우 큰 피해를 입힐 수 있는 공격, 위협 1 순위
- 2017년 3월에 일어난 “여기어때” 의 대규모 개인정보 유출 사건도 SQL Injection 으로 인해 피해가 발생 뉴스 자료
SQL 인젝션 자료
프로젝션 : SELECT 절에 조회할 대상을 지정하는 것
-
엔티티 프로젝션 : 원하는 객체를 바로 조회한 것으로 해당 엔티티는 영속성 컨텍스트에서 관리된다.

-
임베디드 타입 프로젝션 : 임베디드 타입은 조회의 시작점이 될 수 없다는 제약이 있다.

-
임베디드 타입은 엔티티 타입이 아닌 값 타입이다. 따라서 영속성 컨텍스트에서 관리되지 않는다.
-
스칼라 타입 프로젝션 : 숫자, 문자, 날짜와 같은 기본 데이터 타입들

-
여러 값 조회 : 여러 값을 선택하면 Query를 사용하여 조회할 수 있다.

-
NEW 명령어 : SELECT 다음에 NEW 명령어 사용시 반환받을 클래스를 지정할 수 있다.
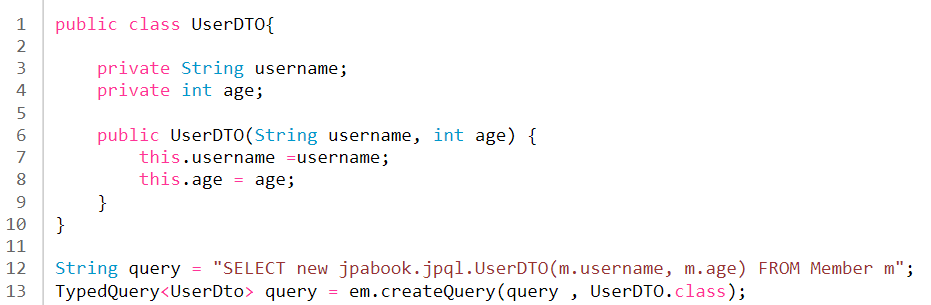
- 주의
- 패키지 명을 포함한 전체 클래스 명을 입력해야 한다.
- 순서와 타입이 일치하는 생성자가 필요하다.
- 주의
페이징 API

- setFirstResult(int startPosition) : 조회 시작 위치(0부터 시작)
- setMaxResults(int maxResult) : 조회할 데이터 수
🐒 집합과 정렬
- 집합 : 집합함수와 함께 통계 정보를 구할 때 사용
ex) 회원수, 나이 합, 평균 나이 , 최대 나이 등등
집합 함수
| 함수 | 설명 | 값이 없을 경우 |
|---|---|---|
| COUNT | 결과 수를 구한다. 반환 타입 : Long | 0 |
| MAX, MIN | 최대, 최소 값을 구한다. 문자, 숫자, 날짜 등에 사용한다. | NULL |
| AVG | 평균값을 구한다. 숫자타입만 사용할 수 있다. 반환 타입 :Double | NULL |
| SUM | 합을 구한다. 숫자 타입만 사용 가능하며, 타입 별로 반환 타입이 다르다. | NULL |
- 참고 사항
- NULL 값은 무시하므로 통계에 잡히지 않는다. DISTINCT가 정의되어 있어도 무시된다.
- DISTINCT를 집합 함수 안에 사용해서 중복된 값 제거 후 집합을 구할 수 있다.
- DISTINCT를 COUNT에서 사용할 때 임베디드 타입은 지원하지 않는다.
GROUP BY, HAVING

- GROUP BY 는 통계 데이터를 구할 때 특정 그룹끼리 묶어준다.
- HAVING : GROUP BY와 함께 사용하고 그룹화한 통계 데이터를 기준으로 필터링한다.
- 전체 데이터를 기준으로 처리하므로 실시간 사용에는 부담이 많다. 결과가 아주 많을 경우 통계 결과만 저장하는 테이블을 별도로 만들어 두고 사용자가 적은 새벽에 통계 쿼리를 실행해서 그 결과를 보관하는 것이 좋다.
ORDER BY
- 결과를 정렬할 때 사용
🐻 JPQL 조인
연관 필드 : 다른 엔티티와 연관관계를 가지기 위해 사용하는 필드
- JPQL 쿼리문 : 회원이 가지고 있는 연관 필드로 조인
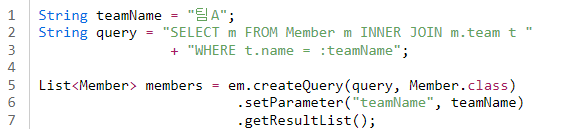
- 실제 SQL 문
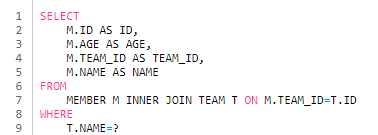
내부 조인 : (INNER) JOIN
- 기준테이블과 연결한 테이블의 중복된 값을 보여준다.
외부 조인 : LEFT (OUTER) JOIN
- 두 테이블을 조인할 때, 1개의 테이블에만 데이터가 있어도 결과가 나옴
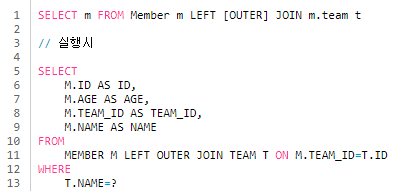
컬렉션 조인 : 1:N, N:1 JOIN

세타 조인 : 전혀 관계없는 엔티티를 조인할 수 있다.
- WHERE 절을 사용한다.
- 내부 조인만 지원
- ex) 회원 이름이 팀 이름과 똑같은 사람 수
🦴 페치 조인
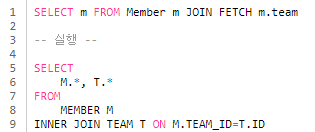
-
연관된 엔티티나 컬렉션을 한 번에 같이 조회
-> 멤버를 조회하면서 연관된 팀을 함께 조회한다. -
JPQL에서 성능 최적화를 위해 제공하는 기능
-
객체 그래프를 유지하면서 조회가 된다.
-
회원과 팀이 지연 로딩 설정이 되어있더라도 함께 조회했으므로 연관된 팀 엔티티는 실제 엔티티이다.
-
회원 엔티티가 영속성 컨텍스트에서 분리되어 준영속 상태가 되어도 연관된 팀을 조회할 수 있다.
- 컬렉션 페치 조인
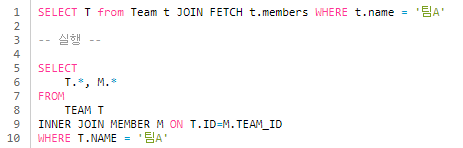
- 팀을 조회하면서 연관된 회원 컬렉션도 함께 조회한다.
- 함께 조회해서 지연 로딩 발생 x
- 페치 조인과 DISTINCT
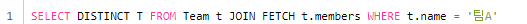
- SQL에 DISTINCT를 추가하고 애플리케이션에서 한 번 더 중복을 제거한다.
- 따라서, 위의 경우에 SQL에서 DISTINCT는 효과가 없지만, 애플리케이션에서 적용된다.
- 페치 조인이 아닌 일반 조인을 사용할 경우?
- SELECT에서 지정한 엔티티만 조회한다.
- 지연 로딩을 설정했다면 프록시나 초기화하지 않은 컬렉션 레퍼를 반환한다.
- 즉시 로딩을 설정했다면 쿼리를 한 번 더 실행한다.
-> 즉, 패치조인을 사용할 경우 연관된 엔티티도 함께 조회한다 !
- 페치 조인의 특징
- SQL 한 번으로 연관된 엔티티들을 함께 조회할 수 있어서 성능을 최적화 할 수 있다.
- 글로벌 로딩 전략보다 우선한다. -> 지연 로딩의 경우에도 함께 조회된다.
-> 글로벌 로딩 전략을 즉시로딩으로 사용하기보다 페치 조인을 사용는게 효과적이다. - 준영속 상태에서도 객체 그래프를 탐색할 수 있다.
- 페치 조인 한계
-
페치 조인 대상에는 별칭을 줄 수 없다. (JPA 표준에서)
-> SELECT, WHERE 절, 서브 쿼리에 페치 조인 대상을 사용할 수 없다. -
둘 이상의 컬렉션을 페치할 수 없다.
-> 컬렉션 * 컬렉션은 카테시안 곱이 만들어지므로 주의, PersistenceException 발생 -
컬렉션을 페치 조인하면 페이징 api를 사용할 수 없다.
-> 하이버네이트에서는 위와 같은 상황에서 경고 로그를 남기면서 메모리에서 페이징 처리를 한다.
-> 데이터가 많으면 성능 이슈와 메모리 초과 예외가 발생할 수 있어 위험하다.
-> 일대다가 아닌 일대일, 다대일 들은 페치 조인을 사용해 페이징 API를 사용할 수 있다. -
성능 최적화에 유용하고 실무에서 자주 사용되지만 여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야한다면 여러 테이블에서 필요한 필드들만 조회해서 DTO로 반환하는 것이 더 효과적일 수 있다.
🦐 경로 표현식 : Path Expression
- 쉽게 말해 점을 찍어 객체 그래프를 탐색하는 것
- 용어 정리
- 상태 필드 : 단순히 값을 저장하기 위한 필드(필드 OR 프로퍼티)
- 연관 필드 : 연관관계를 위한 필드, 임베디드 타임 포함(필드 OR 프로퍼티)
- 단일 값 연관 필드 : @ManyToOne, @OneToOne, 대상이 엔티티
- 컬렉션 값 연관 필드 : @OneToMany, @ManyToMany, 대상이 컬렉션
- 경로 표현식과 특징
- 상태 필드 경로 : 경로 탐색의 끝
- 단일 값 연관 경로 : 묵시적으로 내부 조인이 일어난다. 계속 탐색 가능
- 컬렉션 값 연관 경로 : 묵시적으로 내부 조인이 일어난다. 탐색할 수 없다. 단 FROM 절에서 조인을 통해 별칭을 얻으면 별칭으로 탐색할 수 있다.
- 명시적 조인과 묵시적 조인
- 명시적 조인 : join을 직접 적어주는 것
- 묵시적 조인 : 경로 표현식에 의해 묵시적으로 조인이 일어나는 것, 내부 조인만 가능
- 묵시적 조인 시 주의사항
-
항상 내부 조인이다.
-
컬렉션에서 경로 탐색을 하려면 명시적으로 조인해서 별칭을 얻어야 한다.
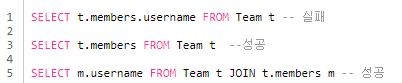
-
경로 탐색은 주로 SELECT, WHERE 절에서 사용하지만 묵시적 조인으로 인해 SQL의 FROM 절에 영향을 준다.
-
조인이 성능상 차지하는 부분은 아주 커서 묵시적 조인은 조인이 일어나는 상황을 한눈에 파악하기 어렵다는 단점이 있다. -> 성능이 중요하면 명시적 조인을 사용하라
-
컬렉션의 size 함수 사용시 count 함수를 사용하는 sql로 변환됨
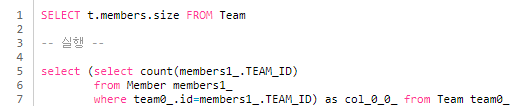
🦉 서브 쿼리 : sql문 안의 또 다른 sql문
- WHERE, HAVING 절에서만 사용할 수 있다
1. {NOT} EXISTS (subquery)
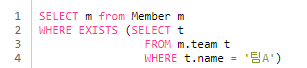
- 서브쿼리에 결과가 존재하면 참, NOT은 반대
2. {ALL | ANY | SOME} (subquery)

- 비교 연산자와 같이 사용한다
- ALL : 조건을 모두 반족하면 참이다.
- ANY / SOME : 조건을 하나라도 만족하면 참이다.
3. {NOT} IN (subquery)

- 서브쿼리의 결과 중 하나라도 같은 것이 있으면 참, 서브 쿼리가 아닌 곳에서도 사용
🐢 조건식
| 종류 | 설명 | 예제 |
|---|---|---|
| 문자 | 작은 따옴표 사용, 작은 따옴표를 표현할 때 연속 두 개 사용 | 'She''s' |
| 숫자 | Long, Double, Float | 10L, 10D, 10F |
| 날짜 | DATE {d 'yyyy-mm-dd'} TIME {t 'hh-mm-ss'} DATETIME {ts 'yyyy-mm-dd hh:mm:ss.f'} |
{d '2022-05-18'} {t '10-11-11'} {ts '2022-05-19 10-11-11.123'} m.createDate = {d '2022-05-19'} |
| Boolean | TRUE, FALSE | |
| Enum | 패키지명을 포함한 전체 이름을 사용해야한다. | jpabook.MemberType.Admin |
| 엔티티 타입 | 엔티티의 타입을 표현한다. 주로 상속과 관련해서 사용한다. | TYPE(m) = Member |
👻 연산자 우선 순위
- 경로 탐색 연산 : .
- 수학 연산 : +, - (단항 연산자, 음수) , *, /, + , -
- 비교 연산 : <>(다름), BETWEEN, LIKE, IN, IS NULL, IS EMPTY, EXISTS
- 논리 연산 : NOT, AND , OR
- 논리 연산
- AND : 둘 다 만족하면 참
- OR : 둘 중 하나만 만족해도 참
- NOT : 조건식의 결과 반대
- 비교 연산
- Between
- X [NOT] BETWEEN A AND B
- X 는 A ~ B 사이의 값이면 참 (A, B 포함)
- IN
- X [NOT] IN (예제)
- X 와 가튼 값이 예제에 하나라도 있으면 참, 예제에는 서브쿼리 사용 가능
- LIKE
- 문자표현식 [NOT] LIKE 패턴값 [ESCAPE 이스케이프문자]
- 문자 표현식과 패턴 값을 비교한다.
- % : 아무 값이 입력되어도 됨, 없어도 됨
- _ : 한 글자는 아무 값이 입력되어도 되지만 값이 있어야함
- \ : 기호 표시
- NULL
- {단일값 경로 | 입력 파라미터 } IS [NOT] NULL
- NULL 인지 비교 한다. 꼭 IS NULL 사용
- 컬렉션 식
: 컬렉션은 컬렉션 식만 사용 가능함 !
- 빈 컬렉션 비교 식
- {컬렉션 값 연관 경로} IS [NOT] EMPTY
- 컬렉션에 값이 비었으면 참
- 컬렉션의 멤버 식
- {엔티티나 값} [NOT] MEMBER [OF] {컬렉션 값 연관 경로}
- 엔티티나 값이 컬렉션에 포함되어 있으면 참
- 스칼라 식
- 스칼라 : 숫자, 문자, 날짜, CASE, 엔티티 타입 같은 가장 기본적인 타입
문자함수
- CONCAT (문자1, 문자2 , ...)
- SUBSTRING (문자, 위치, [길이])
- TRIM([옵션][trim문자] 문자)
- LEADING : 왼쪽만
- TRAILING : 오른쪽만
- BOTH : 양쪽 다 DEFAUTL
- LOWER(문자)
- UPPER(문자
- LENGTH(문자)
- LOCATE(찾을 문자, 원본 문자, [검색 시작 위치])
수학함수
- ABS(수학식)
- SQRT(수학식)
- MOD(수학식, 나눌 수)
- SIZE(컬렉션 값 연관 경로식)
- INDEX(별칭) : @OrderColumn을 사용하는 LIST 타입 컬렉션의 위치 값을 구함
날짜함수
- CURRENT_DATE : 현재 날짜 -> 2022-05-19
- CURRENT_TIME : 현재 시간 -> 23:24:17
- CURRENT_TIMESTAMP : 현재 날짜 시간 -> 2022-05-19 23:24:17.123
- 하이버네이트는 YEAR(날짜), MONTH(날짜), DAY(), HOUR(), MINUTE(), SEOCOND() 지원
- 각각의 날짜 함수는 데이터베이스 방언에 등록되어 있음
-> 문자열에서 날짜변환 : ORACLE TO_DATE , MYSQL STR_TO_DATE
MYSQL과 ORACLE의 날짜 함수
- CASE 식 : 특정 조건에 따라 분기할 때 사용
- 기본 CASE
- 심플 CASE : 조건식을 사용할 수 없지만 문법이 단순하다.
- COALESCE : 스칼라식을 차례대로 조회해서 null이 아니면 반환한다.
- NULLIF : 두 값이 같으면 null을 반환하고 다르면 첫번째 값을 반환한다. 보통 집합함수와 함께 사용
🐾 다형성 쿼리
- JPQL로 부모 엔티티를 조회하면 자식 엔티티도 함께 조회한다.
- TYPE : 엔티티의 상속 구조에서 조회 대상을 특정 자식 타입으로 한정할 때 사용
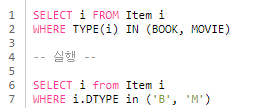
- SQL 문 실행시 DiscriminatorValue로 사용되는걸 볼 수 있음
- TREAT : 부모 타입을 특정 자식 타입으로 다룰 때 사용

- JPA 표준 : FROM, WHERE 절에서 사용가능
- 하이터베이트 : SELECT, FROM, WHERE 절에서 사용가능
- 기타 정리
- ENUM은 = 비교 연산만 지원
- 임베디드 타입은 비교를 지원하지 않는다.
- EMPTY STRING : ORACLE은 NULL처리 MYSQL은 빈문자열 처리
- NULL 정의
- 조건을 만족하는 데이터가 하나도 없으면 NULL이다.
- NULL과의 모든 수학적 계산 결과는 NULL이다. ex) NULL == NULL, NULL is NULL은 참
🦔 엔티티 직접 사용
- 기본 키 값
- 객체 인스턴스는 참조 값으로 식별하고 테이블 로우는 기본 키 값으로 식별한다.
- 따라서 JPQL에서 엔티티 객체를 직접 사용하면 SQL에서는 해당 엔티티의 기본 키값을 사용한다.
- 파라미터로 직접 받아보기
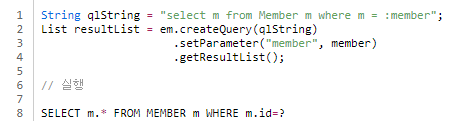
- 외래 키 값

- member 테이블이 team_id 외래 키를 가지고 있어서 묵시적인 조인이 일어나지 않음
- 생성되는 SQL문이 동일
🐌 동적쿼리와 정적쿼리
- 동적 쿼리
- em.createQuery("select ") 처럼 JPQL을 문자로 완성해서 직접 넘기는 것
- 런타임에 특정 조건에 따라 JPQL을 동적으로 구성할 수 있다.
- 정적 쿼리
- 미리 정의한 쿼리에 이름을 부여해서 필요할 때 사용할 수 있는쿼리 -> Named 쿼리
- 한 번 정의하면 변경할 수 없다.
- 데이터베이스의 조회 성능 최적화에 도움
🤖 Named 쿼리
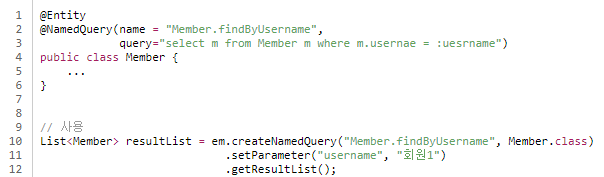
- Named 쿼리는 애플리케이션 로딩 시점에 JPQL 문법을 체크하고 미리 파싱해둔다.
-> 빠르게 오류 확인 가능, 사용시점에는 파싱된 결과를 재사용 하므로 성능상 이점 - @NamedQuery 를 사용해서 자바 코드에 작성하거나 XML 문서에 작성할 수 있다.
- Named 쿼리는 영속성 유닛 단위로 관리되므로 충돌을 방지하기 위해 엔티티 이름을 앞에 주고, 이름이 앞에 있으면 관리하기 쉽다.
- 하나의 엔티티에 2개 이상의 Named 쿼리를 정의하려면 @NamedQueries 사용
XML에 정의
- META-INF/persistence.xml에 해당 xml파일 추가
- 어노테이션과 xml 중 xml이 우선권을 가진다.
- 운영 환경에 따라 다른 쿼리를 실행해야 한다면 환경에 맞춘 xml을 준비하고 xml만 변경하여 배포하면 된다.
