<5강>
<프로세스 실행>
cpu burst: cpu를 쓰는 단계
i/o burst: i/o을 실행하는 단계
프로세스 실행은 cpu 실행주기와 i/o 대기 주기로 구성
<short-term 스케줄러-CPU 스케줄러>
비선점 스케줄링(nonpreemptive):
프로세스가 자발적으로 cpu를 양도하는 것
ex)시스템콜, i/o 요청장치
선점 스케줄링(preemptive):
CPU를 강제적으로 다른 프로세스에 할당, 프로세스의 우선순위 허용
ex)할당된 cpu시간이 끝나면 다른 프로세스에 할당,낮은 우선순위를 가진 프로세스보다 높은 우선순위를 가진 프로세스가 CPU를 선점하는 방식
차이:
preemptive 스케줄링은 우선순위가 높은 프로세스가 실행 중인 동안 다른 프로세스가 그 실행을 중단할 수 있지만, nonpreemptive 스케줄링은 한 번 시작된 프로세스가 CPU를 양도할 때까지 실행된다.
<CPU스케줄링이 일어나는 경우>
1)실행 상태에서 대기상태로 전환될 때
i/o인터럽트 nonpreemtive
2) 실행 상태에서 준비상태로 전환될때
자기한테 할당된 시간이 끝났을 때 preemtive
3)대기 상태에서 준비로 전혼될때
i/0가 끝나고 지금실행중인 프로세스가 끝나면 강제적으로 일어남 preemtive
4)종료nonpreemtive
preemtive고려
1)공유데이터를 동시에 접근할때
2)인터럽트를 처리할 떄(빠르게 처리해야하므로)
3) 커널 모드일 때 선점고려
<디스패치>
디스패치 모듈은 CPU스케줄러에 의해 선택된 프로세스에 대한 CPU제어 제공
<디스패치 과정>
1)문맥교환
2)사용자모드로 전환
3)프로그램을 다시 실행하기 위해 프로그램의 적절한 위치로 이동
Dispatch latency(지연)
Dispatcher가 한 프로세스를 중지하고 다른 실행을 시작하는 데 걸리는 시간
<스케줄링 최적화 기준>
1) 최대 CPU사용률(CPU utilization)
2) 최대 처리량(Throughput)
3) 최소 총처리시간 - 특정 프로세스를 실행하는 데 걸리는 시간(Turnaround time)
4) 최소대기시간 - 프로세스가 ready 큐에서 기다린 시간(Waiting time)
5) 최소응답시간 - 요청한 후 1번째 응답이 생성될때까지 걸리는 시간(짧게 유지)( Response time)
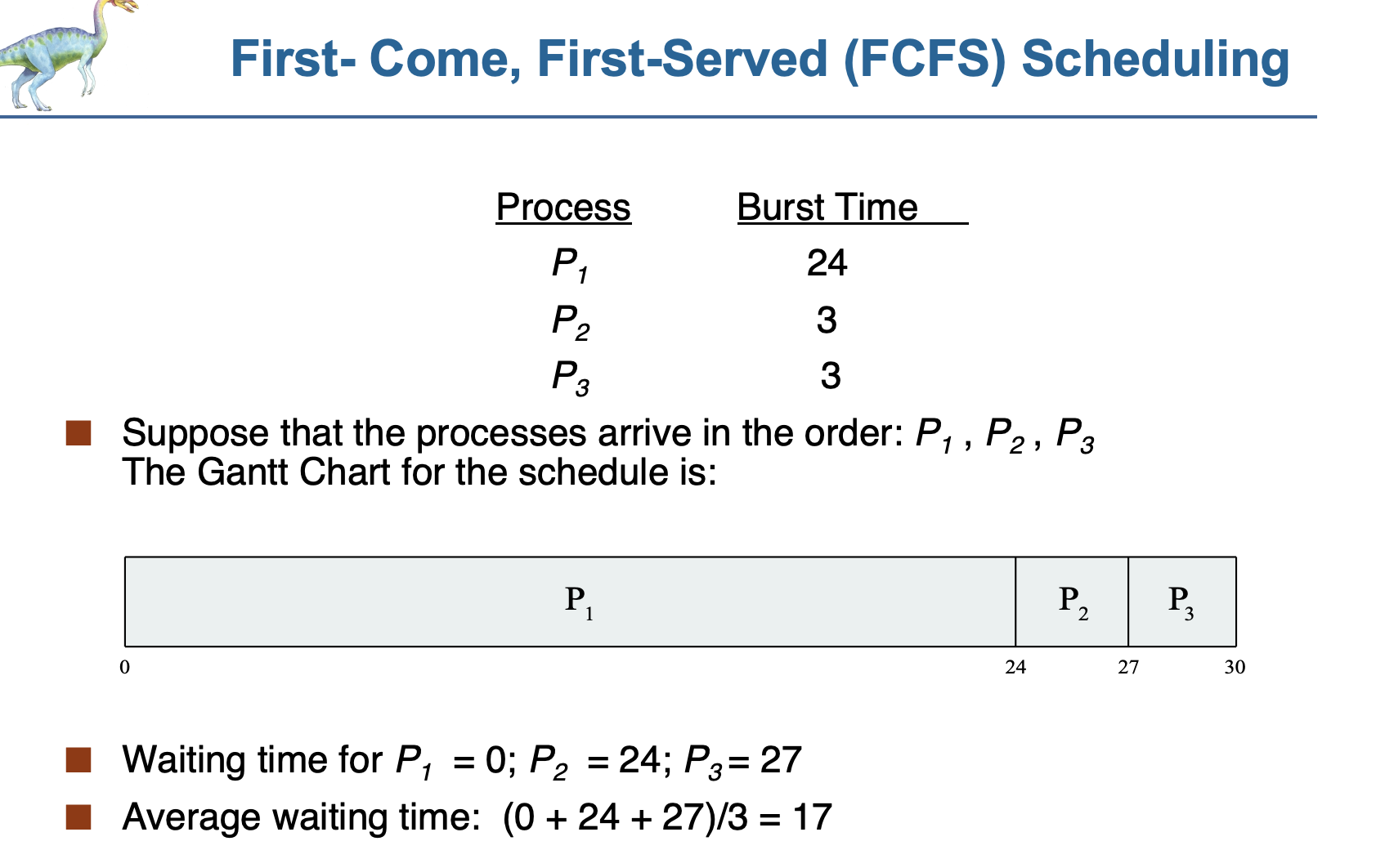
1.(first-come-first-served)FCFS 스케줄링(nonpreemtive)
프로세스가 도착한 순서대로 진행하는 스케줄링
호위효과 발생: 긴 프로세스에 의해 기다리는 시간이 길어짐

2.(Shortest-job-first)SJF 스케줄링(nonpreemtive)
(우선순위 스케줄링의 일종)
최소 평균 대기시간을 제공하는 가장 수행 시간이 짧은 job부터 수행하는 스케줄링
(어떤 게 수행시간이 짧은 지 알기 어려움)

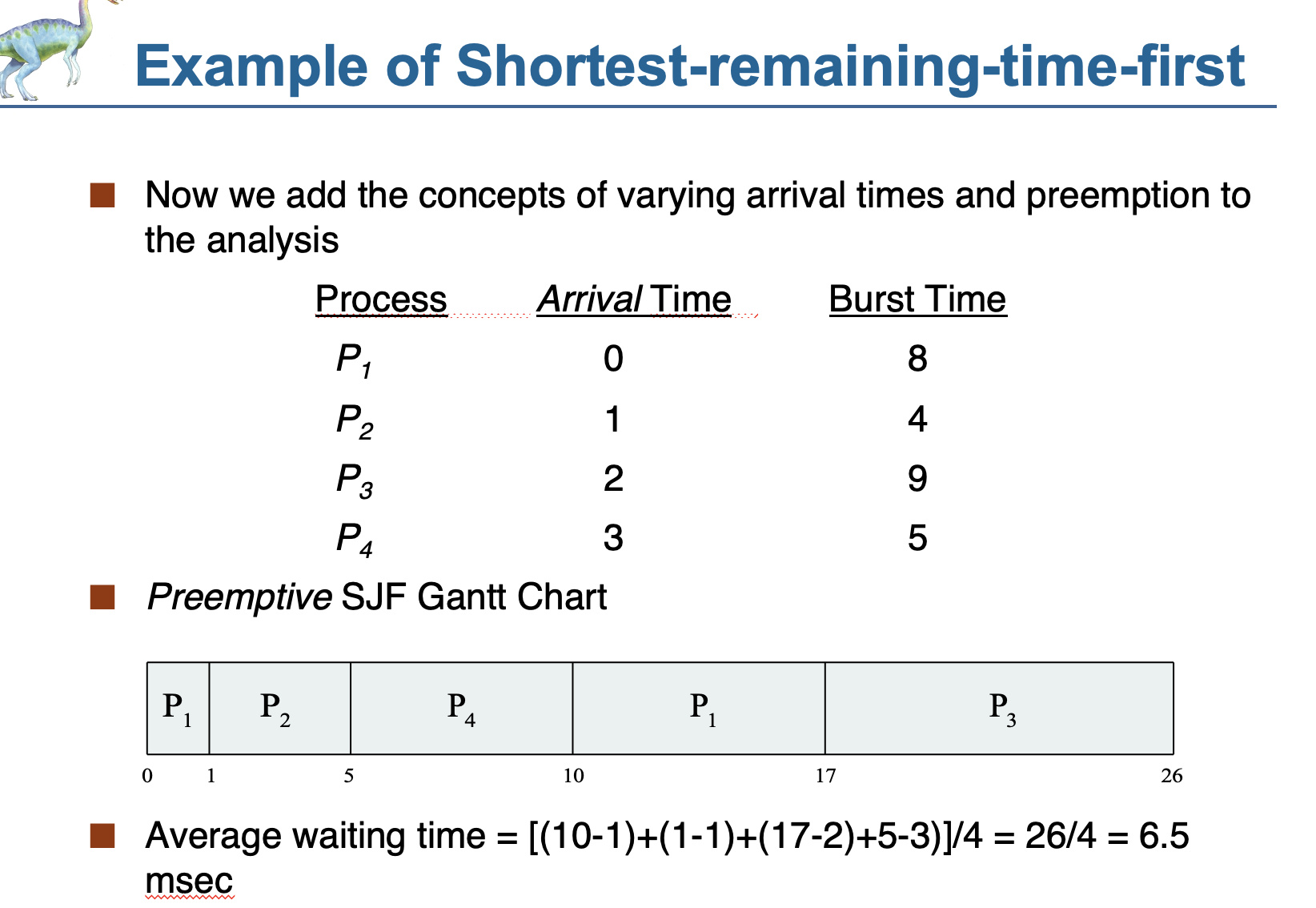
3.< SRTF(Shortest-Remaining-Time-First>
(preemtive) 한 SJF 스케줄링
수행시간이 짧은 job이 나타나면 CPU를 그 job에게 양도하는 스케줄링
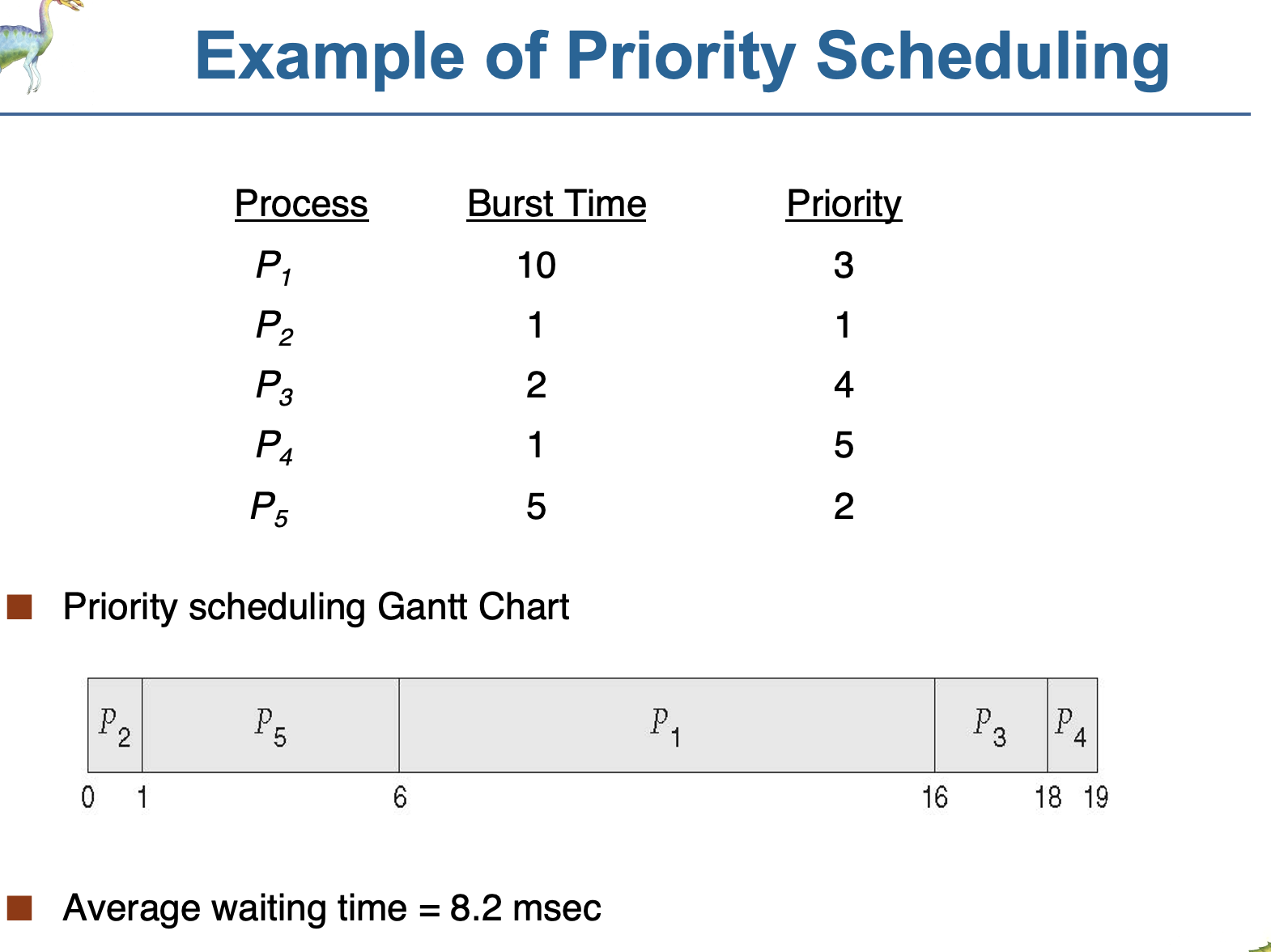
4.<Priority 스케줄링>(우선순위 스케줄링)
(nonpreemtive) 우선순위가 높은 순대로 수행
(preemtive) 우선순위가 높은 job이 나타나면 cpu를 그 job에게 양도
문제 :(starvation)기아 - 낮은 우선순위가 실행되지 않을 수 있음
해결 :aging(노화)- 시간이 지날수록 프로세스의 우선순위를 높여주는 방법
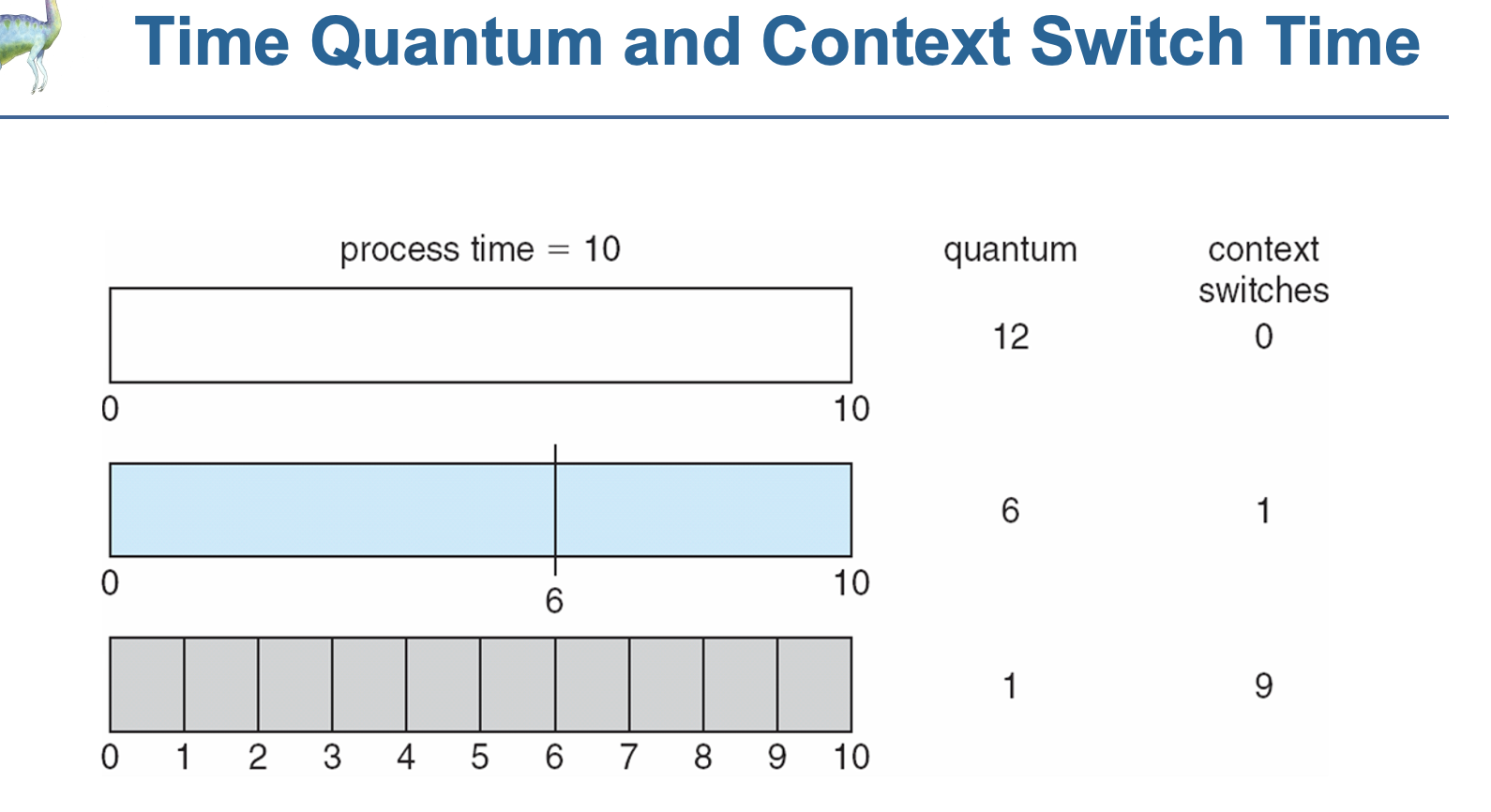
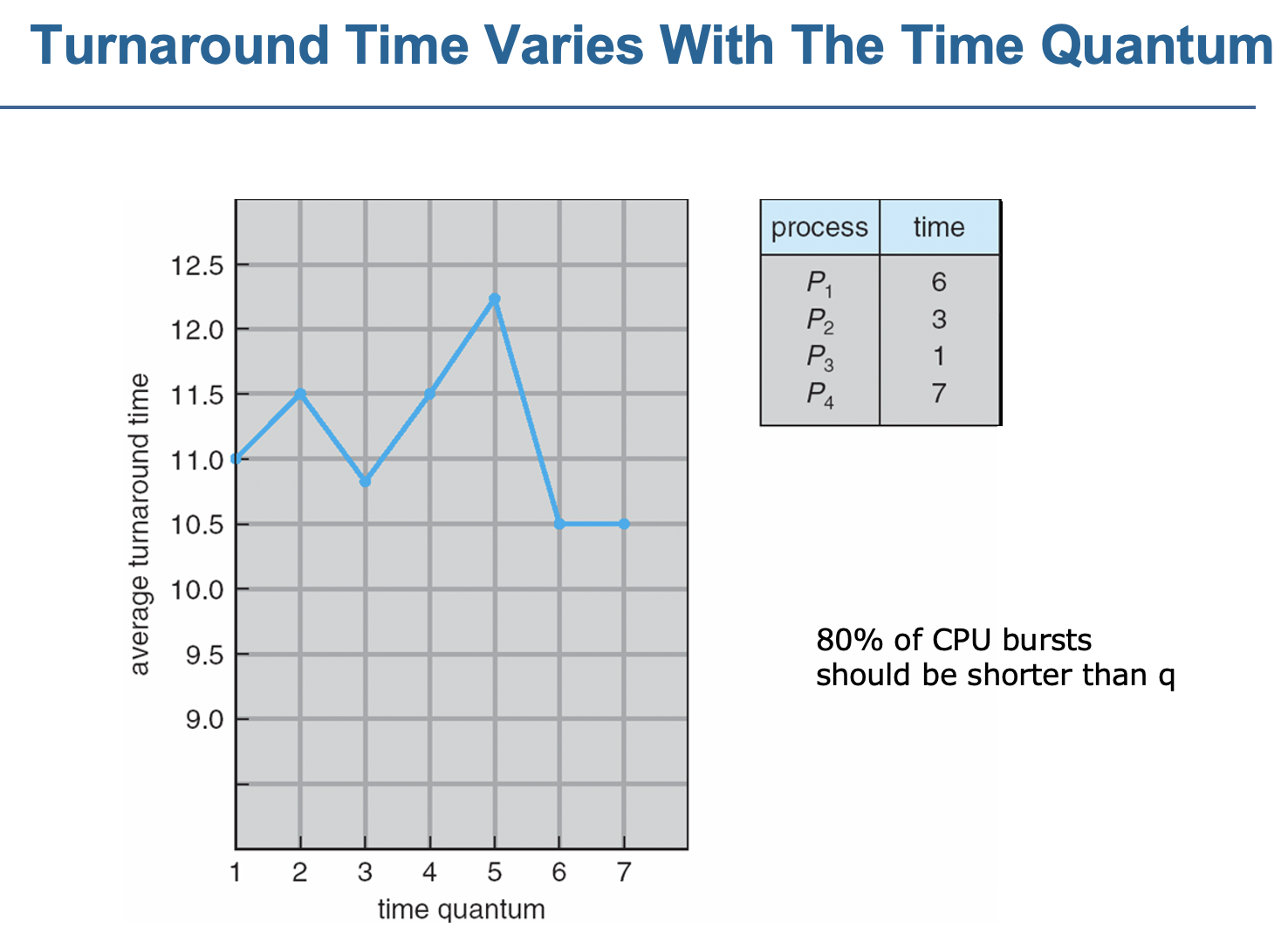
5.<RR(roundrobin)>
일정 시간동안 순서대로 cpu를 할당하는 스케줄러(time slice, time 퀀텀)
일정 시간이 지나고 다시 실행이 덜 끝났으면 ready 큐의 끝으로 감
q가 너무 길어지면: 총 대기시간이 길어진다(FIFO)
q가 너무 짧으면:오버헤드 발생(문맥교환시간보다 길어야함)
SJT에 비해 총 처리시간이 길지만 응답시간이 짧음

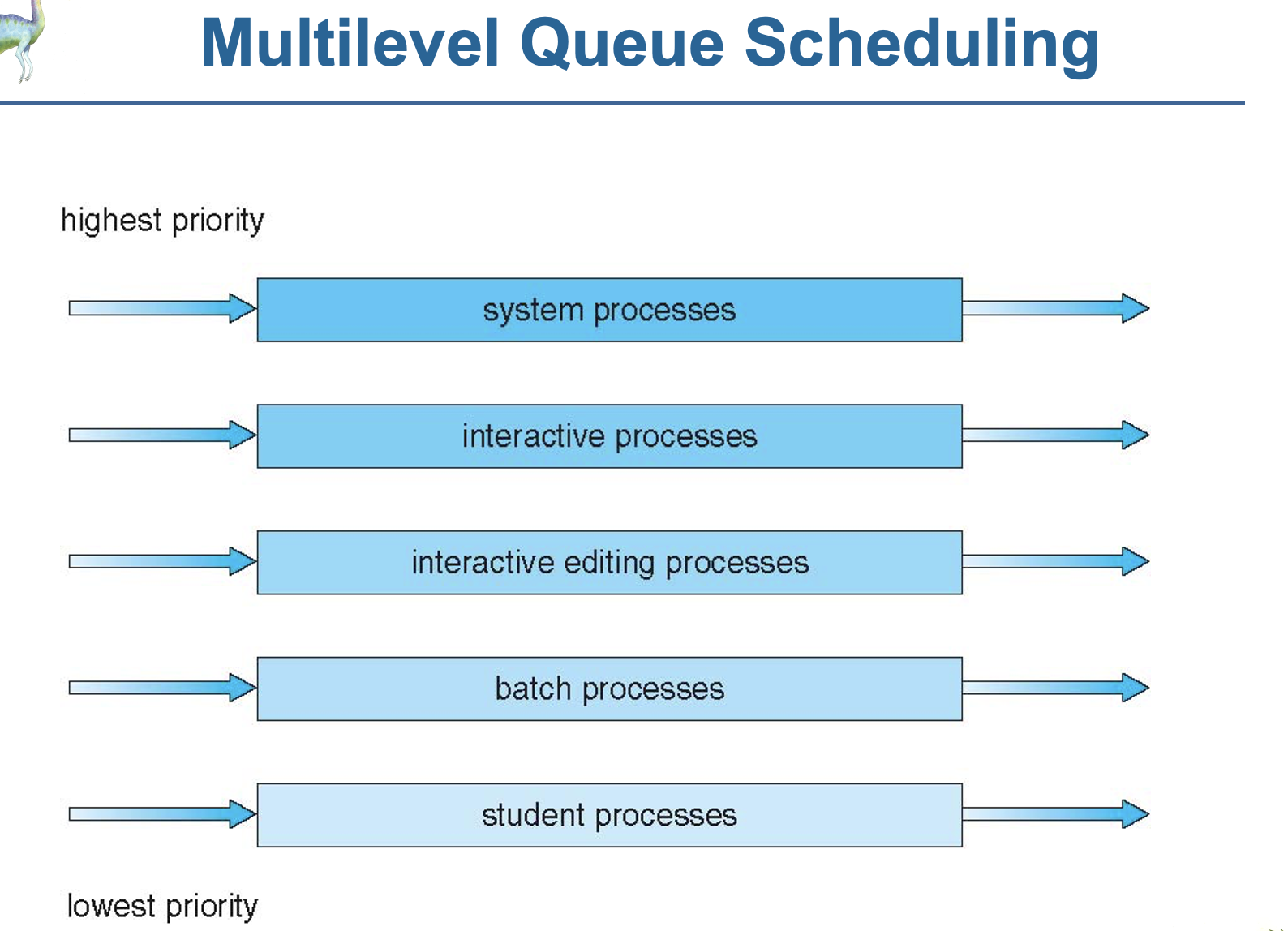
6.<multilevel 큐 스케줄링>
각각의 프로세스를 특성에 맞게 서로 다른 ready큐에 지정하는 것(큐끼리의 이동 불가)
foreground에서는 상호작용(interactive)을 해야하는 프로세스를 rr스케줄링을 통해처리한다.
(응답시간이 빠르고 cpu벌스가 짧은)
background에서는 일괄처리(batch)를 해야하는 프로세스를 fcfs스케줄링을 통해 처리한다.
(총처리량이 많고 긴 시간을 필요로 하는)
큐를 스케줄링 하는 법
1)fixed priority scheduling (고정된 우선순위 스케줄링)
foreground에 서비스를 먼저 실행하고 background의 서비스를 실행한다.
2)time slice
각 큐에 time을 적절한 비율로 할당해야한다.(foreground 80%, background 20%)
7.<multilevel feedback 큐>
멀티레벨 피드백 큐는 멀티레벨 큐랑 동일하나 프로세스가 하나의 큐에서 다른 큐로 이동 가능하다는 점이 다르다. (aging을 통해 이동가능)
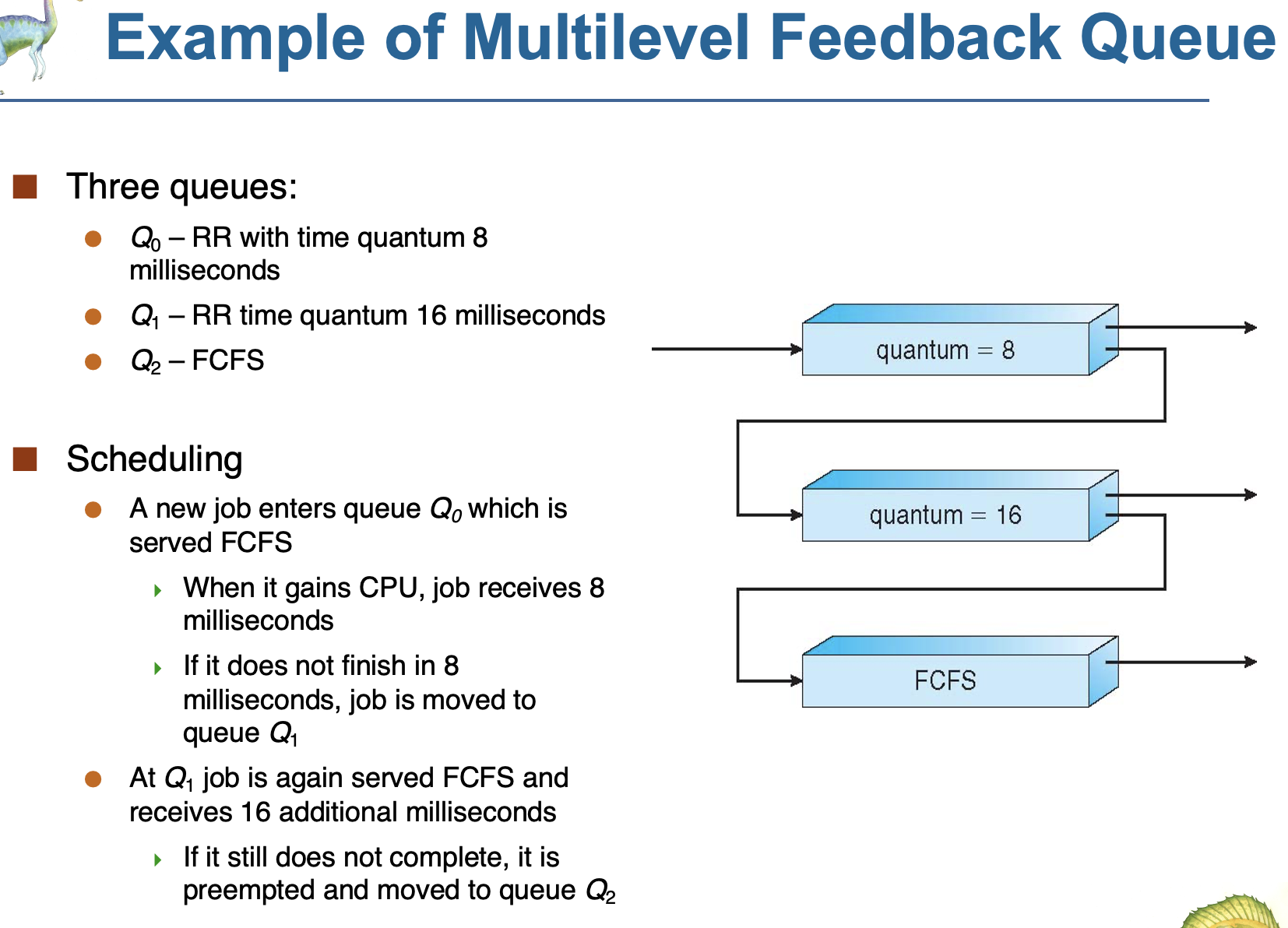
다중 피드백 큐스케줄러는 다음과 같은 매개변수로 정의됩니다:
1)큐의 개수 정하기
2)큐마다의 스케줄링 알고리즘 지정
3) 프로세스를 업그레이드 시킬 때 사용하는 방식
4) 프로세스를 다운그레이드 시킬 때 사용하는 방식
5)프로세스가 들어오면 어떤 큐에 넣을 지 지정
<multiple- processor 스케줄링>
1)비대칭 멀티 프로세싱(Asymmetric multiprocessing)
프로세서가 각각 다른 작업을 수행 (하나의 명령자와 일꾼들이 있는 구조)
단점: 한쪽에 편중될 수 있다
장점: 실행시간 짧다
2)대칭 멀티 프로세싱(Symmetric multiprocessing, SMP)
cpu가 모두 동등한 작업을 수행한다.
단점:실행시간 길다
(cpu가 여러갠 데 readyque는 하나인 경우 - 뒤에 있는 프로세스가 오래 기다려야 함)
(cpu가 여러갠 데 readyque가 여러개인 경우 - 어떤 readyque는 프로세스 엄청 많고 또 어떤 건 너무 적은? 편차가 큰 문제 발생 가능)
<process affinity 친화력>
친화력: 한 프로세스가 같은 cpu에서 수행할 수 있도록 만들어주는 특성
1.soft 친화성(필요하다면 옮겨다닐 수 있는 affinity)
2.hard 친화성(강제적으로 같은 cpu에 실행시켜야하는 affinity)
3.프로세스 세트의 변경 포함
*NUMA(Non-Uniform Memory Access)(불균일 기억장치 접근)아키텍처는 친화력에 의해 프로세스 관리 중요
Load balancing
load balancing: 각각의 cpu가 처리할 프로세스를 동등하게 가지게 하는 것
SMP(대칭 멀티 프로세싱)인 경우 작업을 고르게 실행하기 위해 로드 밸런싱(load balancing)을 시도합니다.
방법:(둘을 구분하는 문제는 안 냄 - 도찐개찐임)
1) push migration - 과부하된 CPU에서 작업을 다른 CPU로 푸시합니다.
2) pull migration - 안 바쁜 프로세서가 바쁜 프로세서에서 대기 중인 작업을 가져옵니다.
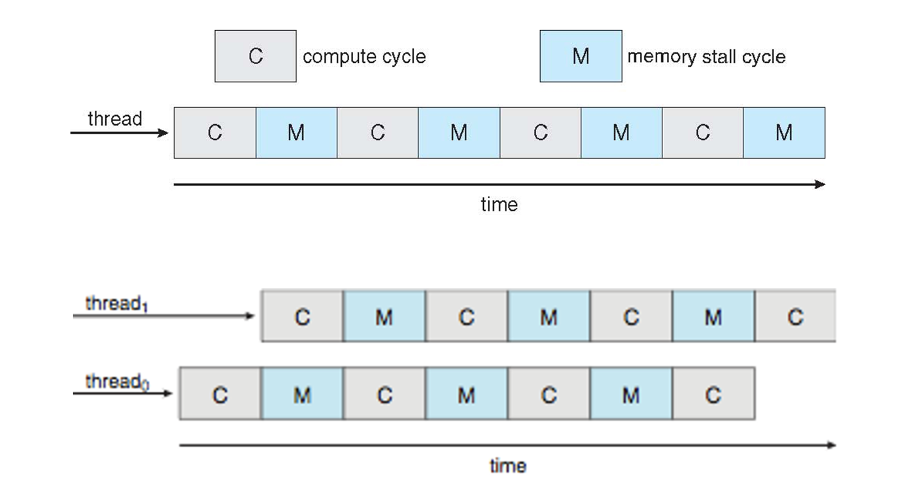
Multithreaded Multicore System
memory stall cycle(메모리 스톨 사이클) - cpu가 멈춰있어야 하는 시간 (core가 쉼)
주로, 메모리의 속도와 CPU의 속도 간의 불일치로 인해 발생
so thread 2개 쓰면서 이렇게 해결