background
1) 프로그램이 실행되기 위해서 디스크에서 메모리로 불러와서 프로세스 내에 배치되어야 함
2) 메인 메모리와 레지스터는 CPU가 직접 접근할 수 있는 유일한 저장 장치임
3) 메모리 유닛은 오직 주소와 읽기 요청, 또는 주소와 데이터 및 쓰기 요청의 흐름만을 본다.
4) 레지스터 접근은 하나의 CPU 클럭(또는 그 이하) 내에 이루어진다.
5) 메인 메모리는 여러 사이클이 걸릴 수 있으며, 이는 정체를 유발할 수 있다.
6) 캐시는 메인 메모리와 CPU 레지스터 사이에 위치한다.
7) 올바른 운영을 보장하기 위해 메모리 보호가 필요하다.
base and limit 레지스터
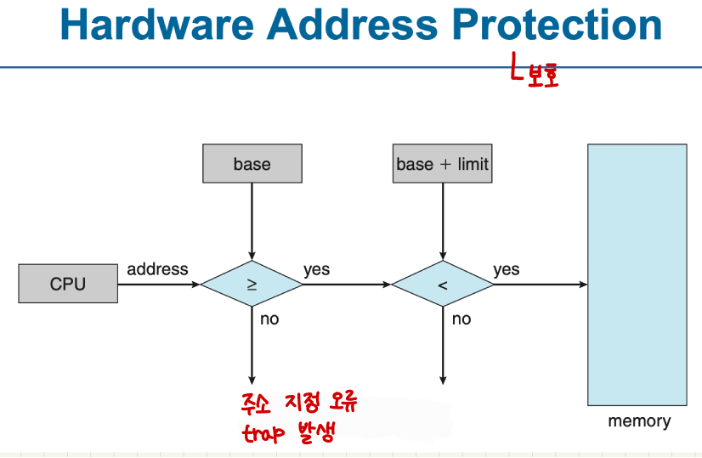
한쌍의 base 레지스터와 limit 레지스터는 논리(logical, virtual) 주소 공간을 정의한다.
CPU는 사용자 모드에서 생성된 모든 메모리 접근이 해당 사용자의 base와 limit 사이에 있는지 확인해야 한다.
<Address binding(주소 바인딩)>
- 논리 주소를 물리적 메모리로 연결시키는 작업
ex)
예를 들어, "이 모듈의 시작에서 14바이트"라는 코드 주소는 재배치 가능한 주소입니다. 그러나 이를 메모리에 로드하고 실행하기 위해서는 이 주소를 절대 주소(예: 74014)로 바인딩해야 합니다. 이것이 바로 주소 바인딩이 수행하는 작업입니다.
<주소 바인딩 3가지 방법>
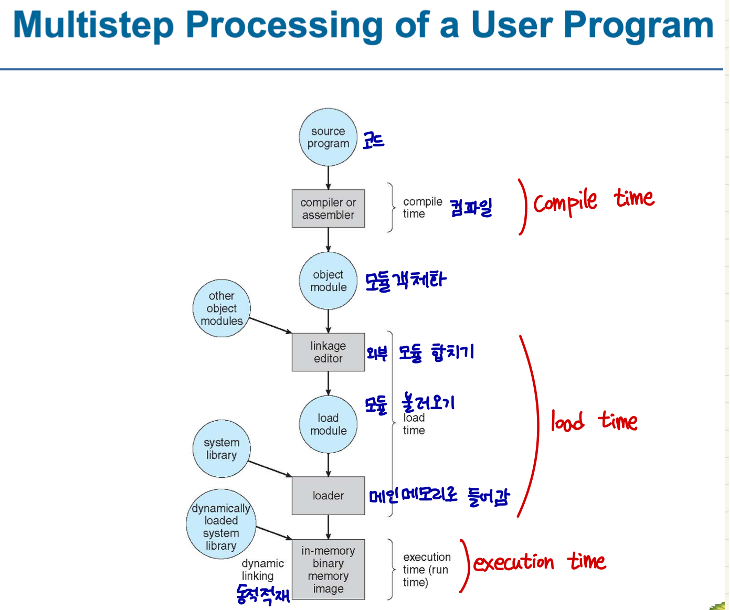
1) Compile time(컴파일 타임 바인딩):
컴파일할 때 물리적 메모리 주소가 결정되는 주소 바인딩
시작 위치가 변경되면 코드를 다시 컴파일해야 합니다.
2)Load time(로드 타임 바인딩):
프로세스가 메인메모리에 저장이 될 때 물리적 주소가 결정되는 주소 바인딩
컴파일 시간에 메모리 위치를 알 수 없는 경우 재배치 가능한 코드(Relocatable code)를 생성해야함
프로그램이 종료될 때까지 물리적 주소 위치 고정
3)Execution time(실행 시간 바인딩):
프로세스가 실행되는 동안 물리적 주소가 결정되는 주소 바인딩
주소 맵을 지원하는 하드웨어(Memory Management Unit(MMU))가 필요
<Logical(논리) vs Pysical(물리) 주소 공간>
a) 논리(Logical) 주소 공간: 프로그램이 생성하는 주소의 집합
CPU에 의해 생성되며 가상(Virtual) 주소로도 불립니다.
b) 물리(Pysical) 주소 공간: 메모리 장치에서 볼 수 있는 주소의 집합
- (컴파일 타임 & 로드 타임 바인딩)은 논리주소와 물리주소가 동일
-> 프로그램이 컴파일되거나 로드될 때 주소가 결정되기 때문 - 실행 시간 바인딩은 논리주소와 물리주소 다를 수 있음
-> 프로그램이 실행되는 동안에만 주소가 매핑되기 때문입니다.
논리 주소 공간은 프로그램이 생성하는 모든 논리 주소의 집합입니다.
물리 주소 공간은 프로그램이 생성하는 모든 물리 주소의 집합입니다.
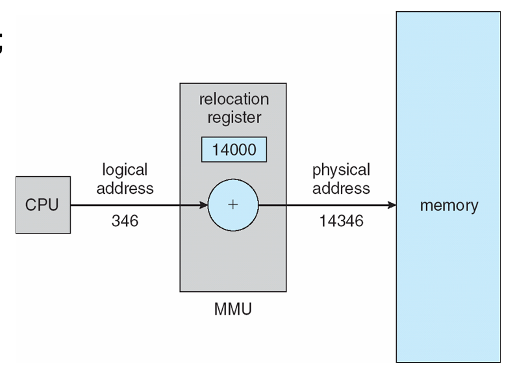
<Memory-Management Unit(MMU)>
가상 주소를 실제 물리 주소로 매핑하는 하드웨어 장치
먼저, 메모리로 전송될 때 사용자 프로세스에 의해 생성된 모든 주소에 재배치 레지스터의 값이 추가되는 간단한 방식 고려
1) 재배치(relocation) 레지스터는 베이스 레지스터로 불립니다.
2) Intel 80x86 아키텍처에서 MS-DOS는 4개의 재배치 레지스터를 사용했습니다.
사용자 프로그램은 논리 주소만 처리하며, 실제 물리 주소를 볼 수 없습니다.
1)실행 시간 바인딩은 메모리 위치에 대한 참조가 발생할 때 발생합니다.
2)논리 주소가 물리 주소에 바인딩됩니다.
<재배치(Relocation) 레지스터를 이용한 동적(Dynamic) 재배치>
- 주소가 디스크에 재배치 가능한 형식으로 있다가 프로그램이 실행될 때 주소가 물리주소로 바인딩된다.
1) 사용되지 않는 루틴은 절대 로드되지 않습니다.(메모리 공간 활용도 향상)
2) 모든 루틴이 디스크에 재배치 가능한 로드 형식으로 디스크에 저장됩니다.
3) 드물게 발생하는 경우를 처리하기 위해 많은 양의 코드가 필요할 때 유용합니다
4) 운영 체제의 특별한 지원이 필요하지 않습니다
- 프로그램 설계를 통해 구현됩니다.
- OS는 동적 로딩을 구현하기 위해 라이브러리를 제공함으로써 도움을 줄 수 있습니다
<Dynamic Linking(동적연결)>
1) 정적 연결(Static linking) –
프로세스가 메인메모리에 로드될 때 라이브러리와 프로그램을 컴바인시키는 것
단점:
같은 코드가 여러개 존재(메모리 많이 잡아먹음),
라이브러리가 변경될 경우 프로세스마다 새로운 버전의 라이브러리와 다시 컴바인 시켜야함
2) 동적 연결(Dynamic Linking) –
- 프로그램이 실행될 때 필요한 라이브러리와 결합됩니다.
- 동적 연결 시스템은
공유 라이브러리(shared libraries - dynamic linking labaries(dll))라고도 알려져 있습니다.
stub의 역할
작은 코드 조각인 스텁이 메모리에 상주하는 라이브러리 루틴을 찾습니다.
스텁은 자신을 찾은 루틴의 주소로 대체하고, 해당 루틴을 실행합니다.
운영체제 도움필요
1) 프로세스의 외부공간에 라이브러리가 존재하는 지 체크해주기 위해 운영체제 필요
2) 여러개의 프로세스가 같은 라이브러리를 공유하도록 운영체제 필요
3) 필요한 루틴이 현재 메모리 주소 공간에 없다면, 운영체제가 이를 메모리에 추가
장점:
하나의 메인메모리에 로드된 라이브러리를 여러개의 프로세스들이 공유할 수 있다.
라이브러리가 새로운 버전으로 바뀌면 바뀐 버전을 프로세스들이 쉽게 업데이트 할 수 있다.
(각각의 프로세스가 필요한 버전 넘버를 명시해야함)
라이브러리 루틴이란?
특정 기능을 수행하는 코드 단위
ex)printf
- 동적 적재(Dynamic loading)에서는 적재를 실행 시까지 미룬 것이고
동적 연결은 연결을 실행 시기까지 미루는 것이다.
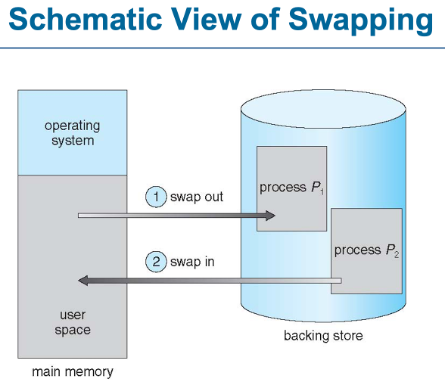
Swapping
프로세스가 메인메모리의 크기보다 클 때 디스크에 저장된 프로세스의 일부를 조금씩 메인메모리로 들고와 실행하는 것
Backing store(백업 저장소):
모든 사용자에 대한 메모리 이미지의 복사본을 저장할 수 있을 만큼 큰 빠른 디스크입니다.
이 디스크는 메모리 이미지에 직접 접근할 수 있어야 합니다.
Roll out, roll in
우선순위 기반 스케줄링 알고리즘에서 사용되는 스와핑 방식입니다.
우선순위가 낮은 프로세스를 스와핑 아웃하여 우선순위가 높은 프로세스를 메모리에 로드하고 실행합니다.
전송 시간:
스와핑 시간의 주요 부분은 전송 시간입니다.
총 전송 시간은 스와핑되는 메모리 양에 비례합니다.
준비 큐:
시스템은 디스크에 메모리 이미지를 가진 실행 준비가 된 프로세스들의 준비 큐(ready queue)를 유지합니다.
<스왑된 프로세스가 동일한 물리적 주소로 스왑 인될 필요가 있는가?>
-주소 바인딩 방식에 따라 다릅니다.
많은 시스템(예: UNIX, Linux, Windows)에서 수정된 스왑 방식이 사용됩니다.
-스왑은 일반적으로 비활성화되어 있습니다.
-할당된 메모리가 임계값을 초과하면 스왑이 시작됩니다.
-메모리 수요가 임계값 이하로 줄어들면 다시 비활성화됩니다.
<Swapping의 문맥교환(context switch)시간>
다음 프로세스가 메모리에 없는 경우:
현재 프로세스를 swap out 하고 목표 프로세스를 swap out해야 합니다.
이로 인해 문맥 전환 시간(단점)이 매우 길어질 수 있습니다.
- request_memory()와 release_memory() 함수를 사용하여 메모리 사용을 관리
ex)
100MB 크기의 프로세스를 하드 디스크로 스왑하는 경우, 전송 속도가 50MB/초라면:
스왑 아웃 시간: 2000ms (2초)
동일한 크기의 프로세스를 스왑 인하는 시간: 2000ms (2초)
총 문맥 전환 시간: 4000ms (4초)
문맥 전환 시간 줄이기:
swap하는 메모리 크기를 줄이면 문맥교환 시간을 줄일 수 있습니다.
일정 조건에만 swap한다?
<swapping의 제약조건>
대기 중인 입출력(I/O) 작업이 있는 경우(Pending I/O):
swap out할 수 없습니다. 그렇지 않으면 I/O 작업이 잘못된 프로세스에 발생할 수 있습니다.
그래서 속도가 느려짐
대안으로 I/O를 항상 커널 버퍼으로 전송한 후 swap 후에 I/O 장치로 전달하는 경우:
이를 더블 버퍼링(double buffering)이라고 하며, 추가적인 오버헤드가 발생합니다.
즉, 2개의 버퍼를 사용해 i/o데이터를 보호하는 것
<Contiguous Allocation(연속할당)>
프로세스에게 연속적인 메모리 공간을 주는 방법 2가지
1) fixed partition(고정 분할)
메인메모리를 똑같은 크기로 나누고 한 파티션에 한 프로세스만 들어가게 메모리를 할당하는 방법
한 파티션에서 남는 공간은 못 쓰는 공간이 됨
프로세스가 차지하고 남는 공간을 내부 단편화(internal fragmentation)라고 함
paging에서도 발생
2) 가변 분할(variable partition)
각각의 프로세스가 필요한 크기만큼 메모리를 할당하는 방법
프로세스가 사용 후 빠진 공간에 다른 프로세스가 못 들어가 남는 공간을 외부 단편화(external fragmentation)이라고 함
둘 다 프로세스와 피티션의 개수는 똑같음,
즉 멀티프로그래밍의 개수는 파티션의 개수에 따라 결정됨
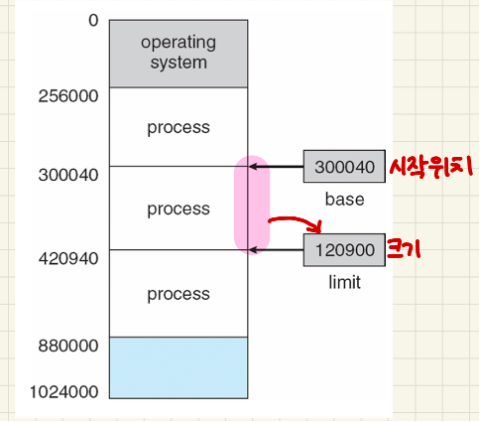
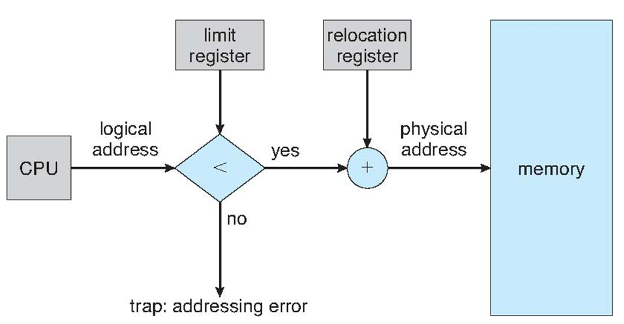
주 메모리는 보통 두 개의 파티션으로 나뉩니다:
운영 체제는 보통 낮은 메모리에 위치합니다.
사용자 프로세스는 높은 메모리에 위치합니다.
베이스 레지스터에는 가장 작은 물리적 주소 값이 들어 있습니다.
리미트 레지스터에는 논리 주소의 범위가 들어 있으며,
각 논리 주소는 리미트 레지스터보다 작아야 합니다.
MMU(메모리 관리 장치)는 논리 주소를 동적으로 매핑합니다.
이렇게 하면 커널 코드가 일시적(transient )이거나 커널 크기가 변경되는 등의 작업을 허용할 수 있습니다.
< Relocation and Limit Registers의 하드웨어 지원>
<Multiple-partition allocation(다중 파티션 할당)>
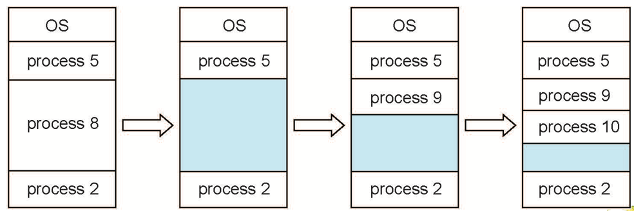
가변 분할:
프로세스가 필요한 만큼한 할당되기 때문에 프로세스가 종료되면 빈 공간이 생김
홀(hole) – 프로세스와 프로세스 사이에 빈 공간
이때 홀이 어떤 프로세스도 들어가지 못 할 정도로 작으면 external fragment(외부 단편화) 발생
프로세스가 도착하면, 해당 프로세스를 수용할 수 있을 만큼 큰 홀에서 메모리를 할당받습니다.
프로세스가 종료되면, 해당 파티션이 해제되고 인접한 자유 파티션들이 결합됩니다.
운영 체제는 다음 정보를 유지 관리합니다:
a) 할당된 파티션(allocated partitions)
b) 자유 파티션(홀)(free partitions)
<동적 저장 할당(Dynamic Storage-Allocation )>
1)First-fit(최초 적합): 이 프로세스가 들어갈 수 있는 첫 번째 큰 공간에 할당
2)Best-fit(최적 적합): 이 프로세스가 들어갔을 때 남는 공간이 가장 적은 곳에 할당
3)Worst-fit: 이 프로세스가 들어갔을 때 남는 공간이 가장 큰 공간에 할당
속도는 First-fit이 가장 빠름 , but 프로세스의 메모리 할당이 한 쪽으로 쏠리는 경향이 있음
<Fragmentation(단편화)>
내부 단편화(Internal Fragmentation)
파티션 안의 못 쓰는 공간, 주로 고정 분할에서 발생
외부 단편화(External Fragmentation)
프로세스 사이의 못 쓰는 공간, 주로 가변 분할에서 발생
최초 적합(First fit) 분석에 따르면, N 블록이 할당된 경우 0.5 N 블록이 단편화로 손실됨
전체 메모리 공간의 1/3이 사용되지 못한다. -> 50% 규칙
외부 단편화를 줄이는 법: 압축(compaction) 또는 수집(collection)
못 쓰는 공간이 남아있으면 쓰는 부분을 한 쪽으로 밀고 안 쓰는 부분을 다른 한 쪽으로 밀어 모아두는 것 (즉, 못 쓰는 공간을 한 곳으로 모아두는 것)
주의 해야할 점
1) 프로세스의 주소가 바뀌기 때문에 주소 바인딩이 실행시간에 일어나지 않으면 압축할 수 없음
2) Pending I/O: 프로세스가 입출력 작업을 수행 중에는os 버퍼에 데이터를 넣고 주소가 결정되면 그 곳에 copy
segmentation
프로세스의 각 요소를 나눠서 메인메모리의 비연속적인 공간에 저장하는 것
세그먼트는 다음과 같은 단위:
main program / procedure / function/ method /object /local variables, global variables /common block /stack/ symbol table /arrays
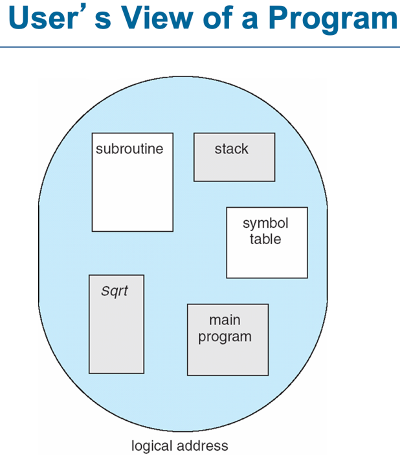
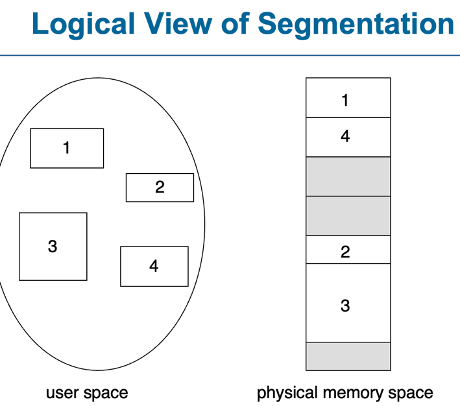
<Segmentation 구조>
논리 주소는 <세그먼트 번호, offset> 즉, 2개의 튜플(tuple)로 구성
세그먼트 테이블 – 이차원 물리 주소를 매핑합니다.
베이스(base) – 세그먼트가 메모리에 위치한 시작 물리 주소를 포함합니다.
리미트(limit) – 세그먼트의 길이를 지정합니다.
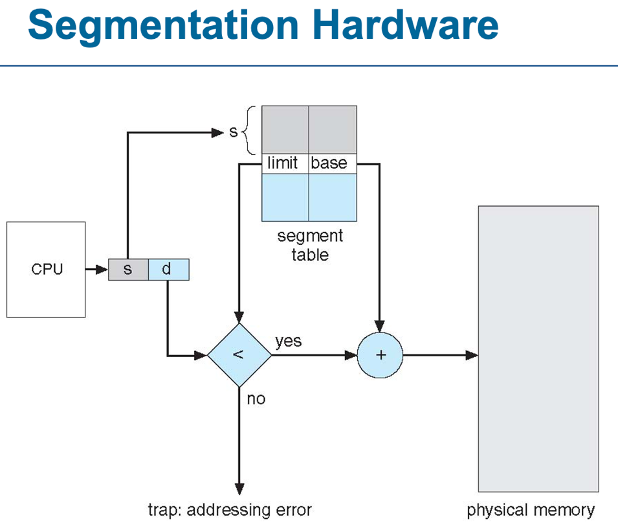
segment-table base register (STBR):메모리 내 세그먼트 테이블의 위치
segment-table length register (STLR):프로그램이 사용하는 세그먼트의 수
(세그먼트 번호 s가 유효하려면 s < STLR 이어야 함)
cpu가 instruction을 가지고 오기 위해서는 2번의 메인 메모리 엑세스가 필요하다
1) segment table로 가서 해당 offset이 segment 범위 안에 있는 지 체크한다.
없으면 에러 발생(다른 공간의 정보를 엑세스 하려고 한 것이라서)
2) offset에다가 base address를 더해 물리주소를 구한다.
segmentation를 하는 가장 큰 이유는 보호(protection), 공유(sharing)
1) 보호가 되는 부분들은 같은 segment안에 같은 protection(보호, 권한?) 설정 가능
2) 공유가 되는 라이브러리를 한 segment 안에 넣을 수 있음
(관리 편리)
세그먼트 테이블의 각 항목과 관련된 보호 기능:
유효화 비트(validation bit) = 0 <--잘못된 세그먼트
읽기/쓰기/실행 권한
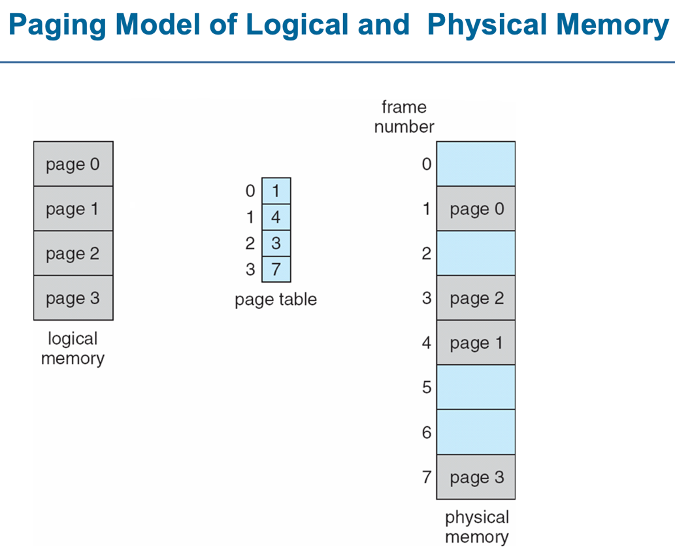
Paging
외부 단편화의 해결방법으로 ,
메모리 공간을 일정한 페이지 단위로 나눠 주소를 불연속적으로 할당하는 메모리 관리 구조
segmentation
외부 단편화 발생,
길이가 달라서 table 안에 시작주소와 limit를 가져야 하기 때문에 메모리를 더 차지함
paging은
외부 단편화 발생안 함,
주소 결정 쉽다.
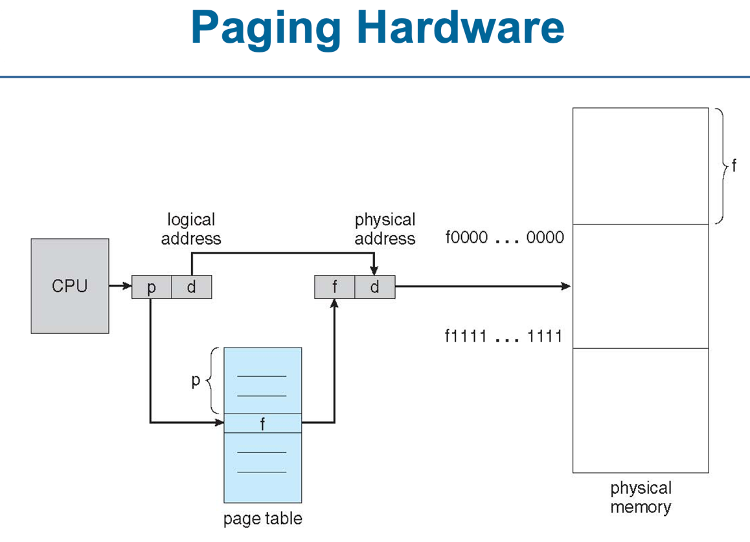
page(페이지): 가상메모리를 일정한 크기로 나눈 블록
frame(프레임) : 물리메모리를 일정한 크기로 나눈 블록
페이지와 프레임의 크기는 같음
-> 프레임에 대응되는 페이지 찾기 쉬움
논리 주소를 물리주소로 바꿔서 데이터를 가져오기 위해서
2번의 메인 메모리 access필요
1)page table를 이용해 물리주소 파악
2)해당 물리주소로 부터 데이터 가져오기
주소 전환 체계
페이지와 프레임의 대응도는 '페이지 테이블'에 저장되어 있다.
페이지 테이블:
context switch가 일어날때마다 내용 바뀌어야 함
페이지 번호(p) – 페이지 테이블의 인덱스
페이지 오프셋(d) – 페이지 내의 특정 위치를 결정

paging
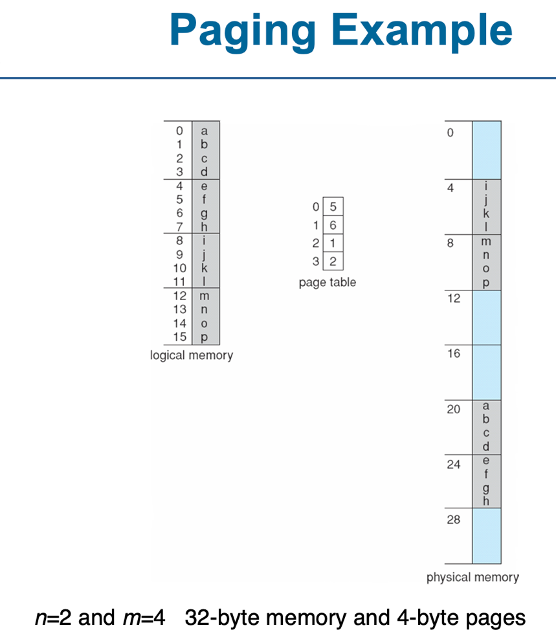
내부 단편화 계산
페이지 크기: 2,048 바이트
프로세스 크기: 72,766 바이트인 경우
72,766 ÷ 2,048 = 35.5 페이지, 따라서 36 페이지가 필요합니다.
(35 페이지는 전체 2,048 바이트로 채워지고, 나머지 1 페이지는 일부만 사용됩니다)
마지막 페이지에서 남는 공간: 2,048 바이트 - 1,086 바이트 = 962 바이트
따라서 내부 단편화는 962바이트
최악의 경우 단편화 = 페이지 크기 – 1 바이트
평균적으로 단편화는 = 1/2 페이지 크기(페이지 크기의 절반)
작은 페이지 크기:
장점: 단편화를 줄임
단점: 페이지 테이블 항목이 많아져 추가적인 메모리 오버헤드가 발생
입출력 속도 떨어짐(많은 i/o를 발생시키게 됨)
큰 페이지 크기:
장점:
페이지 테이블 항목을 줄여 메모리 오버헤드를 줄임,
입출력 속도 빨라짐(적은 i/o)발생
단점:
단편화가 더 많이 발생
free-frame 리스트가 있으면 각각의 프로세스 페이지를 메모리로 옮기는 데 시간 절약됨
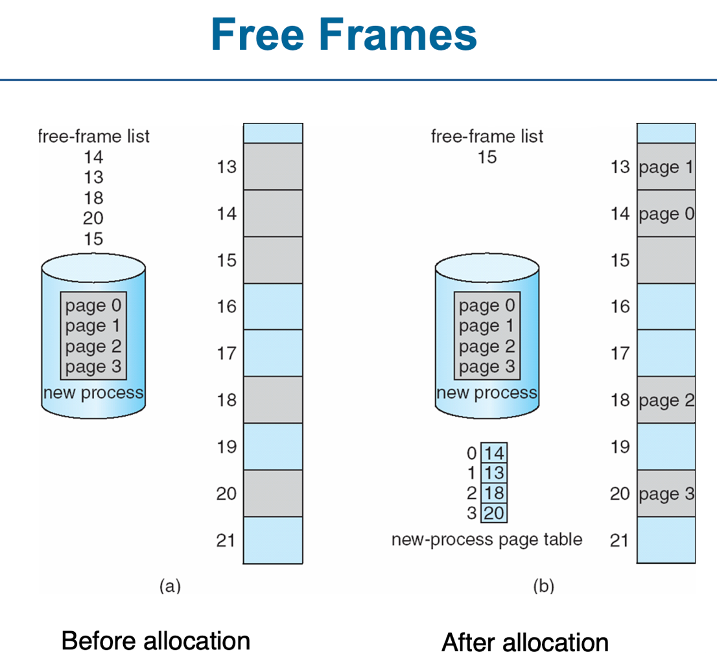
Page table
메인 메모리에 저장되어있음
Page-table base register (PTBR): 페이지 테이블의 위치
Page-table length register (PTLR):는 페이지의 수
데이터에 접근하기위해 두 번의 메모리 접근이 필요
1) 페이지 테이블에 접근해 물리주소 알기
2) 물리주소에 접근해 실제 데이터나 명령어를 가져옴
성능저하 발생 가능
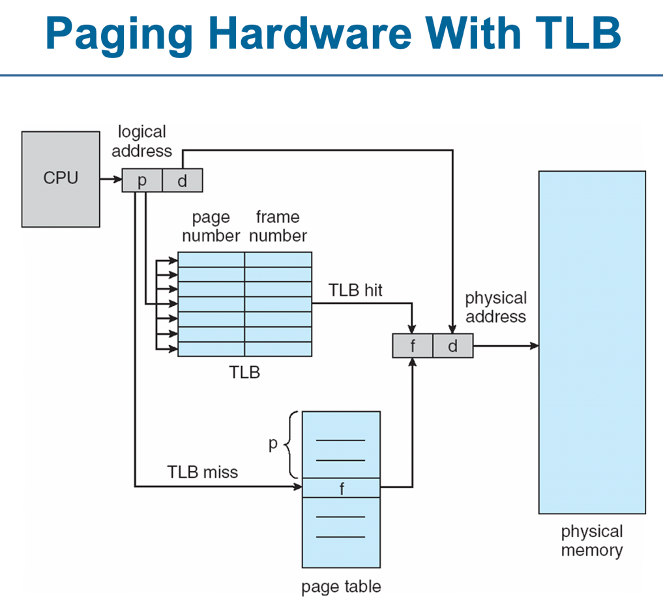
이 문제를 해결하기 위해 'TLB (Translation Look-aside Buffer)' 사용
논리주소를 물리주소로 변환하는 속도를 높이기 위한 page table cash
TLB는 페이지 테이블의 일부를 빠르게 검색하여 페이지 번호를 프레임 번호로 변환합니다.
associative memory라고도함
메모리 접근 속도를 향상, 두 번의 메모리 접근을 하나로 줄여 시스템 성능을 향상
context switch시 마다 TLB를 바꾸지 않기 위해서
TLB 각 항목에 주소공간 식별자address-space identifiers (ASIDs)지정
TLB 미스 시 값이 다음 번에 더 빠른 액세스를 위해 TLB에 로드됩니다
TLB는 사이즈가 작아서 자주 교체해야함
최근 사용된 항목, 중요한 코드 등은 wired-down 고정해둠
TLB – 병렬 검색
주소번역(p,d)
p가 TLB에 있는 경우(TLB hit) 프레임 번호를 가져오고
그렇지 않으면(TLB miss) 메모리의 페이지 테이블에서 프레임 넘버 가져온다.