
🚩 Pytorch functions
- numpy의 np.array와 torch의 tensor는 비슷하다.
- numpy의 문법이 pytorch에서 그대로 적용된다.
- pytorch의 tensor는 GPU에 올려서 사용 가능
x_data.device: 현재 데이터가 어디에 올라와있는지 확인
🍏 Tensor handling
- view: reshape()와 동일하게 tensor의 shape를 변환
- squeeze: 차원의 개수가 1인 차원을 삭제 (압축)
- unsqueeze: 차원의 개수가 1인 차원을 추가
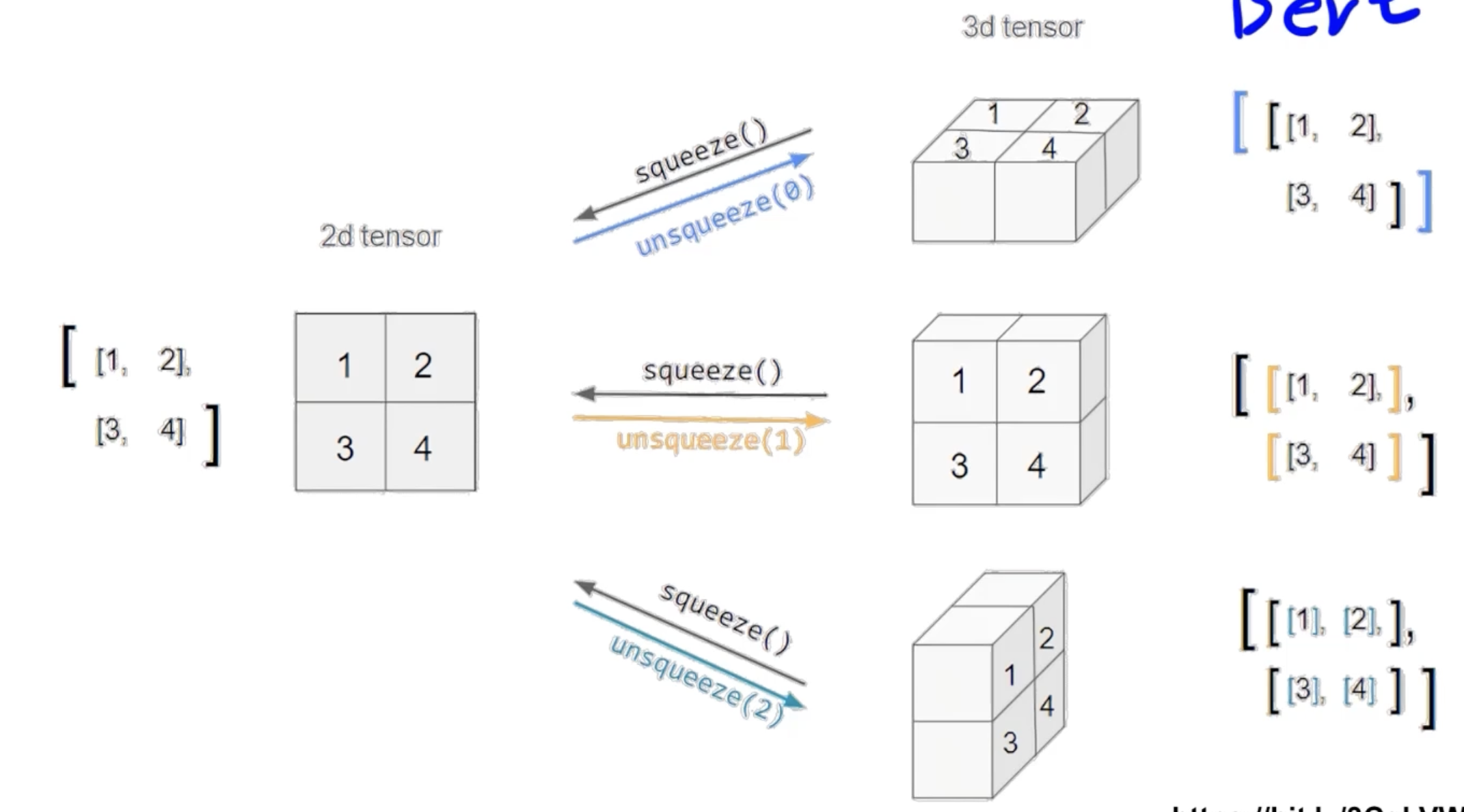
- unsqueeze(0): index 0에 1 추가 // 2d tensor(2x2) → 3d tensor(1x2x2)
- unsqueeze(1): index 1에 1 추가 // 2d tensor(2x2) → 3d tensor(2x1x2)
🍏 Tensor operation
- 행렬곱셈 :
mmormatmul함수 사용 (행렬 간의 연산) - 행렬내적 :
dot함수 사용 (벡터 간의 연산)

- 행렬 간의 사이즈가 맞지 않기 때문에 mm을 실행하면 에러가 뜬다.
- 이때,
matmul를 사용하면 자동으로broadcasting이 일어나기 때문에 b를 자동으로 (3,1)로 맞춰 계산하게 된다. 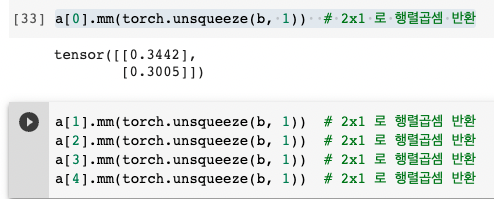
matmul은 이런 꼴과 같다.
🍏 Tensor operation for ML/DL formula
- nn.functional 모듈을 통해 다양한 수식 변환을 지원
import torch
import torch.nn.functional as F
tensor = torch.FloatTensor([0.5, 0.7, 0.1])
h_tensor = F.softmax(tensor, dim=0)구글 코랩 .ipynb 파일 ; https://drive.google.com/open?id=1nlT2Fq-vURe5aywOZ0VHuqa5D0tydL2u
🍏 index_select
x = torch.randn(3, 4)
# tensor([[ 0.1427, 0.0231, -0.5414, -1.0009],
# [-0.4664, 0.2647, -0.1228, -1.1068],
# [-1.1734, -0.6571, 0.7230, -0.6004]])
indices = torch.tensor([0, 2])
torch.index_select(x, 0, indices)
# tensor([[ 0.1427, 0.0231, -0.5414, -1.0009],
# [-1.1734, -0.6571, 0.7230, -0.6004]])🍏 gather
- tensor에서 인덱스를 기준으로 특정 값들을 추출하기 위해 사용
- torch.gather([tensor],[dim],[추출할 tensor의 모양 및 인덱스])
import torch
A = torch.Tensor([[1, 2],
[3, 4]])
indices = torch.tensor([[0], # A의 0행, 0열
[1]]) # A의 1행 1열
output = torch.gather(A, 1, indices).flatten()
>>> tensor([1., 4.])
- 1차원(행 차원) 기준으로 indices를 보면,
- 0행의 인덱스 0 = 1 // 1행의 인덱스 1 = 4
🍏 other functions
torch.numel: Returns the total number of elements in the input tensortorch.chunk: 주어진 텐서를 원하는 조각(chunk)만큼 나누기
단, 원하는 조각보다 적은 조각으로 나누어질 수도 있다. (넘치는 건 안되니까!)
🍏 dim이 뭐에요?
- axis와 dim은 같은 개념으로 쓰인다.
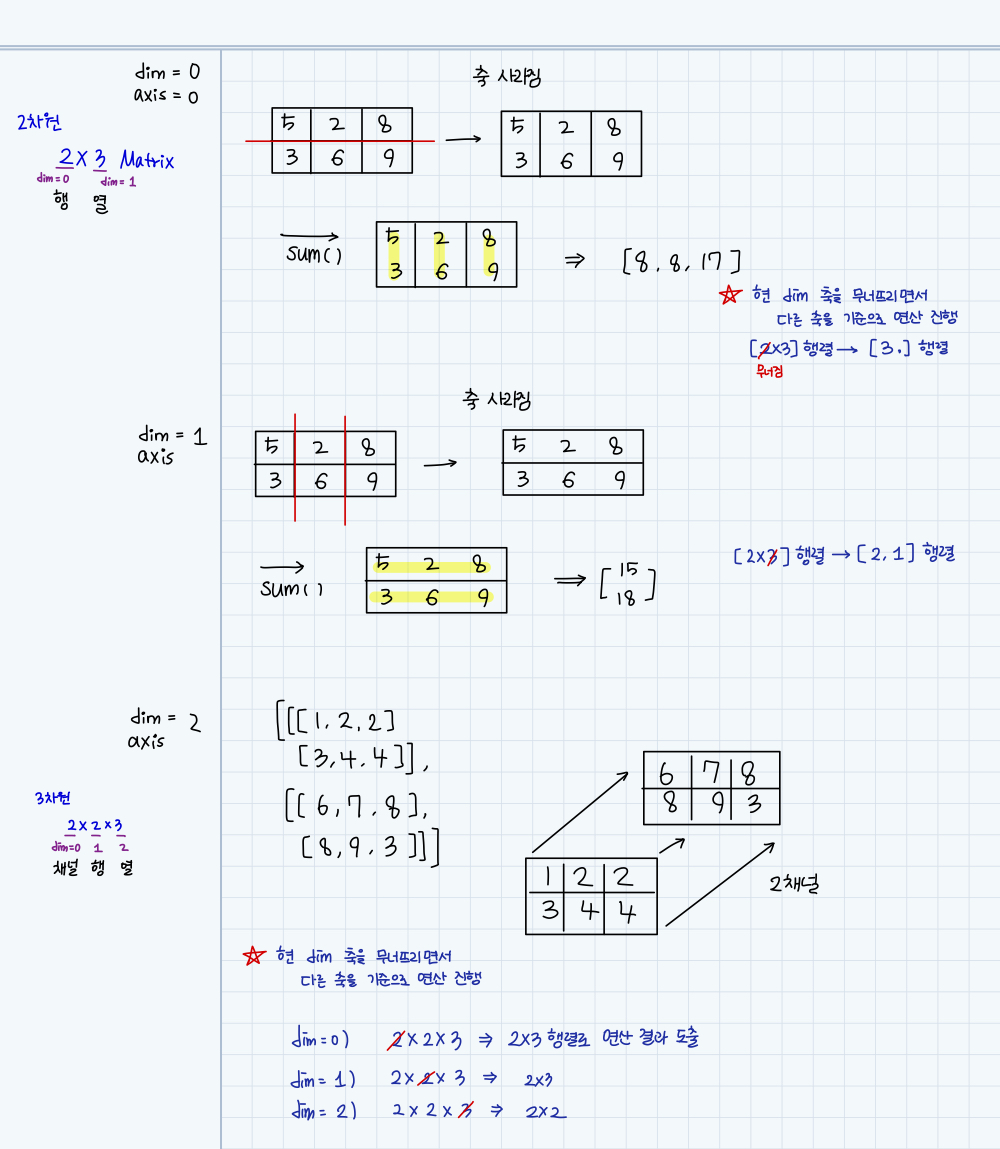
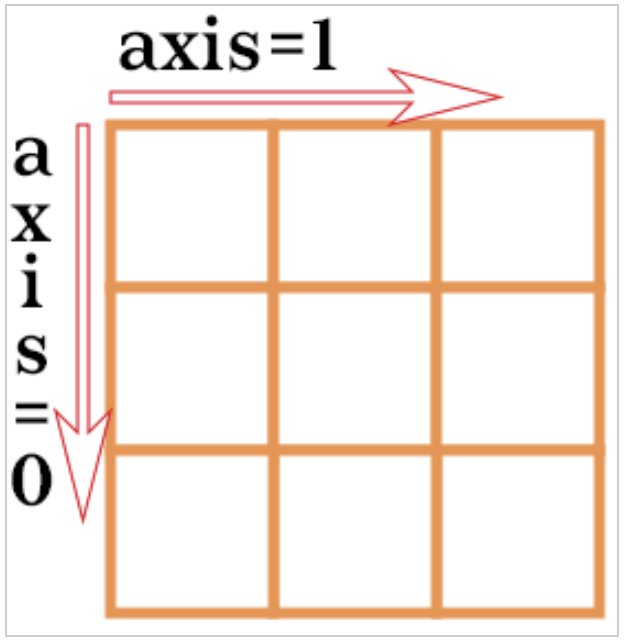
axis = 0 (행) / 행 축으로 자르기 (↓ 방향)
axis = 1 (열) / 열 축으로 자르기 (→ 방향)
🍏 torch.swapdims

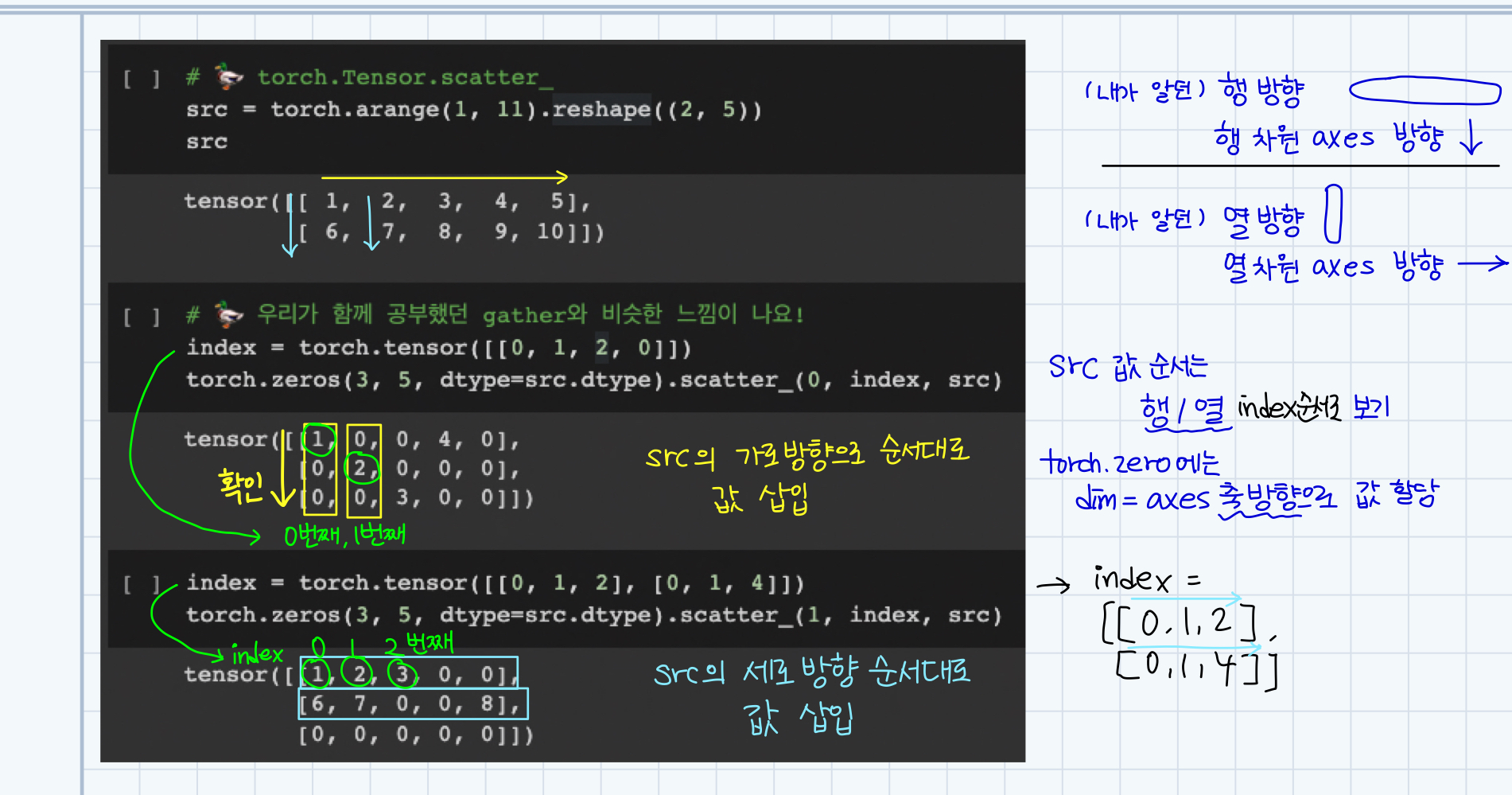
🍏 torch.Tensor.scatter_
- scatter 이해하기
🍏 torch의 math operations
🚩 Autograd & optimizer

x = torch.randn(5, 7) # (5, 7) 행렬의 난수값 텐서
# 데이터가 5개, feature가 7개라는 뜻
layer = MyLiner(7, 12) # output의 size는 (5, 12)가 된다.
- input 벡터 (3, 7) 행렬 → (3, 5) 행렬로 output을 뽑고 싶다면?
- input에 (7, 5) 행렬을 곱해주면 된다! ( = weight )
in_features: 7
out_features: 5
- input에 (7, 5) 행렬을 곱해주면 된다! ( = weight )
- 맨 아래
return x @ self.weights + self.bias는
예측값 y라고 생각하면 된다.
🍏 backward
- layer에 있는 Parameter들의 미분을 수행한다.
- forward의 결과값 (model의 output = 예측값)과 실제값 간의 차이(Loss)에 대해 미분을 수행
- 해당 값으로 parameter 업데이트
for epoch in range(epochs):
# clear gradient buffers because we don't want any gradient from previous epoch to carry forward
optimizer.zero_grad()
# get output from the model, given the outputs
outputs = model(inputs)
# get loss for the predicted output
loss = criterion(outputs, labels) # 예측값과 실제값의 loss를 구함
print(loss)
# get gradients w, r, t to parameters
# (w, r, t) -> MSE loss function's parameters
loss.backward() # loss를 w에 대해 미분, r에 대해 미분, ...
# update parameters
optimizer.step()✍🏻 회고
어려웠던 부분:
- dimension (차원) 에 대한 개념이 헷갈렸고 어렵게 다가왔다.
torch.swapdims와gather함수,scatter_함수가 쉽게 이해되지 않았다.나의 노력!
- 여러 블로그 정리를 보면서 내 나름대로의 이해를 하고 그림 그려가며 정리를 했다. 시간이 꽤 오래 걸렸지만 이해는 확실하게 한 것 같다.

배우고 싶은게 많은 개발자📚