
🚩 Word Embedding
🟨 Bag-of-Words Representation
- Constructing the vocabulary containing unique words (중복 제거)
{ "John really really loves this movie", "Jane really likes this song"}
--> {John,really,loves,this,movie,Jane,likes,song}
- Encoding unique words to one-hot vectors
- A sentence / document can be represented as the sum of one-hot vectors


→ 이러한 bag-of-words 형태의 문서를 정해진 카테고리나 클래스로 분류할 수 있는 대표적 방법 < NaiveBayes Classifier for Document Classification >
🍏 NaiveBayes Classifier

- CV (class) 에서
task단어가 나타날 확률 :- 14개의 unique 단어 중 task는 1번 나타났으므로
=> 각 단어의 특정 class에서의 등장 횟수- document 5(test용)에서 cv라고 판단될 확률 : =
=> 고유한 클래스 개수
- test document = "Classification task uses transformer"


🍏 실습 1
- 문장 토큰화하기 (단어 단위)
from konlpy import tag
from tqdm import tqdm
tokenizer = tag.Okt() # KoNLPy에서 제공하는 Twitter(Okt) 토큰화기 사용하여 토큰화하기
def make_tokenized(data):
tokenized = [] # 단어 단위로 나뉜 리뷰 데이터.
for sent in tqdm(data): # tqdm을 통해 데이터 진행도 표시
tokens = tokenizer.morphs(sent)
tokenized.append(tokens)
return tokenized
train_tokenized = make_tokenized(train_data)
test_tokenized = make_tokenized(test_data)
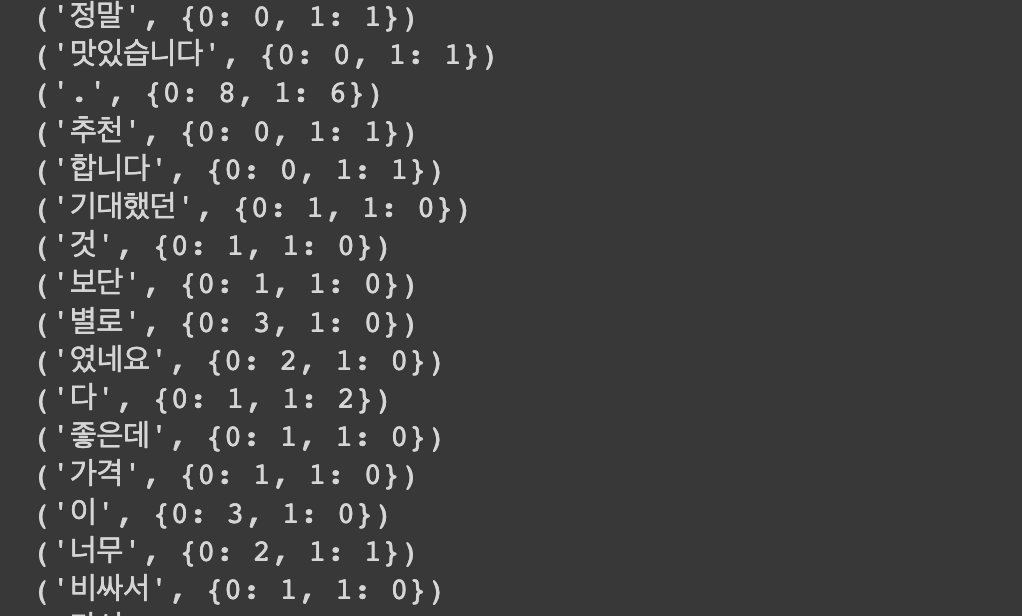
sent: 기대했던 것보단 별로였네요. [문장 그 자체]
tokens: ['기대했던', '것', '보단', '별로', '였네요', '.']
- 토큰화된 단어들을 숫자로 변환하기
from collections import Counter, defaultdict
from itertools import chain
import math
i2w = list(set(chain.from_iterable(train_tokenized))) # list 원소들을 모두 합쳐 iter 형태로
w2i = {w: i for i, w in enumerate(i2w)} # Key: 단어, Value: 단어의 index
# ----> w2i : unique한 토큰들에 index 매겨주기- 고유 클래스 개수 세기 (set_priors) 및 각 단어의 특정 class에서의 등장 횟수 (set_likelihoods)
'''
self.k: Smoothing을 위한 상수.
self.w2i: 사전에 구한 vocab.
self.priors: 각 class의 prior 확률.
self.likelihoods: 각 token의 특정 class 조건 내에서의 likelihood.
'''
def set_priors(self, train_labels):
class_counts = Counter(train_labels) # 클래스가 몇개 존재하는지. (원소가 몇개씩 존재하는지 count해서 dict 형태로)
for label, count in class_counts.items():
self.priors[label] = class_counts[label] / len(train_labels)
def set_likelihoods(self, train_tokenized, train_labels):
token_dists = {} # 각 단어의 특정 class 조건 하에서의 등장 횟수.
class_counts = defaultdict(int) # 특정 class에서 등장한 모든 단어의 등장 횟수.
for tokens, label in zip(train_tokenized, tqdm(train_labels)):
count = 0
for token in tokens:
if token in self.w2i: # 학습 데이터로 구축한 vocab에 있는 token만 고려.
if token not in token_dists: # 10개의 훈련 데이터의 각 토큰들을 (긍정/부정) 클래스로 나누어 점수 매겨주기(?) --> 이런 단어는 긍정이다. 부정이다 단어 라벨링이라고 생각하자.
token_dists[token] = {0:0, 1:0}
token_dists[token][label] += 1
count += 1
class_counts[label] += count
for token, dist in tqdm(token_dists.items()):
if token not in self.likelihoods:
self.likelihoods[token] = {
0:(token_dists[token][0] + self.k) / (class_counts[0] + len(self.w2i)*self.k),
1:(token_dists[token][1] + self.k) / (class_counts[1] + len(self.w2i)*self.k),
}
↑ token_dists[token]

↑ likelihoods[token]
- test 문장 4개 예측하기 (1: 긍정, 0: 부정)
def inference(self, tokens):
log_prob0 = 0.0
log_prob1 = 0.0
for token in tokens:
if token in self.likelihoods: # 학습 당시 추가했던 단어에 대해서만 고려.
log_prob0 += math.log(self.likelihoods[token][0])
log_prob1 += math.log(self.likelihoods[token][1])
# 마지막에 prior를 고려.
log_prob0 += math.log(self.priors[0])
log_prob1 += math.log(self.priors[1])
if log_prob0 >= log_prob1:
return 0
else:
return 1
-----------------------------------------------------------
# 예측한 결과 뽑기
preds = []
for test_tokens in tqdm(test_tokenized):
pred = classifier.inference(test_tokens)
preds.append(pred)
print(preds)
>>> [1, 0, 1, 0]🍏 실습 2
- PyKoSpacing (띄어쓰기 교정)
from pykospacing import Spacing
spacing = Spacing()
kospacing_sent = spacing(new_sent)
>>>
new_sent: "환영합니다!자연어처리수업은재미있게듣고계신가요?"
정답 문장: "환영합니다! 자연어 처리 수업은 재미있게 듣고 계신가요?"
띄어쓰기 교정 후 (kospacing_sent): "환영합니다! 자연어 처리 수업은 재미있게 듣고 계신 가요?"- Hanspell (맞춤법 교정)
from hanspell import spell_checker
sent = "맞춤법 틀리면 외 않되? 쓰고싶은대로쓰면돼지 "
spelled_sent = spell_checker.check(sent)
hanspell_sent = spelled_sent.checked
print(hanspell_sent)
>>> 맞춤법 틀리면 왜 안돼? 쓰고 싶은 대로 쓰면 되지
- 정규 표현식 (Regular Expression) - 수많은 단어 중 찾고 싶은 단어가 있을 때
# -s, -es 로 끝나는 복수 형태의 단어를 찾고 싶을 때
import re
pattern = 'human'
for match in re.finditer(pattern, text):
print(match.span()) # (시작 index, 끝 index + 1)을 반환합니다.
>>>
(106, 111)
(216, 221)
(343, 348)
(637, 642)
(880, 885)
(926, 931)
(1231, 1236)
# 역슬래시 \ 활용하기
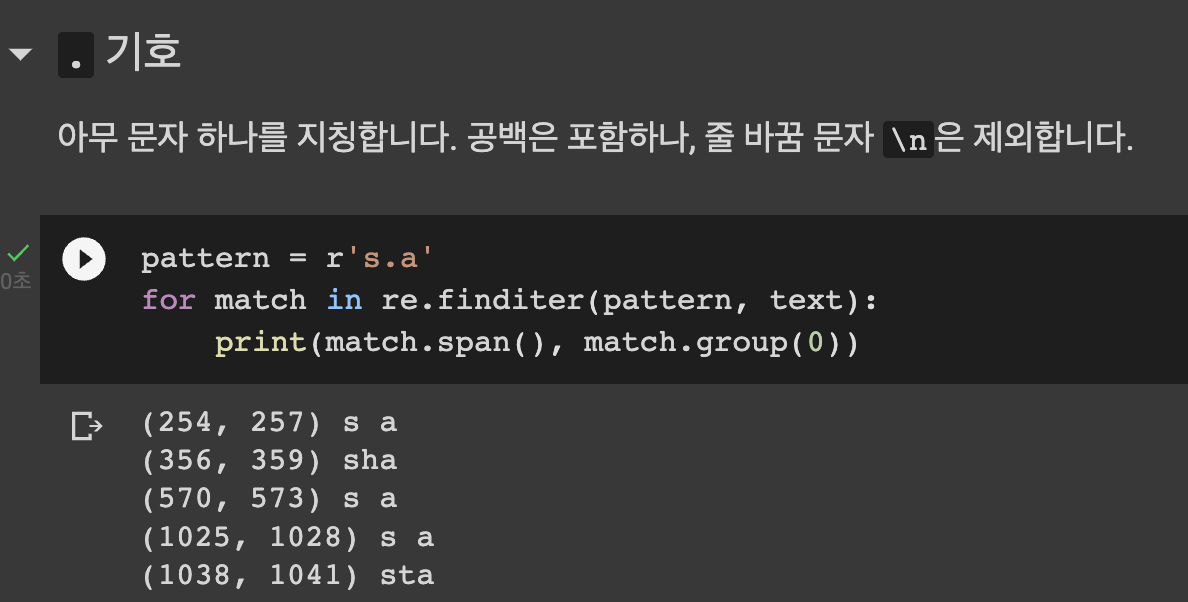
pattern = r's\wa' # s_a 형태의 문자 패턴 뽑혀나옴 # \는 python에서 escape 문자로 쓰이기 때문에 정규표현식을 올바르게 사용하기 위해선 r''형태의 raw string을 사용해야합니다.
for match in re.finditer(pattern, text):
print(match.span(), match.group(0)) # (시작 index, 끝 index + 1)과 들어맞는 패턴을 출력합니다.

find 함수
pattern = 'human'
start = -1
indices = []
while True:
start = text.find(pattern, start+1)
if start == -1:
break
indices.append(start) # human이 나오는 index들 반환🚩 Word2Vec
- 주변 단어 벡터 간의 유사도 반영
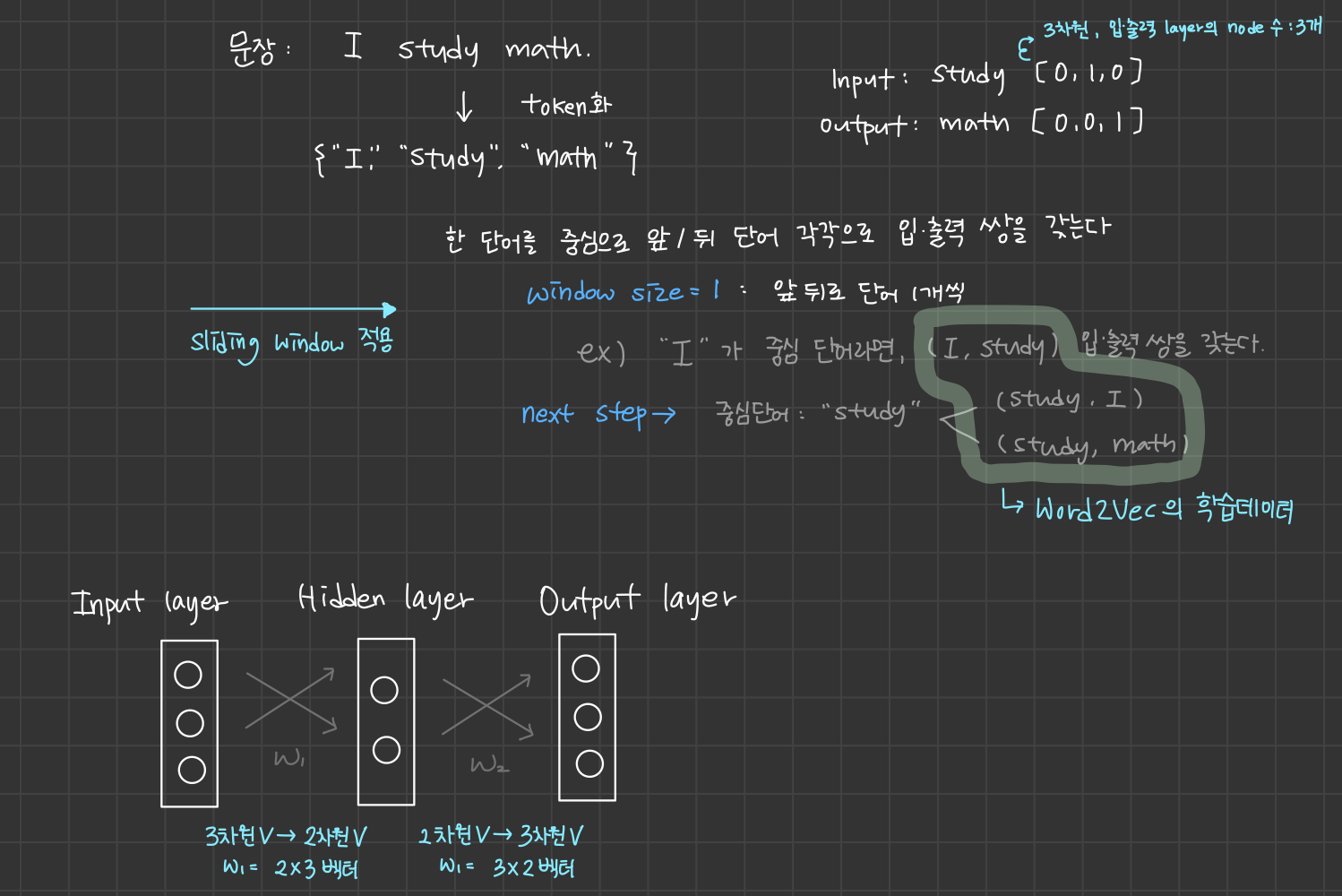
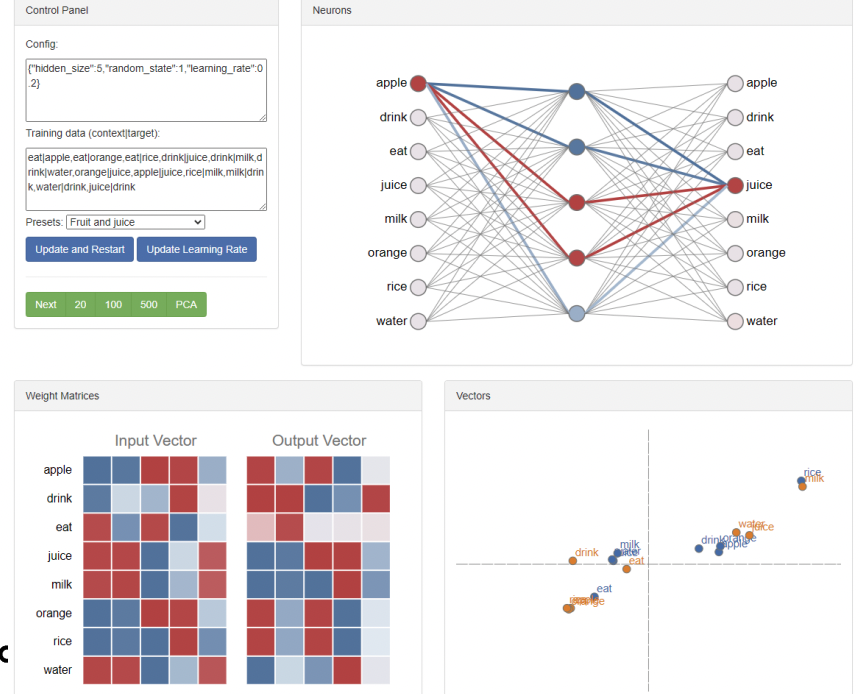
-
Input Vector[apple] 과 Input Vector[orange] 는 유사한 형태를 보인다.
-
Input Vector[milk], Input Vector[juice], Input Vector[water], Output Vector[drink] 4개가 유사한 형태를 보인다.
-
어느 것을 Word Embedding 의
최종 Output으로 설정할까?
--> 2개의 벡터 다 상관 없지만, 대부분 입력 word에 해당하는 Embedding Vector (Input Vector)로 사용한다.
Word2Vec은 각 단어들 간의 의미론적인 관계를 파악하여 결과 단어를 유추할 수 있다.
🚩 GloVe
-
Word2Vec은 특정 입출력 단어 쌍이 학습 dataset에 자주 등장한 경우, 그 쌍은 여러 번 학습이 됨으로써 두 내적 값이 점점 커지게 하는 학습 방법
-
GloVe는 학습 dataset에서 단어 쌍이 등장한 횟수를 미리 계산하고 이에 log값을 취해 두 단어 간의 내적에서 빼준다. --> 중복 계산 방지
@ Word2Vec에 비해 빠르고 적은 데이터에서도 잘 동작한다.
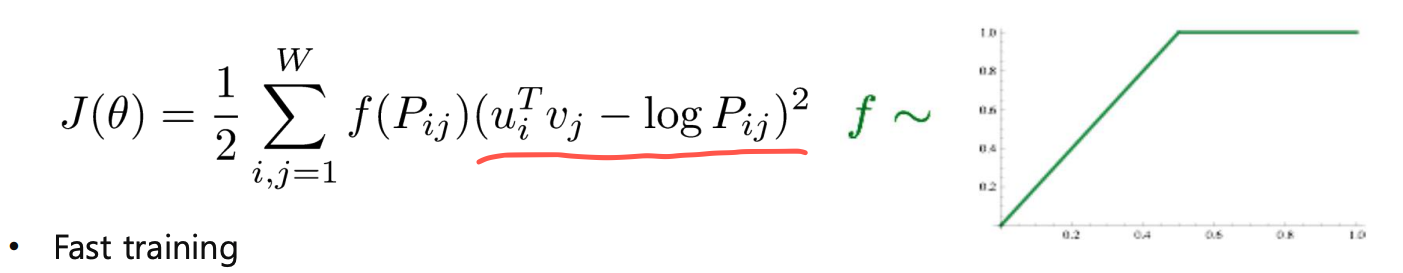
🍏 실습 1
train_tokenized: 주어진 학습 데이터 토큰화한 리스트i2w; unique 단어 추출 리스트화w2i: 각 unique 단어들에 index 번호 부여CBOWDataset —> 중심 단어 기준으로 양옆 입출력 단어쌍 x에 삽입
token_ids= 각 문장에 존재하는 unique 단어들의 토큰 id 리스트 (각 문장별로 단어개수가 다르다)self.x= 각 문장의 token_ids에서 중심 단어를 잡고 양옆 입출력 단어쌍을 만들어(양옆window_size만큼 포함), x에 추가 (각 문장들 반복해서 모든 문장 수행됨)self.y= 각 중심 단어들부터 시작한 id 리스트

🍏 실습 2 (LaBSE)
다국어 임베딩 (다른 언어의 2 문장 사이 유사도 확률 계산)
LaBSE (language-agnostic BERT Sentence Embedding)
🍏 과제 1
- 정규표현식 re를 이용해 토큰화하기
\s+: 모든 공백 제거 (큰 공백도 제거 가능)
|: 그리고
[.,!?]: [ ] 안에 있는 기호들 구분해서 split
n\’t: (not의 준말 - 과제 조건) 고려하여 split (token 처리)
\w+: 문자 또는 숫자가 1개 이상인 경우
\’\w+: (’s, ‘m) 등 Apostrophe 뒤의 글자 붙인것도 개별 토큰화 (과제 조건)코드 —> tokens = re.split(r'\s+|([.,!?]|n\'t|\'\w+)',sentence)
이 때, None을 없애려면 괄호 ()를 \s+부터 묶어주면 된다. (공백으로 바뀜)
만약r'\s+|([.,!?])|(n\'t)|(\'\w+)'이렇게 3번의 괄호를 각각 묶어주게 되면 ( ) 안의 요소들의 일치를 확인하게 된다. split이 모든 ( )를 체크해서 3번 체크! 그룹이 여러 개일 때는 다른 그룹을 체크할 때 None 발생import re re.split(r'\s+|([.,!?])|(n\'t)|(\'\w+)', "this isn't Hojun's work.") >>> OUTPUT: ['this', None, None, None, 'is', None, "n't", None, '', None, None, None, 'Hojun', None, None, "'s", '', None, None, None, 'work', '.', None, None, '']< this isn't Hojun's work. >
this 뒤의 각 3개의 ( ) 요소와 일치하는 문자가 있는지 --> 없다 (None)
isn't 는 2번째 괄호에 해당하므로 n't 기준으로 순서대로 양 옆에 None 생성
' ' 공백은 3개의 ( ) 와 일치하지 않으므로 3개의 None
Hojun's 는 3번째 괄호에 해당하므로 's 기준으로 왼쪽 2개 None 생성❓ None들 사이에
''이 왜 껴있나요?
>>
re.split을 충족하는 str이 차례대로 있을 때 단어들 사이에 공백이 있으면 ''이 생기는 것 같다.
isn't Hojun에서는n't와(공백)이 차례대로 있어서 그 사이에''이 생기고Hojun's work에서도's와(공백)이 차례대로 있어서 그사이에''이 생긴 듯.
반면에this is의(공백)양옆에는 split condition을 충족하는 단어들이 없어서 ''이 없다.❓ 왜 \s+가 공백으로 분리하는데도
''공백을 제거하지 못할까?
공백 제거를 못하는게 아니다.
re.split(pattern, str)이렇게 주어졌을 때 pattern을 한꺼번에 process 하는듯하다.
(\s+를 먼저 해결하고 ([.,!?]|n\'t|\'\w+)를 해결하는 것이 아니라, str을 읽으면서 pattern의 모든 조건을 확인하는 것 같다)
조건을 확인 후 문장 자체의 공백들을 분리하여 리스트화한다.만약 \s+로 분리되지 않고 그 공백조차 보존된다면?
# \s+ 도 괄호로 묶어주면 보존된다. re.split(r'(\s+)|([.,!?]|n\'t|\'\w+)', "this isn't Hojun's work.") >>> OUTPUT: ['this', ' ', None, 'is', None, "n't", '', ' ', None, 'Hojun', None, "'s", '', ' ', None, 'work', None, '.', '']보존된다면 문장의 단어 사이사이 공백도 같이 출력되는 것을 확인할 수 있다! 위의 질문에서 \s+가 실행이 잘 되어서 공백 출력이 안되고 분리된 것으로 확인 가능하다.
( )조건을 만족하는 단어 요소만 양옆에 공백이 있으면''이 출력되는 거라 \s+랑은 다른 부분이다.
❓ 왜 \s+가 찾는 공백은 없어지고
([.,!?]|n\'t|\'\w+)가 찾는 것들을 출력에 보존될까?
괄호 = 보존 역할print(re.split('(,)', "1,2,3,4,5")) print(re.split(',', "1,2,3,4,5")) >>> OUTPUT: ['1', ',', '2', ',', '3', ',', '4', ',', '5'] ['1', '2', '3', '4', '5']위와 같이 공백을 보존하고 싶으면 \s+대신 (s+)을 사용하면 된다.
이해에 도움 주신 이강혁 캠퍼님 감사합니다!
