
🚩 LSTM (long short-time memory)
- RNN의 time step 길이가 길어질수록 발생하는 gradient vanishing 등의 long term dependency 문제를 해결할 수 있는 LSTM
- 단기 기억을 길게 기억할 수 있도록 개발한 모델
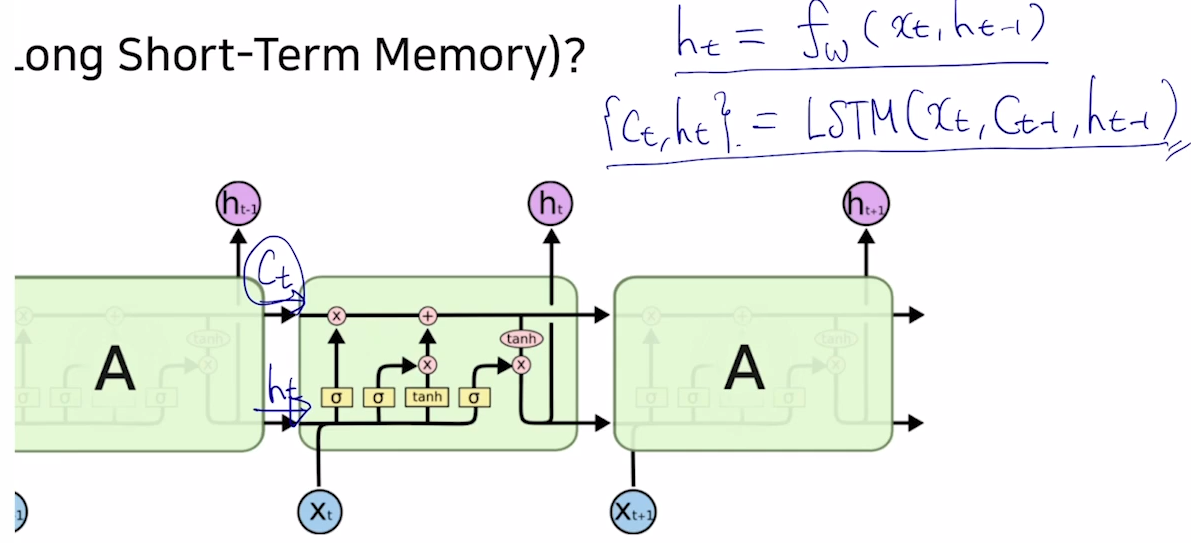
- RNN과 달리 cell state 가 다음 time step의 입력값으로 들어간다.
sigmoid를 거쳐서 나온i,f,o는0~1 값을 가지게 되고, 다른 벡터와 sigmoid의 0 또는 1과 element-wise 곱해줌으로써 어떤 정보는 보존되고 어떤 정보는 보존되지 않는다.
- 만약 sigmoid의 값이
0.3이고 함께 곱해지는 벡터가5라면, 0.3*5 = 1.5로5의30%의 정보만 보존tanh는-1 ~ 1사이의 값으로 유의미한 정보로 변환
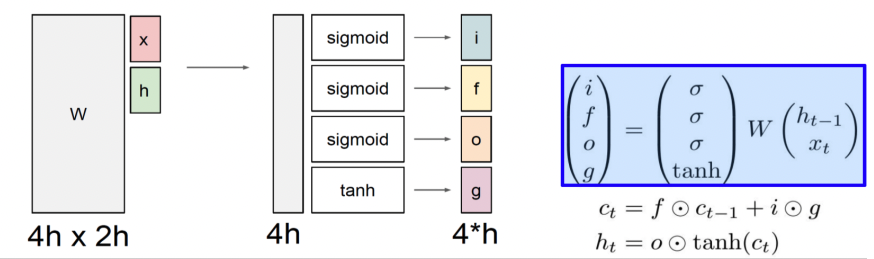
🍏 LSTM의 세부 동작 (forget gate, input gate, output gate)
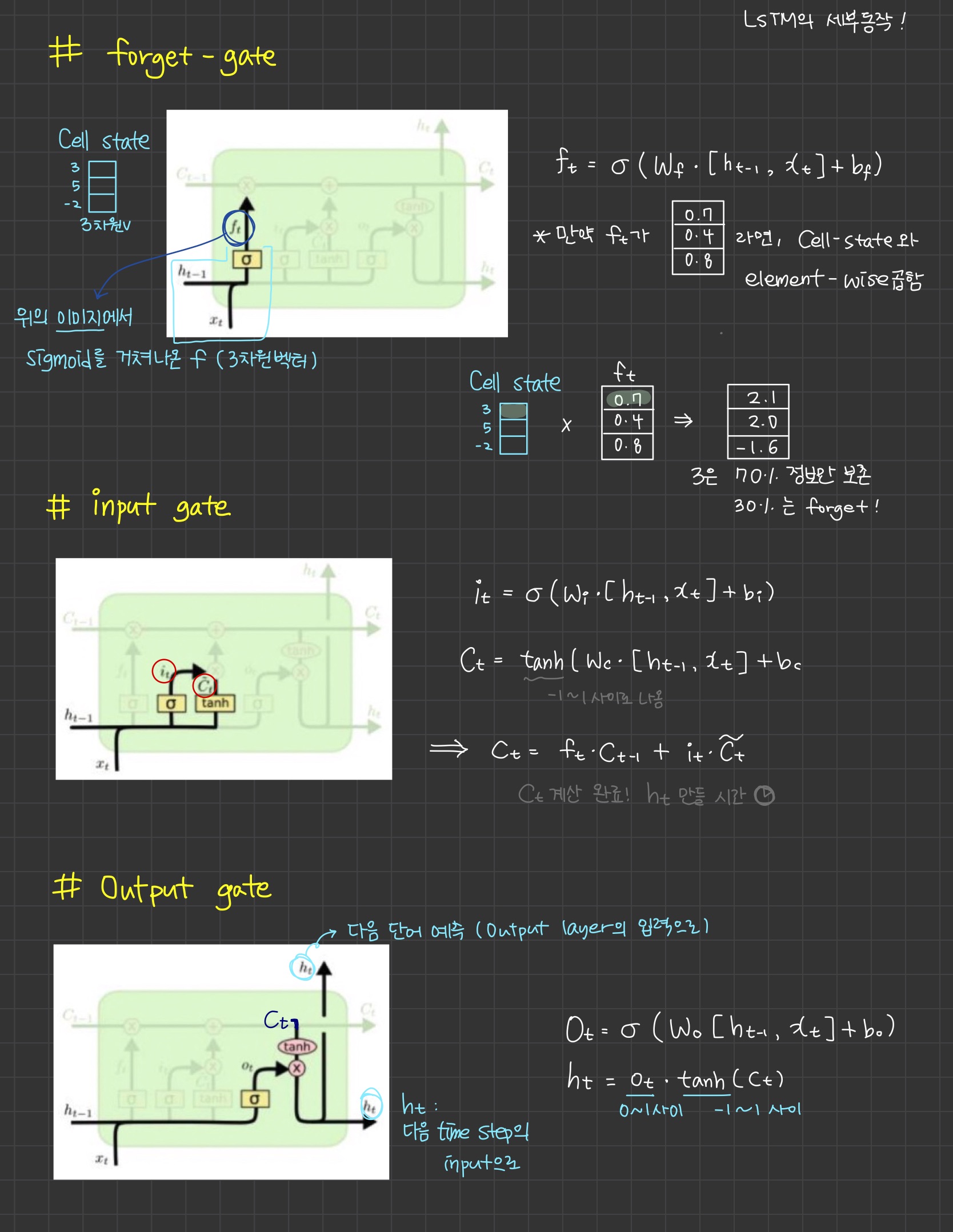
- input gate 쪽에는 2개의 gate가 있다. (
input,gate)
🍏 LSTM의 파라미터 개수 구하기
| 은닉층은 1개이다.
| 입력()의 차원은 25이다.
| 은닉 상태()의 차원은 100이다.
| LSTM의 각 게이트는 bias를 가진다.
LSTM 입력 차원 을 m, 은닉상태 차원 을 n
각 4개의 gate 연산에 사용되는 파라미터는 ()
파라미터 수 :
파라미터 수 :
파라미터 수 :
==>
🚩 GRU
Gated Recurrent Unit
- LSTM의 모델구조를 경량화해서 더 적은 메모리와 빠른 계산 시간
- Cell state와 hidden state를 일원화해서 hidden state만이 존재
- LSTM에서 완전한 정보를 가지고있던 cell state와 같은 역할을 하는 통합된 hidden state 존재
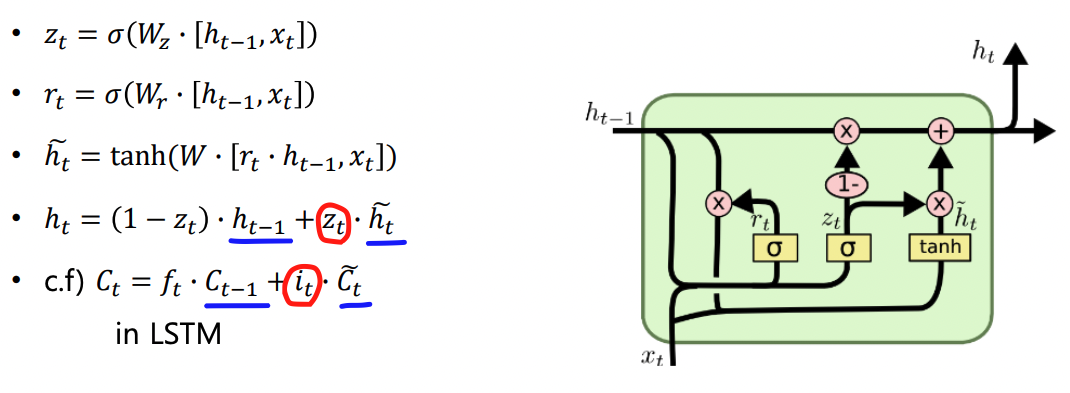
-
LSTM에서 사용한 (맨 마지막 수식 c.f 부분) 수식에서 GRU는 input gate 만 가져온다. 는 () 로써 사용 --> 부분
-
덧셈 연산을 통해서 gradient들을 복사해 넘겨주므로 gradient가 손실없이 잘 전달된다. 더 긴 time step까지 gradient 전달이 가능해 long time dependency 를 더욱 줄였다.

배우고 싶은게 많은 개발자📚