SQL 수업에서 미니 프로젝트를 시작했다. 우리 팀 주제는 '따릉이'이다. 따릉이는 서울열린데이터광장에서 데이터를 구하기도 쉽고 그 안에서 시계열 데이터를 다뤄볼 수도 있고, 또 날씨 데이터나 상권 데이터, 지도 시각화 등 연관시킬 수 데이터와 분석 기법이 많아 다루기 좋은 주제인 것 같다. 아무튼 데이터 분석 프로젝트가 처음인 만큼 궁금한 것이나 아리송한 개념이 있으면 여기에 정리해보려고 한다.
데이터 분석의 시작은 EDA
탐색적 데이터 분석이란?
탐색적 데이터 분석(Exploratory Data Analysis)은 모델링에 앞서 데이터를 살피는 모든 과정을 의미한다. 시각화 및 통계 도구를 사용해 주어진 데이터의 구조와 특징 등을 이해하는 것이 EDA다!
- 개념 참고 : 탐색적 자료분석e
EDA의 기반이 되는 기본 개념
데이터의 유형
EDA의 타깃이라고 할 수 있는 데이터는 2가지로 분류할 수 있다.
1. 일변량 Univariate
EDA를 통해 한 번에 파악하려는 변수가 한 개다. 데이터를 설명하고 그 안에 존재하는 패턴을 찾는 것이 주요 목적이다.
2. 다변량 Bivariate(multivariate)
EDA를 통해 한 번에 파악하려는 변수가 여러 개다. 여러 변수 간의 관계를 보는 것이 주요 목적이다. 여러 변수들을 동시에 확인하기 전에 개별 데이터를 먼저 파악하는 것이 좋다.
변수의 유형
1. 질적변수 = 범주형(Categorical variable)
범주형 데이터는 'A', 'B', 'C'와 같이 종류를 표시하는 데이터를 말한다. 범주형 변수란 고유한 값이나 번주의 수가 제한된 변수다.
- 이진형(Binary)
- 순서형(Ordinal) : 순위를 매길 수 있는 변수 ex) 학점, 성취도 평가
- 명목형(Nominal) : 순위를 매길 수 없는 변수 ex) 성별, 혈액형, 이름, 주소
2. 양적변수(Quantitative or numeric variable)
변수의 값을 숫자로 나타낼 수 없는 변수를 의미한다.
- 이산형(Discrete) : 데이터가 비연속적인 변수(정수) ex) 사람 수
- 연속형(Continuous) : 값과 값 사이에 연속된(무수히 많은) 값을 갖는 변수(실수) ex) 몸무게, 키, 기온 등
EDA 방법
데이터는 수치적인 요약과 그래프를 통해 살펴봄으로써 쉽게 이해할 수 있다.
1. 수치적인 요약(기술통계)
비시각화 방법으로 그래픽적인 요소를 사용하지 않는 방법이다. 주로 Summary Statistics를 통해 데이터를 확인한다.
- 평균(Mean), 중앙값(Median), 최빈값(Mode)
- 표준편차(Standard Deviation), 분산(Variance)
- 사분위수범위(Interquartile Range)
- 첨도(Kurtosis), 왜도(Skewness)
2. 그래프에 의한 요약(Graphical methods)
차트 혹은 그림 등을 이용해 데이터의 분포를 살피는 방법이다.
- 범주형 : bar
- 수치형
- 이산형 : bar
- 연속형 : kdeplot, histogram
- 범주형 + 수치형 : boxplot, violinplot, etc
- 수치형 + 수치형 : scatter
EDA, 무엇을 어떻게 할까?
- 자료속에 내포된 대표값, 대표값의 불확실성
- 모평균, 모비율, 분산, …
- 점추정 및 구간추정
- 자료/변수의 분포는?
- 분포 = 밀도함수/질량함수의 추정: 히스토그램, 상자그림
- (백)분위수
- QQ plot, 정규성검정, 분포검정
- 이상치의 탐색
- 변수들간의 관계
- 연속형/연속형 변수간의 관계
- 산점도, 상관계수 - 연속형/범주형 변수간의 관계
- 조건부 분포/대표값/분산, 상자그림, 히스토그램 - 범주형/범주형 변수간의 관계
- 교차표, 막대그래프, 동일성/독립성 검정 - 관심변수와 그에 영향을 주는 변수간의 함수관계
-회귀분석, 분산분석, …
- 잔차에 대한 검토
- 연속형/연속형 변수간의 관계
EDA 해보기
캐글에서 찾은 EDA 설명과 예시. 컴페티션이 끝나 데이터를 다운받을 수 없어 눈으로 보고 모르는 개념은 주석을 달아봤다. 글쓴이의 말처럼 컴페티션에 참여할 때 이런 식으로 고민하고, 이런 생각을 해야겠다는 흐름을 참고하면 될 것 같다.
라이브러리 호출 및 I/O
# 나는 먼저 seaborn과 matplotlib을 설치했다 (matplotlib은 아나콘다 프롬프트에서 conda install matplotlib로 설치했다)
!pip install seaborn
# 데이터 분석 라이브러리
import numpy as np
import pandas as pd
# 시각화 라이브러리
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
# 원하는 여러 파일을 한 번에 가져오기 위해 os 모듈을 import했다
import os
for dirname, _, filenames in os.walk('/kaggle/input'): # 1) os.walk('경로 지정')
for filename in filenames: # 2)
print(os.path.join(dirname, filename)) # 3)
# 1) 경로에 있는 파일을 하나하나 불러 온다
# 2) 그중 filename만 불러온다
# 3) 경로와 filename을 join해 새로운 경로를 만든다
sns.set_style("whitegrid")더 알기
os 모듈은Operating System의 약자로서 운영체제에서 제공되는 여러 기능을 파이썬에서 수행할 수 있게 한다. 예를 들어 파이썬을 이용해 파일을 복사하거나 디렉터리를 생성하고 특정 디렉터리 내의 파일 목록을 구하고자 할 때 os 모듈을 사용한다. (참고 : 파이썬으로 배우는 알고리즘 트레이딩 - OS 모듈
- 현재 경로 구하는 명령어 : os.getcwd()
- 특정 경로에 존재하는 파일과 디렉터리 목록을 구하는 함수 : os.listdir()
- listdir 함수의 인자로 경로를 전달하는 경우 해당 경로에 존재하는 파일과 디렉터리 목록을 구할 수 있다
- ex) os.listdir('c:/Anaconda3')
- 해당 경로에 총 몇 개의 파일 또는 디렉터리가 존재하는지 확인 : len(files)
- 'c:/Anaconda3'이라는 경로에 있는 파일 중 확장자가 'exe'로 끝나는 파일만 출력하는 코드 :
for x in os.listdir('c:/Anaconda3'): if x.endswith('exe'): # .endswith() : 마지막 문자열에서 원하는 텍스트 매칭 print(x) python.exe pythonw.exe Uninstall-Anaconda.exe
- 문자열 안에서 특정 텍스트를 찾는 방법 중 하나로, 내가 찾고 싶은 텍스트가 문자열의 처음이나 끝에 있다면
str.startwith()와str.endwith로 찾을 수 있다.
- 예시로url='http://google.com'이면url.startwith('http://')처럼 사용 가능!
- 단, 찾고 싶은 입력값이
리스트나세트형이라면튜플로 먼저 변환해줘야 한다.
- 예를 들어
choice=['http:', 'https:']이고url='http://google.com'일때,url.startwith(choice)를 하고 싶다면url.startwith((tuple(choice))요렇게 써야 한다!- 참고: 판다스 문자열 찾기
데이터 읽기
csv파일로 제공되는 정형 데이터(보유한 정보에 대해 적절히 정의된 스키마가 있는 데이터)는
pd.read_csv()로 읽어올 수 있다.
train_data = pd.read_csv('/kaggle/input/kakr-4th-competition/train.csv')
test_data = pd.read_csv('/kaggle/input/kakr-4th-competition/test.csv')pandas의 메서드로 간단한 탐색
데이터를 불러온 후에는 기본적으로 어떤 형태의 데이터가 있는지 살펴볼 수 있으며 다음 메서드를 사용할 수 있다.
.head(): 상위 5개, 괄호 안에 숫자로 개수 변경 가능.tail(): 하위 5개, 괄호 안에 숫자로 개수 변경 가능.sample(): 랜덤 5개, 괄호 안에 숫자로 개수 변경 가능
train_data.head()데이터의 feature 확인
데이터의 각 feature는 다음과 같은 의미를 가지고 있다. (data description에서 제공)
- age : 나이
- workclass : 고용 형태
- fnlwgt : 사람 대표성을 나타내는 가중치 (final weight의 약자)
- education : 교육 수준
- education_num : 교육 수준 수치
- marital_status: 결혼 상태
- occupation : 업종
- relationship : 가족 관계
- race : 인종
- sex : 성별
- capital_gain : 양도 소득
- capital_loss : 양도 손실
- hours_per_week : 주당 근무 시간
- native_country : 국적
- income : 수익 (예측해야 하는 값)
feature에 대한 통합 정보 확인
현재 여러 가지 feature가 있는 것을 확인할 수 있으며 각 feature에 대한 통합적인 정보(구조, 데이터 타입, 전체 데이터 수 등)는 2가지로 살펴볼 수 있다.
.info().describe()
1. .info()
train_data.info()- 각 feature에 있는 데이터에 몇 개의 null이 있는지, 각 데이터의 type을 확인할 수 있다.
- object는 수치형이 아닌 자료형으로 이해할 것, 대부분 string 이다.
- 후에 object인 feature는 대부분의 머신러닝 모델에 직접적인 입력 값으로 사용할 수 없으니 전처리 과정이 필요하다.
2. .describe()
train_data.describe()- describe을 사용하면 수치형 데이터의 다음 통계값을 추출할 수 있다.
- count : 개수
- mean : 평균
- std : 표준 편차
- min : 최솟값
- 25% : 제 1사분위값
- 50% : 중앙값, 중위값
- 75% : 제 3사분위값
- max : 최댓값
3. .describe(include='O')
- 범주형 데이터의 경우 include='O'를 추가하여 확인할 수 있다.
train_data.describe(include='O')- 이 경우에는
범주의 개수,상위 범주,빈도수등을 제공한다.
4. 범주형 데이터는 어떤 feature를 가지고 있나
for col in train_data.columns:
if train_data[col].dtype == 'object': # 데이터 타입이 object인 것만!
categories = train_data[col].unique() # 범주형 데이터 칼럼에서 고유한 값을 카테고리에 담기
print(f'[{col}] ({len(categories)})')
print('\n'.join(categories))
print()
# 이런 식으로 출력됨
[workclass] (9)
Private
State-gov
?
Self-emp-not-inc
Local-gov
Federal-gov
Self-emp-inc
Without-pay
Never-worked
더 알기
고유한 값을 반환하는 메서드들
- unique() :
고유한 값(범주)이 어떤 종류인지 알고 싶을 때 사용
- ex) 빵 가게의 데이터(df)에서 빵 품목(item)을 확인하고 싶을 때
df['item'].unique()식으로 품목의 종류를 출력할 수 있음- nunique() :
고유한 값(범주)들의 수를 출력, 고유한 값의 총 수를 알고 싶을 때 사용
- ex) 빵 가게 데이터에서 빵 품목의 총 수를 확인하고 싶을 때
df['item'].nunique()로 출력할 수 있음- value_counts() : 고유한 값의
값별로 데이터의 수(같은 범주의 갯수)를 출력해주는 함수로, 품목에 따른 수량을 확인하고 싶을 때 사용
- ex) 빵 가게 데이터에서 빵 품목 별로 수량을 확인하고 싶을 때
df['item'].value_counts()로 확인
시각화로 데이터의 분포 보기
위의 수치적으로만 보면 데이터에 대한 이해가 부족할 수 있으므로 시각화 라이브러리 matplotlib과 seaborn을 통해 데이터를 살펴본다.
데이터의 분포는 다음과 같이 살필 수 있다. 대표적인 몇 가지만 살펴본다. (이외에도 다양한 방법이 존재)
- 범주형 : bar
- 수치형
- 이산형 : bar
- 연속형 : kdeplot, histogram - 범주형 + 수치형 : boxplot, violinplot, etc
- 수치형 + 수치형 : scatter
1. 범주형 데이터의 시각화
그 전에 범주형 feature의 unique한 범주 개수를 세어 본다
for col in train_data.columns:
if train_data[col].dtype == 'object':
categories = train_data[col].unique()
print(f'[{col}] ({len(categories)})')
# 출력
[workclass] (9)
[education] (16)
[marital_status] (7)
[occupation] (15)
[relationship] (6)
[race] (5)
[sex] (2)
[native_country] (41)
[income] (2)- 전반적으로 범주의 수가 많아 전처리 이전에는 2개 이상의 feature를 한 plot에서 보기에는 조금 효율성이 떨어질 것 처럼 보인다.
- pandas의
.value_counts()메서드를 사용하면같은 범주의 개수를 쉽게 셀 수 있다.
train_data['sex'].value_counts()
# 출력
Male 17482
Female 8567
Name: sex, dtype: int641) seaborn을 활용한 시각화
이를 matplotlib으로 그릴 수도 있지만, seaborn을 사용하면 다음과 같이 그릴 수 있다.
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
# 카운트 플롯(countplot) : 막대를 사용해 각 범주형 변수의 빈도수를 시각화
sns.countplot(x='sex', data=train_data)
plt.show()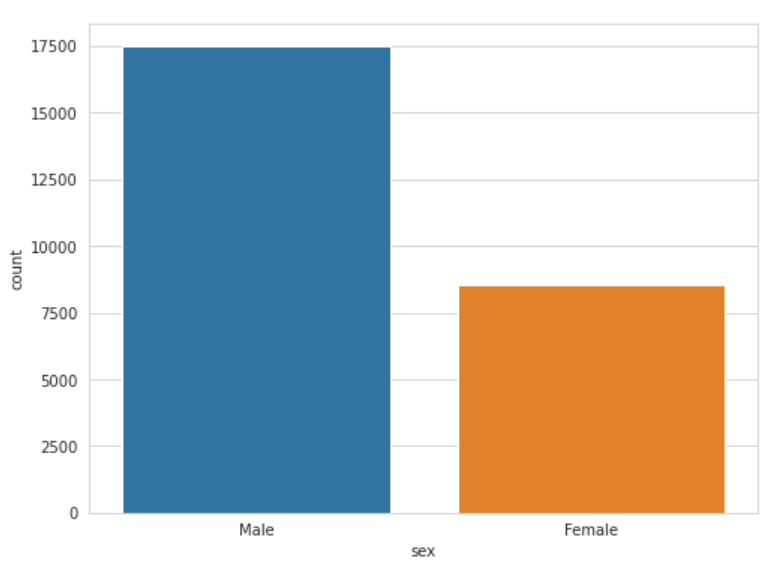
여기서 잠깐!
Q.fig, ax = plt.subplots()이 부분은 왜 있는 걸까?
A. plt.subplots() 함수는 Figure와 axes 객체를 포함하는 튜플을 반환하는 함수다. fig, ax = plt.subplots()를 두 변수fig,ax에 담는 것은 그림 수준의 속성을 변경하거나 나중에 그래프를 이미지 파일로 저장하려는 경우(예: fig.savefig('yourfilename.png'))에 유용하다.
2) 시각화 custom
EDA의 핵심은 본인, 그리고 타인의 가독성을 생각하며 작성하는 것이다.
- 여백, 축, 공간, 텍스트 등의 내용을 활용하면 된다
fig, axes = plt.subplots(1, 2, figsize=(13, 7), sharey=True)
sns.countplot(x='sex', data=train_data, ax=axes[0], palette="Set2", edgecolor='black')
sns.countplot(x='income', data=train_data, ax=axes[1], color='gray', edgecolor='black')
# Margin & Label 조정
for ax in axes :
ax.margins(0.12, 0.15)
ax.xaxis.label.set_size(12)
ax.xaxis.label.set_weight('bold')
# figure title
plt.suptitle('Categorical Distribution',
fontsize=17,
fontweight='bold',
x=0.05, y=1.06,
ha='left' # horizontal alignment
)
plt.tight_layout()
plt.show()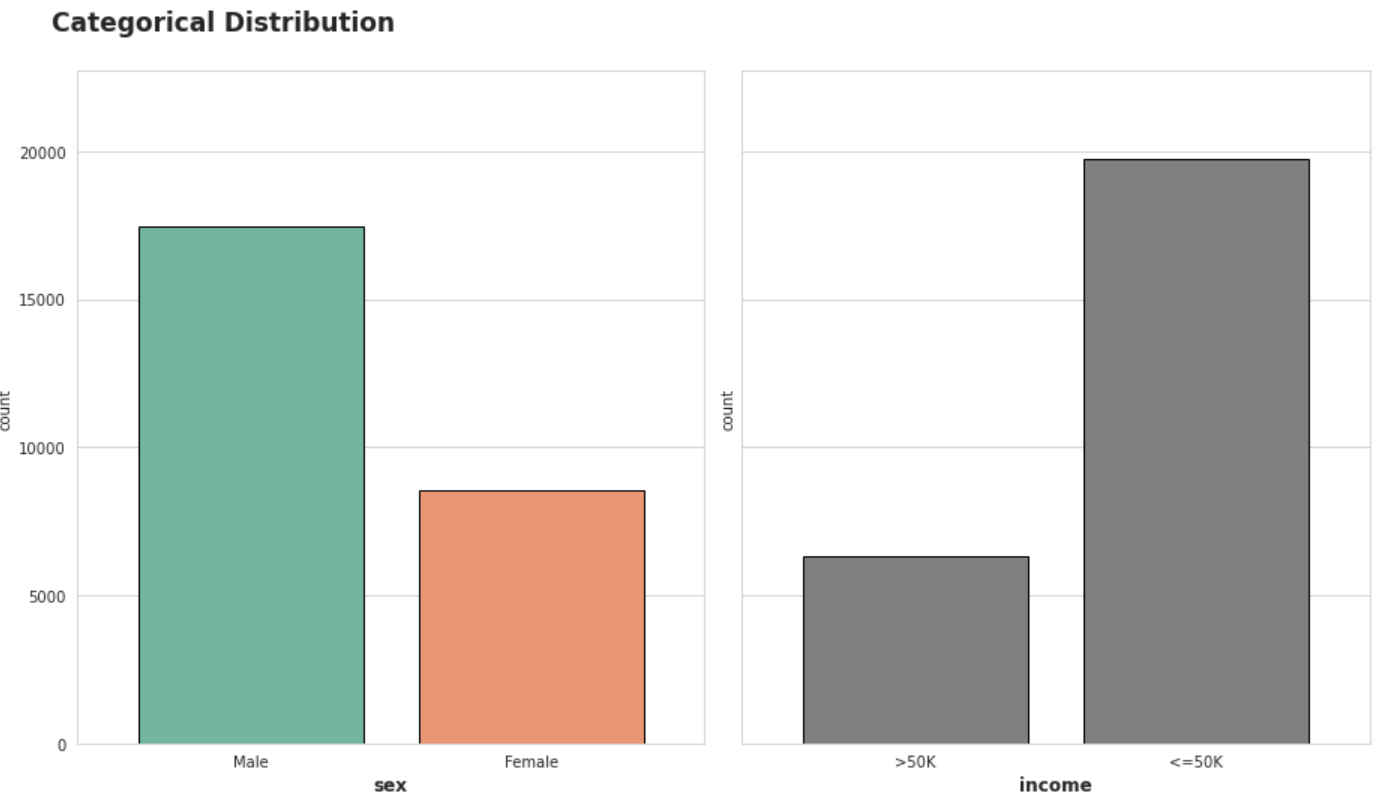
- 남성과 여성의 비율도 2:1 정도의 불균형
- 타겟값인 income도 약 3:1 정도의 불균형
이런 특성을 하나씩 살펴보며 후에 어떤 인코딩, 어떤 feature selection, feature engineering을 할 수 있을지 생각한다.
비슷한 방식으로 relationship과 marital_status도 살펴볼 수 있다.
2. 수치형 데이터의 시각화
다음과 같은 수치형 데이터에서 일부만 살펴본다.
- age
- education_num
- capital_gain
- capital_loss
- hours_per_week
- fnlwgt
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
ax.hist(train_data['age'], bins=10)
ax.set_ylim(0, 6000)
ax.set_title('Age Distribution')
plt.show()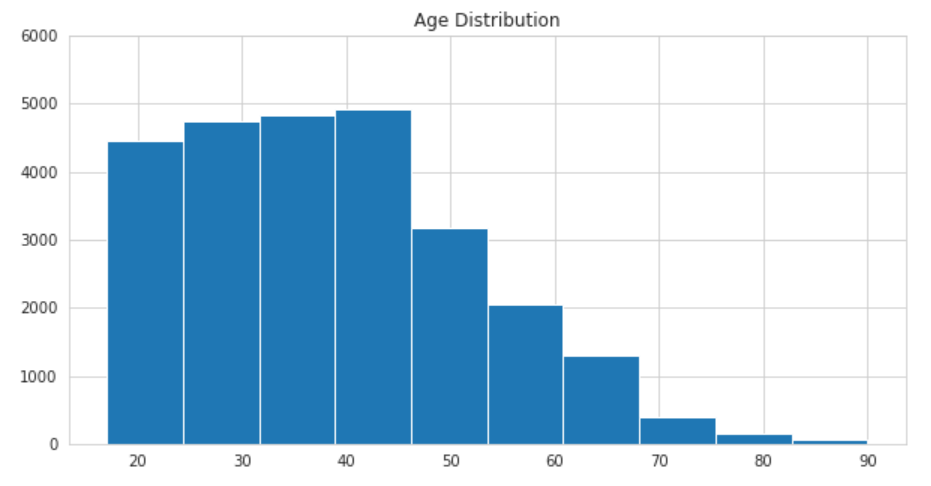
- 인구조사인 만큼 17세부터 데이터가 시작하고 90세가 최고령임을 알 수 있다.
- 45세 부근에서 수가 훅 줄어드는 것을 볼 수 있다.
나이는 어떤 식으로 인코딩하면 좋을까? 타이타닉 대회에서 사용하는 age_band로 나이 구간을 만들 수 있고, 다양한 방식을 생각해볼 것!
나머지 데이터도 이런 방식으로 EDA해볼 것
더 깔끔하고 더 많은 내용을 담고 더 좋은 인사이트를 담는!
EDA 노트북을 만들어 보는 것부터 데이터 분석은 시작!
더 공부할 것
- 데이터프레임을 합치는 여러 방법(merge, join, concat)을 정리해봐야겠다!
