관계형 데이터베이스 용어
관계형 데이터 베이스

관계형 데이터베이스는 테이블을 사용하고, 키와 값을 사용하는 데이터베이스의 한 종류.
데이터의 종속성을 관계(Relationship)로 표현하는 것이 관계형 데이터베이스의 특징.
스키마 (Schema)
데이터베이스에 저장되는 데이터 구조와 제약 조건을 정의한 것.
- 데이터베이스 스키마는 모든 테이블, 열 이름 및 유형, 인덱스 등을 설명함
인스턴스 (Instance)
정의된 스키마에 따라 데이터베이스에 실제로 저장된 값.
테이블 (Table)
행과 열로 구성된 데이터 집합.
릴레이션 (Relation)
보통 관계형 데이터베이스의 테이블을 릴레이션(Relation)이라 부름.
정보를 구분하여 저장하는 기본 단위
- 튜플(Tuple)과 속성(Attribute)로 구성되어 있음.
- 릴레이션의 특징
- 한 릴레이션에는 동일한 튜플 존재 X
- 한 릴레이션에서 튜플들의 순서는 의미 X
- 한 릴레이션에서 속성 사이의 순서는 의미 X
- 속성값은 원자 값(더는 분해할 수 없는 하나의 값)으로만 구성됨
- 튜플들은 시간에 따라 변함
- 튜플을 식별하는 속성들의 부분집합을 키(Key)로 설정
- 릴레이션 스키마를 구성하는 속성값 동일해도 됨
뷰 (View)
다른 테이블 기반으로 만들어진 가상테이블.
- 일반 테이블과 달리 실제 값 저장 X
- 논리적으로만 존재하면서 물리적으로 존재하는 테이블과 동일한 방법으로 사용
속성 (Attribute)
릴레이션의 열
필드 (Field)
파일 구조에서 열
튜플 (Tuple)
릴레이션의 행
레코드 (Record)
파일구조에서 행
차수 (Degree)
하나의 릴레이션에서 속성의 전체 개수.
정적인 특성.
카디널리티 (Cardinality)
하나의 릴레이션에서 튜플의 전체 개수.
동적인 특성.
키 (Key) - 튜플 식별
검색, 정렬 시 튜플을 구분할 수 있는 기준이되는 속성 또는 속성의 집합
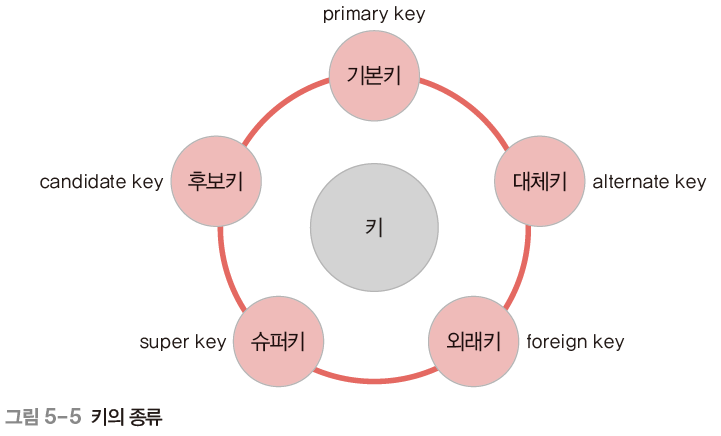
1. 후보키 (Candidate Key)

튜플을 유일하게 구별하기 위해 꼭 필요한 최소한의 속성 또는 속성의 집합
- 유일성 : Key로 하나의 튜플 유일하게 구별 가능
- 최소성 : 꼭 필요한 속성으로 구성
Ex
- (고객 이름) 속성은 후보키? -> 불가능 (동명이인 -> 유일성 X)
- (고객 아이디) 속성은 후보키? -> 가능 (같은 고객 아이디 X)
- (고객 아이디 + 고객 이름) 후보키? -> 불가능 (고객이름 필요 X -> 최소성 X)2. 기본키 (Primary Key)

여러 후보키 중에서 기본적으로 사용할 키
- 후보키 1개 -> 해당 후보키 기본키
- 후보키 여러 개 -> 데이터베이스 사용 환경 고려해 적합한 것 선택
Ex
후보키 : (고객 아이디), (고객 이름 + 주소)
-> (고객 아이디)3. 대체키 (Alternate Key)
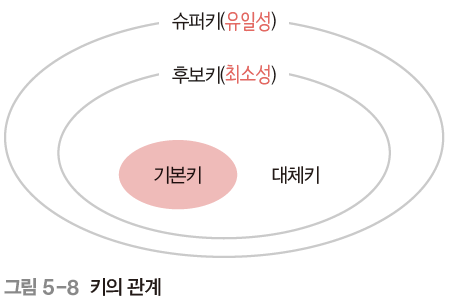
후보키 중 기본키를 제외한 나머지 키 = 보조키
Ex
후보키 : (고객 아이디), (고객 이름 + 주소)
-> (고객 이름 + 주소)4. 슈퍼키 (Super Key)
유일성은 만족하지만 최소성은 만족하지 않는 속성 또는 속성의 집합
5. 외래키 (Foreign Key)

어떤 릴레이션에 소속된 속성 또는 속성 집합이 다른 릴레이션의 기본키가 되는 키
- 다른 릴레이션의 기본키를 그대로 참조하는 속성의 집합이 외래키. 릴레이션들 사이의 관계 표현
- 외래키로 지정되면 참조 테이블의 기본키에 NULL X
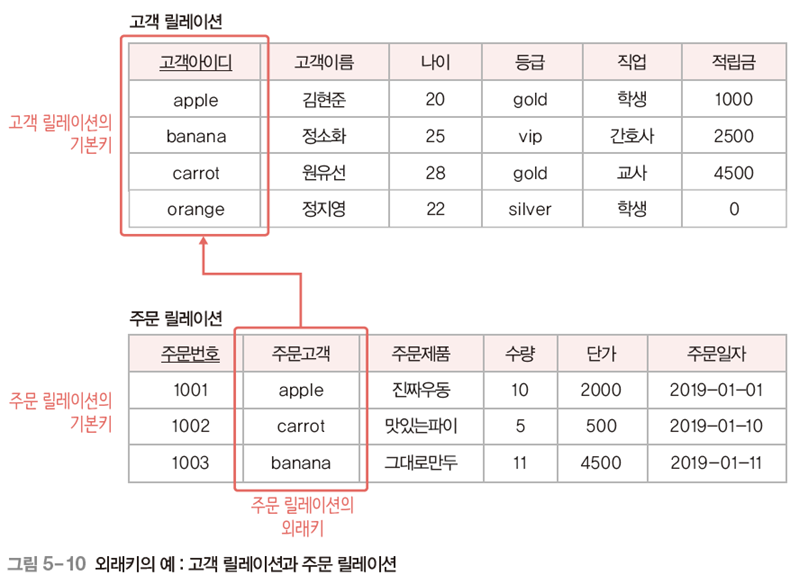
Ex
주문 릴레이션의 (주문 고객) 속성은 고객 릴레이션의 (고객 아이디)를 참조
- 주문 릴레이션 : 참조하는 릴레이션 (외래키 가짐)
- 고객 릴레이션 : 참조되는 릴레이션 (기본키 가짐)
- 외래키 : 참조하는(주문) 릴레이션의 (주문 고객)조인(Join)
두개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법
- 테이블을 연결하려면, 적어도 하나의 컬럼을 서로 공유하고 있어야하므로 이를 이용해 데이터 검색에 활용.
CROSS JOIN
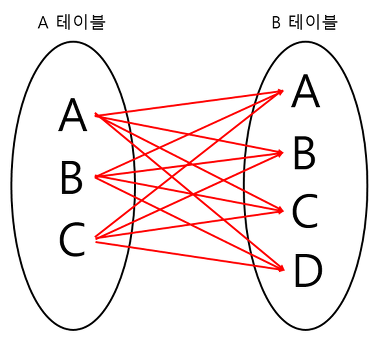
모든 경우의 수를 전부 표현해주는 방식
A가 3개, B가 4개면 총 3 * 4 = 12개의 데이터 검색
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
CROSS JOIN JOIN_TABLE BSELF JOIN
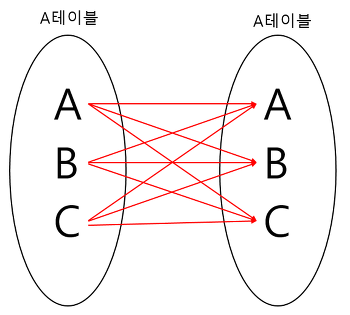
자기 자신과 자기 자신을 조인하는 것
하나의 테이블을 여러번 복사해 조인
자신이 갖고 있는 컬럼을 다양하게 변형시켜 활용할 때 자주 사용
SELECT
A.NAME, B.AGE
FROM EX_TABLE A, EX_TABLE BSQL Injection
응용 프로그램 보안 상의 허점을 의도적으로 이용해, 악의적인 SQL문을 실행되게 함으로써 데이터베이스를 비정상적으로 조작하는 공격 기법
- 웹 애플리케이션이 데이터베이스에 질의를 하는 과정에 사용되는 SQL 쿼리를 조작하여 데이터베이스를 대상으로 공격자가 의도한 악의적인 행위를 할 수 있는 Injection 기반의 웹 취약점
- 공격에 성공하게 되면 조직 내부의 민감한 데이터나 개인 정보를 획득할 수 있고, 심각한 경우 조직의 데이터 전체를 장악하거나 완전히 손상시킬 수 있음
공격 방법
1. 인증 우회
SQL 인젝션 공격의 대표적이 경우로, 로그인 폼(Form)을 대상으로 공격.
정상적인 계정 정보 없이도 로그인을 우회하여 인증 획득 가능.
Ex1
로그인 시, 아이디와 비밀번호를 input 창에 입력
SELECT * FROM USER WHERE ID = "abc" AND PASSWORD = "1234";input 창에 비밀번호를 입력함과 동시에 다른 쿼리문 입력
"1234"; DELETE * USER FROM ID = "1";보안이 완벽하지 않은 경우, 이처럼 비밀번호가 아이디와 일치해서 True가 되어 뒤에 작성한 DELETE 문이 데이터베이스에 영향을 줄 수도 있음.
Ex2
비밀번호 입력창에 ' or '1' = '1와 같이 입력하면 '으로 앞 쿼리문을 닫고 '1' = '1'과 같은 true 문을 작성해 무조건 적용되도록 수정한 뒤 DB를 마음대로 조작 가능
SELECT * FROM client WHERE name = 'anjinma' AND password ='' or '1' = '1'2. 데이터 노출
시스템에서 발생하는 에러 메시지를 이용해 공격하는 방법.
보통 에러는 개발자가 버그를 수정하는 면에서 도움을 받을 수 있지만, 해커들은 이를 역이용해 악의적인 구문을 삽입해 에러 유발.
Ex
해커는 GET 방식으로 동작하는 URL 쿼리 스트링을 추가하여 에러 발생시킴.
이에 해당하는 오류가 발생하면, 이를 통해 해당 웹앱의 데이터베이스 구조를 유추할 수 있고 이를 해킹에 활용
URL을 통해 파라미터를 주고받는 GET 방식은 해커가 단순히 URL을 통해 전달될 파라미터를 조작하면 손쉽게 SQL injection 취약점 적용 가능
- URL 쿼리 스트링 : 사용자가 입력 데이터를 전달하는 방법중의 하나로, URL 주소에 미리 협의된 데이터를 파라미터를 통해 넘기는 것
http://test.com/login.php?id=abc1234 and password=''
방어 방법
1. 입력 값에 대한 검증
검증 로직을 추가해 미리 설정한 특수문자들이 들어왔을 때 요청을 막아냄
2. SQL 서버 오류 발생 시, 해당하는 Error Message 노출 금지
View를 활용해 원본 데이터베이스 테이블에는 접근 권한을 높임.
일반 사용자는 View로만 접근해 에러를 볼 수 없도록 만듦
3. Prepared Statement 구문 사용
Prepare Statement를 사용하면, 특수문자를 자동으로 escaping 해준다. (Statement와는 다르게 쿼리문에서 전달인자 값을 ?로 받는 것) 이를 활용해 서버 측에서 필터링 과정을 통해서 공격을 방어한다.
- Statement
String sql = "SELECT NAME, AGE FROM TABLE WHERE USERID = " + userID- Prepared Statement
String sql = "SELECT NAME, AGE FROM TABLE WHERE userID = ?"SQL vs NoSQL

https://usishi.com/category/yazilim
SQL
- SQL 은 '구조화된 쿼리 언어 (Structured Query Language)'의 약자.
- 특정 유형의 데이터베이스와 상호 작용하는 데 사용하는 쿼리 언어.
- SQL 을 사용하면 관계형 데이터베이스 관리 시스템(RDBMS)에서 데이터를 저장, 수정, 삭제 및 검색 가능.
RDBMS 특징
- 데이터는 정해진(엄격한) 데이터 스키마(= structure)를 따라 데이터베이스 테이블에 저장됨.
- 데이터는 관계를 통해서 연결된 여러개의 테이블에 분산됨.
- 엄격한 스키마
- 데이터는 테이블에 레코드로 저장되며 각 테이블에는 명확하게 정의된 구조 (Schema)가 있음.
- 스키마를 준수하지 않는 레코드는 추가 X
- 데이터 관계
- 정규화를 통해 데이터들을 여러 개의 테이블에 나누어서, 데이터들의 중복을 피할 수 있음.
NoSQL
- NoSQL은 Non-SQL, Not Only SQL, non-relational database 라고도 불림. 의미는 SQL과 반대되는 접근방식으로 이해. (스키마 X, 관계 X)
- RDB의 레코드는 문서(documents)로 일컫음.
- 다른 구조의 데이터를 같은 컬렉션(SQL에 테이블을 의미)에 추가할 수 있음.
비교 분석
1. 확장성
SQL
- SQL은 수직적으로 확장.
- 수직적 확장은 CPI나 RAM 같은 부품을 업그레이드하거나 하드웨어를 추가하여 서버의 성능을 향상시킴
NoSQL
- NoSQL은 수평적으로 확장.
- 수평적 확장은 더 많은 서버를 추가해 서버를 전체적으로 분산시킴.
2. 관계
SQL
- 관계형 데이터는 각 table 간의 관계(JOIN)을 통해 데이터 파악 가능.
- 데이터 중복을 없앨 수 있고, 데이터의 정확성을 높일 수 있음.
NoSQL
- 다른 Collection이 필요하다면 기존 Collection의 데이터를 일부 복제.
- Collection 별로 중복된 데이터가 존재.
- 중복된 데이터는 삭제하거나 업데이트할 때 반영 안될 수 있음.
Sharding(샤딩)은 같은 테이블 스키마를 가진 데이터를 다수의 DB에 분산하여 저장하는 방법.
이 기술을 접목하면 SQL도 수평적 확장을 적용할 수 는 있지만, 실제 구현은 어렵다고 함.
3. 속성
SQL
- SQL은 ACID 특성을 따름.
- ACID는 DB의 트랜잭션이 안전하게 수행되는 것을 보장하기 위한 특징
NoSQL
- NoSQL은 CAP 이론을 따름.
- CAP 이론은 분산 시스템에서는 CAP 세 가지 속성 모두를 만족하는 것은 불가능하며, 오직 2가지만 만족할 수 있다는 것으로 정의.
CAP 이론
- Consistency (일관성) : 모든 요청은 최신 데이터 또는 에러를 응답받음. (DB가 3개로 분산되었다고 가정할 때, 하나의 특정 DB의 데이터가 수정되면 나머지 2개의 DB에서도 수정된 데이터를 응답받아야 함.)
- Availability (가용성) : 모든 요청은 정상 응답을 받음. (특정 DB가 장애가 나도 서비스가 가능해야 한다.)
- Partitions Tolerance (분리 내구성) : DB간 통신이 실패하는 경우라도 시스템은 정상 동작 한다.
4. 스키마
SQL
- SQL은 데이터를 저장하기 위해 스키마가 먼저 정의되어야 함.
NoSQL
- NoSQL은 JSON 혹은 객체의 형태인 Key-Value 로 데이터가 저장됨
(Document -> Collection -> Database)
결론
SQL
- 장점
- 스키마가 정의되어 있어 확실하고 명확.
- 구조의 완전성을 보장.
- 관계를 설정하기에, 데이터는 중복없이 한번만 저장.
- 단점
- 유연 X. 스키마를 사전에 시간 들여 철저하게 짜야 하고 나중에 수정하기 번거로움 (엄격한 스키마).
- 관계를 맺어 데이터를 저장하기에, 중복되지는 않지만, 조인을 많이 해야할 경우 매우 복잡한 쿼리를 작성해야 할 수 있음.
- 수평적 확장이 가능하지만 어렵기 때문에 성장 한계가 오는 시점이 옴.
관계를 맺고 있는 데이터가 자주 변경되는 경우, 또 명확한 스키마가 사용자와 데이터에게 중요한 경우 관계형 데이터베이스를 사용하는게 좋음. 금융 산업과 같은 시스템의 형태가 급격하게 변하지 않으면서 그 안의 데이터가 계속 바뀌는 보수적인 시스템에서 유리.
NoSQL
- 장점
- 스키마가 없기에, 훨씬 더 유연. 언제든지 데이터를 추가할 수 있음. (필드 추가).
- 어떠한 형식으로도 데이터를 저장할 수 있기에, 필요한 대로 저장해 읽어오는 속도가 빠름.
- 수직 및 수평 확장 모두 가능해 데이터베이스가 애플리케이션에서 발생시키는 모든 읽기 / 쓰기 요청을 처리 가능.
- 단점
- 유연성에 의해, 데이터 구조 결정을 계속 미룰 수 있음.
- 데이터를 중복되게 필요한 컬렉션 마다 저장할 수 있어, 필요한 컬렉션마다 돌면서 여러 개의 레코드를 다 업데이트해야 함. 누락할 시, 데이터가 최신이 아닐 수 있음.
- 수정 시, 모든 컬렉션에서 다 수정해야 함.
비관계형 데이터베이스는 정확한 데이터 구조를 알 수 없거나 변경 / 확장 될 수 있는 경우 (수평적으로), 읽기 처리는 많이 하지만, 데이터를 자주 변경하지 않는 경우 사용하면 유리함.
이상 (Anomaly)
테이블을 설계할 때 잘못 설계하여 데이터를 삽입, 삭제, 수정할 때 논리적으로 생기는 오류
- 좋은 관계형데이터베이스를 설계하는 목적 중 하나가 정보의 이상 현상(Anomaly)이 생기지 않도록 고려해 설계하는 것.
- 갱신 이상(Modification ANomaly), 삽입 이상(Insertion Anomaly), 삭제 이상(Deletion Anomaly)으로 구성됩니다.
| 학번 | 이름 | 나이 | 성별 | 강의코드 | 강의명 | 전화번호 |
|---|---|---|---|---|---|---|
| 1011 | 이태호 | 23 | 남 | AC1 | 데이터베이스 | 010-0000-0000 |
| 1012 | 강민정 | 20 | 여 | AC2 | 운영체제 | 010-1111-1111 |
| 1013 | 김현수 | 21 | 남 | AC3 | 자료구조 | 010-2222-2222 |
| 1013 | 김현수 | 21 | 남 | AC4 | 웹 프로그래밍 | 010-2222-2222 |
| 1014 | 이병철 | 26 | 남 | AC5 | 알고리즘 | 010-3333-3333 |
1. 삽입 이상
자료를 삽입할 때 의도하지 않은 자료까지 삽입해야만 자료를 테이블에 추가가 가능한 현상
Ex
강의를 아직 수강하지 않은 새로운 학생을 삽입할 경우 강의 코드와 강의명 속성에는 NULL 값이 들어가야하는 문제
2. 갱신 이상 : 중복된 데이터 중 일부만 수정되어 데이터 모순이 일어나는 현상
Ex
강의 코드가 "AC3"인 김현수의 전화번호를 수정할 경우, 3번째 튜플의 데이터만 수정됨.
3, 4번째 튜플은 같은 사용자 데이터임에도 불구하고 전화번호가 다름.
3. 삭제 이상 : 어떤 정보를 삭제하면, 의도하지 않은 다른 정보까지 삭제되어버리는 현상
Ex
강의 코드가 "AC1"인 데이터베이스 개론 강의를 삭제하면, 이태호의 데이터까지 삭제됨.
이러한 이상 현상을 예방하고 효과적인 연산을 하기 위해 데이터 정규화(Data Normalization)를 함.
인덱스 (Index)
추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조.
만약 우리가 책에서 원하는 내용을 찾는다고 하면, 책의 모든 페이지 찾아 보는 것은 오래 걸림.
데이터베이스의 index == 책의 색인
데이터베이스에서도 테이블의 모든 데이터를 검색하면 시간이 오래 걸려
데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 함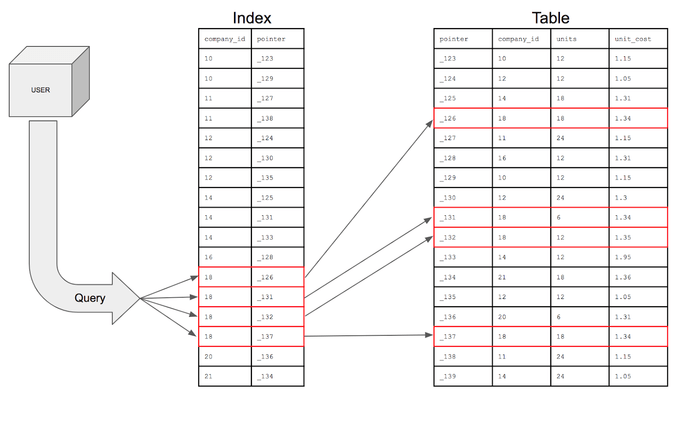
인덱스를 활용하면, 데이터를 조회하는 SELECT 외에도 UPDATE나 DELETE의 성능이 함께 향상.
// Mang이라는 이름을 업데이트 해주기 위해서는 Mang을 조회해야 한다.
UPDATE USER SET NAME = 'MangKyu' WHERE NAME = 'Mang';만약 index를 사용하지 않은 컬럼을 조회해야 하면 전체를 탐색하는 Full Scan을 수행.
Full Scan은 전체를 비교하여 탐색하기 때문에 처리 속도가 느림.
1. 과정
테이블을 생성하면, MYD, MYI, FRM 3개의 파일 생성
- FRM : 테이블 구조가 저장되어 있는 파일
- MYD : 실제 데이터가 있는 파일
- MYI : Index 정보가 들어가 있는 파일 (사용하지 않으면 비어져 있음)
사용자가 SELECT로 Index를 사용하는 Column 탐색 시, MYI 파일 내용 검색
2. 단점
- Index 생성 시, .mdb 파일 크기 증가
- 한 페이지를 동시에 수정할 수 있는 병행성이 줄어듦.
- 인덱스 된 Field에서 Data를 업데이트하거나, Record를 추가 또는 삭제 시 성능이 떨어짐.
- 데이터 변경 작업이 자주 일어나느 경우, Index를 재작성해야하므로, 성능에 영향을 미침.
3. 상황
- 사용하면 좋은 경우
- WHERE, JOIN, 또는 ORDER BY 자주 사용되는 Column
- 외래키 사용되는 Column
- 규모가 작지 않는 테이블
- 사용을 피해야하는 경우
- Data 중복도가 높은 Column
- DML이 자주 일어나는 Column
4. DML 일어났을 때의 과정
-
INSERT
기존 Block에 여유가 없을 때, 새로운 Data가 입력됨- 새로운 Block을 할당 받은 후, Key를 옮기는 작업 수행(많은 양의 Redo가 기록되고, 유발)
- Index split 작업 동안, 해당 Block에 대해 Key 값이 변경되면 안되므로 DML이 블로킹 (대기 이벤트 발생)
-
DELETE
- Table에서 Data가 DELETE되는 경우 : Data가 지워지고, 다른 Data가 그 공간 사용 가능.
- Index에서 Data가 DELETE되는 경우 : Data가 지워지지 않고, 사용 안됨 표시만 해둠.
테이블의 Data 수와 Index의 Data 수가 다를 수 있음.
-
UPDATE
- Index는 UPDATE 불가능
- Index에서는 Delete가 발생한 후, 새로운 Insert 작업
-> 2배의 작업 소요
5. 인덱스(Index)의 자료구조
해시 테이블(Hash Table)
(Key, Value)로 데이터를 저장하는 자료구조, 빠른 데이터 검색이 필요할 때 유용.
해시 테이블은 Key 값을 이용해 고유한 Index 생성 후, 그 Index에 저장된 값 꺼내오는 구조
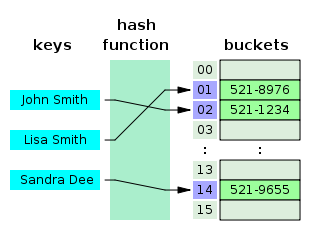
- 해시 테이블 기반의 DB 인덱스는 (데이터=컬럼의 값, 데이터 위치)를 (Key, Value)로 사용
- 해시 테이블의 시간 복잡도 O(1)
- But, 해시가 등호(=) 연산에만 특화되어 제한적.
- 해시 함수는 값이 1이라도 달라지면 완전히 다른 해시 값 생성
- 부등호 연산(<, >)이 자주 사용되는 데이터베이스 검색을 위해서는 해시 테이블 적합 X
- ex) "나는"으로 시작하는 모든 데이터 검색하기 위한 쿼리문은 인덱스 혜택 X.
B+ Tree
자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조.
모든 노드에 데이터(Value)를 저장했던 B-Tree와 다른 특성을 가짐
- 잎노드(데이터 노드)만 인덱스와 함께 데이터(Value) 가짐, 나머지 노드(인덱스 노드)들은 데이터를 위한 자식 포인터 즉, 인덱스(Key)만 가짐.
- 잎노드들은 LinkedList로 연결.
- 데이터 노드 크기는 인덱스 노드의 크기와 같지 않아도 됨.- 기존의 B-Tree는 어느 한 데이터의 검색은 효율적이지만, 모든 데이터를 한 번 순회하는 데에는 트리의 모든 노드를 방문해야 하므로 비효율적.
- 잎 노드를 제외하고 데이터 저장하지 않기 때문에 메모리 더 확보. 따라서 하나의 노드에 더 많은 포인터 가질 수 있어 트리의 높이가 낮아지므로 검색 속도 높임.
- 데이터베이스의 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생될 수 있음. B+Tree의 잎노드들을 LinkedList로 연결해 순차 검색을 용이하게 함.
- 무조건 잎노드까지 가야한다는 점 때문에 B+Tree의 시간복잡도 O(log2n)
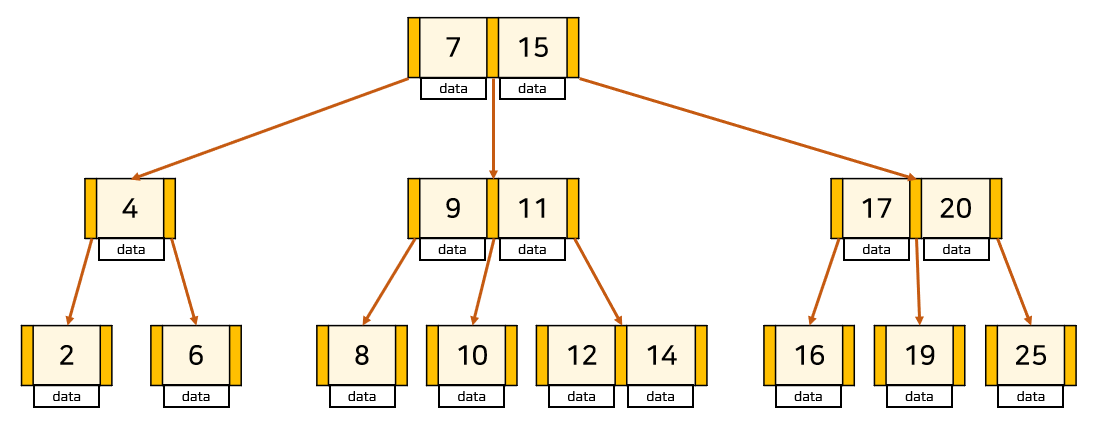
B-Tree 예시
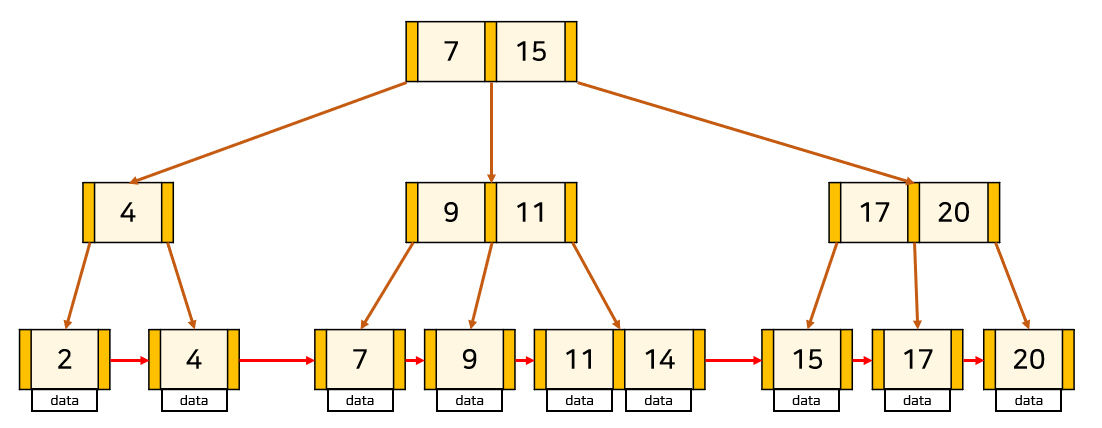
B+Tree 예시
B+Tree의 검색과정은 B-Tree와 동일. But 삽입 삭제는 항상 잎노드에서 일어나 차이가 있음
1) 삽입
(1) Key의 수가 최대보다 적은 잎노드에 삽입하는 경우
- 해당 노드의 가장 앞이 아닌 곳에 삽입되는 경우는 단순히 삽입
- 잎 노드의 가장 앞에 삽입 되는 경우는, 해당 노드를 가리키는 부모 노드의 포인터의
오른쪽에 위치한 Key로 K를 바꿔줌.
그리고 삽입된 Key에 Linked List로 연결
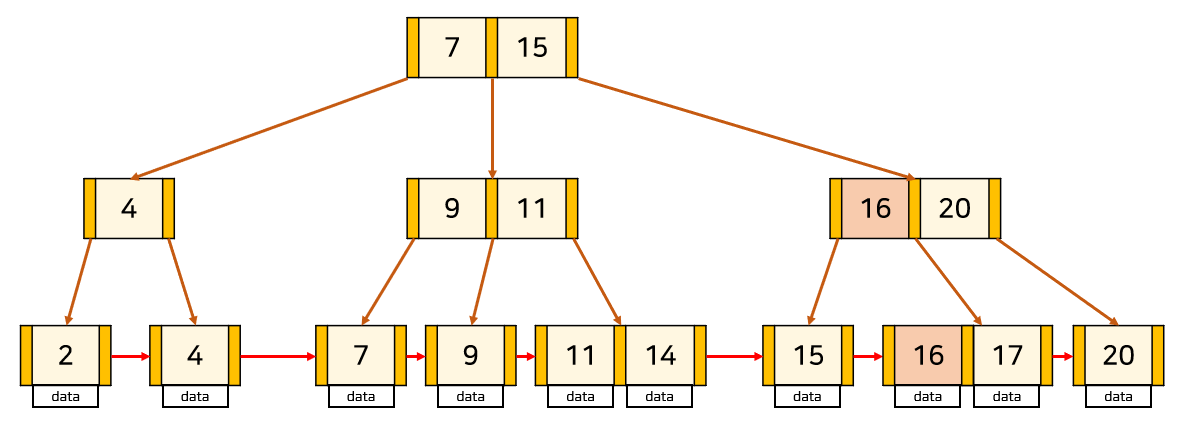
(2) Key의 수가 최대인 잎 노드에 삽입하는 경우
Key의 수가 최대이므로 삽입하는 경우 분할 해야함.
- 중간 노드에서 분할이 일어나는 경우는 B-Tree와 동일.
- 잎노드에서 분할이 일어나는 경우는 중간 키를 부모 노드로 올려주는데 이때, 오른쪽 노드에 중간 Key를 붙여 분할.
그리고 분할된 두 노드를 LinkedList로 연결
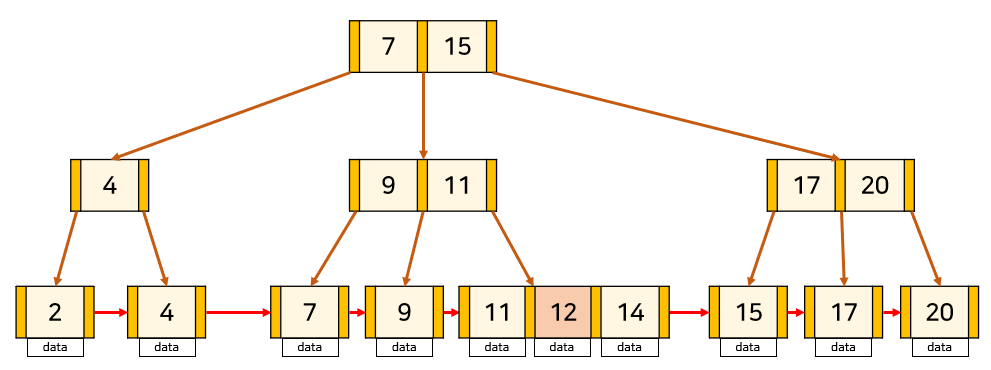
2) 삭제
(1) Key의 수가 최대보다 적은 잎노드에 삽입하는 경우
B-Tree와 동일한 방법으로 삭제
(2) Key의 수가 최대인 잎 노드에 삽입하는 경우
이 경우는 leaf node가 아닌 node에 key가 중복해서 존재한다. 따라서 해당 key를 노드보다 오른쪽에 있으면서 가장 작은 값으로 바꿔줘야 함.

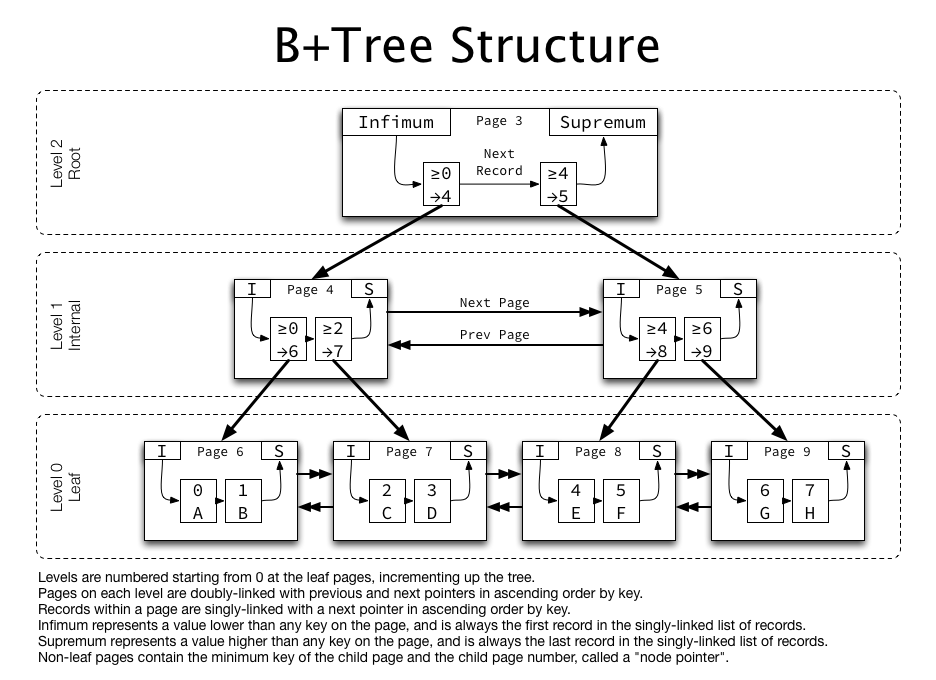
- 같은 레벨의 노드들 : Double Linked List로 연결
- 자식 노드들 : Single Linked List로 연결
참고
https://ddecode.tistory.com/entry/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4DB-4%EA%B4%80%EA%B3%84%ED%98%95-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4%EC%9D%98-%ED%82%A4key%EC%9D%98-%EC%A2%85%EB%A5%98?category=1019311
https://gyoogle.dev/blog/
https://incheol-jung.gitbook.io/docs/q-and-a/db/sql-vs-nosql
https://rebro.kr/167
