Sqoop이란,
Sqoop은 Apache Hadoop 생태계에서 RDBMS(Relational Database Management System)와 Hadoop 사이에서 데이터 전송을 쉽게 할 수 있도록 도와주는 도구입니다. Sqoop를 사용하면 Hadoop의 분산 파일 시스템인 HDFS(Hadoop Distributed File System)에 데이터를 이전할 수 있습니다. 또한, Sqoop는 RDBMS에서 Hadoop으로 데이터를 가져올 수도 있습니다. Sqoop는 간단한 명령어를 사용하여 데이터를 이전하고 가져오는 것이 가능합니다.
Hadoop으로 데이터를 이전하는 데는 일정한 프로세스가 필요합니다. 이를 위해 Sqoop는 RDBMS에 저장된 데이터를 Hadoop으로 이전하거나 Hadoop에서 데이터를 RDBMS로 이전하는 데 필요한 도구를 제공합니다. Sqoop를 사용하면 데이터베이스의 데이터를 쉽게 Hadoop으로 가져올 수 있습니다. 이를 통해 더욱 간편하게 분석하고 처리할 수 있습니다. 또한, Sqoop는 Hadoop에서 데이터를 쉽게 데이터베이스에 저장할 수 있도록 도와줍니다.
Sqoop는 데이터 전송을 위해 다양한 옵션을 제공합니다. 이러한 옵션을 이용하여 데이터 전송 과정에서 발생할 수 있는 문제를 해결할 수 있습니다. 또한, Sqoop는 다양한 데이터 포맷을 지원합니다. 이는 데이터 전송 시 데이터 포맷 변환 작업을 줄여줍니다.
이러한 Sqoop의 기능들은 많은 기업에서 데이터 분석 및 처리를 위해 사용되고 있습니다. Sqoop를 이용하면 데이터 전송 및 변환 과정을 간편하게 처리할 수 있으며, 빠른 데이터 분석 및 처리가 가능합니다.
현재는 지원하지 않는 구버전이라고 합니다.
MySQL에서 Sqoop을 활용해 hdfs에 적재(로드)
MySQL에서 Sqoop을 활용해 hdfs에 적재하는 방법은 다음과 같습니다. 먼저, Sqoop 명령어를 사용하여 MySQL 데이터베이스와 연결합니다. 이때, MySQL 데이터베이스에 대한 인증 정보와 연결하는 방법을 명시해야 합니다.
그 다음, 적재할 테이블과 적재 위치를 지정합니다. 테이블 이름을 지정해야 하며, 필요한 경우 특정 열만 선택할 수도 있습니다. 또한, 적재할 위치를 지정하는 것도 중요한데, 이는 Hadoop 클러스터의 HDFS 경로를 지정하거나, 로컬 파일 시스템에 저장할 수도 있습니다.
이후 명령어를 실행하여 데이터를 hdfs에 적재합니다. Sqoop은 이 과정에서 자동으로 데이터를 매핑하고 타입 변환을 수행합니다. 이러한 과정을 통해 MySQL 데이터를 Hadoop으로 쉽게 이전할 수 있습니다.
또한, Sqoop는 다양한 옵션을 제공하여 데이터 전송 과정에서 발생할 수 있는 문제를 해결할 수 있습니다. 예를 들어, 데이터를 전송하면서 특정 열을 필터링하거나, 데이터를 압축하거나, 병렬로 전송할 수도 있습니다. 이러한 옵션을 이용하면 데이터 전송 과정에서 생길 수 있는 문제를 미리 방지할 수 있습니다.
MySQL 데이터를 Hadoop으로 이전하는 것은 데이터 분석 및 처리를 위해 매우 중요합니다. Sqoop를 이용하면 이러한 작업을 쉽게 수행할 수 있으며, 빠른 데이터 분석 및 처리가 가능합니다.
test database 다운
스쿱 설치 전 사용할 예시 데이터를 다운로드 받고, 압축풀기
wget https://github.com/datacharmer/test_db/releases/download/v1.0.7/test_db-1.0.7.tar.gz tar xvfz test_db-1.0.7.tar.gz
압축을 푼 뒤, ls를 통해 test_db 디렉토리가 생성된 걸 확인했습니다.
이제 이 디렉토리에 있는 데이터를 mysql에 적재(로드)할 예정입니다.
test_db폴더로 들어가서 데모데이터를 mysql에 적재(로드)해줍니다.
cd test_db # test_db로 이동 ls # 확인 mysql -umulti -p1111 < employees.sql
여기에서 mysql -u마이에스큐엘유저네임 -p비밀번호 < employees.sql

mysql -umulti -pmysql -u마이에스큐엘아이디 -p 누르게되면
password를 바로 입력하면 됩니다. (육안상 보이지않은채로 입력하면 됨)
show databases; 
use 테이블명을 입력해줍니다.
use employees select * from employees limit 10; 그리고 Control + d 눌러서 빠져나오기

그리곤 test_db 위치에서 빠져나와, home위치로 돌아온 뒤 Sqoop 설치 해줍니다.
Sqoop 다운설치
cd .. # home위치로 돌아오기
wget http://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
방금 설치한 파일이름이 sqoop-1.4.7.bin__hadoop-2.6.0 길기 때문에 좀 더 짧게 sqoop-1.4.7 로 바꿔주겠습니다.
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7
Sqoop 환경변수등록
vi ~/.bashrc
i 눌러서 insert 모드로
# SQOOP_HOME export SQOOP_HOME=/path/to/sqoop-1.4.7 export PATH=$PATH:$SQOOP_HOME/bin
위의 코드를 복사붙혀넣기 넣어줍니다.
esc 누르고
:wq 눌러서 빠져나옵니다.
source ~/.bashrc
source를 이용해 현재 셀 세션에 적용 해줘야합니다.
echo $SQOOP_HOME
하게되면 잘 설치됨 확인할 수 있습니다.
커넥터 다운로드
.jar 는 자바 파일입니다.
wget https://repo.maven.apache.org/maven2/mysql/mysql-connector-java/8.0.21/mysql-connector-java-8.0.21.jarmv mysql-connector-java-8.0.21.jar $SQOOP_HOME/lib
기본적으로 스쿱은 jdbc를 활용해 RDBMS를 사용하므로, 알맞는 버전의 jdbc 커넥터를 다운받습니다. 다운받은 커넥터는 $SQOOP_HOME/lib 폴더에 옮겨줍니다.
ls $SQOOP_HOME/lib
설치파일 확인해줍니다.
Sqoop -> HDFS
스쿱을 이용해 RDBMS에 있는 데이터를 하둡에 적재(로드)
실행 중 StringUtils 관련 오류가 발생되기때문에 다음 라이브러리를 다운로드 받고, Sqoop 라이브러리에 추가 합니다.
wget https://dlcdn.apache.org//commons/lang/binaries/commons-lang-2.6-bin.tar.gztar zxvf commons-lang-2.6-bin.tar.gz
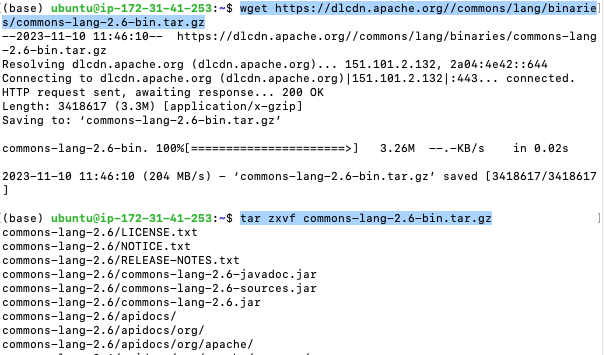
역시나 엄청난 양의 모듈이 다운받아집니다.
mv ~/commons-lang-2.6/commons-lang-2.6.jar $SQOOP_HOME/lib
mv 를 통해서 lib폴더에 있는 SQOOP_HOME파일로 이동시켜줍니다.
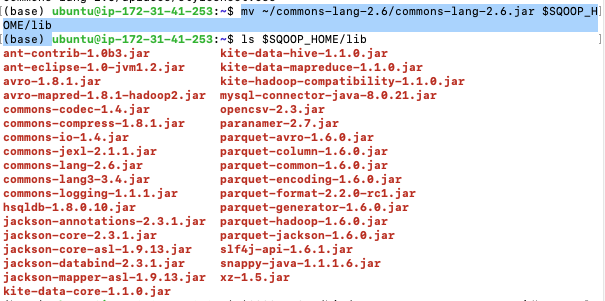
HDFS -> Sqoop
$SQOOP_HOME/bin/sqoop export --connect 'jdbc:mysql://172.31.41.253/employees' \ --username multi \ --password 1111 \ --table export_employees \ --export-dir /user/ubuntu/sqoop/employees \ --input-fields-terminated-by ',' --input-lines-terminated-by '\n'
jps하면 아무것도 안나온다.
하둡 dfs와 yarn을 실행시켜 연동해준다.
$HADOOP_HOME/sbin/start-dfs.sh $HADOOP_HOME/sbin/start-yarn.sh
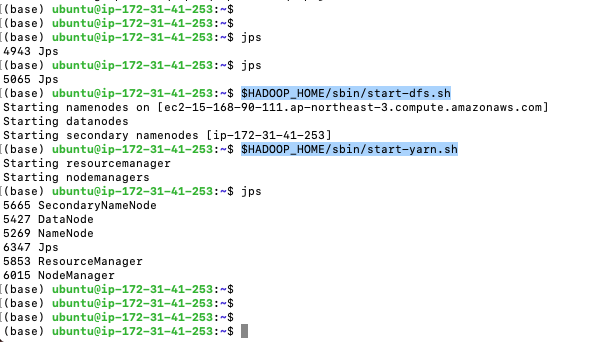
이제 하둡 실행되었다.
$SQOOP_HOME/bin/sqoop import \
--connect 'jdbc:mysql://$your_mysql_host/employees?useUnicode=true&serverTimezone=Asia/Seoul' \
--username $your_mysql_username \
--password $your_mysql_password \
--query 'SELECT e.emp_no, e.birth_date, e.first_name, e.last_name, e.gender, e.hire_date, d.dept_no FROM employees e, dept_emp d WHERE (e.emp_no = d.emp_no) AND $CONDITIONS' \
--target-dir ~/sqoop/employees \
--split-by e.emp_no위의 내용에 따라 적용합니다.
참고로 $your_mysql_host 는 현재 사용하고있는 AWS 인스턴스의 호스트 주소인, Private IPv4 addresses 로 적용합니다.
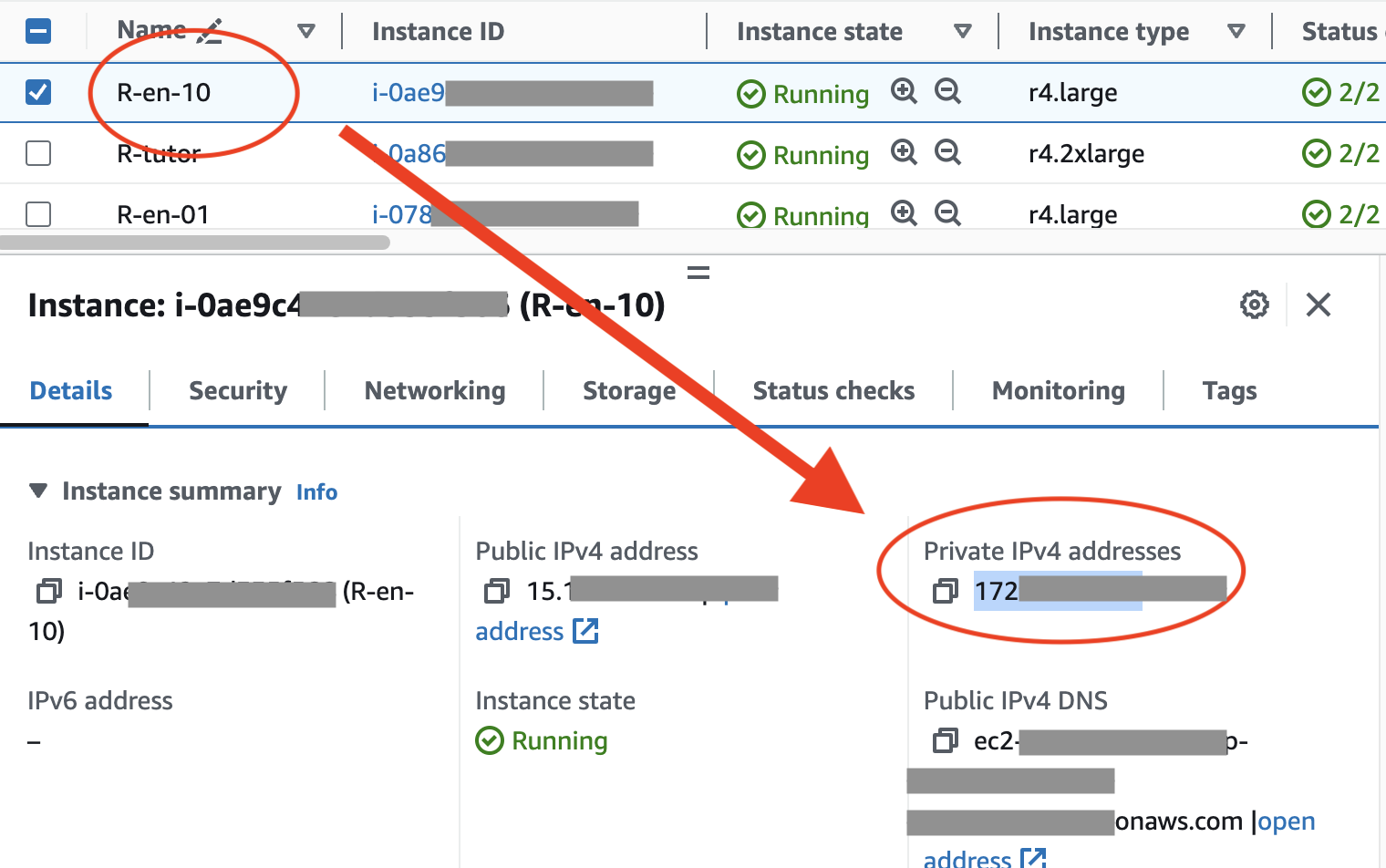
usename은 당연히 mysql등록했을때 username입니다.
mysql에 접근하기위함
$SQOOP_HOME/bin/sqoop import \ --connect 'jdbc:mysql://172.31.41.253/employees?useUnicode=true&serverTimezone=Asia/Seoul' \ --username multi \ --password 1111 \ --query 'SELECT e.emp_no, e.birth_date, e.first_name, e.last_name, e.gender, e.hire_date, d.dept_no FROM employees e, dept_emp d WHERE (e.emp_no = d.emp_no) AND $CONDITIONS' \ --target-dir /user/ubuntu/sqoop/employees \ --split-by e.emp_no

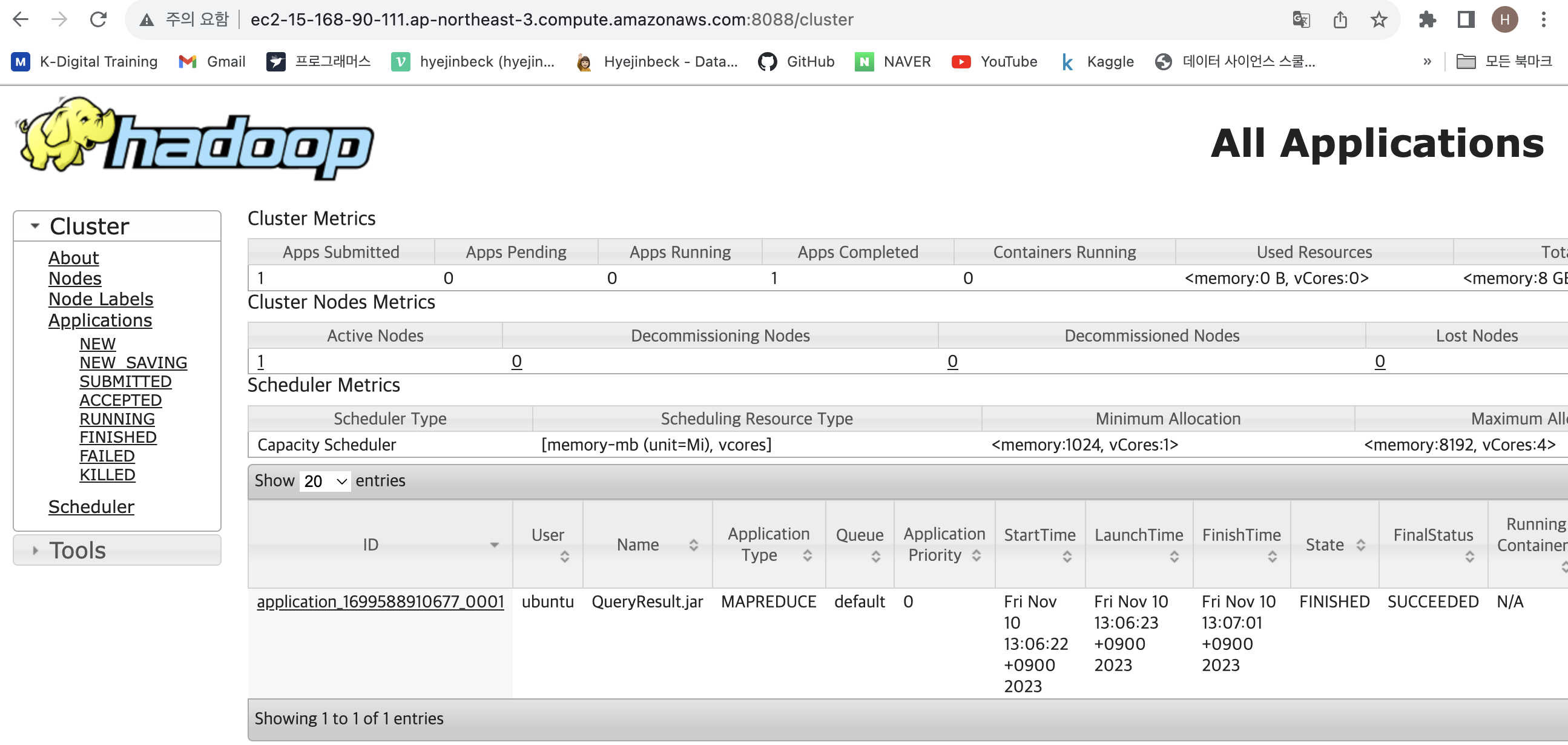
웹사이트에 입력해서 확인해봅니다.
Public IPv4 DNS 여기에 :8088을 입력합니다.
hdfs dfs -Is /user/ubuntu/sqoop
hdfs dfs -ls -R /user/ubuntu/sqoop
hdfs dfs -tail /user/ubuntu/sqoop/employees/part-m-00000mysql -umulti -puse employees;CREATE TABLE `export_employees`
(
`emp_no` int NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum ('M','F') NOT NULL,
`hire_date` date NOT NULL,
`dept_no` varchar(16) NOT NULL
);control + d 해서 빠져나오기
$SQOOP_HOME/bin/sqoop export \
--connect 'jdbc:mysql://172.31.41.253/employees?useUnicode=true&serverTimezone=Asia/Seoul' \
--username multi \
--password 1111 \
--table export_employees \
--export-dir /user/ubuntu/sqoop/employees \
--input-fields-terminated-by '\t' \
--columns emp_no,birth_date,first_name,last_name,gender,hire_date,dept_no종료
HDFS를 종료할 때는 Yarn을 먼저 종료하고, 다음에 HDFS를 종료 합니다.
$HADOOP_HOME/sbin/stop-yarn.sh $HADOOP_HOME/sbin/stop-dfs.sh
