DuckDuckGo
웹 검색
덕덕고는 웹검색엔진 중 하나입니다.
duckduckgo, openai, langchain 모듈을 설치합니다.
!pip install --upgrade --quiet duckduckgo-search openai langchain_communityfrom langchain_community.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("who's hot fashion designer in korea")누가 한국에서 잘나가는 패션 디자이너일까요?

Seoul Has Spoken—These 6 South Korean Designers Are the Ones to Watch. During fashion month, the world gets enamored by giant, conglomerate-backed luxury houses and refuses to look elsewhere. On European runways, some of our editors\' favorite brands churn out look after look to a die-hard global audience that\'s been following them for years. Founded in 1988, Solid Homme is truly a pioneer in Korean fashion and one of the first brands from the country to crossover and have international appeal. Today, it continues to create clothing ... The project started in 2010 and assists emerging Korean designers with showcasing their collections to a broader international audience. "Concept Korea NY, which has introduced a total of 34 Korean emerging designers [at NYFW since 2010], serves as an important window for presenting K-fashion to [attendees]," Lee tells TZR. Her bad-girl style is co-signed by none other than @badgalriri herself, Rihanna helped popularize Seo\'s \'Fear\' mink stole (from
???
영어로만 나오니 어지럽습니다.
한국말로 물어보겠습니다.
search.run("현재 제일 유명한 한국 패션 디자이너는 누구야?")
YouTube
웹 검색
youtube_search 모듈을 설치합니다.
!pip install --upgrade --quiet youtube_search지금 유명한 패션디자이너가 누구인지 유투브로 검색해보겠습니다.
from langchain_community.tools import YouTubeSearchTool
tool = YouTubeSearchTool()
tool.run("지금 유명한 패션디자이너가 누구야?")['https://www.youtube.com/watch?v=RVu34fdhkdk&pp=ygUx7KeA6riIIOycoOuqhe2VnCDtjKjshZjrlJTsnpDsnbTrhIjqsIAg64iE6rWs7JW8Pw%3D%3D', 'https://www.youtube.com/shorts/EOQaE4-ZZdE']
해당 유투브 url 주소를 복사하여 들어가보겠습니다.

음.......
스크립트 내용에 기반한 검색
제목 등에 대해서는 낚시질이 있을 수 있으니, 더 자세한 검색을 하기위해 유투브 스크립트 내용까지도 포함하여 검색할수 있게 해보겠습니다.
- youtube-transcript-api : 유투브 영상에 있는 자막text 를 검색
- pytube : 위와 동일
- faiss
- tiktoken
- langchain
- langchain_openai
!pip install --upgrade --quiet youtube-transcript-api pytube faiss-cpu tiktoken langchain langchain_openai물어보고 싶은 영상의 url을 가져옵니다.
이 영상의 내용에 대해 물어보겠습니다.
# From: https://towardsdatascience.com/getting-started-with-langchain-a-beginners-guide-to-building-llm-powered-applications-95fc8898732c
from langchain.document_loaders import YoutubeLoader # 유튜브 로더
from langchain.embeddings import OpenAIEmbeddings # 임베딩용
from langchain.vectorstores import FAISS # 벡터 스토어 종류 중 하나
from langchain.chains import RetrievalQA # 질문 답변 툴
from langchain_openai import ChatOpenAI # OpenAI 쓸 수 있는 툴
from pprint import pprint # 아웃풋 프린트 툴 (필요 없음)
# OpenAI 키 세팅입니다
import os, openai
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('openai')
openai.api_key = os.getenv("OPENAI_API_KEY")
# 임베딩이 필요한데요, 자세한건 다음 파트에서 다룰게요!
embeddings = OpenAIEmbeddings()
# 유튜브 링크에서 자막 내용 가지고 옵니다 ----> 유명패션디자이너 "톰프라운"의 인터뷰 영상 url 주소
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=e-HZ2TIVULI")
documents = loader.load()
# 벡터스토어 만듭니다. 이것도 다음 파트에서 자세하게 다루겠습니다!
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever()
# 이제 언어모델 쓸 거 만들어두고요..
llm = ChatOpenAI(model_name="gpt-4")
# RetrievalQA 를 써서 "가져오는 기계" 만듭니다
qa = RetrievalQA.from_chain_type(
llm=llm,
# chain_type="stuff",
retriever=retriever,
return_source_documents=True)참고로 좀 더 깔끔한 답변을 얻기 위한 과정

좀 더 깔끔하게 답변을 얻기 위한 과정은 생략하고 pprint로 출력해봅니다.
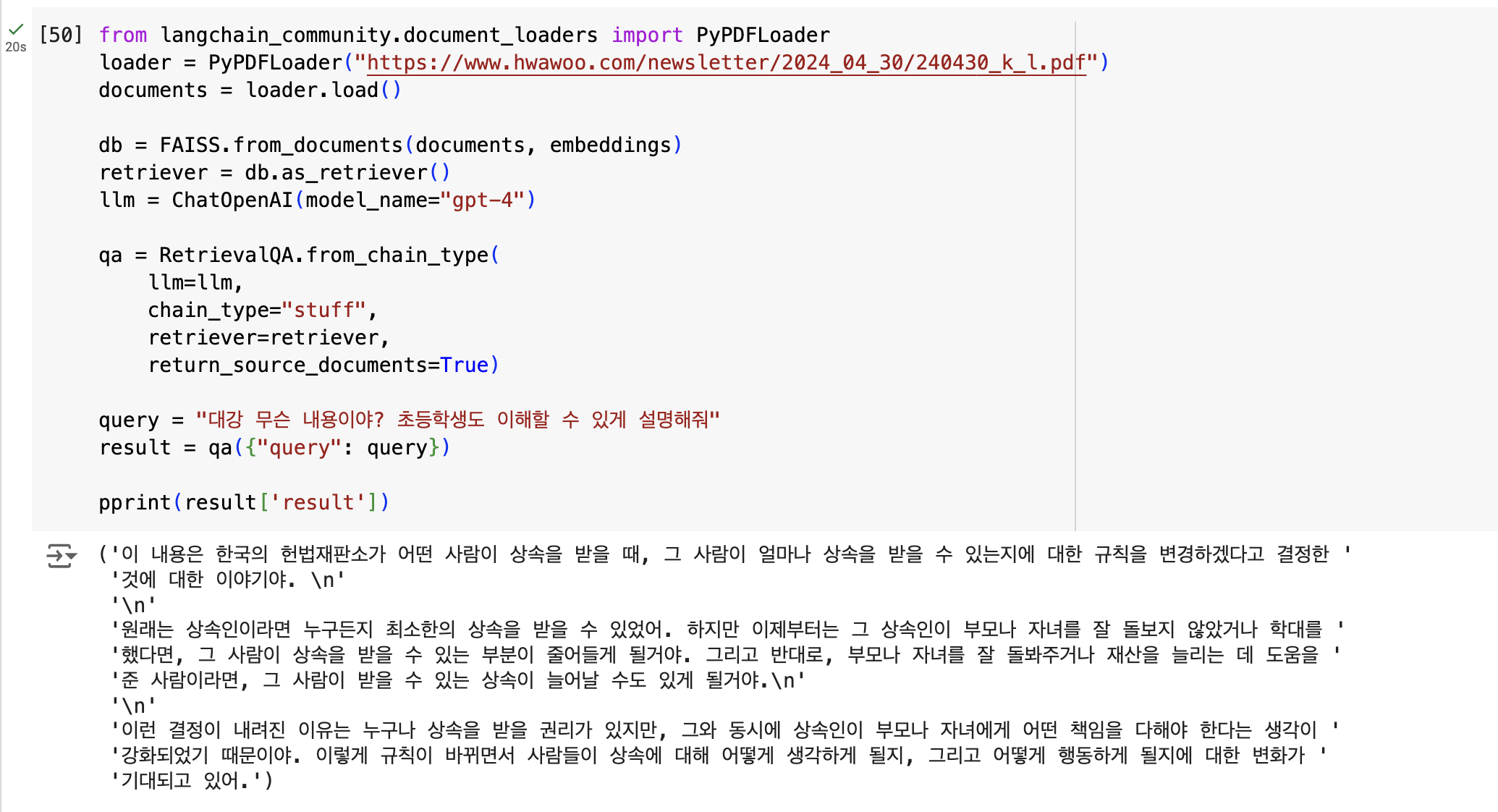
# 질문 정의하고 물어봅니다.
query = "What is the topic of this video?" # 이 영상에서 말하고 있는 주제가 뭐야?
result = qa({"query": query})
pprint(result['result'])영어 울렁증.....
한국말로 요약해달라고 할겁니다.
query = "이 영상에서 말하고 있는 주제가 무엇인지 한국말로 말해줘"
result = qa({"query": query})
pprint(result['result'])
한국영상 물어보기
물어보고 싶은 영상으로는 이걸로 결정했습니다.
다른 이유는 없고 그냥 '한국 패션디자이너'를 검색했더니 제일 먼저 나왔기 때문입니다.
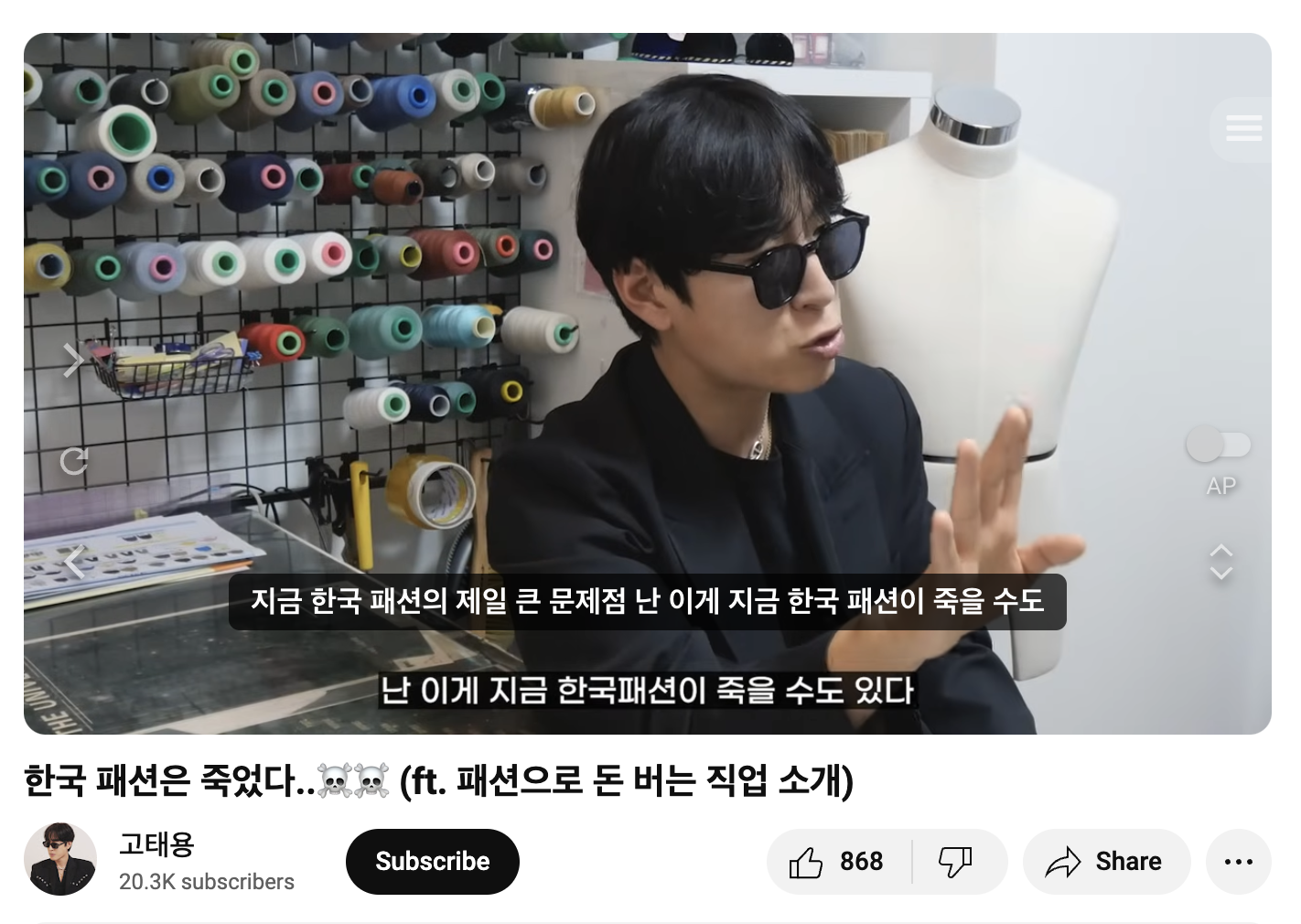
# 로딩을 한국어로
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=zITOBfuWyHE", language='ko')
documents = loader.load()
# create the vectorestore to use as the index
# 가지고온 자막을 문장 하나하나를 벡터DB로 만듭니다.
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever()
llm = ChatOpenAI(model_name="gpt-4")
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
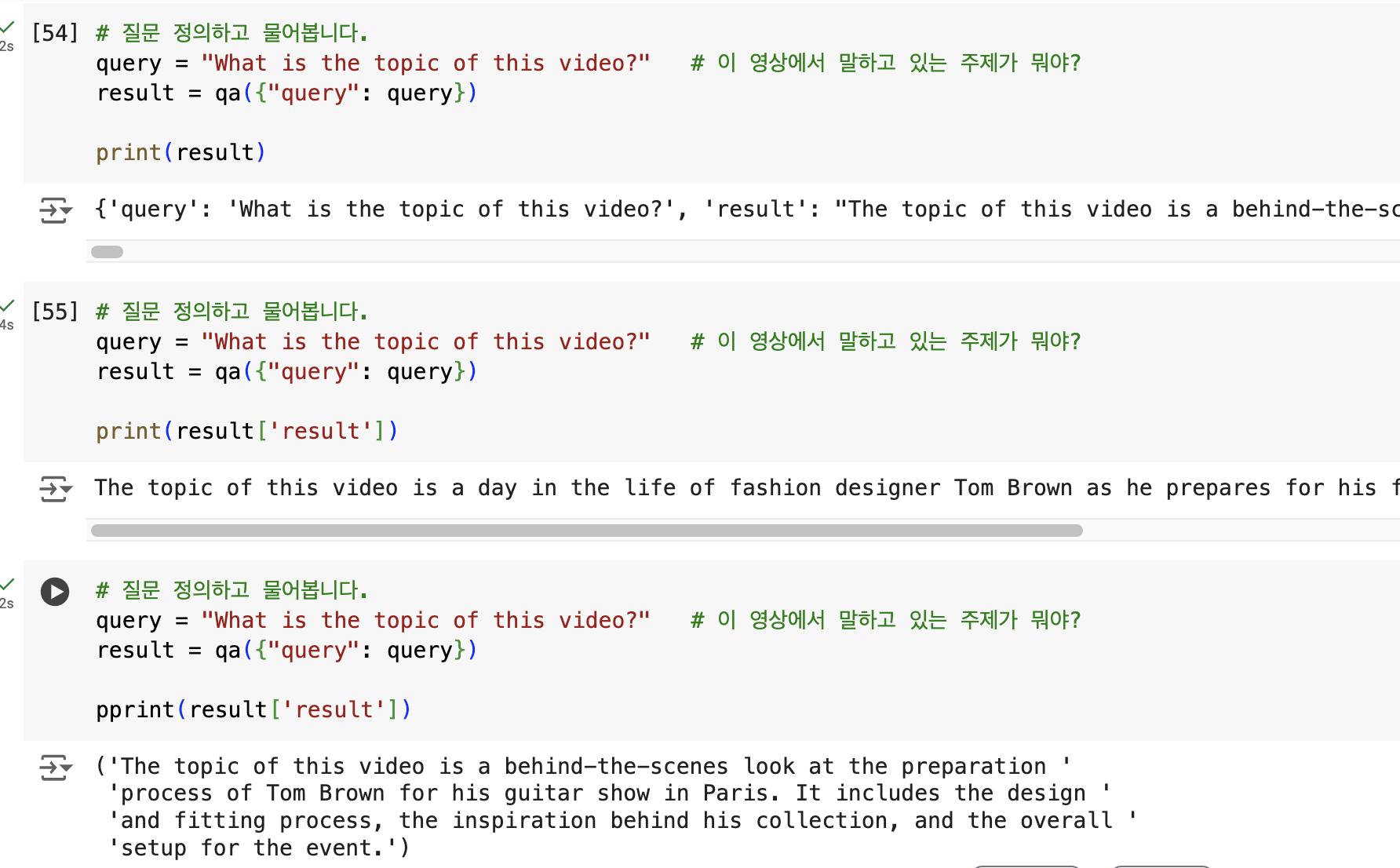
query = "대강 무슨 내용이야?"
result = qa({"query": query})
pprint(result['result'])('이 내용은 한국 패션 산업의 현실과 여러 패션 관련 직업에 대해 이야기하고 있습니다. 패션 디자이너, 스타일리스트, 패션 에디터, '
'포토그래퍼, 헤어 메이크업 아티스트 등 다양한 직업들의 역할과 중요성을 설명하며, 각 직업이 패션 산업에서 어떻게 작용하는지 설명하고 '
'있습니다. 또한, 현대 패션 산업에서의 새로운 직업들, 예를 들어 패션 인플루언서와 리셀러에 대해서도 언급하고 있습니다. 한편, 한국 '
'패션 산업의 문제점 중 하나로 젊은 사람들이 패션에 대한 열정이 떨어져, 패션 관련 학과나 신입생 수가 줄어들고 있다는 점을 지적하고 '
'있습니다.')
# 자꾸 반복되는데 그냥 함수로 만들면 더 쉬울 것 같습니다.
def ask_youtube(url, q, language='en'): # url주소의 영상에 대한 + 질문을 + 영어로
loader = YoutubeLoader.from_youtube_url(url, language=language)
documents = loader.load()
# create the vectorestore to use as the index
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever()
llm = ChatOpenAI(model_name="gpt-4-turbo-preview")
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
return qa({"query": q})이렇게 함수로 만든 후, 더 간단하게 다양한 질문들을 하겠습니다.
print(ask_youtube("https://www.youtube.com/watch?v=zITOBfuWyHE", "그래서 말하고 있는 사람이 도대체 누구야?", language="ko"))
print로도 질문해보고
pprint로 질문해서 좀 더 엔터로 가독성 좋게 출력도 해봅니다.
PDF 요약 해달라고하기 (url주소)
!pip install --quiet pypdf물어볼 pdf 로는 구글 검색 대강 했을때 첫번째 나오는 걸로 가져왔습니다.
다른 의미는 없습니다.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("https://www.hwawoo.com/newsletter/2024_04_30/240430_k_l.pdf")
documents = loader.load()
db = FAISS.from_documents(documents, embeddings)
retriever = db.as_retriever()
llm = ChatOpenAI(model_name="gpt-4")
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
query = "대강 무슨 내용이야? 초등학생도 이해할 수 있게 설명해줘"
result = qa({"query": query})
pprint(result['result'])('이 내용은 한국의 헌법재판소가 어떤 사람이 상속을 받을 때, 그 사람이 얼마나 상속을 받을 수 있는지에 대한 규칙을 변경하겠다고 결정한 '
'것에 대한 이야기야. \n'
'\n'
'원래는 상속인이라면 누구든지 최소한의 상속을 받을 수 있었어. 하지만 이제부터는 그 상속인이 부모나 자녀를 잘 돌보지 않았거나 학대를 '
'했다면, 그 사람이 상속을 받을 수 있는 부분이 줄어들게 될거야. 그리고 반대로, 부모나 자녀를 잘 돌봐주거나 재산을 늘리는 데 도움을 '
'준 사람이라면, 그 사람이 받을 수 있는 상속이 늘어날 수도 있게 될거야.\n'
'\n'
'이런 결정이 내려진 이유는 누구나 상속을 받을 권리가 있지만, 그와 동시에 상속인이 부모나 자녀에게 어떤 책임을 다해야 한다는 생각이 '
'강화되었기 때문이야. 이렇게 규칙이 바뀌면서 사람들이 상속에 대해 어떻게 생각하게 될지, 그리고 어떻게 행동하게 될지에 대한 변화가 '
'기대되고 있어.')