
IMLS의 워싱턴과 사모아를 포함한 모든 지역의 공립 도서관 기관의 설문조사 데이터셋
2018년, 2017년, 2016년 조사 데이터를 저장할 수 있는 3개의 테이블 생성하고
각 테이블에서 시간이 지남에 따라 측정값이 어떻게 변하는지 살펴보겠습니다.
데이터불러오기
테이블 생성
-- 2018년도 공공도서관 설문조사 테이블 만들기
CREATE TABLE pls_fy2018_libraries (
stabr text NOT NULL,
fscskey text CONSTRAINT fscskey_2018_pkey PRIMARY KEY,
libid text NOT NULL,
libname text NOT NULL,
address text NOT NULL,
city text NOT NULL,
zip text NOT NULL,
county text NOT NULL,
phone text NOT NULL,
c_relatn text NOT NULL,
c_legbas text NOT NULL,
c_admin text NOT NULL,
c_fscs text NOT NULL,
geocode text NOT NULL,
lsabound text NOT NULL,
startdate text NOT NULL,
enddate text NOT NULL,
popu_lsa integer NOT NULL,
popu_und integer NOT NULL,
centlib integer NOT NULL,
branlib integer NOT NULL,
bkmob integer NOT NULL,
totstaff numeric(8,2) NOT NULL,
bkvol integer NOT NULL,
ebook integer NOT NULL,
audio_ph integer NOT NULL,
audio_dl integer NOT NULL,
video_ph integer NOT NULL,
video_dl integer NOT NULL,
ec_lo_ot integer NOT NULL,
subscrip integer NOT NULL,
hrs_open integer NOT NULL,
visits integer NOT NULL,
reference integer NOT NULL,
regbor integer NOT NULL,
totcir integer NOT NULL,
kidcircl integer NOT NULL,
totpro integer NOT NULL,
gpterms integer NOT NULL,
pitusr integer NOT NULL,
wifisess integer NOT NULL,
obereg text NOT NULL,
statstru text NOT NULL,
statname text NOT NULL,
stataddr text NOT NULL,
longitude numeric(10,7) NOT NULL,
latitude numeric(10,7) NOT NULL
);- pls : Public Libraries Survey의 약자이며
미국에서 주립 도서관 및 도서관 서비스에 대한 통계 데이터를 수집하고 보고하는 연례 조사를 말합니다. - fy2018 : 데이터가 다루는 회계 연도
- libraries : 설문조사의 특정 파일 이름
데이터 불러오기
-- 2018년도 공공도서관 설문조사 데이터 가져오기
COPY pls_fy2018_libraries
FROM '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_09/pls_fy2018_libraries.csv'
WITH (FORMAT CSV, HEADER);인덱스 추가
-- 2018년도 공공도서관 설문조사 데이터 검색할때, 더 빠르게 하기위해 libname열에 인덱스 추가
CREATE INDEX libname_2018_idx ON pls_fy2018_libraries (libname);현재 2018년도 데이터만 가져왔습니다.
2017, 2016년도 테이블도 만들고 데이터도 가져오겠습니다.
방식은 동일합니다.
세 테이블이 동일한 구조를 가지고 있습니다.
대부분의 설문조사는 매년 약간씩 변화가 있을 수도 있다곤 합니다.
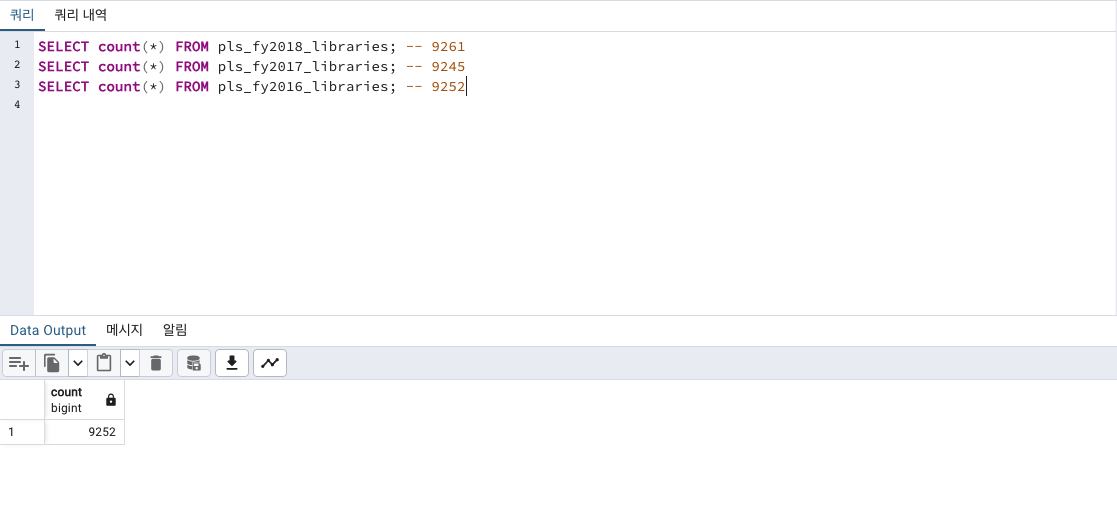
COUNT
전체 행rows 갯수
총 몇 행이 있는지 확인하겠습니다.
SELECT COUNT(*) FROM 테이블명;
열 안에 Null 수
SELECT COUNT(컬럼명) FROM 테이블명;
COUNT()안에 컬럼명을 입력하면, 해당 컬럼의 NULL이 아닌 값의 갯수가 나옵니다.
-- 전체 행의 갯수
SELECT count(*) FROM pls_fy2018_libraries; -- 9261
-- 해당 (컬럼)의 결측치가 아닌 값 갯수
SELECT count(libname) FROM pls_fy2018_libraries; -- 9261
-- stabr 컬럼에는 Null 값이 없습니다!
-- 물론 CREATE TABLE 에서 NOT NULL 조건을 달았기 때문에 있을수가 없습니다!열 안에 고유값 수
고유값 갯수를 세기에는 DISTINCT 를 사용할수 있습니다.
DISTINCT는 고유한 값의 목록을 나오는데요
COUNT (DISTINCT 컬럼명) 을 하게되면, 해당 컬럼의 고유한 값의 갯수를 확인할 수 있습니다.
-- 해당 (컬럼)의 결측치가 아닌 값 갯수
SELECT count(libname) FROM pls_fy2018_libraries; -- 9261
-- 해당 (컬럼)의 고유한 값의 갯수
SELECT count(DISTINCT libname) FROM pls_fy2018_libraries; -- 8478
-- libname : 도서관 이름
-- DISTINCT 중복값을 제거한 고유의 도서관 이름 목록 MAX와 MIN
최대값과 최소값 구하기
SELECT MAX(컬럼명) FROM 테이블명;
SELECT MIN(컬럼명) FROM 테이블명;
SELECT MAX(컬럼명), MIN(컬럼명) FROM 테이블명;
-- 해당 (컬럼)의 최대값과 최소값 구하기
SELECT max(visits), min(visits) FROM pls_fy2018_libraries;
-- -1 : 해당 질문에 대한 '응답없음'
-- -3 : 도서관이 일시적 또는 영구적 폐쇄된 경우
-- 데이터를 탐색할 때는 음수값을 고려하고 제외해야 합니다. (WHERE절 이용)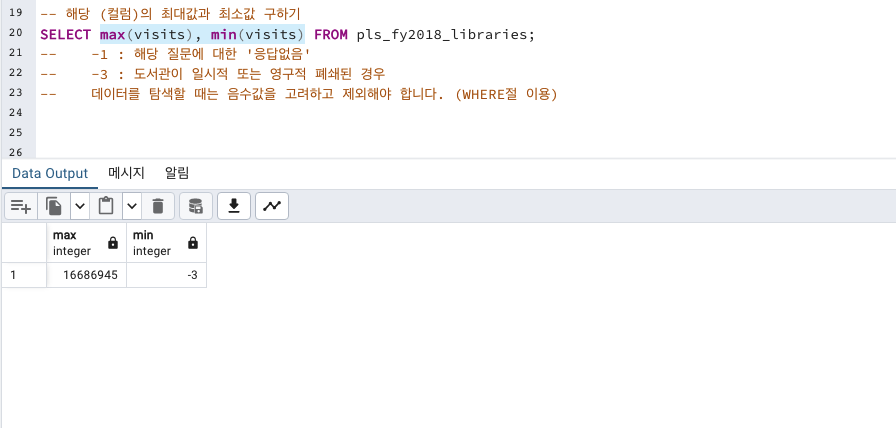
GROUP BY
DISTINCT와 유사하게 결과에서 중복값을 제거합니다.
SELECT 컬럼명1,, FROM 테이블명;
GROUP BY 컬럼명1,,
중복값을 제거한 컬럼명1의 목록 확인
어느 주에 도서관이 많을까요?
필요 컬럼 : 주 (stabr), 도서관 rows 갯수는 count(*)로
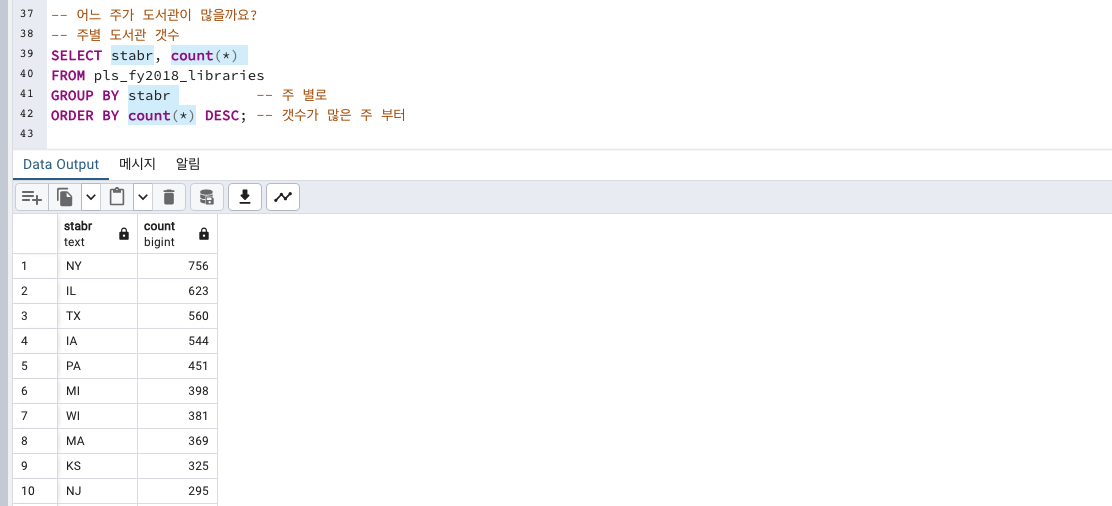
NY 뉴욕주 > IL 일리노이주 > TX 텍사스 주 순으로 2018년 가장 많은 도서관 기간을 보유했습니다.
SUM
총 도서관 방문자 수
2018년, 2017년, 2016년의 각각 총 도서관 방문자 수를 확인해보겠습니다.
SELECT sum(방문자열)
FROM 테이블명
WHERE 방문자열 >=0 ;
참고로 방문자열 visits 에는 도서관이 폐쇄되었거나 응답없음을 나타내는 음수가 있다고 합니다. 따라서 방문값이 0 이상인 값을 WHERE로 필터링 해줍니다.
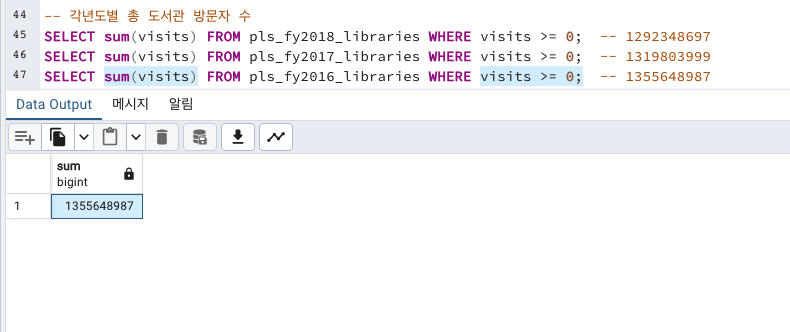
점점 방문자수가 하락하고 있습니다.
보기 쉽게 3개의 테이블을 JOIN으로 합쳐서 한 번에 결과물을 보겠습니다.
PK키로 설정했던 fscskey 로 합치겠습니다.
-- 2018, 2017, 2016 각 도서관 데이터를 JOIN 으로 병합하여 방문자수(visits)확인
SELECT
2018년데이터의 방문자수의 합계
,2017년데이터의 방문자수의 합계
,2016년데이터의 방문자수의 합계
FROM 2018년도테이블 as 별칭으로서,2018년데이터
JOIN 2017년도테이블 as 2017년데이터 ON 2018년데이터.fscskey = 2017년데이터.fscskey
JOIN 2016년도테이블 as 2016년데이터 ON 2018년데이터.fscskey = 2016년데이터.fscskey
WHERE
2018년데이터.방문자 >= 0
AND 2017년데이터.방문자 >= 0
AND 2016년데이터.방문자 >= 0 역시나 FROM 절 (JOIN 포함) 에서 as로 테이블명을 좀 더 간단하게 해주고 나머지 절들에서 그 별칭을 사용해주겠습니다.
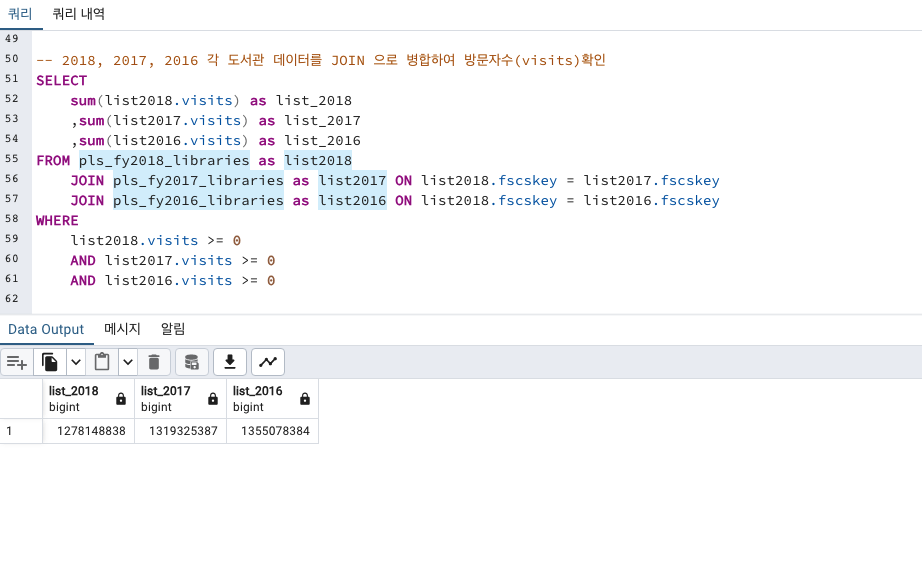
Wifi 네트워크 연결 수
위의 코드를 visits -> wifisess 로 바꾸어
2018,2017,2016년별 총 와이파이 네트워크 연결 수도 감소세인지 확인해보겠습니다.
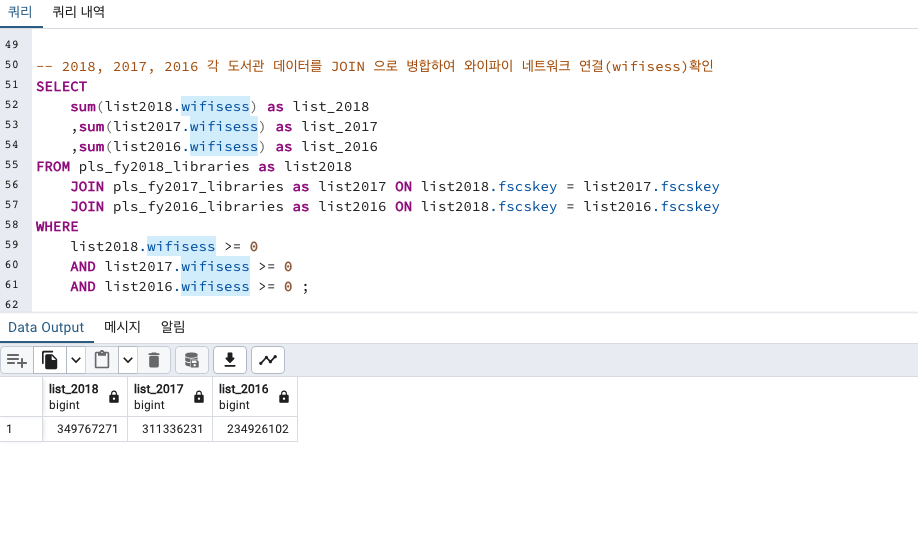
오히려 사람들이 와이파이 연결한 횟수는 증가했습니다!
주별 도서관 방문 변화율
미국 전국적으로 도서관 방문 수가 2016~2018년 사이 점점 줄어들고 있습니다.
어느 주가 하락세가 있고 그 중에서도 상승하고 있는 주는 어디일까요?
주별 추세를 확인해보겠습니다.
코드가 길어지니 작성순서순으로 정리해보겠습니다.
먼저 FROM 으로 2018년테이블과 JOIN 2017년 테이블,2016년테이블을 합쳐줍니다. 여기서 각 테이블에게 as 별칭을 주어 나머지 절에 간단하게 입력할수있도록 합니다.
FROM
pls_fy2018_libraries as pls2018
JOIN pls_fy2017_libraries as pls2017 ON pls2018.fscskey = pls2017.fscskey
JOIN pls_fy2016_libraries as pls2016 ON pls2018.fscskey = pls2016.fscskey이제 합쳐진 2016~2018 도서관 테이블에서 SELECT로 값을 가져오겠습니다.
- 주 stabr 컬럼 (어자피 3개의 테이블이 합쳐져서 그 중 1개만 가져옵니다)
- pls2018 의 방문자수 합계
- pls2017 의 방문자수 합계
- pls2016 의 방문자수 합계
- 그리고 전년도 대비 최신년도의 방문자수 변화율
- (pls2018방문자수합계 - pls2017방문자수합계) / pls2017방문자수합계 * 100
- (pls2017방문자수합계 - pls2016방문자수합계) / pls2016방문자수합계 * 100
- 백분율이기때문에 cast(컬럼명 on NUMERIC) 또는 ::NUMERIC 변환
- 그리곤 round( , 1) 로 소수점 1자리에서 반올림
SELECT
pls2018.stabr
, sum(pls2018.visits) as visits18
, sum(pls2017.visits) as visits17
, sum(pls2016.visits) as visits16
-- , (sum(pls2018.visits::numeric) - sum(pls2017.visits)) / sum(pls2017.visits) * 100
-- , round( (sum(pls2018.visits::numeric) - sum(pls2017.visits)) / sum(pls2017.visits) * 100 , 1)
, round( (sum(pls2018.visits::numeric) - sum(pls2017.visits)) / sum(pls2017.visits) * 100 , 1) as chg_2018_7
, round( (sum(pls2017.visits::numeric) - sum(pls2016.visits)) / sum(pls2016.visits) * 100 , 1) as chg_2017_6이제 주별 도서관 방문 변화율을 위해 sum()도 넣어주고 변화율도 넣어줬습니다.
이럴경우 꼭 GROUP BY 기재를 해줘야 합니다. 없으면 에러납니다.

GROUP BY pls2018.stabr그리곤 방문자 visits 열의 음수들을 필터링으로 걸러주게끔 WHERE 절도 적어줍니다.
WHERE 절에는 콤마,로 구분하는것이 아니라 AND 나 OR 로 필터링 걸어줘야하는걸 늘 까먹습니다..!
WHERE
pls2018.visits >= 0
AND pls2018.visits >= 0
AND pls2018.visits >= 0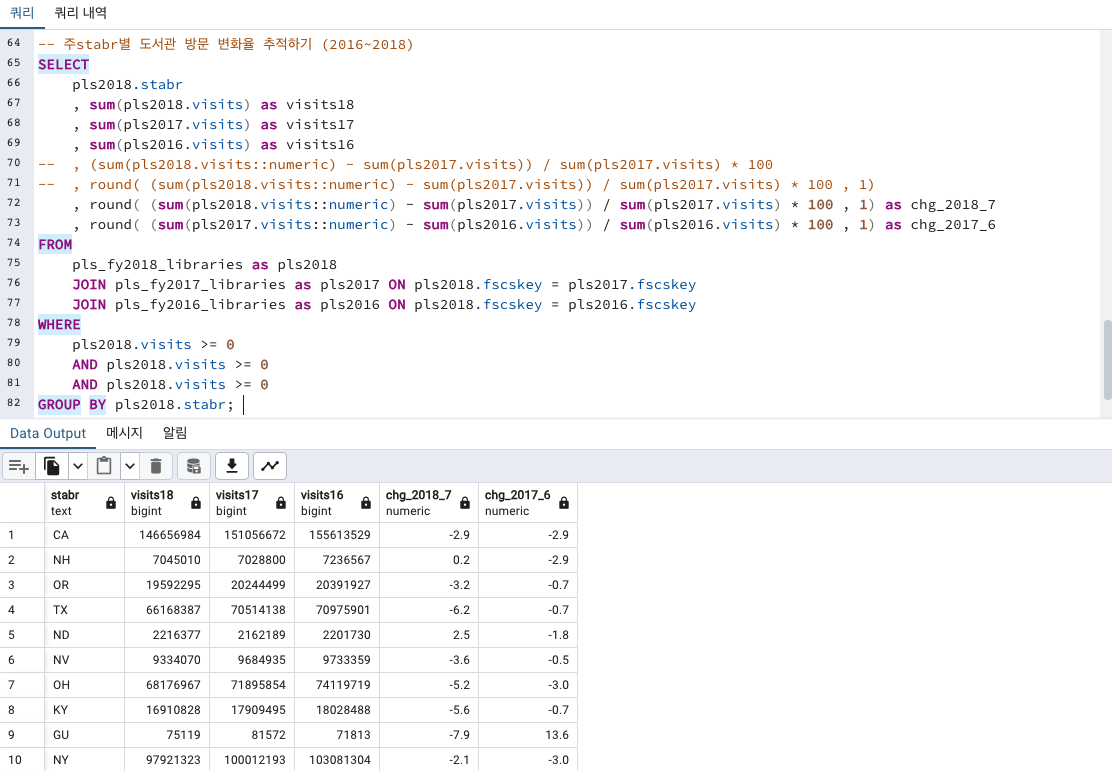
보기쉽게 2017년대비 2018년의 방문자수 증감율을 기준으로 정렬해보겠습니다.
-- 주stabr별 도서관 방문 변화율 추적하기 (2016~2018)
SELECT
pls2018.stabr
, sum(pls2018.visits) as visits18
, sum(pls2017.visits) as visits17
, sum(pls2016.visits) as visits16
-- , (sum(pls2018.visits::numeric) - sum(pls2017.visits)) / sum(pls2017.visits) * 100
-- , round( (sum(pls2018.visits::numeric) - sum(pls2017.visits)) / sum(pls2017.visits) * 100 , 1)
, round( (sum(pls2018.visits::numeric) - sum(pls2017.visits)) / sum(pls2017.visits) * 100 , 1) as chg_2018_7
, round( (sum(pls2017.visits::numeric) - sum(pls2016.visits)) / sum(pls2016.visits) * 100 , 1) as chg_2017_6
FROM
pls_fy2018_libraries as pls2018
JOIN pls_fy2017_libraries as pls2017 ON pls2018.fscskey = pls2017.fscskey
JOIN pls_fy2016_libraries as pls2016 ON pls2018.fscskey = pls2016.fscskey
WHERE
pls2018.visits >= 0
AND pls2018.visits >= 0
AND pls2018.visits >= 0
GROUP BY pls2018.stabr
ORDER BY chg_2018_7 DESC; 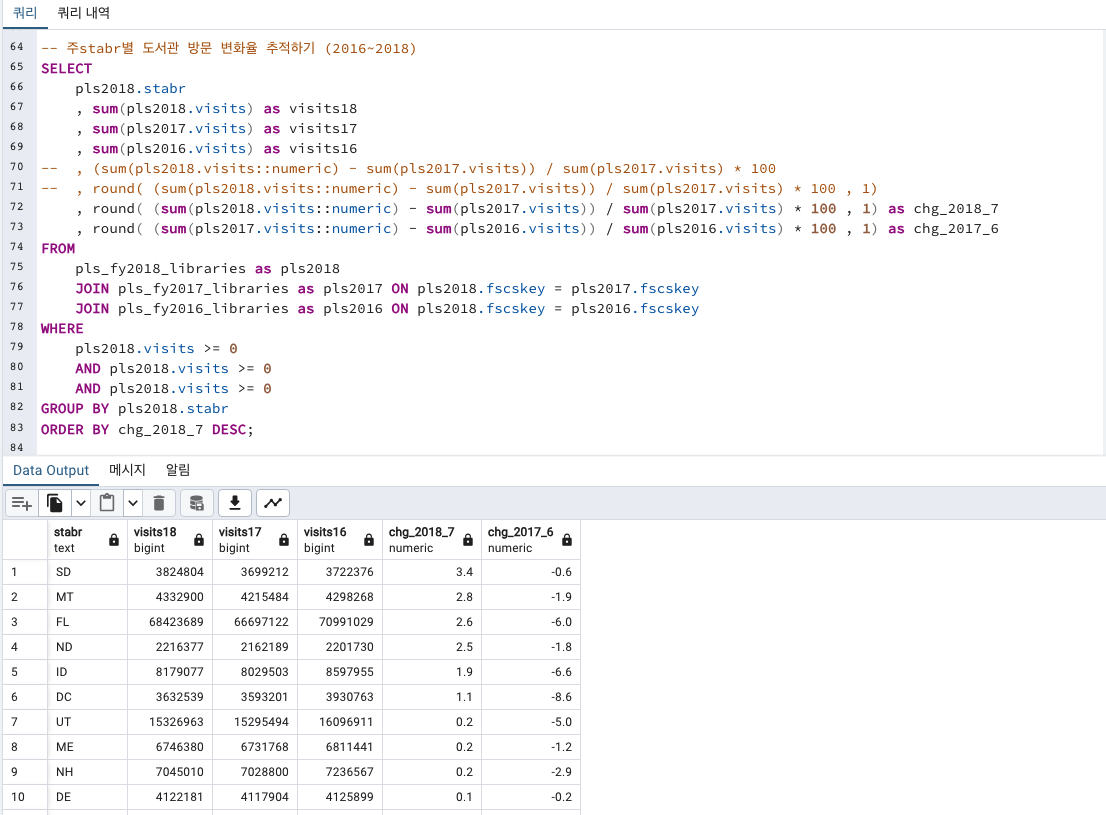
HAVING
위에 있는 GROUP BY 절에 필터링을 걸어주기위한 HAVING 절입니다.
GROUP BY 바로 뒤에
HAVING 조건절
방문수가 큰 도서관 중 방문수 증가한 지역
그래서 어느 주의 도서관이 2016~2018 방문자수가 증감했는지 파악했는데요,
2018년도 방문 수가 5000만 이상인 큰 값만 보고 싶습니다.
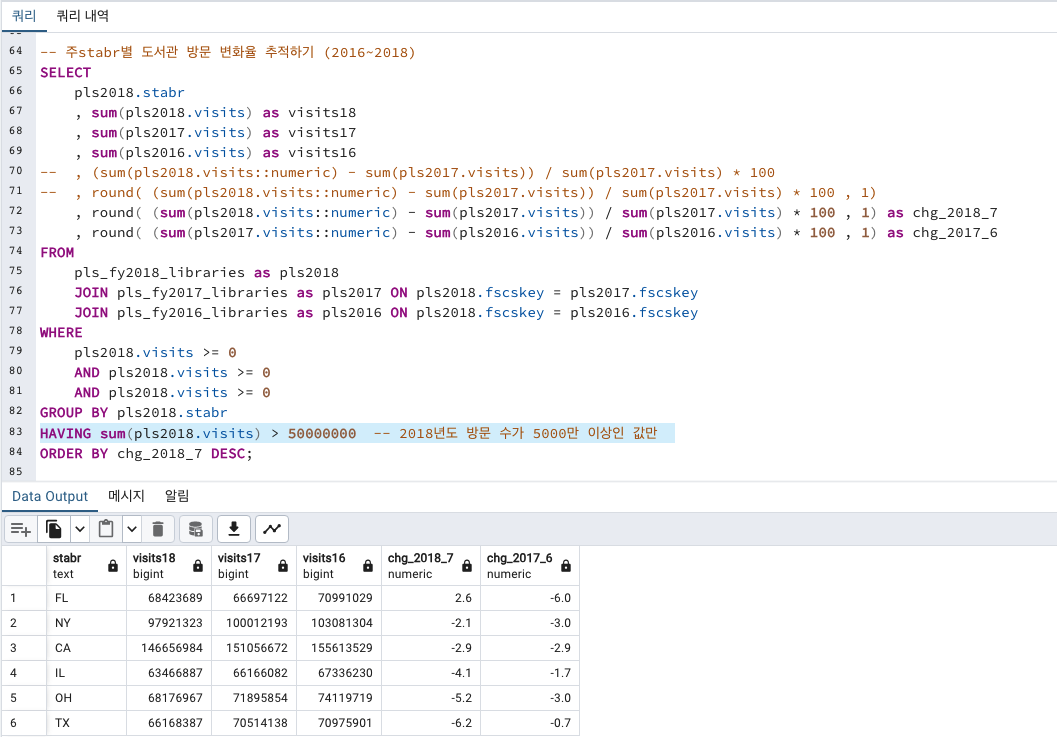
2018년도에 5000만명 이상 방문한 지역은 총 6곳으로 확인됩니다.
FL 플로리다주가 작년에 비해 유일하게 방문 수가 증가했습니다.
나머지 주들은 모두 방문 수가 하락하고 있습니다.
문제
도서관 방문 횟수는 점차 감소하는 추세입니다.
그렇다면 도서관의 고용패턴은 어떨까요?
정규직 직원 수 (totstaff) 의 추이또한 확인해보고 싶습니다.
주별 정규직 추세
위의 visits 을 totstaff 를 바꿔서 확인해보겠습니다.
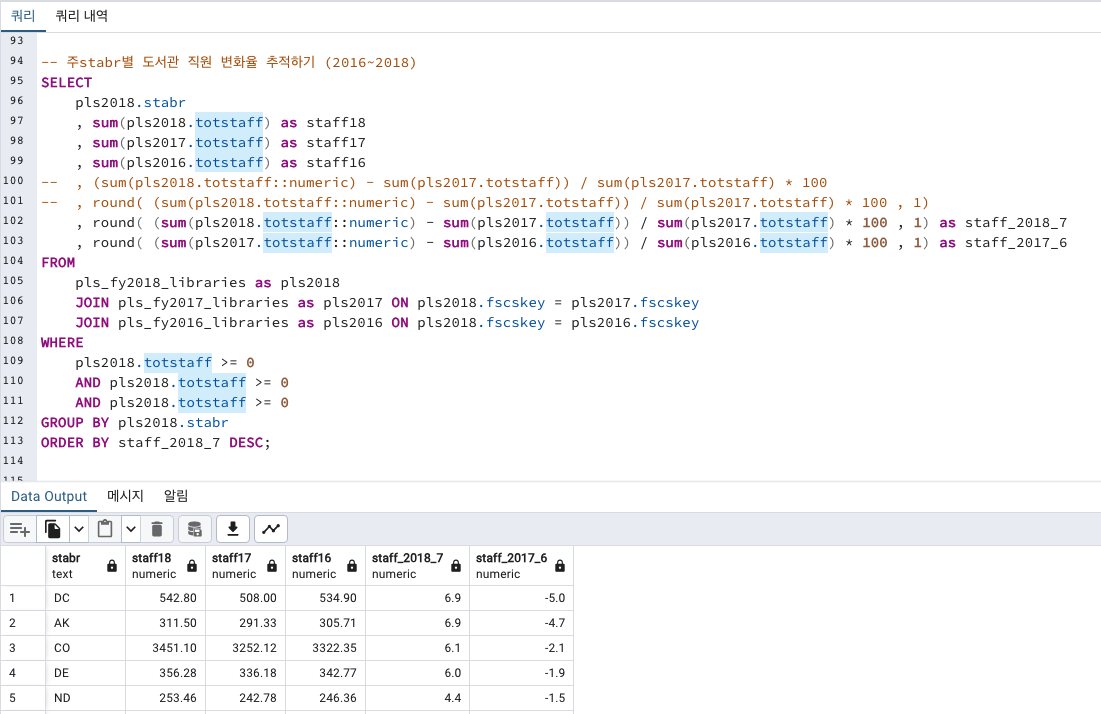
DC > AK > CO 순으로 2018년도 정직원 고용률이 올라갔습니다.
SELECT 절에 도서관 방문자수 증감률 컬럼도 추가해서 같이 비교해보겠습니다.
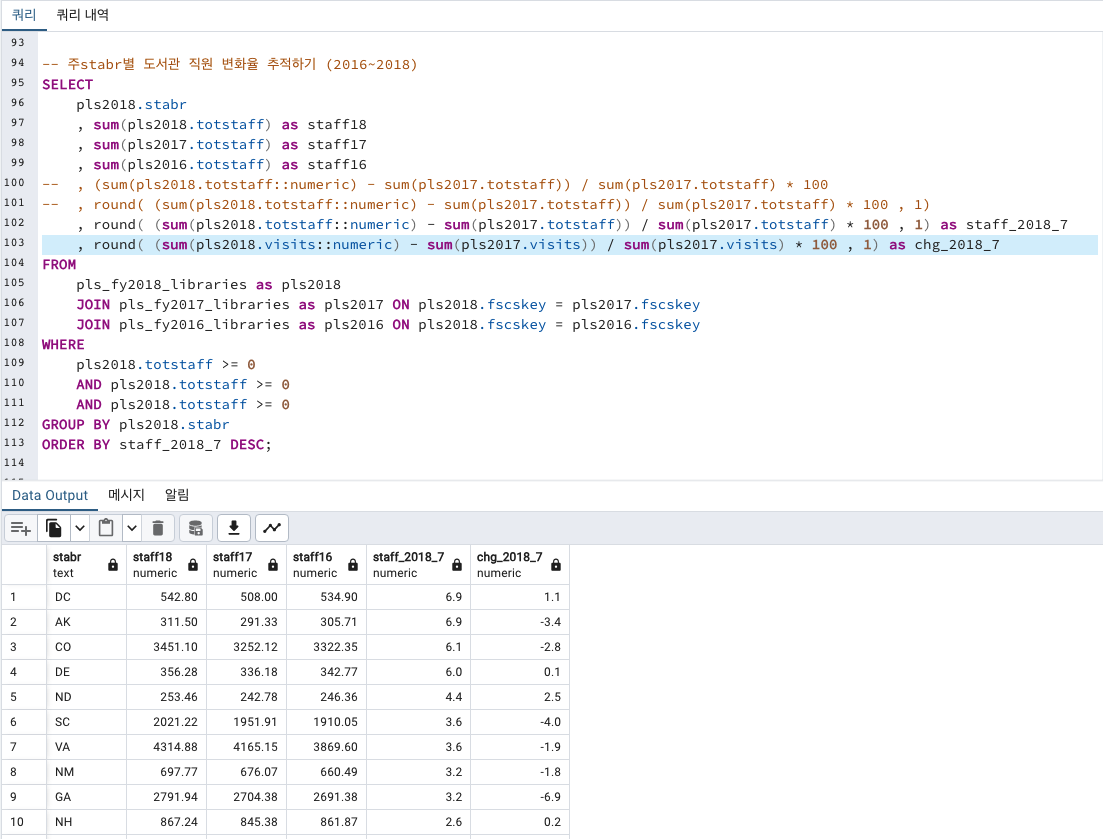
정직원 고용률이 올라간 주를 봤을때, AK주는 전년대비 방문수가 줄어들었지만 직원 고용률은 올라갔습니다.
