미리보기
데이터 정리
data.info()
data.head(2)
# 불필요한 컬럼 삭제
stats = data.drop(['주소', '역전화번호', 'lat', 'lng','호선'], axis=1)
stats.head()
stats['역명'].unique()
stats.loc[stats['역명'] == '강남']
stats.loc[stats['역명'] == '강남'].iloc[:, 1:-1]
stats.loc[stats['역명'] =='강남'].iloc[:, 1:-1].values # 2차원 
np.squeeze(stats.loc[stats['역명'] =='강남'].iloc[:, 1:-1].values) # 1차원 
그래프 차트
강남역
place = '강남'
plt.figure(figsize=(10, 6))
sns.pointplot(x=np.arange(1, 13), y=np.squeeze(stats.loc[stats['역명'] ==place].iloc[:, 1:-1].values))
plt.show()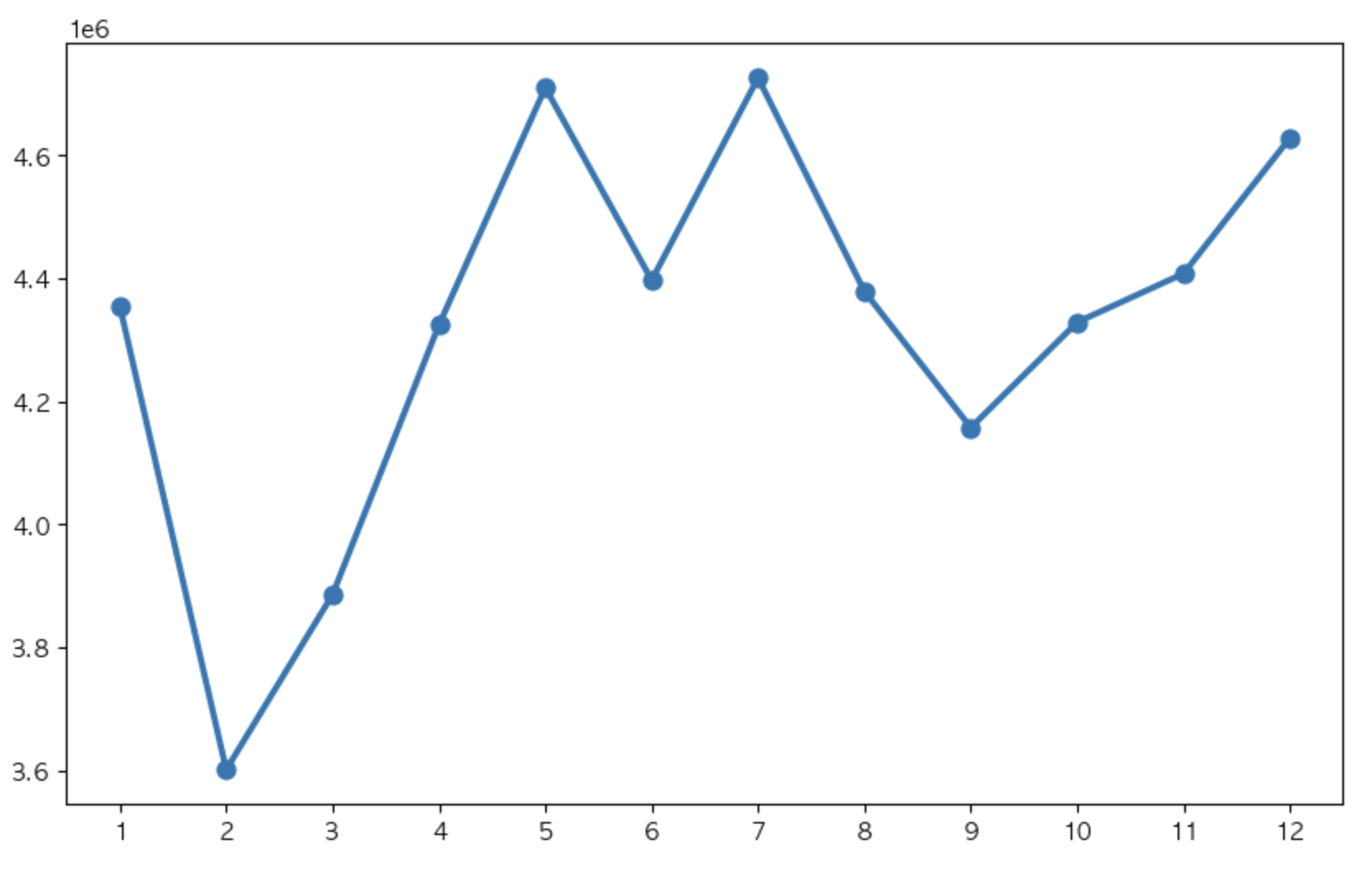
강남역,한양대역
place1 = '강남'
place2 = '한양대'
plt.figure(figsize=(10, 6))
sns.pointplot(x=np.arange(1, 13), y=np.squeeze(stats.loc[stats['역명'] ==place1].iloc[:, 1:-1].values),color='black')
sns.pointplot(x=np.arange(1, 13), y=np.squeeze(stats.loc[stats['역명'] ==place2].iloc[:, 1:-1].values),color='red')
plt.show()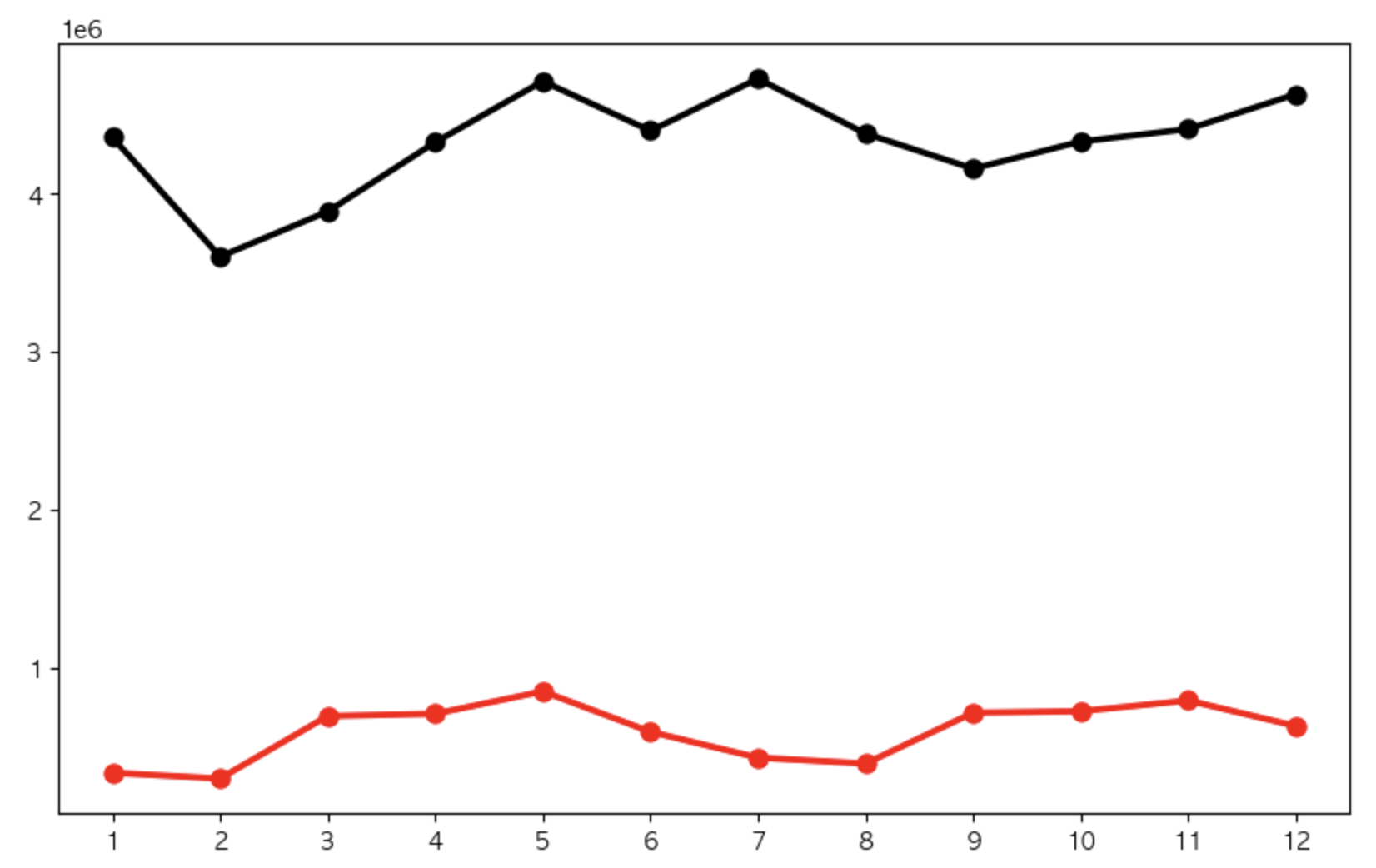
확실히 강남역 승하차인원이 많다.
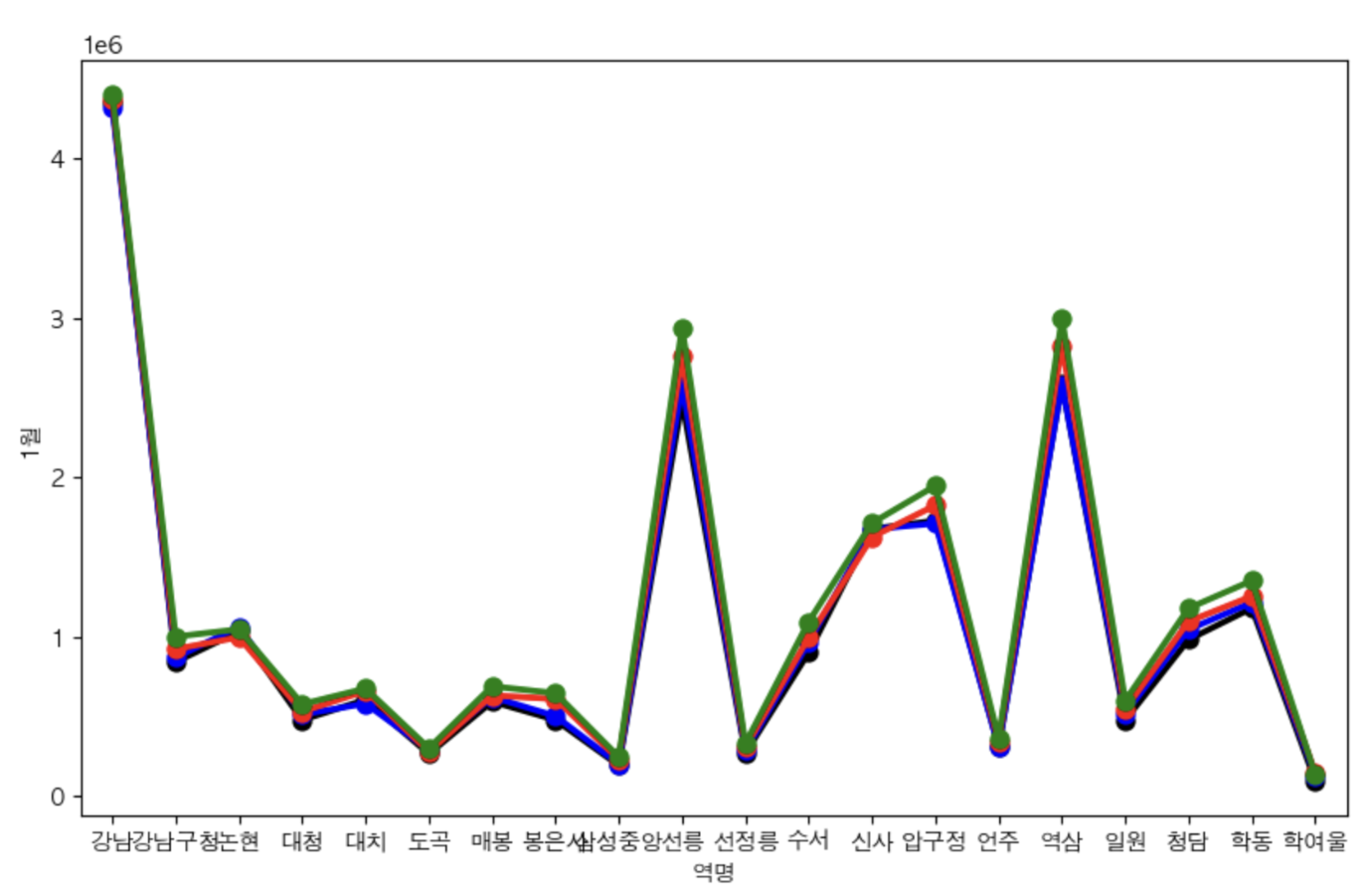
그렇다면, 강남역만 볼 게 아니라, 강남구 전체 (강남역 포함) 지하철역별 그래프를 확인해보자.
강남구 전체
# 강남구 내에서의 지하철역별 1월 승하차인원 비교
gu = '강남구'
plt.figure(figsize=(10, 6))
sns.pointplot(x='역명', y='1월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='black')
plt.show()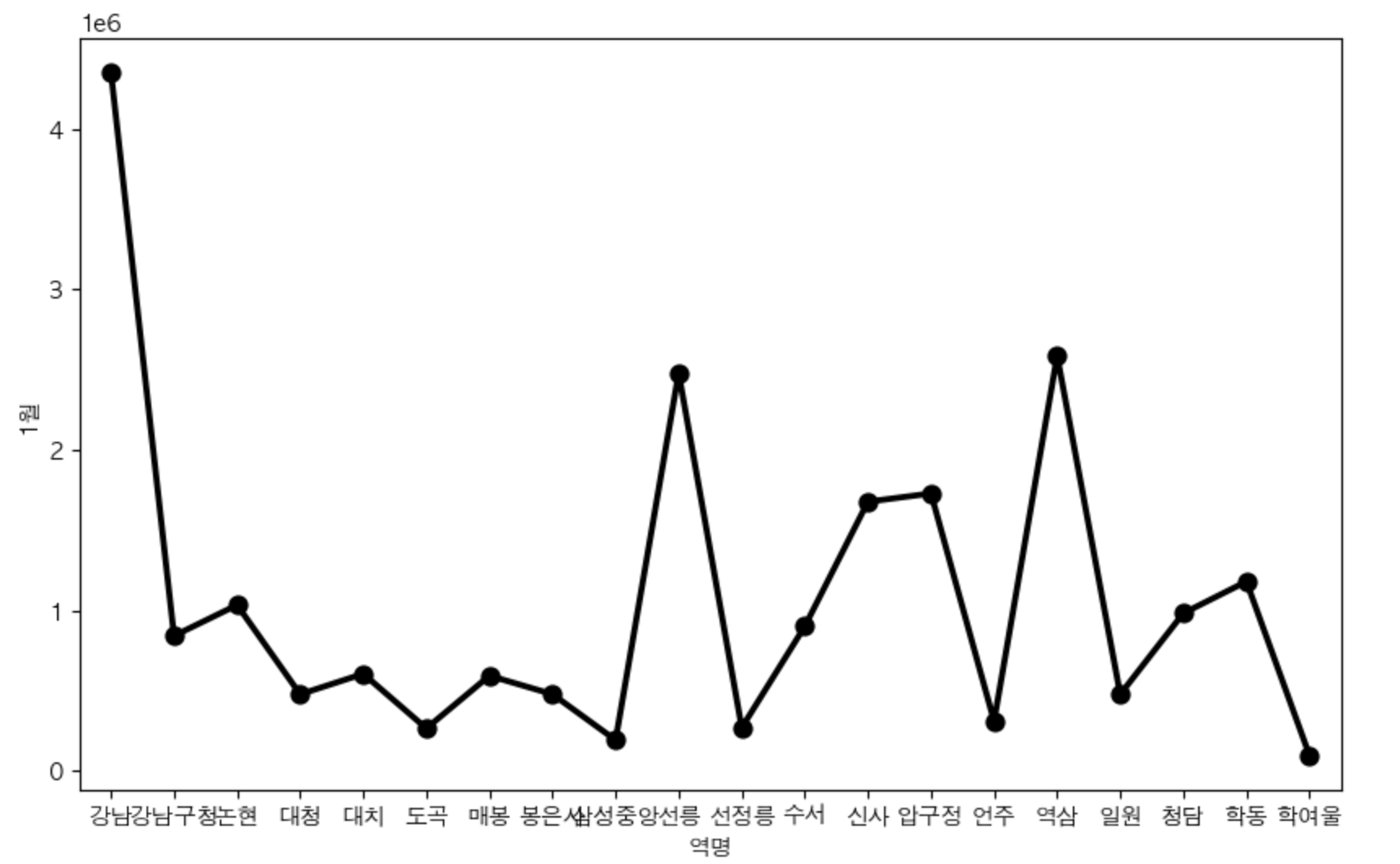
역시가 강남역 인원이 많다.
강남역 > 역삼역 > 선릉역 순
강남구 전체 + 일부 월만
# 강남구 내에서의 지하철역별 1월,4월,8월,11월 승하차인원 비교
gu = '강남구'
plt.figure(figsize=(10, 6))
sns.pointplot(x='역명', y='1월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='black')
sns.pointplot(x='역명', y='4월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='blue')
sns.pointplot(x='역명', y='8월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='red')
sns.pointplot(x='역명', y='11월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='green')
plt.show()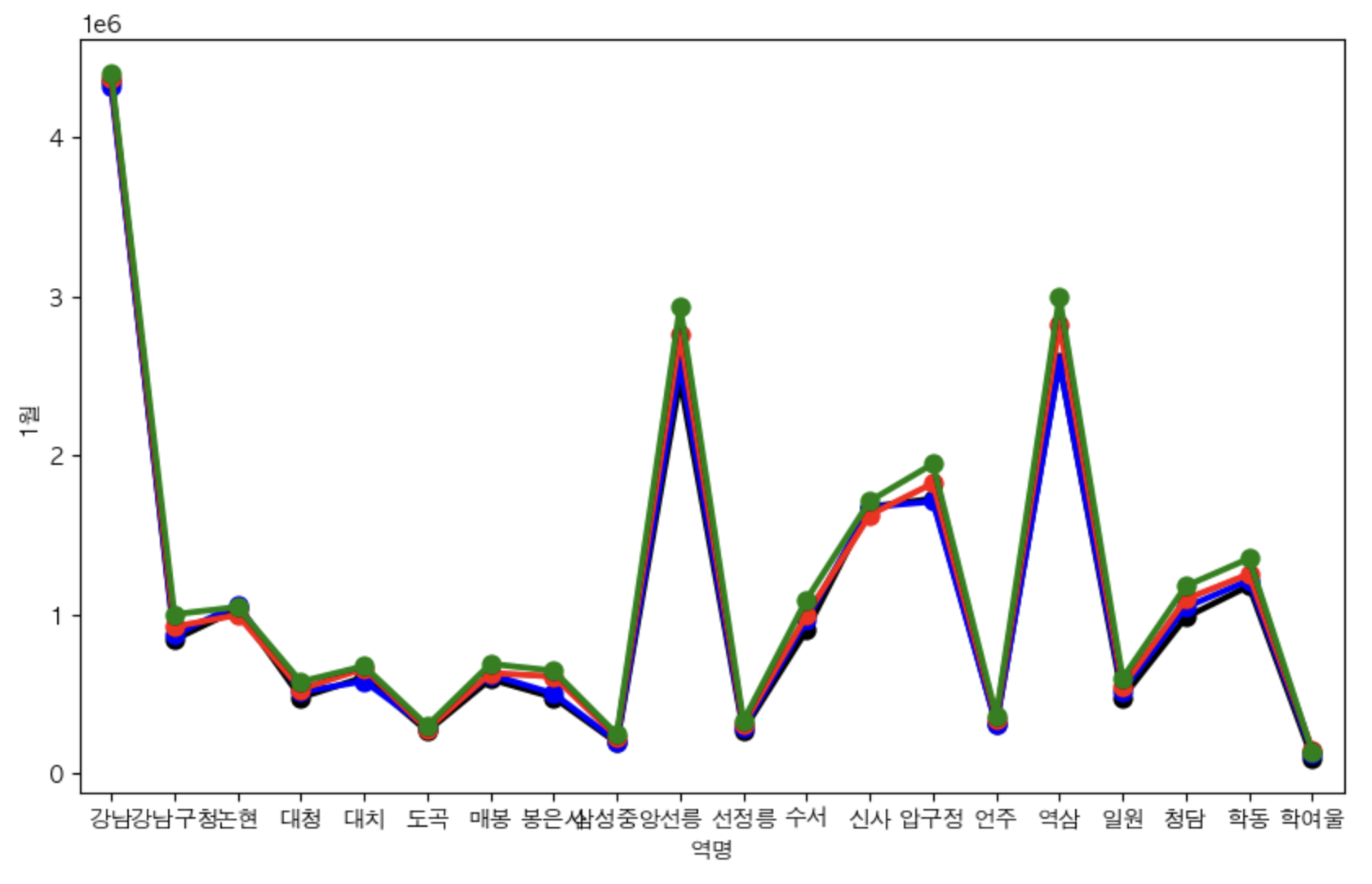
마포구 전체 + 일부 월만
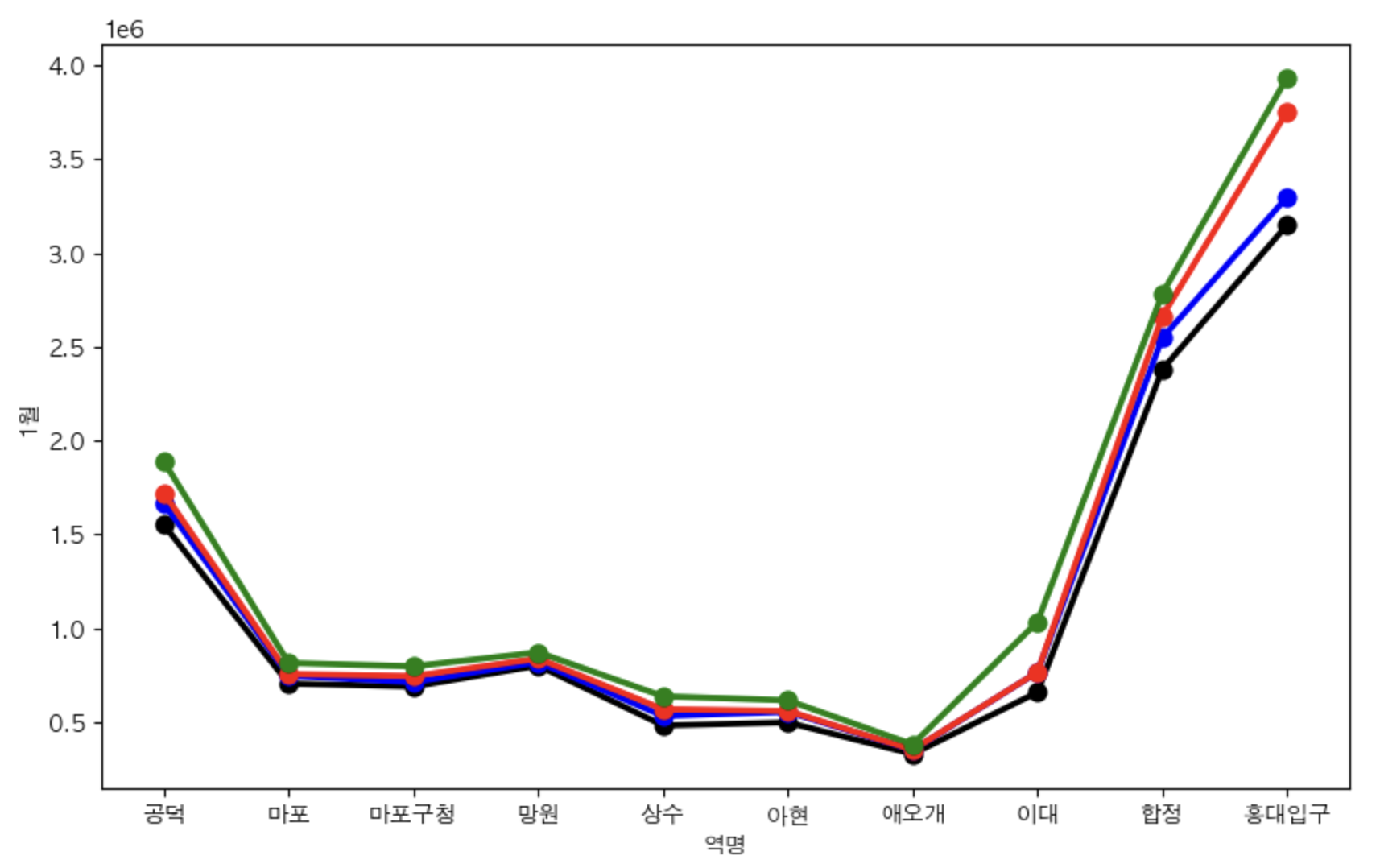
# 마포구 내에서의 지하철역별 1월,4월,8월,11월 승하차인원 비교
gu = '마포구'
plt.figure(figsize=(10, 6))
sns.pointplot(x='역명', y='1월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='black')
sns.pointplot(x='역명', y='4월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='blue')
sns.pointplot(x='역명', y='8월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='red')
sns.pointplot(x='역명', y='11월', data=stats.loc[stats['구']==gu].iloc[:, :-1],color='green')
plt.show()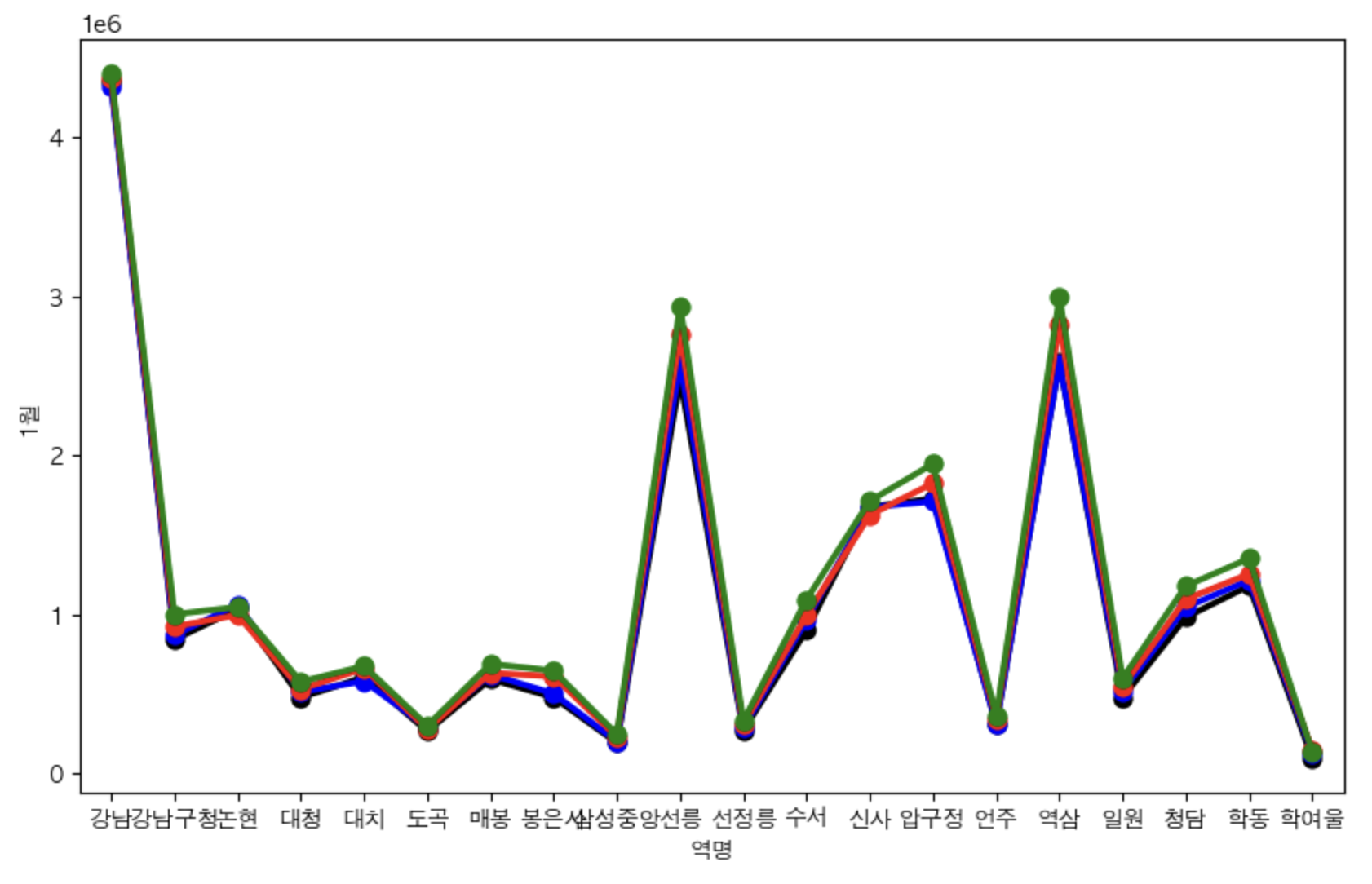
히트맵
# 강남구 내에서의 지하처역별로 월별 승하차인원
gu = '강남구'
stats.loc[stats['구'] ==gu].iloc[:, :-1]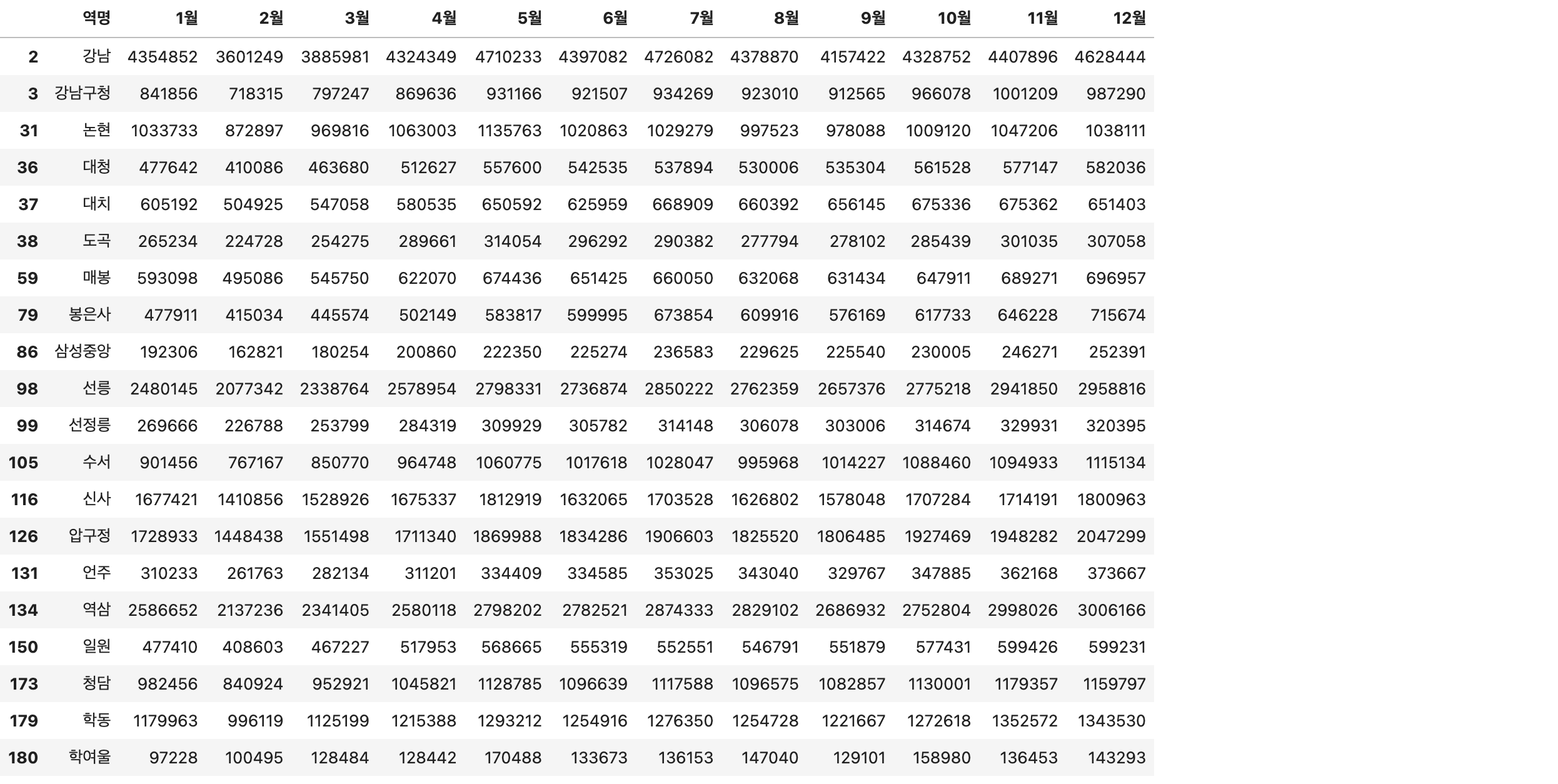
# 강남구 내에서의 지하처역별로 월별 승하차인원 히트맵 시각화
gu = '강남구'
plt.figure(figsize=(12, 12))
cmap = sns.cubehelix_palette(light=1, as_cmap=True)
sns.heatmap(stats.loc[stats['구'] == gu].iloc[:, 1:-1]/1000, annot=True, fmt='.1f', cmap=cmap, cbar_kws={"shrink": .7})
# 숫자값이 너무 커서 나누기 1000
plt.yticks(np.arange(len(stats.loc[stats['구'] == gu].iloc[:, 0].values)), stats.loc[stats['구'] == gu].iloc[:, 0].values)
plt.yticks(rotation=45)
plt.show()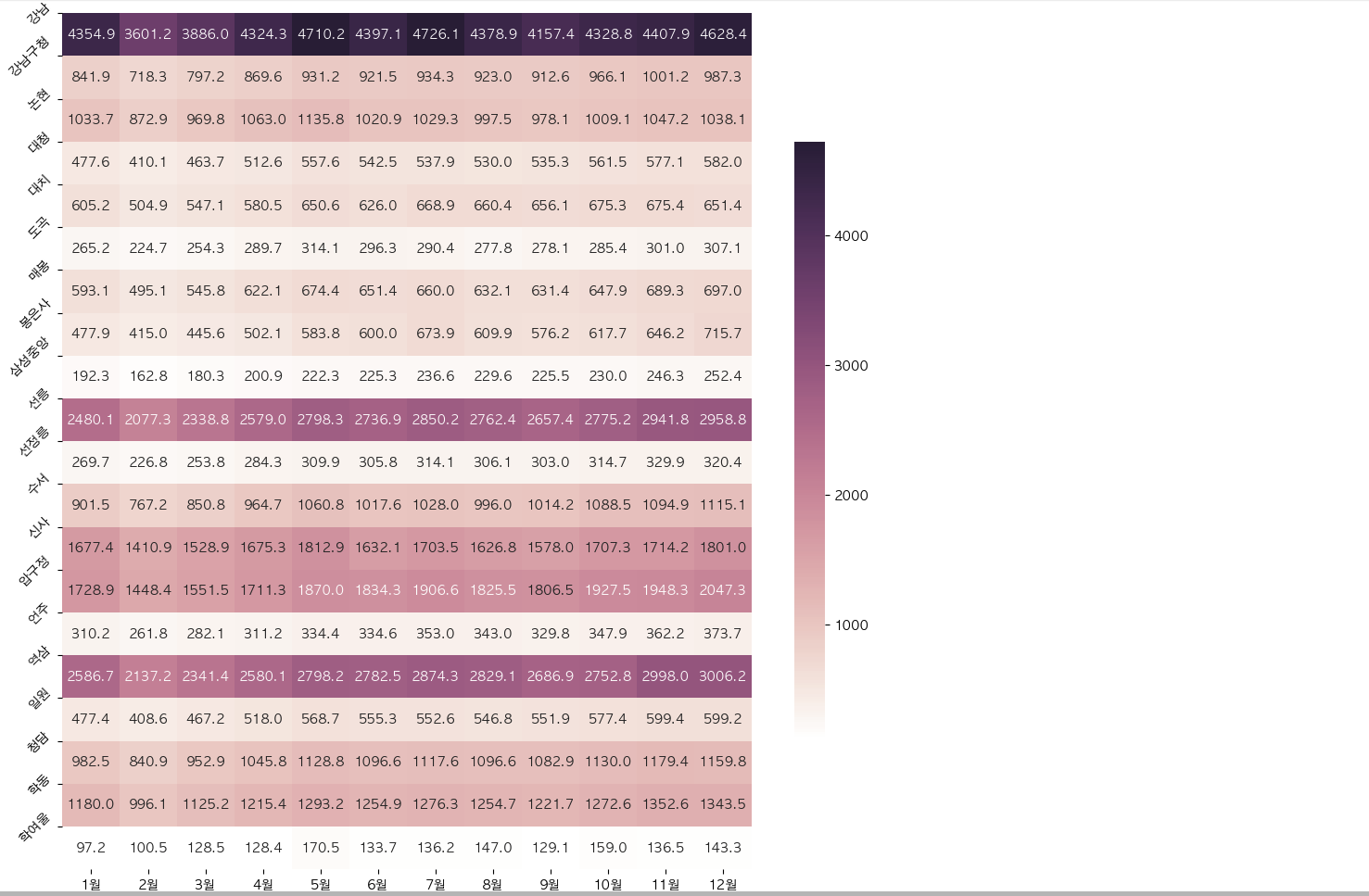
# 마포구 내에서의 지하철역별로 월별 승하차인원 히트맵 시각화
gu = '마포구'
plt.figure(figsize=(12, 12))
cmap = sns.cubehelix_palette(light=1, as_cmap=True)
sns.heatmap(stats.loc[stats['구'] == gu].iloc[:, 1:-1]/1000, annot=True, fmt='.1f', cmap=cmap, cbar_kws={"shrink": .7})
# 숫자값이 너무 커서 나누기 1000
plt.yticks(np.arange(len(stats.loc[stats['구'] == gu].iloc[:, 0].values)), stats.loc[stats['구'] == gu].iloc[:, 0].values)
plt.yticks(rotation=45)
plt.show()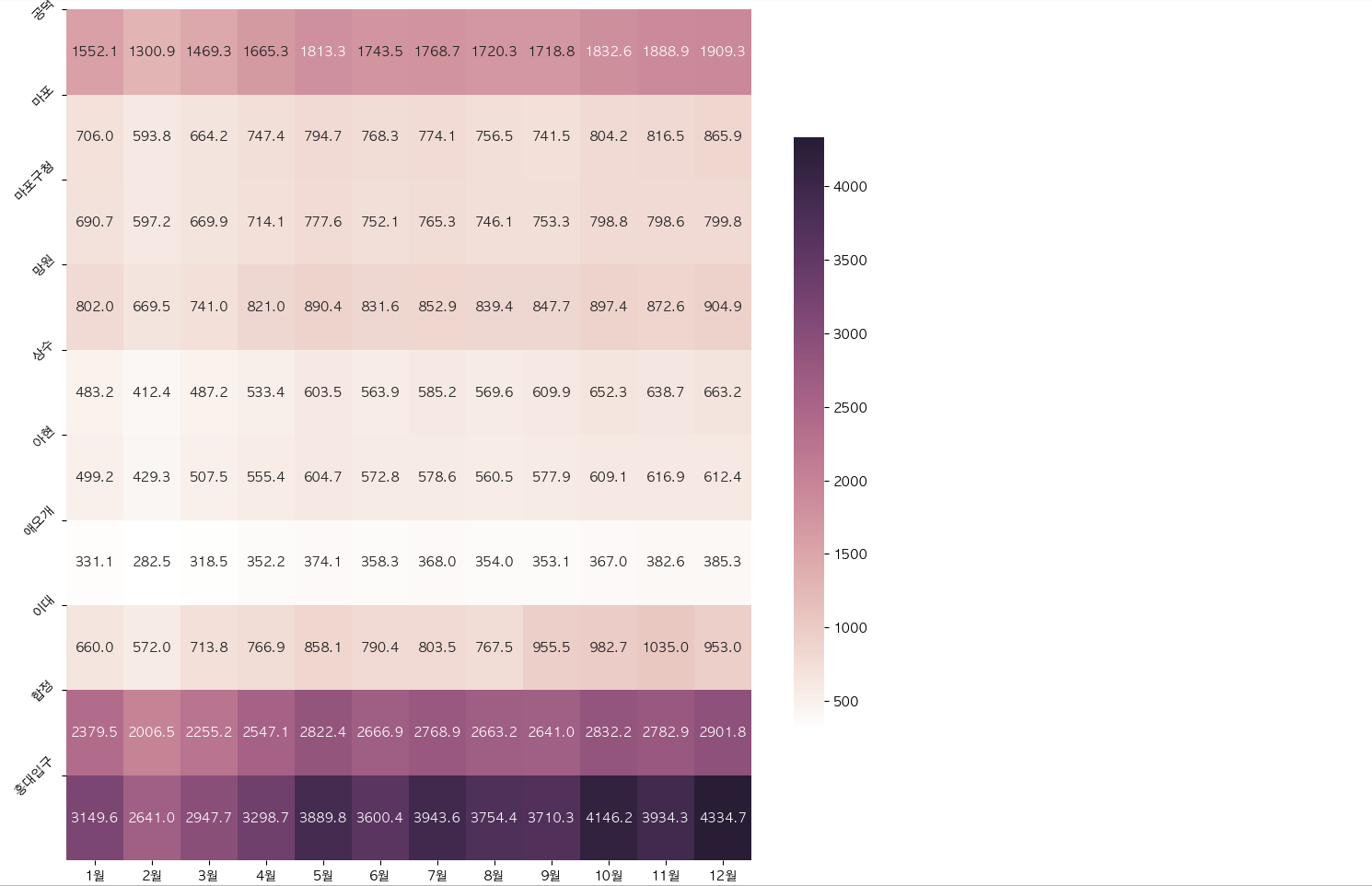
평균 비교
강남구 평균
gu = '강남구'
avg = stats.loc[stats['구']==gu].iloc[:, 1:-1].mean()
avg
강남구 평균 vs 강남역 평균 비교
place1 = '강남'
plt.figure(figsize=(10, 6))
sns.pointplot(x = np.arange(1, 13), y=np.squeeze(stats.loc[stats['역명'] == place1].iloc[:, 1:-1].values), color='black')
sns.pointplot(x = np.arange(1, 13), y=np.squeeze(avg.values), color='red')
plt.show()
# black = 강남역 승하차인원 평균
# red = 강남구 전체 지하철역 승하차인원 평균 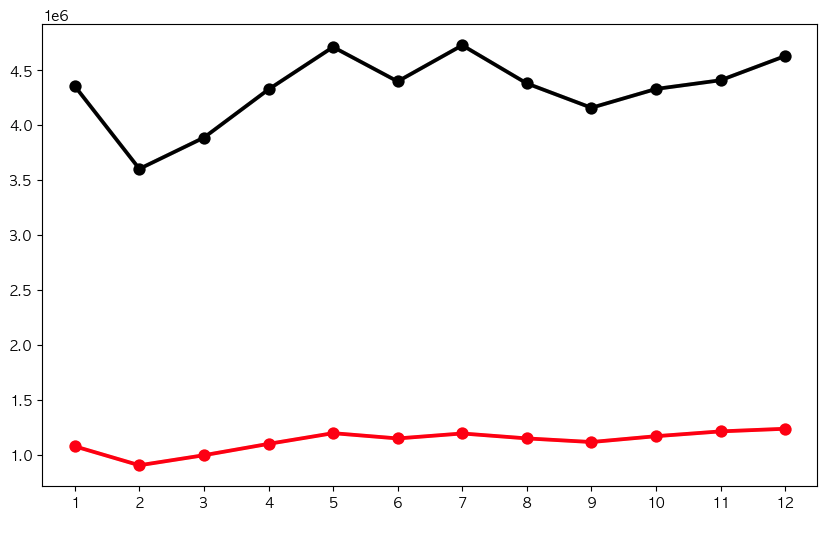
강남'역' 승하차인원이 워낙 많다보니 패턴분석이 다소 어렵습니다.
변동폭만 보기위해, 정규화 MinMaxScaler
아무리 강남역 승하차인원이 워낙 많아도,
최대치 1 ~ 최소값 0 으로 표시되기 때문에
승하차인원 월별 변동폭을 보기에는 MinMaxScaler가 필요합니다.
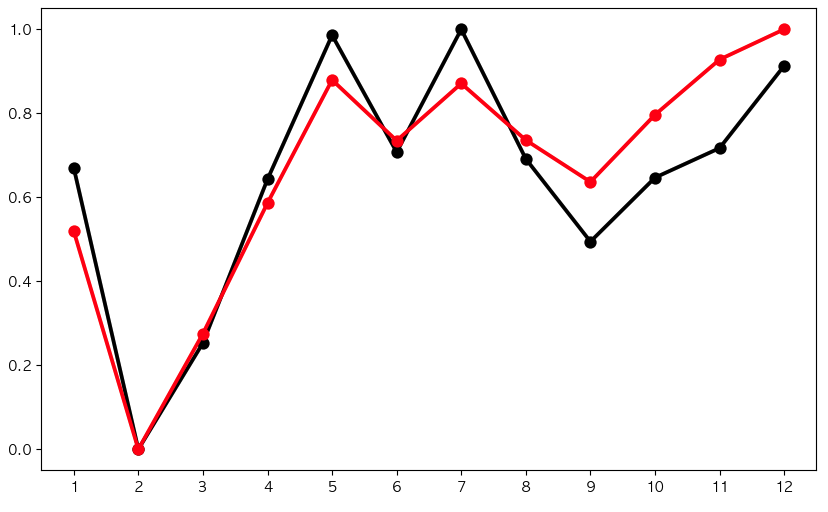
black 검정 라인이 강남역 변동폭입니다. 1월, 5월, 7월에 강남구 평균보다 승하차인원이 크게 증가했습니다. 이때 강남역으로 놀러 오는 사람이 많은걸까요...

데이터기반 스토리텔링을 통해 인사이트를 얻습니다.