고객 니즈 관점에서 데이터 분석 역량을 키우는 것은 중요합니다. 현실적이고 친숙한 데이터를 이용하여 분석을 해봅니다.
스크래퍼란?
웹사이트에서 "필요한" 부분만 수집하는 도구입니다.구글이나 네이버같이 웹사이트의 "모든" 하이퍼링크를 순회하면서 자료를 수집하는 도구와는 다릅니다.
url경로 전달
스크래퍼를 통해 해당 웹사이트에 접속해서, 데이터를 수집합니다.
https://www.gilbut.co.kr/search/search_book_list
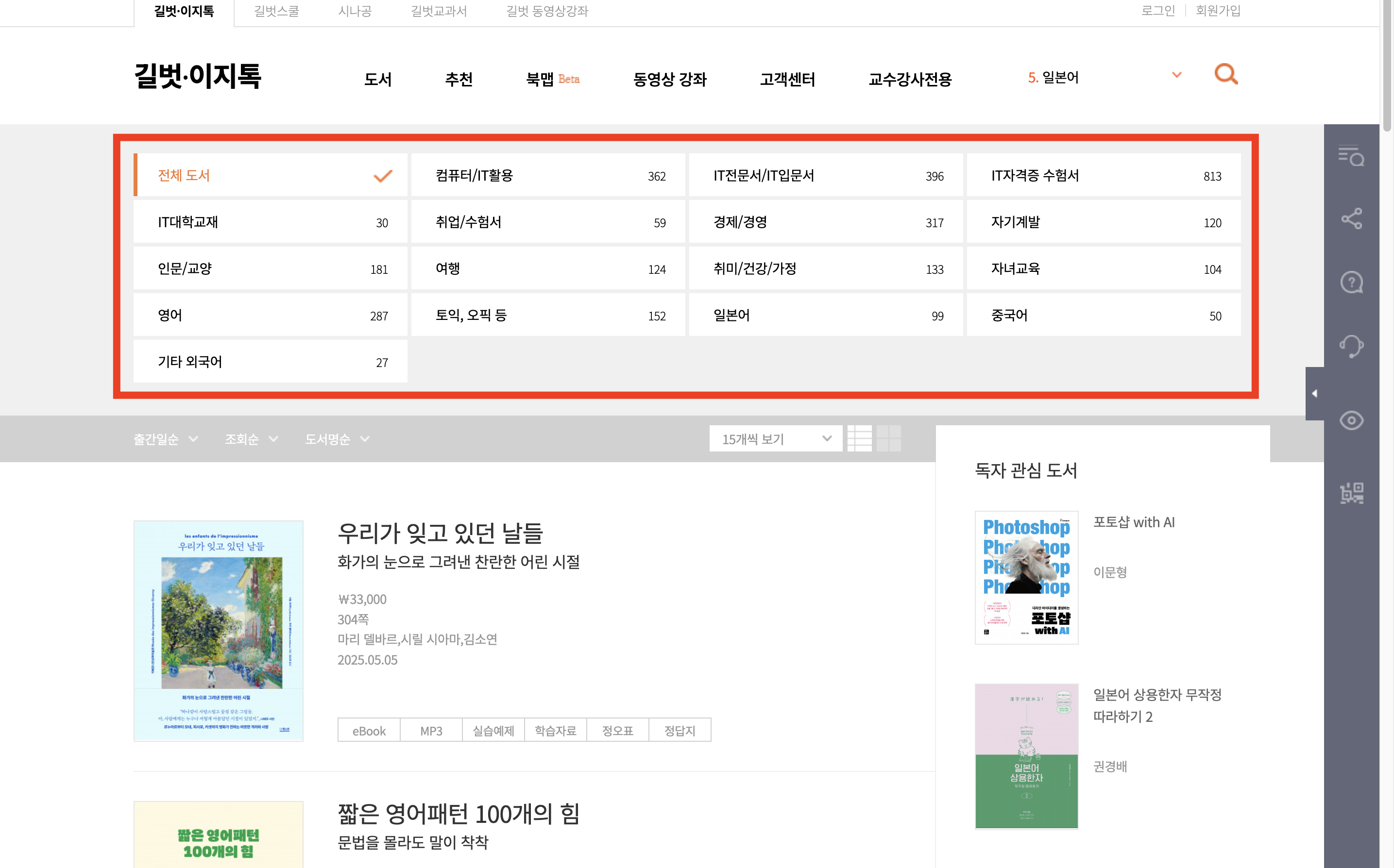
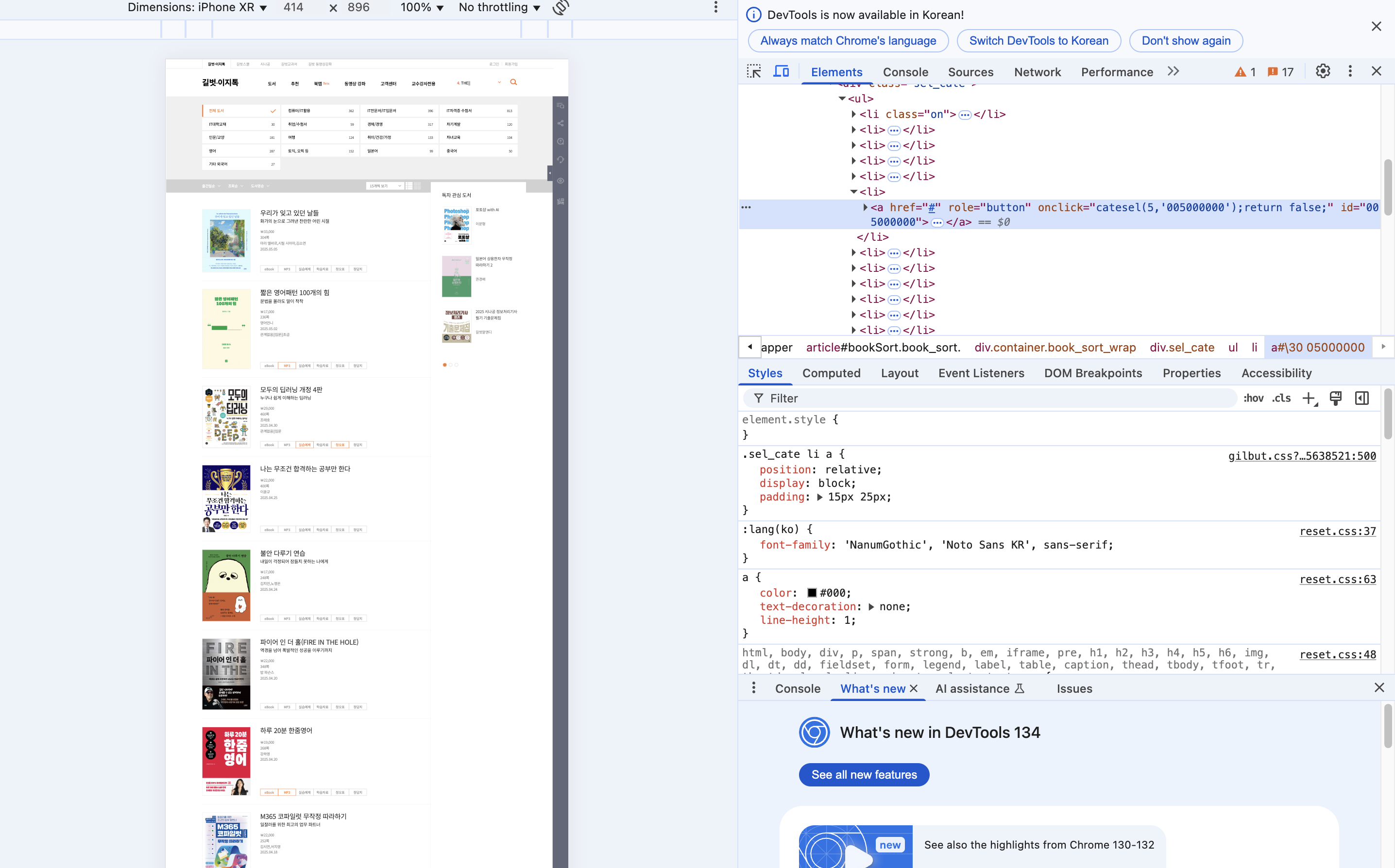
그 중에 "취업/수험서" 칸의 오른쪽 마우스를 클릭하여 "검사" 를 클릭합니다.
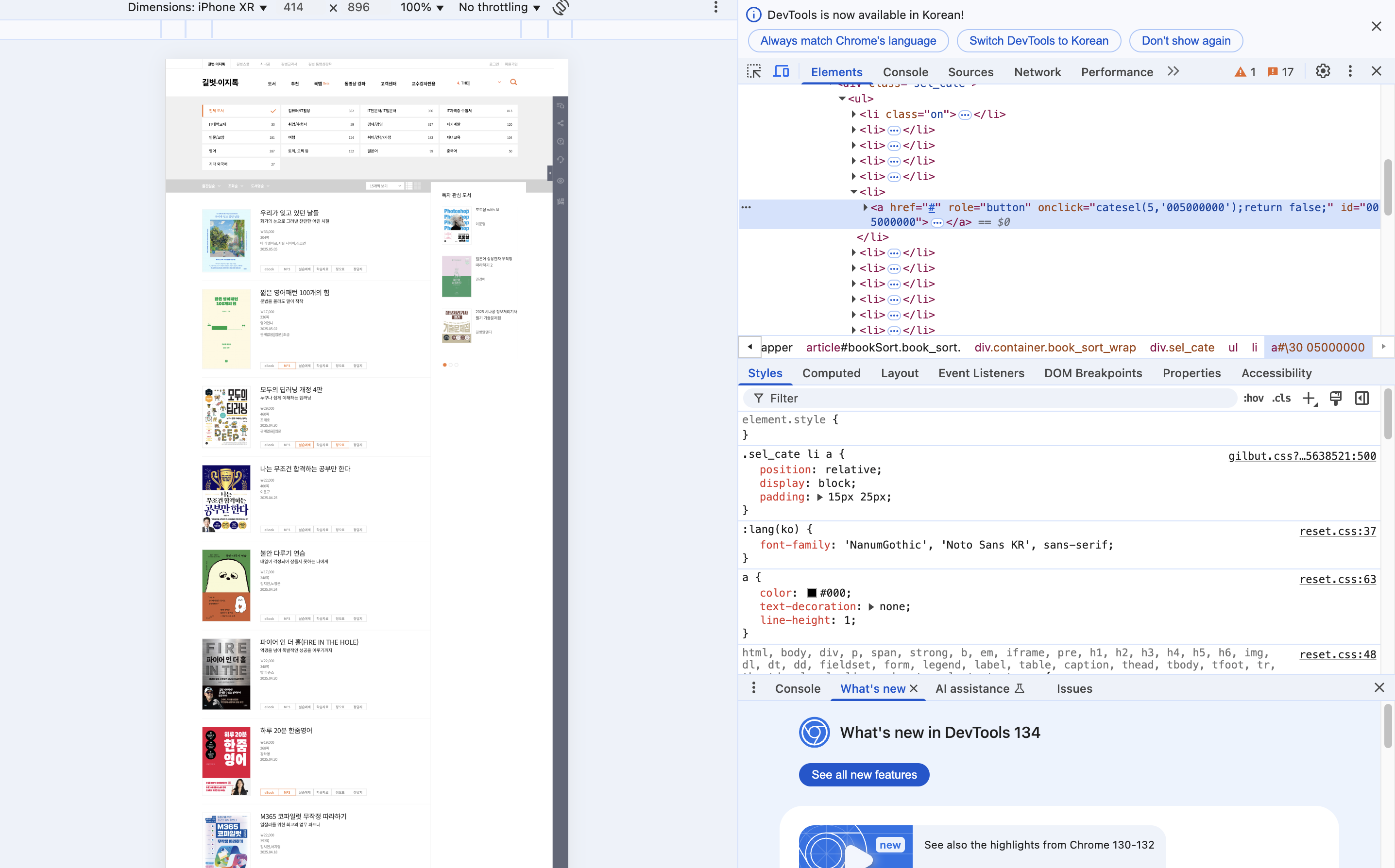
그리고 그 중에서 "취업/수험서" 가 적혀있는 단어를 찾으세요.
만약 없다면 마우스를 움직여, 찾으세요.
▶ 를 누르면 숨겨진 코드가 보여질겁니다.
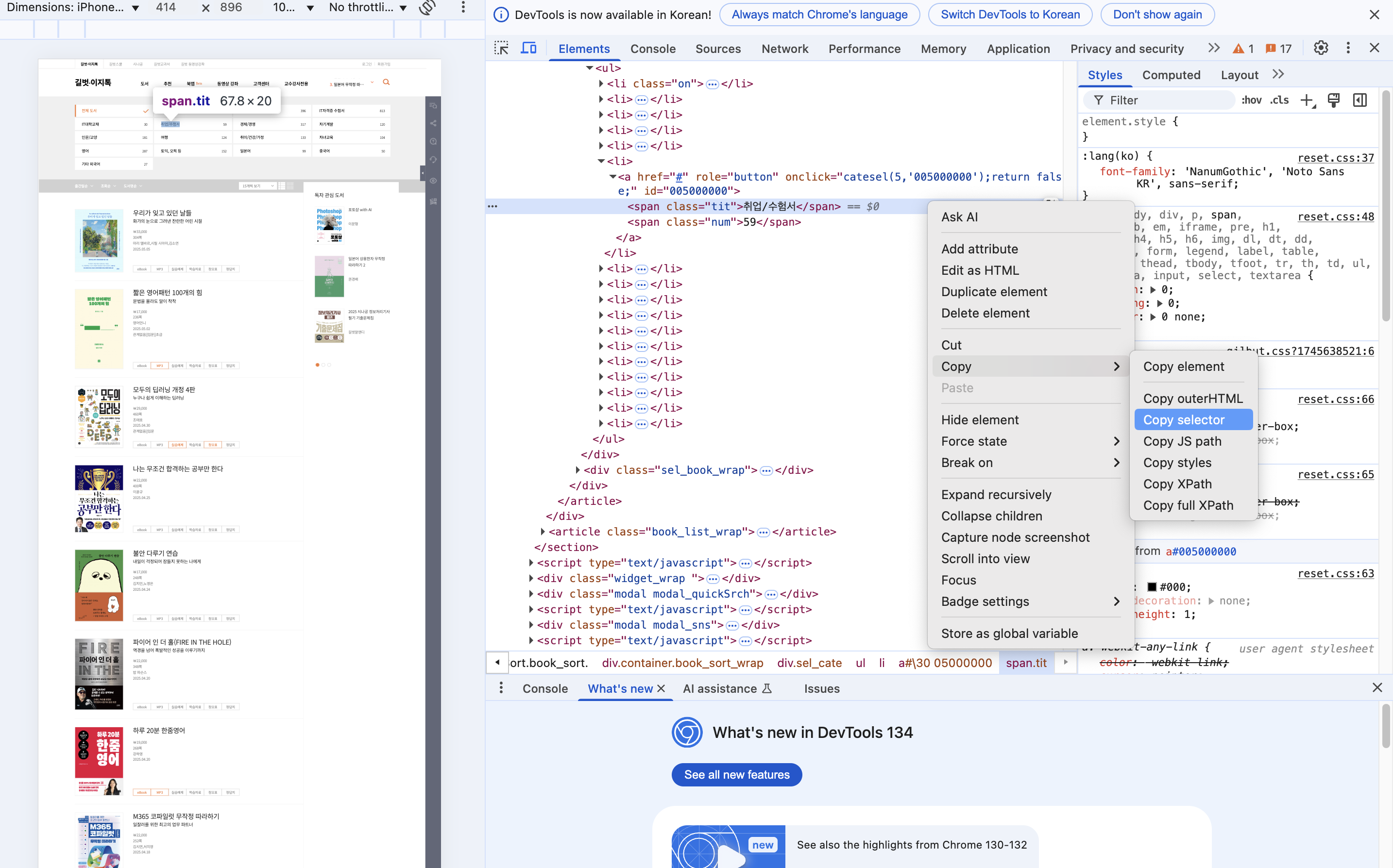
그리곤 오른쪽 마우스를 클릭해서 Copy --> Copy selector 을 누르세요.
Ctrl + V로 붙혀넣기 하면 이러한 내용이 나옵니다.
#\30 05000000 > span.tit책 카테고리가 저장된 태그 정보와 구조 파악 완료
"취업/수험서" 정보가 저장된 태그 전체 경로를 확인하였습니다.
가장 상위 경로부터 마지막 경로까지 > 로 구분하여 안내하고 있습니다. 마지막 경로는 span.tit 입니다.#\30 05000000 > span.tit이라는 말은 즉슨
태그상위 > id = 05000000
태그 하위 > span class = tit
값 > 취업/수험서
입니다.
HTML 수집(requests,get)
너무 오랜만이야! 쥬피터 노트북아 ㅠㅠㅠㅠㅠ
너무 오랜만이라서 터미널창 여는것도 구글링해서 겨우 열었다..... 반성한다 나자신
import requests
url = "https://www.gilbut.co.kr/search/search_book_list"
response = requests.get(url)
html = response.text
html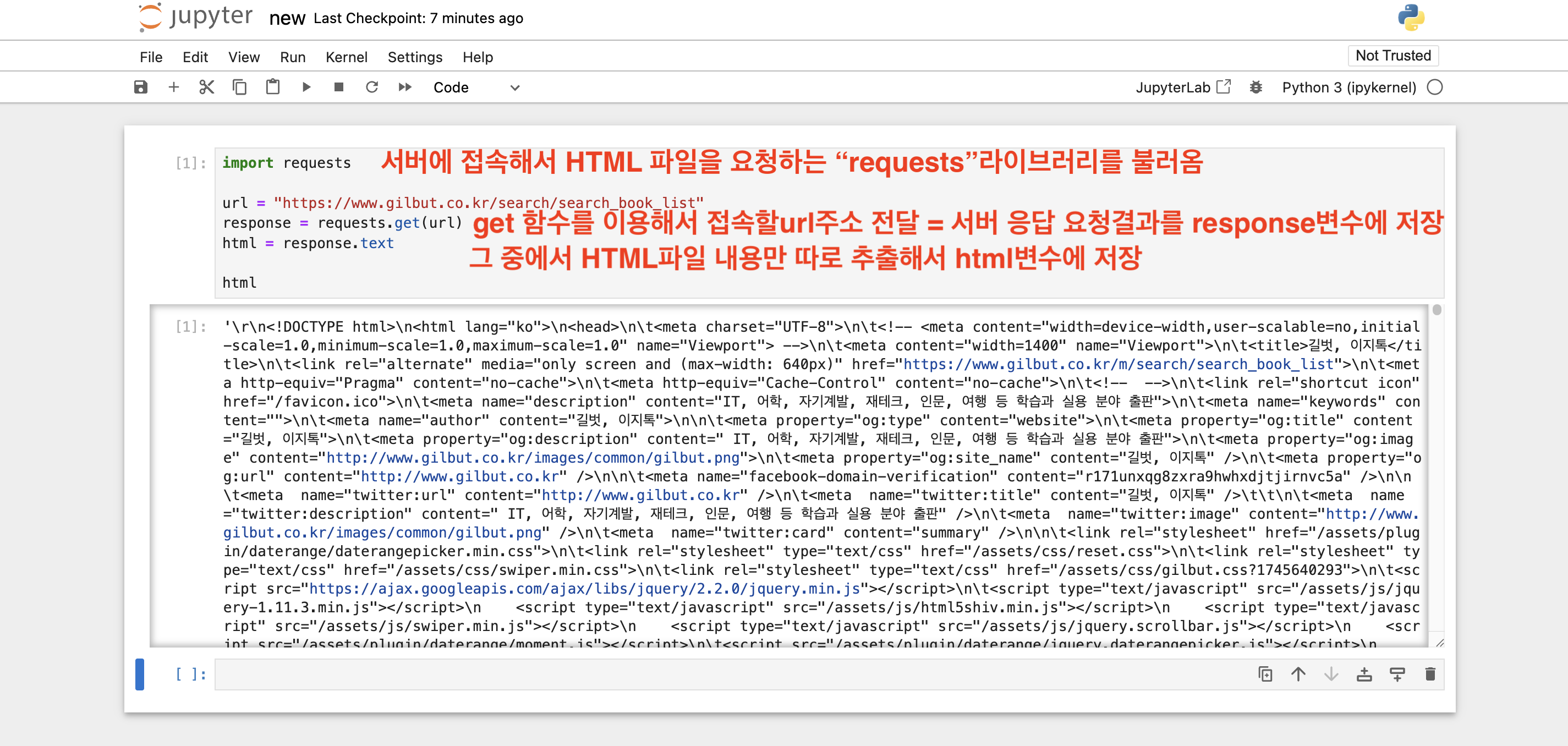
requests 라이브러리는,
서버에 접속해서 HTML 파일을 요청합니다.
그리고 get 함수를 이용해서 접속할 url주소를 전달합니다.
이제, 스크래퍼 첫 단추인 HTML 수집을 완료했습니다!
HTML 파싱(bs4)
HTML을 분석할 때에는 BeautifulSoup 라이브러리를 사용합니다.
해당 라이브러리에 분석할 HTML 내용을 입력하고 파싱(parsing)을 위한 파서(parser)를 지정합니다.
파싱 parsing : HTML 을 분석하여, 태그 중심으로 정보를 정렬
파서 parser : 파싱하는 방법
- BeautifulSoup 순서 입니다.
(1) 수집한 HTML을 파싱한다.
(2) 파싱 결과에서 필요한 태그를 선택할 때, 사용한다.파서의 3가지 종류 -----------------------------------
lxml로 파싱하면 일부 결과가 누락되는 경우도 간혹 생기지만, 대부분 lxml 파서로도 충분합니다.
(1) lxml
- 장점 : 처리 속도가 빠르고 결과도 대부분 lxml을 이용하기 때문에, 인터넷에서 추가 정보를 찾기에 용이함
- 단점 : 일부 정보가 누락될 경우가 있음
(2) html5lib
- 장점 : 구조가 복잡한 HTML 파일의 파싱에 적용 (웹 페이지가 HTML5로 작성되었을 경우, 결과가 매우 좋음)
- 단점 : 속도가 느림
(3) html.parser
- 장점 : lxml과 html.parser 특징을 모두 가지고 있음, 누락되는 정보가 별로 없음
- 단점 : 속도가 빠르지는 않음
이제, 수집한 HTML을 BeautifulSoup을 이용하여 파싱하고 필요한 태그를 선택합니다.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
categorys = soup.select ("span.tit")
categorys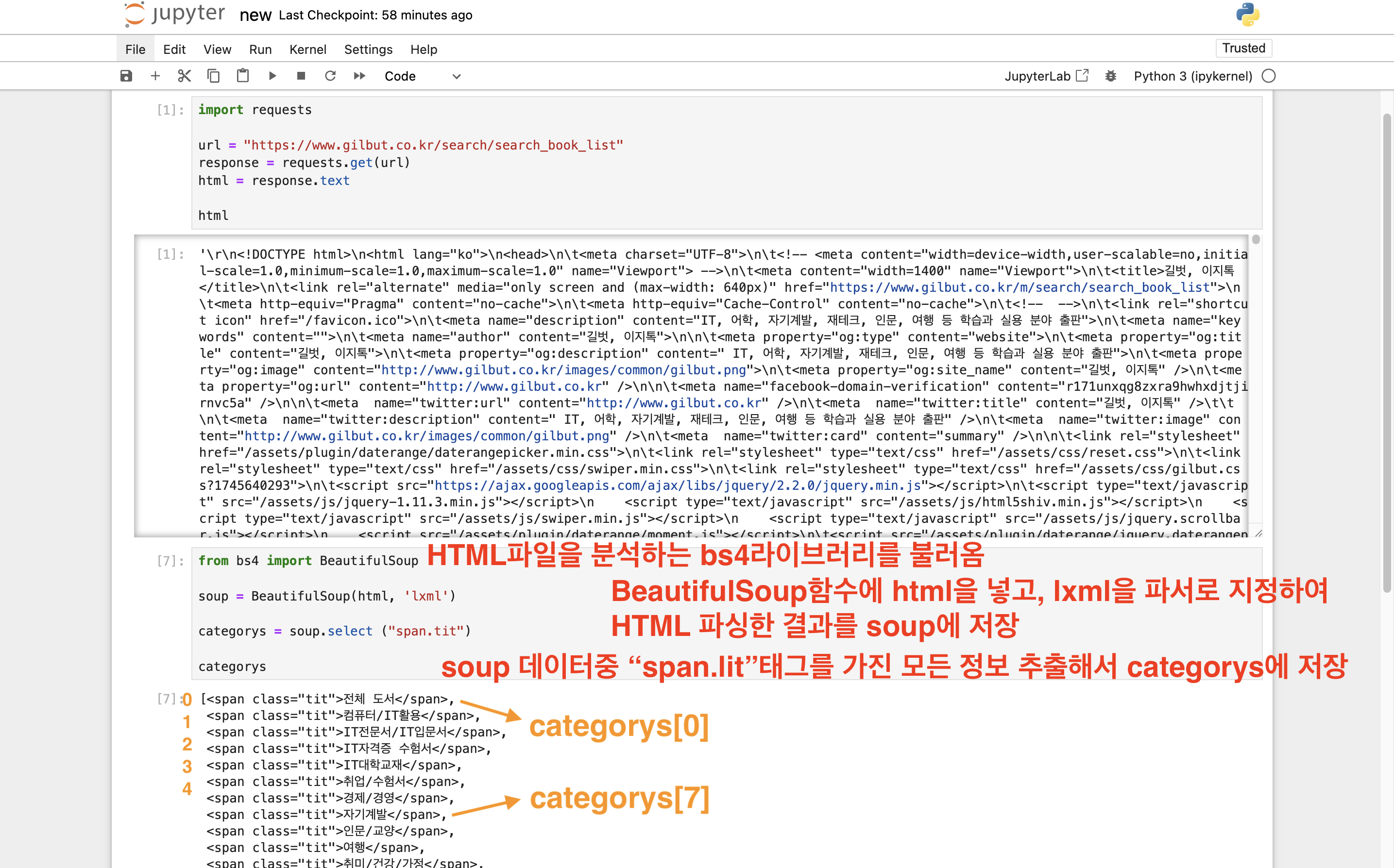
다행히, 결과를 보니 책 종류가 모두 정상적으로 수집되었습니다!
bs4 (BeautifulSoup) 라이브러리는,
HTML 파일을 분석합니다.
전처리
하지만 <span class="tit"> 태그까지 출력되어 보기에 불편합니다.
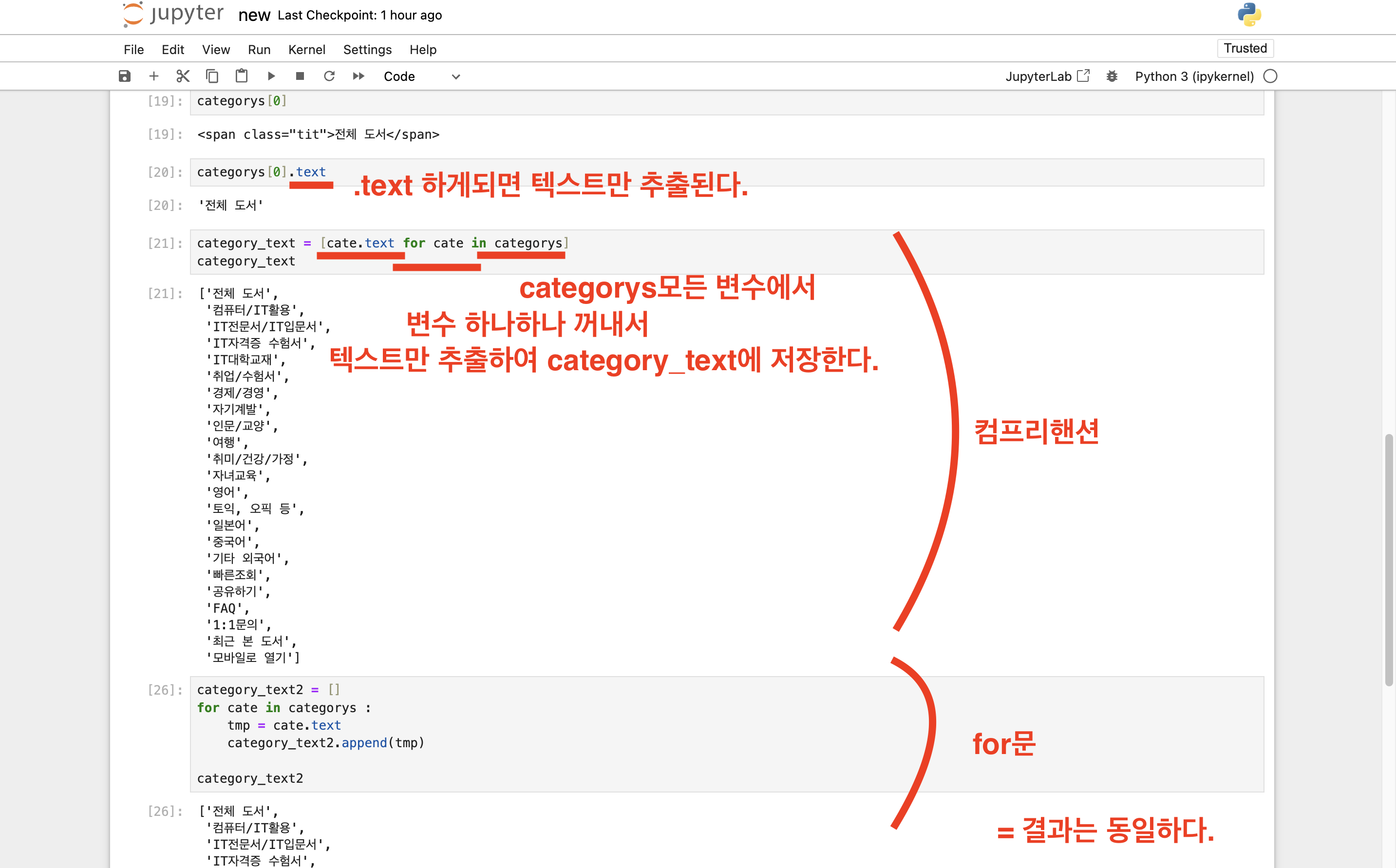
.text를 이용해서 태그는 제외하고 텍스트만 추출합니다.
categorys 변수에는 여러개 값이 있고, 하나씩 텍스트만 추출하기 위해서는 for문을 써야 합니다.
그리고 for문보다는 코드를 짧게 줄인, 컴프리핸션 comprehension 으로 간단하게 구현할 수 있습니다.
[for문]
for 반복변수 in 범위 : 반복 코드[컴프리핸션]
새로운 변수 이름 = [반복변수 for 반복변수 in 반복범위]
하지만 추출된 텍스트를 보니
전체 도서, 빠른조회, 공유하기, FAQ 등과 같은 쓸데없는 값들이 있습니다.
제거해줍니다.
반복문으로 제거
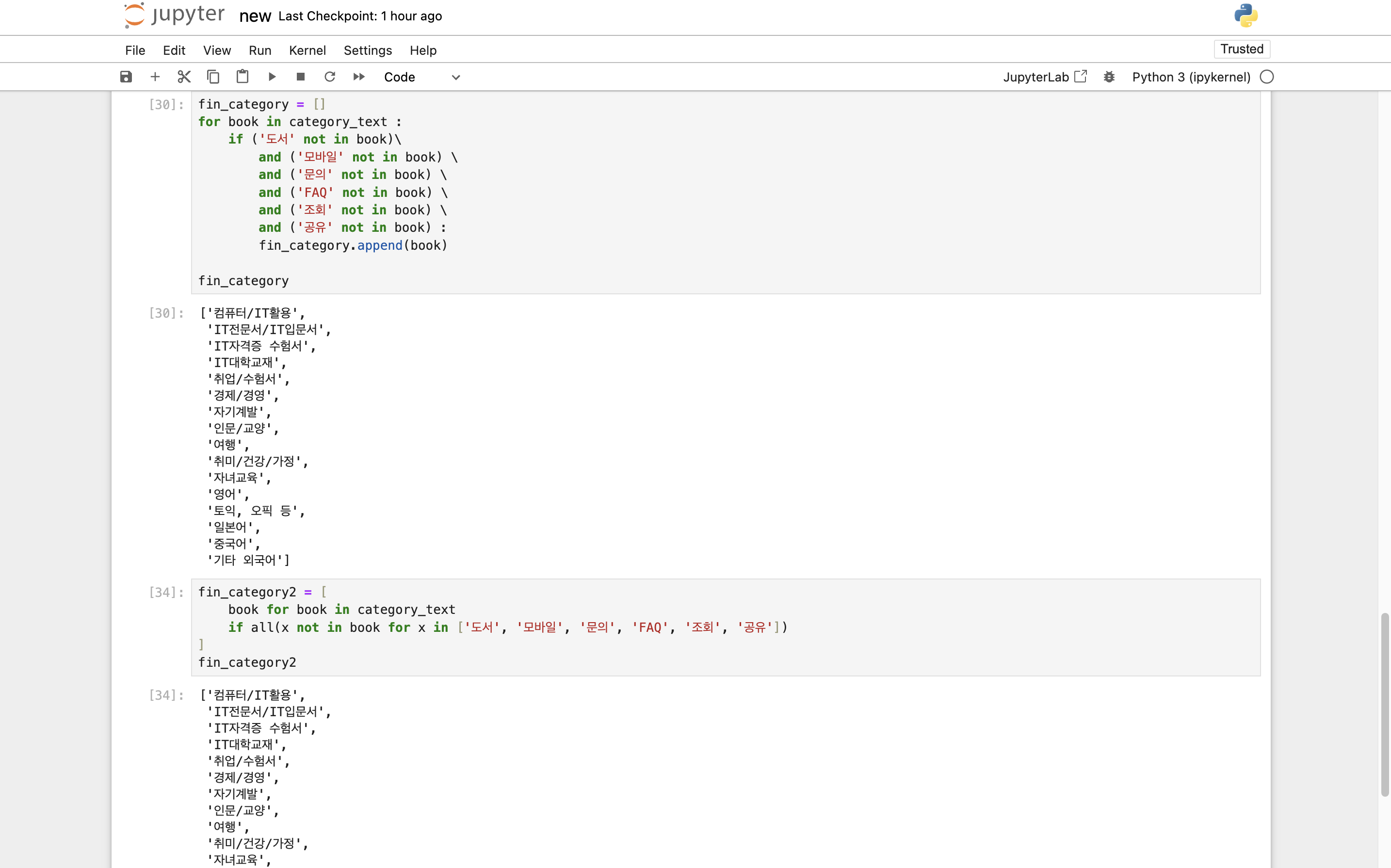
fin_category = []
for book in category_text :
if ('도서' not in book)\
and ('모바일' not in book) \
and ('문의' not in book) \
and ('FAQ' not in book) \
and ('조회' not in book) \
and ('공유' not in book) :
fin_category.append(book)
fin_category또는
fin_category = [
book for book in category_text
if all(x not in book for x in ['도서', '모바일', '문의', 'FAQ', '조회', '공유'])
]
fin_category