
커널에서 시간을 관리하는 방식은 왜 알아야 할까?
커널 코드 구성 방식
- 기능을 구현
- 실행 시간 흐름 제어
Device Driver에서 실행 시간 제어
- 타임아웃
- 예외처리
Device Driver에서 타임아웃루틴이 있어야 하는 이유
- 응답성을 키우기 위해서
- 정해진 스펙에 맞게 루틴을 구현하기 위해서
- 100ms내에 함수 실행이 마무리되지 않으면?
- return 문 추가- 다시 한번 loop를 돌게하는 조건문 추가
커널 타이머 소개
리눅스 커널 드라이버에서 실행 시간의 흐름을 체크하려면?
- jiffies
jiffies와 HZ
jiffies란
- jiffies는 커널 드라이버에서 실행 시간을 체크하는 단위
- jiffies는 1초에 HZ(250)만큼 증가하며 이를 기준으로 시간의 흐름을 관리
HZ란
- HZ는 진동수라고 부르며, 1초에 jiffies가 업데이트 되는 횟수
- 대부분의 Armv8 계열(Aarch64) 리눅스 커널에서는 HZ값이 250임(
CONFIG_HZ = 250)
현재 jiffies가 1000이면 jiffies는 초당 다음과 같이 변경됨
- 1초 후 1250
- 2초 후 1500
- 3초 후 1750
HZ가 크면 좋을까?
- HZ가 너무 크면 시스템에 오버헤드가 걸림
- HZ가 너무 작으면 시스템에 동적 타이머의 만료 시각을 처리하는데 오차가 발생
- 최적화된 값을 설정하는 것이 중요
jiffies와 jiffies_64 변수
jiffies와 jiffies_64 변수의 관계

- 두 변수는 주소가 같지만 크기가 다름
jiffies는jiffies_64시작 주소를 기준으로 4byte 주소 공간에 있는 값을 저장jiffies_64는 8byte 단위로 주소 공간에 있는 값을 저장
커널 동기화
임계 영역(Critical Section)
- 2개 이상의 프로세스가 동시에 실행하면 동시 접근 문제를 일으킬 수 있는 코드 블록
레이스 컨디션(Race Condition)
- 임계 영역에 2개 이상의 프로세스가 동시에 어떤 코드 연산을 수행하는 상황
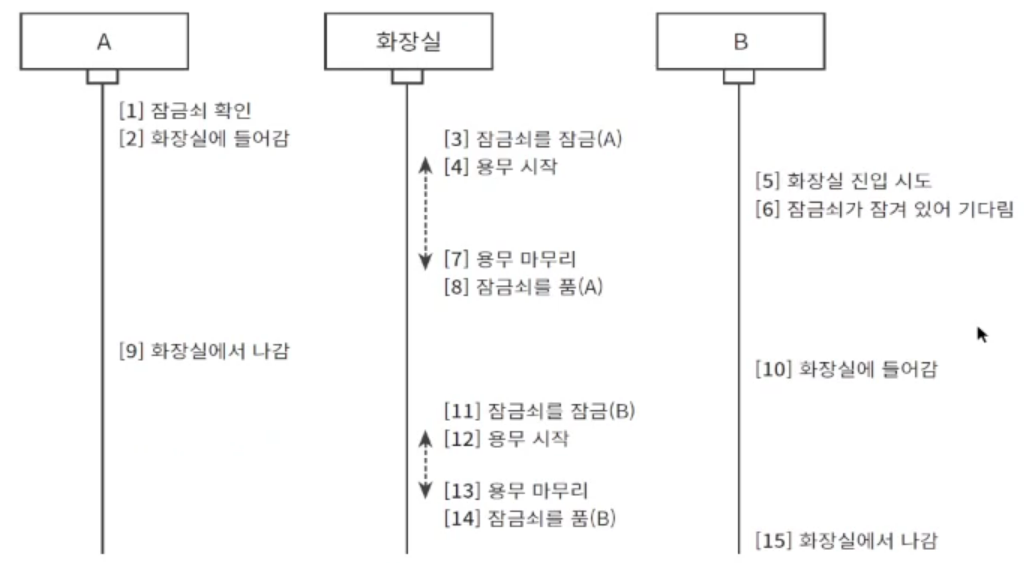
커널 동기화 기법을 잘 알아야 하는 이유
트러블 슈팅
- Race로 인한 다양한 이슈 대응(Crash)
- 가장 난이도가 높은 이슈(가장 많이 고생)
- 리눅스 커널 커뮤니티에서 꾸준히 Race Condition을 방지하기 위한 패치가 제안
기능 구현
- 안정적인 드라이버 코드 작성
- 함수의 호출 path를 파악해 Critical Section 루틴 파악
커널의 동작 방식 이해
- 커널 코드를 이해하기 위해
Race Condition은 왜 발생할까 ?
SMP(Symmetric Multiprocessing)
- SMP란 하나의 시스템에 다수의 CPU가 한 개의 메모리를 쓰는 컴퓨터 시스템 아키텍처
- 서로 다른 CPU에서 실행 중인 프로세스가 같은 코드나 함수에 접근하는 상황 초래
SMP(Symmetric Multiprocessing)의 예시
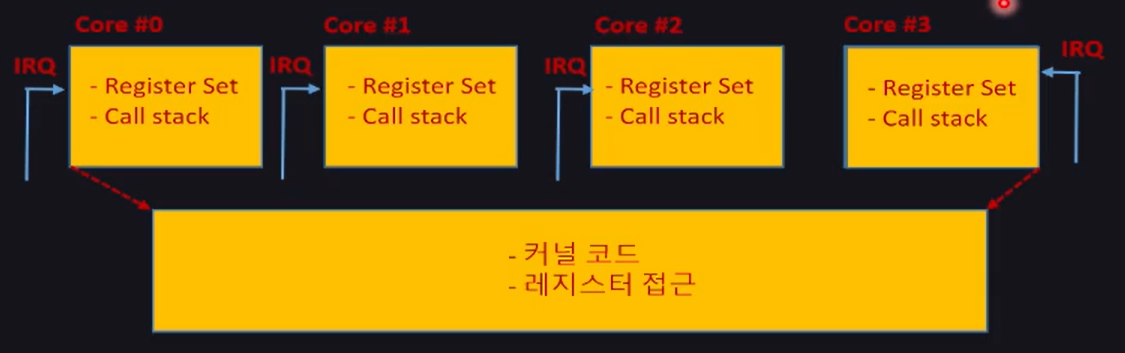
- 각 코어마다 EL0~EL2에서 구동됨
- IRQ는 각 코어별로 랜덤하게 전달
- 프로세스는 각 코어를 돌아다님(
Migration)
인터럽트 발생
- 어떤 CPU 코어에서도 인터럽트는 언제든 발생할 수 있음
rpi_set_synchronize()함수를 실행하는 도중 인터럽트가 발생해 다시rpi_set_synchronize()함수에 진입함
Preemptive Scheduling
-
선점 스케줄링 : CPU 코어에서 실행중인 프로세스를 강제로 실행을 멈추게 하고 우선순위가 높은 프로세스를 강제로 실행하게 함
-
대부분의 리눅스 커널은
Preemptive Scheduling환경에서 실행 -
우리가 입력한 코드 블록이 실행되는 도중
Preemptive Scheduling될 수 있음
스핀락(SpinLock)의 주요 특징
스핀락의 특징
- 뮤텍스에 비해 구현 복잡도가 낮음
- 스핀락 구현부는 아키텍처에 의존적임
- CPU 아키텍처(Armv7, Armv8, RISC-V)에 따라 스핀락 구현부가 다름
스핀락의 세부 동작 원리
- 이미 누군가가 스핀락을 획득했으면 스핀락을 획득할 때까지 계속 기다림(Busy-Waiting)
- 다른 프로세스가 스핀락을 해제하면 바로 스핀락을 획득하고 Critical Section을 실행
스핀락을 써서 Critical Section을 보호하는 루틴1
_kthread_create_on_node()함수
struct task_struct *__kthread_create_on_node(int (*threadfn)(void *data), void *data, int node,
const char namefmt[], va_list args)
{
DECLARE_COMPLETION_ONSTACK(done);
struct task_struct *task;
struct kthread_create_info *create = kmalloc(sizeof(*create),
GFP_KERNEL);
spin_lock(&kthread_create_lock); // 스핀락을 획득
list_add_tail(&create->list, &kthread_create_list); // Critical Section
spin_unlock(&kthread_create_lock); // 스핀락을 해제
wake_up_process(kthreadd_task);
}스핀락을 써서 Critical Section을 보호하는 루틴2
_qcom_glink_rx_open_ack()함수
busy_waiting : A 프로세스가 spin lock 획득한 다음 idr_find()를 실행하고 있는데
다른 프로세스가 spin lock을 획득하려 하면 이 spin lock이 해제돼서 자신이 spin lock을 할 수 있을 때 까지 기다림
static int qcom_glink_rx_open_ack(struct qcom_glink *glink, unsigned int lcid)
{
struct glink_channel *channel;
spin_lock(&glink->idr_lock); // 스핀락을 획득
channel = idr_find(&glink->lcids, lcid); // Critical Section
spin_unlock(&glink->idr_lock); // 스핀락을 해제
if (!channel) {
dev_err(glink->dev, "Invalid open ack packet\n");
return -EINVAL;
}
complete_all(&channel->open_ack);
return 0;
}뮤텍스 소개
뮤텍스란
- 뮤텍스는 운영체제에서 쓰는 용어로 'Critical Section'에 2개의 프로세스가 동시에 접근하지 못하도록 방지하는 기법
- 각 운영체제 커널마다 다르게 구현됨
같은 mutex_lock를 2번 사용하면 큰일 남!
mutex_lock을 걸고 또 걸면 자신이 mutex_lock을 건 상태에서 다시 걸면 sleep에 진입하면서 자신을 깨워주길 기다려야 하므로 영원히 깨어나지 못함
리눅스 커널에서 뮤텍스란
- 뮤텍스는 스핀락과 더불어 리눅스 커널 및 리눅스 커널 드라이버에 가장 많이 활용되는 커널 동기화 기법
- 뮤텍스는
sleep을 지원하며 프로세스 컨텍스트에서 주로 쓰는 커널 동기화 기법 - 인터럽트 컨텍스트에서 사용 불가
뮤텍스의 구현 방식
fashpath
- 뮤텍스는 다른 프로세스가 이미 획득하지 않은 상태면 바로 획득
- fastpath로 빨리 뮤텍스를 획득하고 해제
slowpath
- fastpath흐름으로 뮤텍스 획득을 시도했는데 다른 프로세스가 이미 뮤텍스를 획득한 경우 실행되는 동작
- 뮤텍스를 획득하지 못한 프로세스는 queue에 자신을 등록하고 휴면 상태에 들어감
- 뮤텍스를 해제한 프로세스는 뮤텍스 queue에 등록(뮤텍스 획득을 이미 시도)한 다른 프로세스를 깨움
WorkFlow
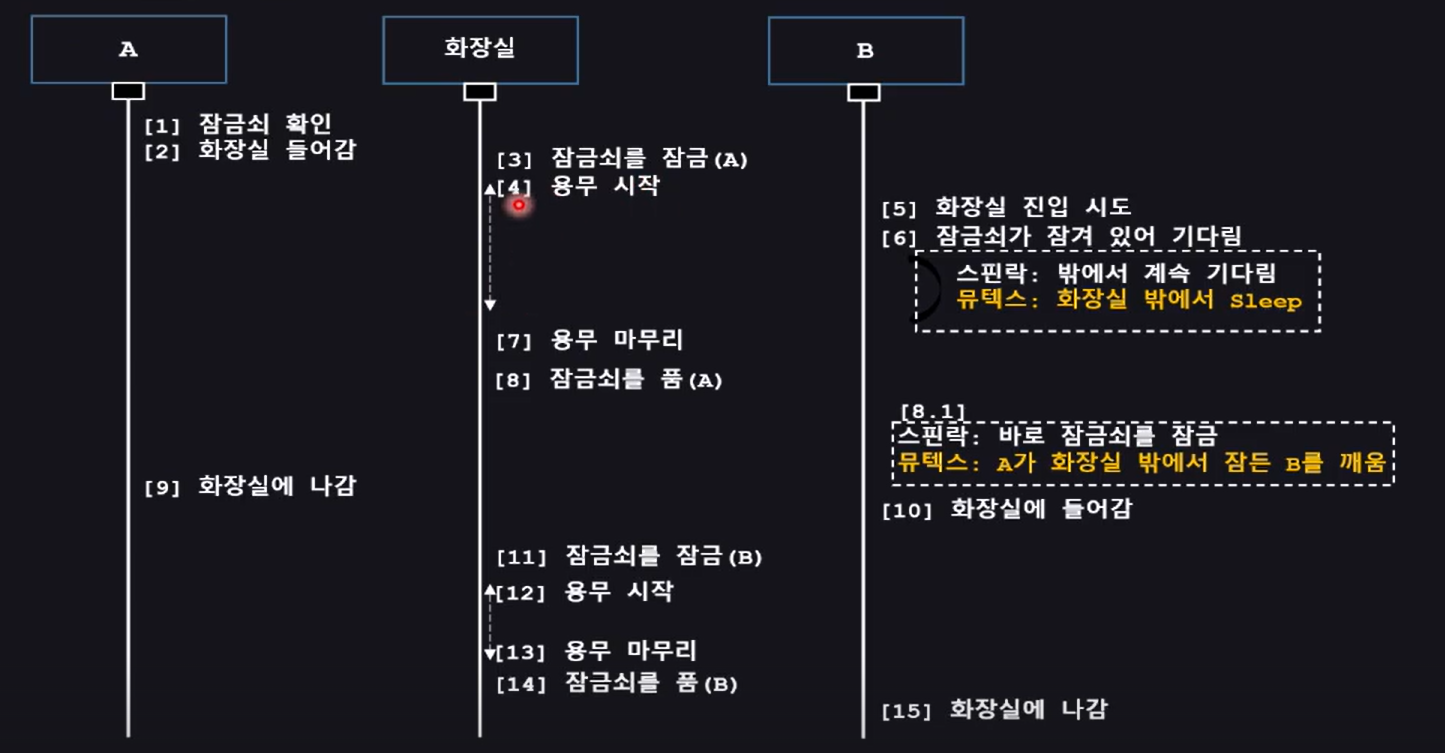
뮤텍스를 써서 Critical Section을 보호하는 루틴1
dbs_work_handler() 함수
static void dbs_work_handler(struct work_struct *work)
{
struct policy_dbs_info *policy_dbs;
struct cpufreq_policy *policy;
struct dbs_governor *gov;
policy_dbs = container_of(work, struct policy_dbs_info, work);
policy = policy_dbs->policy;
gov = dbs_governor_of(policy);
/*
* Make sure cpufreq_governor_limits() isn't evaluating load or the
* ondemand governor isn't updating the sampling rate in parallel.
*/
mutex_lock(&policy_dbs->update_mutex);
gov_update_sample_delay(policy_dbs, gov->gov_dbs_update(policy));
mutex_unlock(&policy_dbs->update_mutex);
...
}뮤텍스를 써서 Critical Section을 보호하는 루틴2
iommu_probe_device() 함수
mutex_lock(&group->mutex);
iommu_alloc_default_domain(group,dev);
mutex_unlock(&group->mutex);
if(group->default.domain){
ret = _iommu_attach_device(group->default_domain, dev);
뮤텍스를 써서 Critical Section을 보호하는 루틴3
qaic_postclose() 함수
static void qaic_postclose(struct drm_device *dev, struct drm_file *file)
{
mutex_lock(&qddev->users_mutex);
if(!list_empty(&usr->node))
list_del_init(&usr->node);
mutex_unlock(&qddev->users_mutex);
뮤텍스 자료구조
뮤텍스 구조체
owner : 해당 뮤텍스가 해제가 되었는지 lock 되었는지 확인할 수 있는 필드
wait_list : 뮤텍스가 한번도 획득되지 않았다면 wait_list가 비워져있음
다른 프로세스가 뮤텍스 획득을 시도하면 자신을 wait_list에 등록함
struct mutex {
atomic_long t owner; // 뮤텍스를 획득한 프로세스의 task descriptor 주소
raw_spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list; // 뮤텍스를 기다리는 프로세스의 정보
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_mapdep_map;
#endif
}; - CONFIG_MUTEX_SPIN_ON_OWNER, CONFIG_DEBUG_MUTEXES, CONFIG_DEBUG_LOCK_ALLOC는 추가 디버깅 Feature
