
테이블에 대한 동작 속도를 높여주기 위한 자료구조
Index와 사용 이유
책의 목차와 같이 DB의 Index도 Query의 SELECT 문의 속도를 향상시키는 역할을 한다.
Index도 하나의 DB 객체이므로 따로 저장 공간이 필요하며, 보통 저장된 공간의 10% 정도가 Index를 위한 저장 공간으로 사용된다.
- Oracle, DB2 등에서는 스키마 객체 역할
- MySQL, SQL Server 등에서는 테이블 내의 객체 역할
Index 동작 방법
특정 컬럼에 Index를 설정해서, 해당 컬럼을 기반으로 데이터를 정렬한 후 별도 메모리 공간에 데이터 물리적 주소와 함께 Index를 저장하게 된다
책 내용 - 데이터
책 목차 - Index
책 페이지 번호 - 물리적 주소
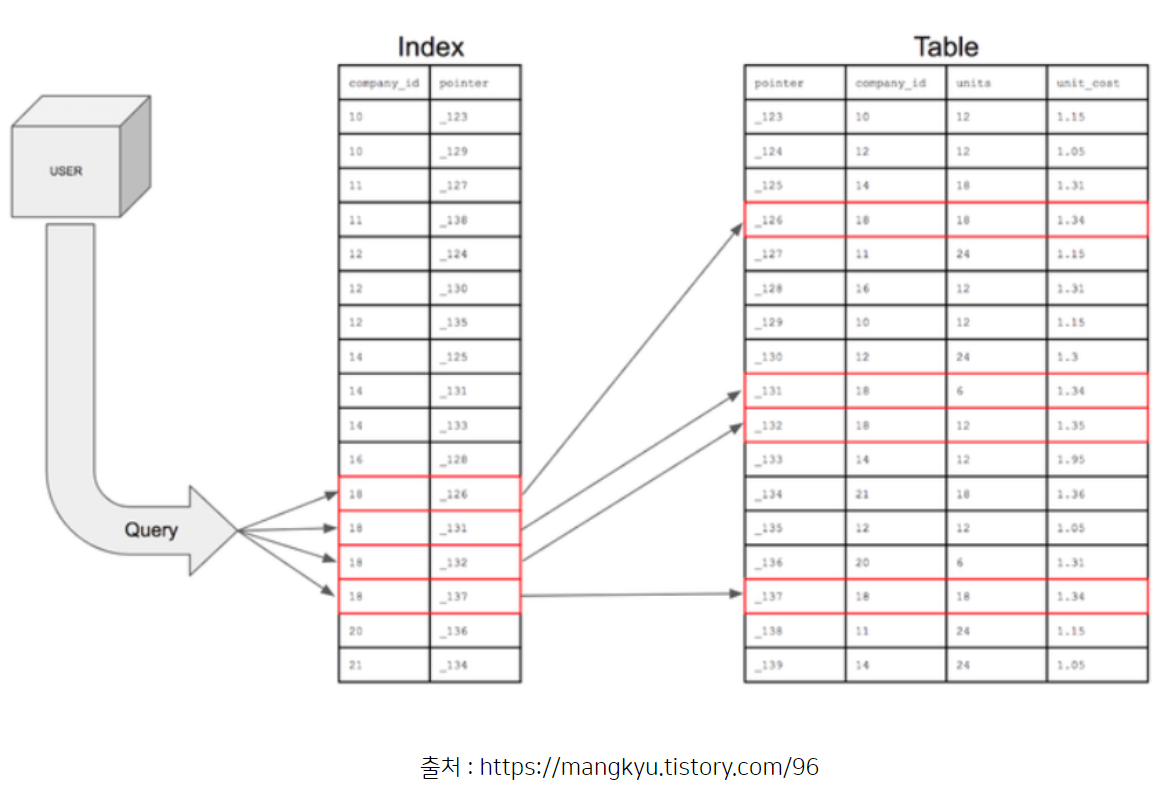
Index의 핵심은 Index에 의해 데이터가 정렬된 형태를 갖는 다는 점!!
1. Full Table Scan - Index가 없을 경우
DB의 모든 데이터를 하나하나 대조하면서 원하는 데이터를 찾는 방식
2. Index Scan - Index가 있을 경우
Index를 참고해 특정 데이터를 찾음
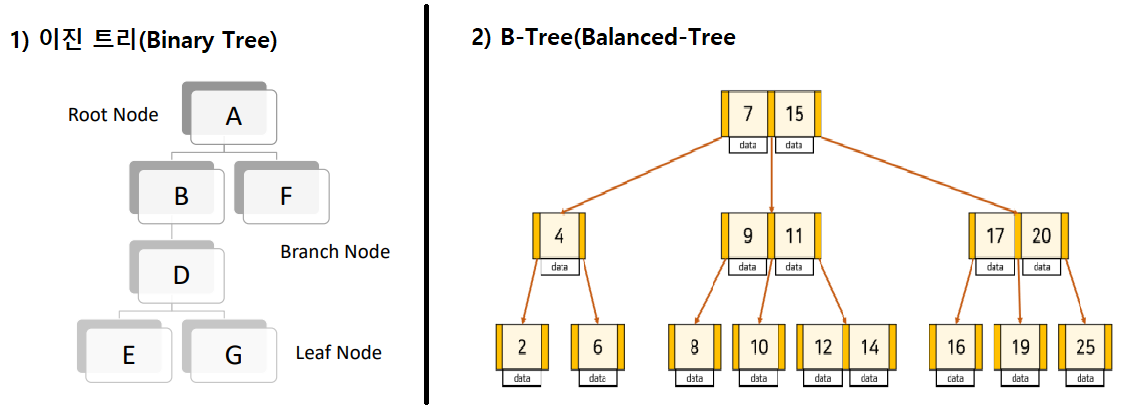
대표적으로 B-Tree 자료구조가 있다
※ 참고 B-Tree 자료구조
기존의 이진 트리(Binary Tree)는 노드 수가 2개로 제한 되어있고 한쪽 노드에 트리 구조가 몰리는 단점이 존재
B-Tree(Balanced-Tree) 구조는 자식 노드를 2개 이상 가질 수 있고, Root 노드 부터 leaf 노드까지 거리가 일정하다는 특징이 있음
Clustered Index VS Non-Clustered Index
1. Clustered Index
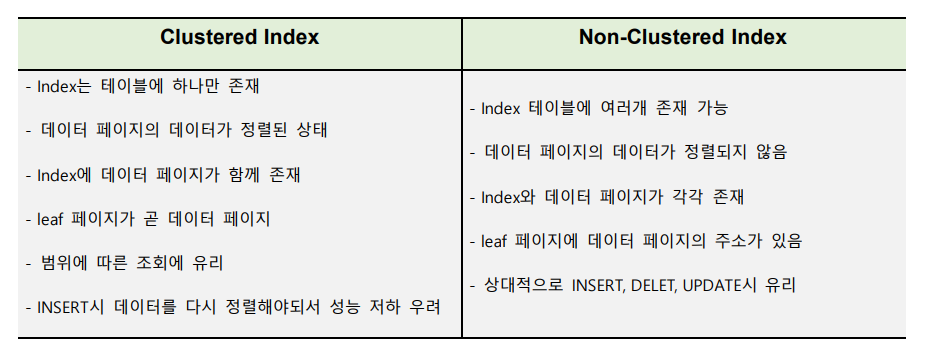
Index 안에 데이터가 포함(Index와 데이터가 군집)
- 테이블 당 1개만 존재
- PK 생성시 Clustered Index로 자동 생성
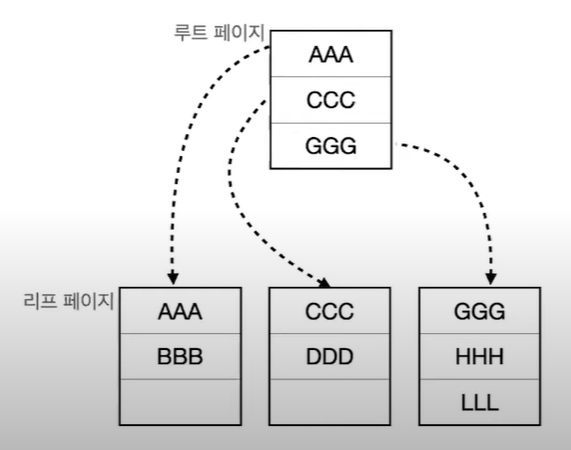
- 데이터가 정렬된 상태
- Index에 데이터 페이지가 함께 존재
- 리프 페이지가 곧 데이터 페이지
예시
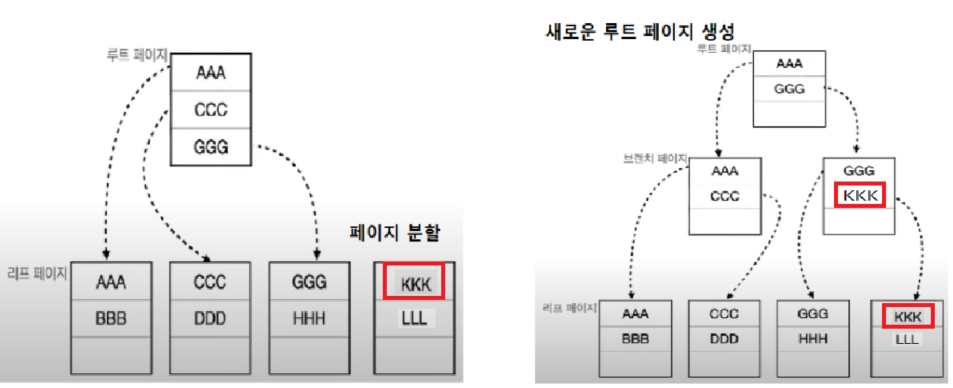
 여기서 HHH와 LLL 사이에 위치에 정렬되여야할 KKK 데이터를 집어 넣는다면, 페이지 분할이 필요하다
여기서 HHH와 LLL 사이에 위치에 정렬되여야할 KKK 데이터를 집어 넣는다면, 페이지 분할이 필요하다
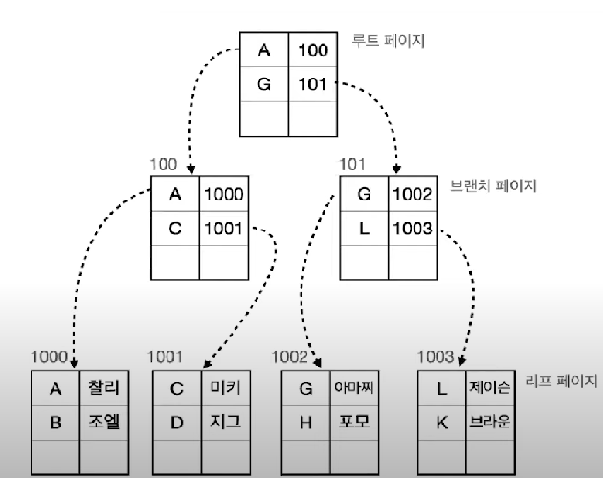
DB와 가까운 모습으로 다시 살펴 보면 H라는 데이터를 찾는을 때 2번의 이동만 하면 된다
루트 페이지에서 101 브랜치 브랜치로 이동
→ 101 브랜치에서 1002 리프 페이지로 이동
2.Non-Clustered Index
Index 안에 데이터가 포함되지 않음(Index와 데이터가 따로 존재)
- Secondary Index(보조 Index)라 불림
- 테이블에 여러개의 Index 존재 가능
- Unique 제약 조건 시 자동 생성
- Index와 데이터 페이지가 따로 존재
- 리프 페이지는 데이터의 주소를 가짐
- 데이터 페이지의 데이터가 정렬되지 않음
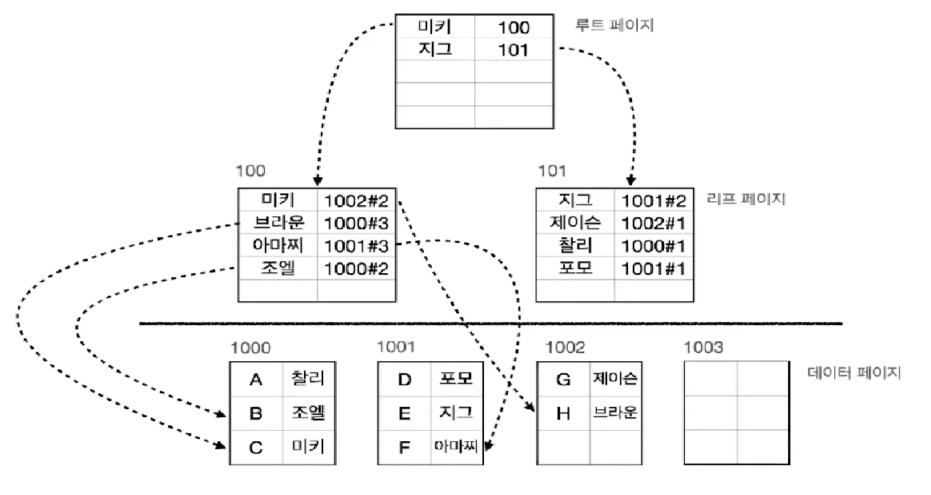
예시 - 닉네임 컬럼에 Non-Clustered Index 생성
데이터 페이지가 닉네임 순으로 정렬되어 있지 않지만, Index 쪽은 닉네임 순으로 정렬이 되어 있다
여기서 "검프"라는 데이터를 넣는 다면 아래와 같아진다
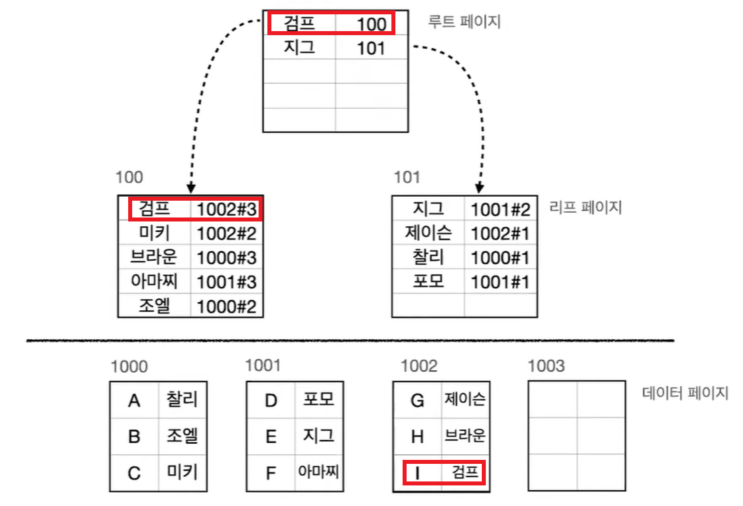
데이터 페이지에서는 제일 마지막에 데이터가 삽입되지만, Index 페이지에서는 정렬이 발생해 루트 페이지가 변하게 된다
따라서 INSERT, UPDATE, DELETE시 Clustered Index에 비해 성능 하락이 덜하다는 상대적인 장점이 있지만, 조회시 리프 페이지에 있는 데이터 주소로 다시 데이터 페이지를 이동해야하는 단점이 있다
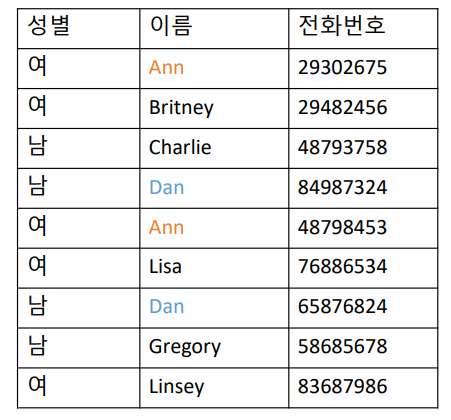
효과적인 Index 설정하기 - Cardinality
어떤 컬럼에 Index를 생성하냐에 따라 Query문의 성능이 좌우하게 된다
보통 Index를 설정하는 컬럼은 Cardinality가 높은 컬럼일 수록 더 적합하다고 판단한다
Cardinality가 높다 = 한 컬럼이 가지는 값의 중복도가 낮다 = 컬럼의 데이터 값이 다양하다
성별과 이름, 전화번호 3 컬럼이 있을 때, 중복된 수치가 낮은 전화번호 컬럼에 Index를 생성하는 것이 효율적이다
출처
우아한 테코톡 - 찰리의 인덱싱
https://www.youtube.com/watch?v=P5SZaTQnVCA
[Database] 인덱스(index)란?
https://mangkyu.tistory.com/96
[Database] Clustered Index와 Non-Clustered Index
https://pangtrue.tistory.com/286
