JPA

지금 시대는 객체를 관계형 DB에 관리한다.
SQL 중심적으로 개발을 진행하는 경우들이 대부분인데 이러한 SQL 중심적인 개발의 문제점은 반복되는 CRUD 작업들과 이로인한 지루한 코드들이다.
- 객체를 테이블에 맞추어 모델링하고 테이블에 맞추어 저장하게 된다.
- 객체는 자유롭게 객체 그래프를 탐색할 수 있어야하는데 객체답게 모델링 할 수록 매핑작업만 늘어나게 되는 문제점도 있다.
객체를 자바 컬렉션에 저장 하듯이 DB에 저장할 수 있는 방법은 없는가?? -> 이에 대한 해답이 바로 JPA이다.
JPA
- Java Persistence API
- 자바 진영의 ORM 기술 표준이다.
- JPA는 애플리케이션과 JDBC 사이에서 동작한다.
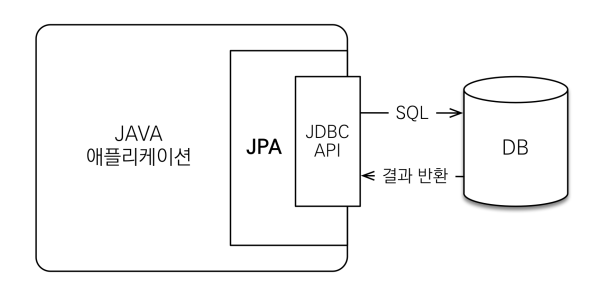
JPA는 인터페이스의 모음이다.
인터페이스인 JPA를 사용하기 위해서는 구현체가 필요하며, 이를 구현한 구현체 중 대표적인 것으로는 Hibernate가 있다.
- 구현체들을 좀 더 쉽게 사용하고자 추상화 시킨 Spring Data JPA라는 모듈을 이용하여 JPA기술을 다룰수 있다.
- 이들의 관계 : JPA <- hibernate <- Spring Data JPA
Spring Data JPA
Hibernate를 쓰는 것과 Spring Data JPA를 쓰는 것 사이에는 큰 차이가 없다.
그렇다면 왜 Spring Data JPA를 개발했으며, 이를 권장하는 것일까?
- 구현체의 용이성
- 저장소 교체의 용이성
크게 이렇게 두 가지 이유가 있다.
'구현체 교체의 용이성'이란, Hibernate외에 다른 구현체로 쉽게 교체하기 위함이다.
'저장소 교체의 용이성'이란, 관계형 데이터베이스 외에 다른 저장소로 쉽게 교체하기 위함이다.
ORM은 무엇인가?
- Object Relational Mapping 말 그대로 객체 관계 매핑이다.
- 객체는 객체대로 설계하고, RDBMS는 RDBMS로 설계하는 것이다.
- ORM 프레임워크가 중간에서 매핑 해준다.
그래서 우리는 JPA를 왜 사용해야하는가??
SQL 중심적인 개발에서 우린 개발자 답게 객체 중심으로 개발을 할 수 있다.
유지보수, 성능, 생산성도 좋아지며 패러다임의 불일치를 해결한다.
생산성이 어떻게 좋아지는가?
JPA는 아래의 기능이 다 만들어져 있으므로 개발자는 이러한 기능을 불러 쓰기만 하면 된다.
- 저장 : jpa.persist(member)
- 조회 : Member member = jpa.find(memberId)
- 수정 : member.setName("변경할 이름")
- 삭제 : jpa.remove(member)
유지보수는 어떻게 좋아지는가?
기존에 우린 필드가 변경되면 모든 SQL을 수정해야 했다. 하지만 JPA를 사용하면 필드만 추가하면 되고, SQL은 개발자가 직접 처리하는게 아닌 JPA가 알아서 처리한다.
JPA와 패러다임의 불일치 해결
- JPA와 상속
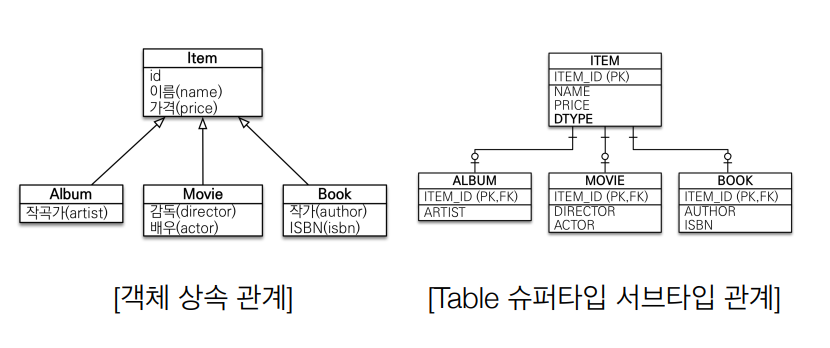
저장
개발자가 jpa.persist(album);을 명령하면 JPA는 이 명령을 받고, Item table과 Album table 두 군데 모두 insert 쿼리를 날려준다.
조회
개발자가 Album album = jpa.find(Album.class, albumId);라고만 명령을 하면 JPA가 알아서 Item과 Album을 Join해서 찾아온다.
연관관계와 객체 그래프 탐색
연관관계를 아래와 같이 저장하면
member.setTeam(team);
jpa.persist(member);객체 그래프를 탐색할 수 있다.
Member member = jpa.find(Member.class, memberId);
Team team = member.getTeam();JPA의 성능 최적화 기능
1. 1차 캐시와 동일성(identity)을 보장한다.
-> 같은 트랜잭션 안에서는 같은 엔티티를 반환한다. 약간의 조회 성능이 향상된다.
String memberId = "100";
Member m1 = jpa.find(Member.class, memberId); //SQL
Member m2 = jpa.find(Member.class, memberId); //캐시
println(m1 == m2) //true위의 코드를 보면 SQL은 한 번만 실행한다.
1차 캐시를 사용하기 때문에 동일한 트랜잭션에서 조회한 엔티티가 같음이 보장된다.
2.트랜잭션을 지원하는 쓰기 지연
-> 트랜잭션을 커밋할 때까지 SQL을 모아서 JDBC BATCH SQL 기능을 사용해서 한 번에 SQL을 전송한다.
transaction.begin(); //트랜잭션 시작
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다.
//커밋하는 순간 데이터베이스에 INSERT SQL을 모아서 보낸다.
transaction.commit(); //트랜잭션 커밋3.지연로딩(Lazy Loading)
-> 지연로딩이란 객체가 실제로 사용될 때 로딩하는 것을 말한다.
Member member = memberDAO.find(memberId); //select * From Member
Team team = member.getTeam();
String teamName = team.getName(); //select * from Team
//이때 실제로 team이 사용되기 때문에 실제로 로딩된다.
//member는 자주쓰고, team은 가끔 쓰는 경우에 지연로딩을 사용
//보통 지연로딩을 사용하다가 최적화가 필요할 때 즉시로딩을 옵션으로 사용한다.반대로 즉시로딩은 JOIN SQL로 한번에 연관된 객체까지 미리 조회하는 방법이다.
Member member = memberDAO.find(memberId); //select M.* , T.* From Member Join Team....
From Member
Team team = member.getTeam();-> member를 가져온 경우에 member만 주로 쓰는 경우에는 지연로딩을 사용하면 좋고, member와 연관된 객체를 같이 쓰는 경우에는 즉시로딩을 사용하는 것이 좋다.
Reference
참고 : https://www.inflearn.com/course/ORM-JPA-Basic/dashboard 김영한 님의 JPA 프로그래밍 강의
https://book.naver.com/bookdb/book_detail.nhn?bid=9252528 자바 ORM 표준 JPA 프로그래밍
https://book.naver.com/bookdb/book_detail.nhn?bid=15871738 스프링부트와 AWS로 혼자 구현하는 웹서비스
위의 책을 참고하고, 강의를 수강하면서 작성한 글입니다.
틀린 부분 등 다양한 피드백 환영합니다.
