
📜 참고 자료
MSA 아키텍처에서는 내부적으로 서로 통신하는 관계의 서비스 중 하나라도 오류가 발생하면, 실제 오류가 나지 않은 MS에서도 500번대 응답 상태코드가 반환되게 됩니다.
따라서, 한 MS에서 다른 MS와 통신 시에, 오류가 발생했을 경우 해당 데이터 대신에 디폴트 값으로 전달해줄 데이터를 가지고 있어 오류를 방지하도록 구현해줘야 합니다.
따라서, 하나의 Microservice 장애가 시스템 전체에 확산되지 않도록 처리해줘야 합니다.(fault tolerance)
예를 들면,
Users Microservice -> Feign Client -> Order MicroService -> Catalog Microservice 의 순서로 호출이 발생하고 있는 경우에
Order 또는 Catalog 측에서 오류가 발생하더라도, 실제 요청을 받은 User Service에서는 이에 상관없이 User Microservice 자체 오류가 아니라면, 200번대 정상 응답을 보내줘야 한다는 점이 핵심입니다.
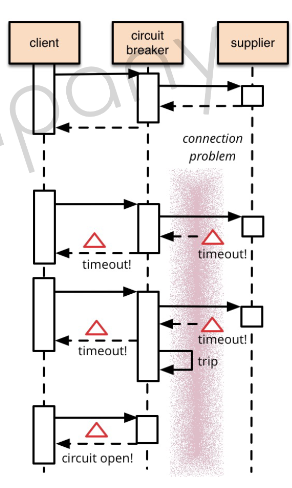
장애가 발생한 서비스에 대한 요청을 차단(장애 회피)하여 시스템 전체의 부하를 줄이고, 더 많은 오류가 발생하지 않도록 하는 기능을 제공하는 도구를 Circuit Breaker 라고 합니다.
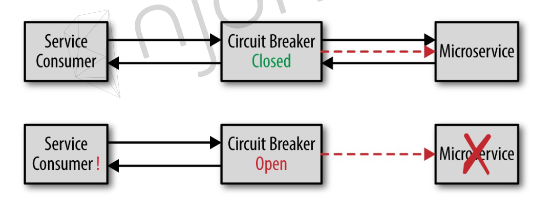
아래의 그림은 공식 사이트에서 가져온 CircuitBreaker의 상태를 표현한 그림입니다.
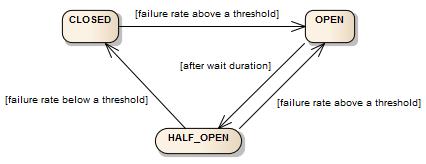
CircuitBreaker의 3가지 상태인 CLOSED, OPEN, HALF-OPEN 입니다.
- CLOSED (닫힘 상태)
- 초기 상태이며, 서비스 호출이 정상적으로 발생하는 상태를 말합니다.
- CircutBreaker가 호출을 모니터링하고, 호출 실패 시 횟수를 측정하게 됩니다.
- 정해진 실패 임계값을 초과 시 CircuitBreaker는 Open 상태로 전환됩니다.
- OPEN(열림 상태)
- 일정 시간 동안 모든 호출이 차단되는 상태를 말합니다.
- 설정한 시간이 지나면, CircuitBreaker의 상태는 다시 HALF-OPEN 상태로 전환됩니다.
- HALF-OPEN(반열림 상태)
- 일정 시간 동안 제한된 수의 호출만을 허용합니다.
- 이 시간 동안 호출이 성공하면 CircuitBreaker는 Closed 상태로 전환되고, 실패하면 Open 상태로 전환됩니다.
그렇다면, 어떻게 이러한 CircuitBreaker를 실제 서비스에 도입할 수 있을까요?
이를 사용하기 위해 Spring 진영에서 만든 Resiliance4J 라는 라이브러리가 있습니다.
💡 Resilience4J란?
Neflix의 Hystrix와 유사한 fault tolerance를 위한 라이브러리입니다. fault tolerance라는 것은 시스템의 일부가 장애가 나더라도 전체 시스템은 중단 없이 잘 동작할 수 있도록 해주는 능력을 말합니다. 이러한 기능은 MSA 구조에서 한 MS에 장애가 전체 시스템의 장애로 전파되는 것을 막기위해 사용됩니다.
Resilience4j와 CircuitBreaker의 관계는 포함관계로써, Resilience4J 라는 라이브러리 내 포함된 핵심 모듈 중에 하나가 CircuitBreaker 입니다.

Circuit Breaker 설정 시에, Resilience4JCircuitBreakerFactory에 설정을 해줍니다.
.failureRateThreshold() : CircuitBreaker를 open/close 결정하기 위한 failure rate(실패율 임계값)
- default : 50% ex) 10회 중 5회 실패 시, CircuitBreaker Open
waitDurationInOpenState() : CircuitBreaker를 open 상태를 얼마나 유지할지 설정합니다.
- default : 60sec ex) open 이 후 60초 동안 open상태 유지
slidingWindowType : CircuitBreaker 가 닫힐 때 통화 결과를 기록하는데 사용되는 슬라이딩 창의 유형을 설정합니다.
- 횟수 또는 시간 기반(몇 회 요청 실패했는가, 얼마동안 open되어 있었는가)
slidingWindowSize : 슬라이딩 창의 크기 구성
- 횟수 또는 시간의 기준을 의미합니다.
- default : 100
💡 Sliding Window란?
슬라이딩 윈도우는 최근 X개의 요청을 분석하여 open 상태로 바꿀지 말지 여부를 결정합니다.
이 때, 설정으로 가능한 옵션으로 시간과 횟수가 있습니다.
- 시간 기준 : x초 간 10% 이상의 예외 발생 시 OPEN 상태로 전환.
- 횟수 기준 : 최근 X개의 요청 중 10% 이상의 예외 발생 시 OPEN 상태로 전환.

실제 서비스에 비유하면, order service에서 4초동안 응답이 없을 경우, CircuitBreaker를 Open 해줍니다.
Users Microservice - CircuitBreaker 적용
현재 OrderService 서버를 꺼놓은 상태에서 회원 상세 정보 조회 요청을 보내게 되면, 다음과 같이 응답 상태 코드 500 에러가 발생하게 됩니다.

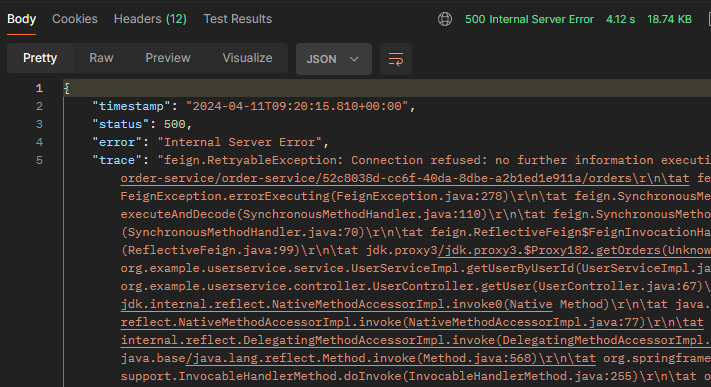
이를 CircuitBreaker 설정을 해주면, 200 응답으로 orders에 빈배열을 가져올 수 있도록 합니다.
Resilience4j 의존을 추가 해줍니다.
implementation 'org.springframework.cloud:spring-cloud-starter-circuitbreaker-reactor-resilience4j'그 다음으로 UserServiceImpl 내부 로직을 수정해줍니다.
기존의 UserServiceImpl에 회원 상세 정보를 조회하는 메서드 내부에 CircuitBreaker를 설정해주도록 하겠습니다.
@Override
public UserDto getUserByUserId(String userId) {
UserEntity userEntity = userRepository.findByUserId(userId);
if(userEntity == null)
throw new UsernameNotFoundException("user not found");
UserDto userDto = new ModelMapper().map(userEntity,UserDto.class);
/* CircuitBreaker 적용 */
CircuitBreaker circuitBreaker = circuitBreakerFactory.create("circuitbreaker");
List<ResponseOrder> orderList = circuitBreaker.run(() -> orderServiceClient.getOrders(userId),
throwable -> new ArrayList<>());
userDto.setOrders(orderList);
return userDto;
}위처럼 기본적으로 Resilience4j에서 제공하는 CircuitBreaker를 도입하였습니다.
그렇다면, 다시 postman에서 요청하여 테스트 해보겠습니다.
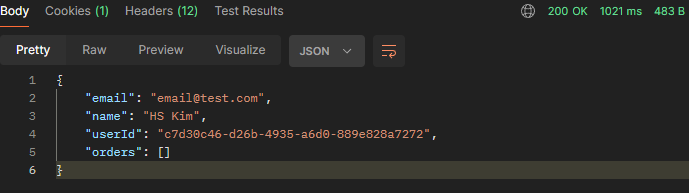
위와 같이 정상적으로 200 응답상태 코드 반환 및 orders라는 빈배열을 출력하도록 구현하였습니다.
요약하면, Order Microservice가 죽어있는 상태인 경우에는 ArrayList의 빈 배열을 반환하도록 되어 있고, 정상적으로 서버가 돌아갈 경우엔 정상적인 데이터를 반환하도록 해주는 것이 CircuitBreaker입니다.
일반적으로, 이러한 Circuit Breaker에 모니터링 시스템을 연동해주어 사용합니다. ex) 프로메테우스
Microservice 분산 추적 - Zipkin
MSA에서는 독립적으로 서비스를 제공하지 않고 다른 MS와 연쇄적인 상호작용을 통해서 제공하게 됩니다.
그 과정에서 해당하는 요청 정보가 어떻게 서버에 전달되고, 어떠한 처리과정을 거쳐서 서비스를 제공하는지에 대해 추적할 수 있는 기능을 "Microservice 분산 추적" 이라고 합니다.
분산 추적을 위해서 tracing 정보를 저장하기 위한 서비스가 필요합니다.
이를 위해서 zipkin 이라는 서비스를 사용하겠습니다.
간단하게 zipkin에 대해서 설명하면,
- Twitter에서 사용하는 분산 환경의 Timing 데이터 수집, 추적 시스템을 제공하는 오픈 소스입니다.
- Google Drapper에서 발전하였으며, 분산환경에서의 시스템 병목 현상을 파악하는데 사용됩니다.
- Collector, Query Service, Database
즉, MSA 아키텍처 및 분산 시스템의 발전으로 인해서, 해당 환경에서 어디서 문제가 발생하는지에 대한 시각적인 모니터링 시스템의 필요성에 의해서 개발됐습니다.
zipkin을 사용하면서 기억해야 하는 핵심 단어가 있습니다.
span
- 하나의 요청에 사용되는 작업의 단위를 의미합니다.
- 64 bit unique ID(고유키)
Trace
- 트리 구조로 이뤄진 span 셋
- 하나의 요청에 대한 같은 Trace ID를 발급합니다
Spring Cloud Sleuth
- 스프링 부트 애플리케이션을 Zipkin과 연동합니다.
- 요청 값에 따른 Trace ID, Span ID를 부여합니다.
- Trace와 Span Ids를 로그에 추가가 가능합니다.
- servlet filter
- rest template
- scheduled actions
- message channels
- feign client
⚠️ spring-cloud-sleuth-stream 스팩 아웃 & Brave 도입
이 프로젝트의 핵심 기능이 Micrometer Tracing 프로젝트로 이관되면서(참고) Spring Cloud Sleuth가 Spring Cloud Release Train에서 제거됐습니다(참고).
이로 인해, 기존의 사용했던 Spring Cloud Sleuth 라이브러리에서 Brave로 변경해줘야 합니다.
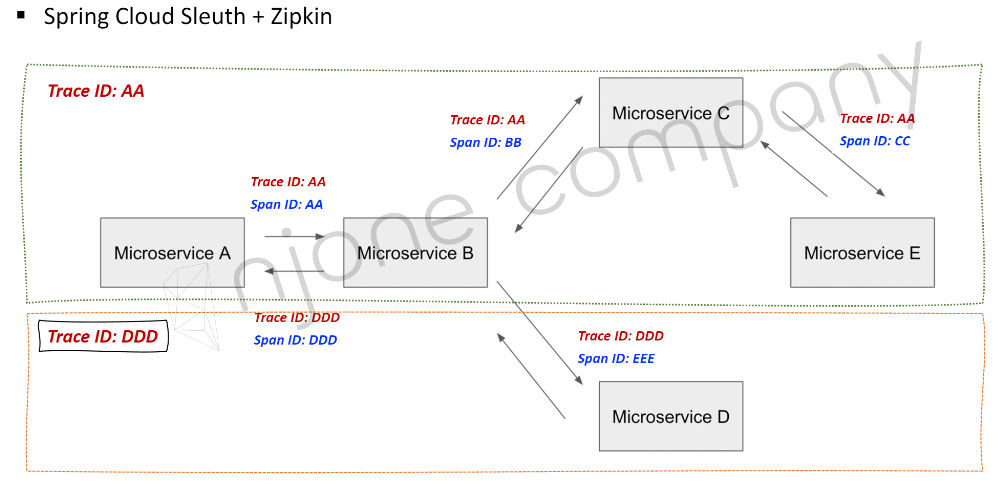
위에서 알 수 있듯이 하나의 요청에 대한 내부 통신은 하나의 Trace ID로 엮여 있고, 트랜잭션 추적을 위해서 각각의 Span ID가 부여됩니다.
Zipkin 실습
📜 Zipkin 설치
위에 Zipkin 공식 사이트에 들어가시면, quickstart 방식에 대한 설명이 있습니다. 해당 내용대로 진행하시면, 다음과 같이 Zipkin이 실해되게 됩니다.
필자의 경우, 윈도우11 home 을 사용중이며 bash 명령어 사용을 위해서 git bash 상에서 zipkin을 실행시켰습니다.
$ java -jar zipkin.jar
Zipkin 서버의 기본 포트번호는 9411을 사용하며, 아래의 링크를 타고 들어가면 Zipkin 서버의 대시보드 확인이 가능합니다.
그 다음으로 MS와 연동해보도록 하겠습니다.
위에 언급한 것과 같이 현재 Zipkin 연동을 위한 라이브러리가 변경되어 Spring Boot 3.x 버전부터는 Micrometer와 연결하기 위한 Brave 라이브러리를 추가해줘야 합니다.
implementation 'io.micrometer:micrometer-observation'
implementation 'io.micrometer:micrometer-tracing-bridge-brave'
implementation 'io.zipkin.reporter2:zipkin-reporter-brave'actuator의 management를 사용하여 zipkin 설정을 해주므로, Spring Boot Actuator 의존성도 추가되어 있는지 확인해줘야 합니다.
implementation 'org.springframework.boot:spring-boot-starter-actuator'그 다음으로 application.yml 파일을 수정하겠습니다.
management:
endpoints:
web:
exposure:
include: refresh, health, beans, busrefresh
tracing:
sampling:
probability: 1.0
propagation:
consume: b3
produce: b3_multi
zipkin:
tracing:
endpoint: "http://127.0.0.1:9411/api/v2/spans"-
consume :
시스템이 외부에서 들어오는 요청을 처리할 때 사용하기 위한 트레이싱 데이터의 전파 형식을 지정합니다. b3 전파 형식을 사용하여 들어오는 트레이싱 데이터를 해석하고 처리한다는 것을 의미합니다. b3 전파 형식은 Zipkin 트레이싱 시스템에서 널리 사용되며, 트레이스 ID, 스팬 ID, 샘플링 결정 등을 전파 시 사용하게 됩니다. -
produce :
시스템이 외부로 보내는 요청 또는 메시지에 사용할 트레이싱 데이터의 전파 형식을 정의합니다. b3_multi는 B3의 멀티헤더 형식을 사용하여 트레이싱 데이터를 전송한다는 것을 의미합니다. 멀티헤더 형식은 별도의 헤더로 각각의 트레이싱 정보를 전송합니다. -
zipkin.tracing.endpoint :
zipkin에 저장하기 위한 주솟값을 명시해주는 설정입니다.
요청 성공 시나리오
실제 postman을 통해서 요청을 보내보도록 하겠습니다.
우선, order-service의 주문 생성 로직에 log를 추가해준 뒤 주문 정보를 생성하겠습니다. postman을 통해서 요청 2개를 보내게 되면 다음과 같이 console에 찍히게 됩니다.
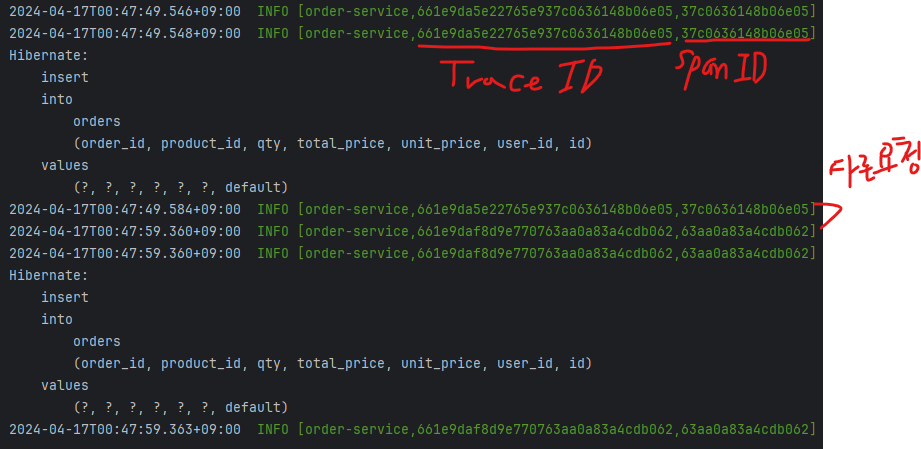
2개의 요청이 다르므로, Trace ID와 Span ID가 모두 다르게 나오는 것을 확인할 수 있습니다.
추가로, Zipkin 대시보드에서도 해당 요청에 대한 정보를 TraceID로 추적 및 조회가 가능합니다.
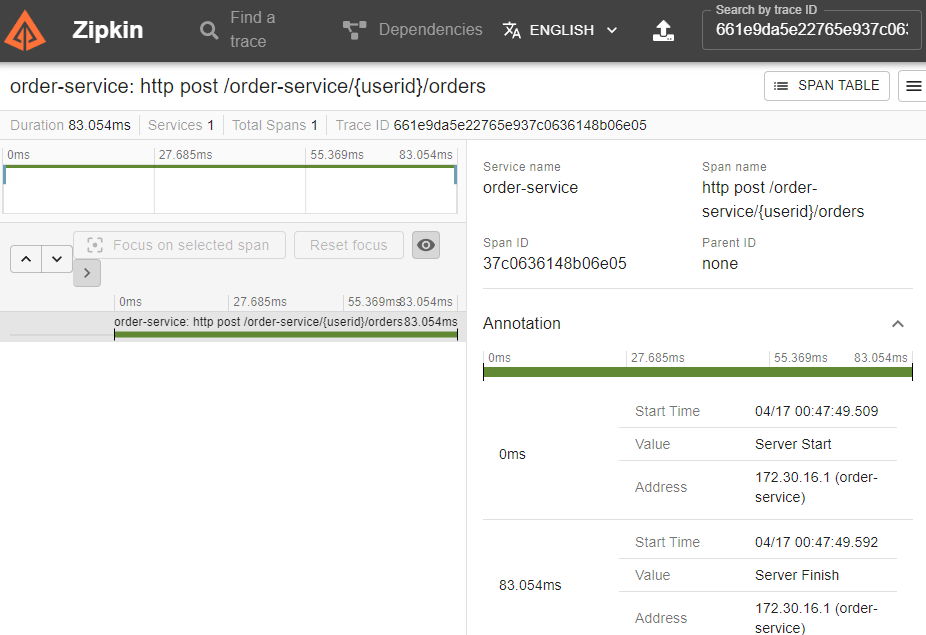
그 다음으로, user-service에 회원 정보 조회를 통해서 주문 정보를 가져와 보도록 하겠습니다.
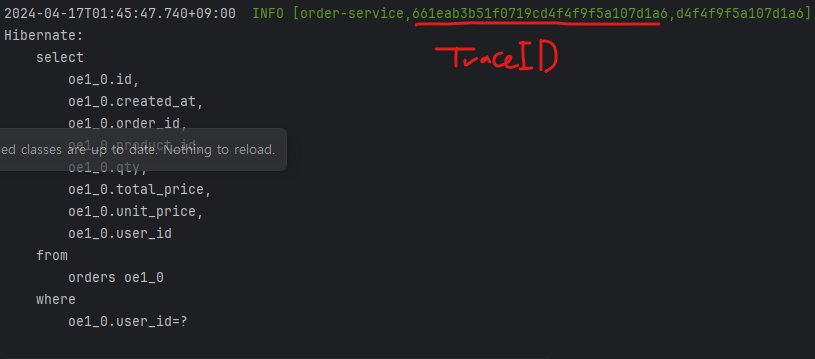
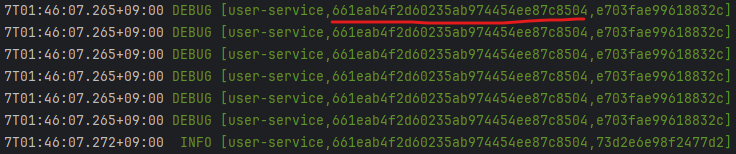
위처럼 하나의 HTTP 요청 내에서 또다른 HTTP 요청이 발생할 경우, 두 요청은 하나의 TraceID를 가지지만, 다른 SpanID를 갖게 됩니다.(원래는 이게 맞지만....)
실제로는 해당 TraceID 값이 다르게 출력됩니다... 이 부분은 추가적으로 설정이 필요한것 같기도 합니다.. 하하
즉, Zipkin에서 서비스 내 호출 관계에 대한 흐름을 Tracing하여 기록하며, 이 때 필요한 호출 데이터에 대한 정보를 Micrometer의 Brave 라는 라이브러리를 통해서 전달을 해준다고 보면 됩니다.
이어서 Zipkin 대시보드에 보시면, Find a trace 라는 버튼이 있습니다. 해당 버튼을 누르게 되면, Zipkin에 저장된 호출 정보들에 대해서 "serviceName" 으로 조회가 가능합니다
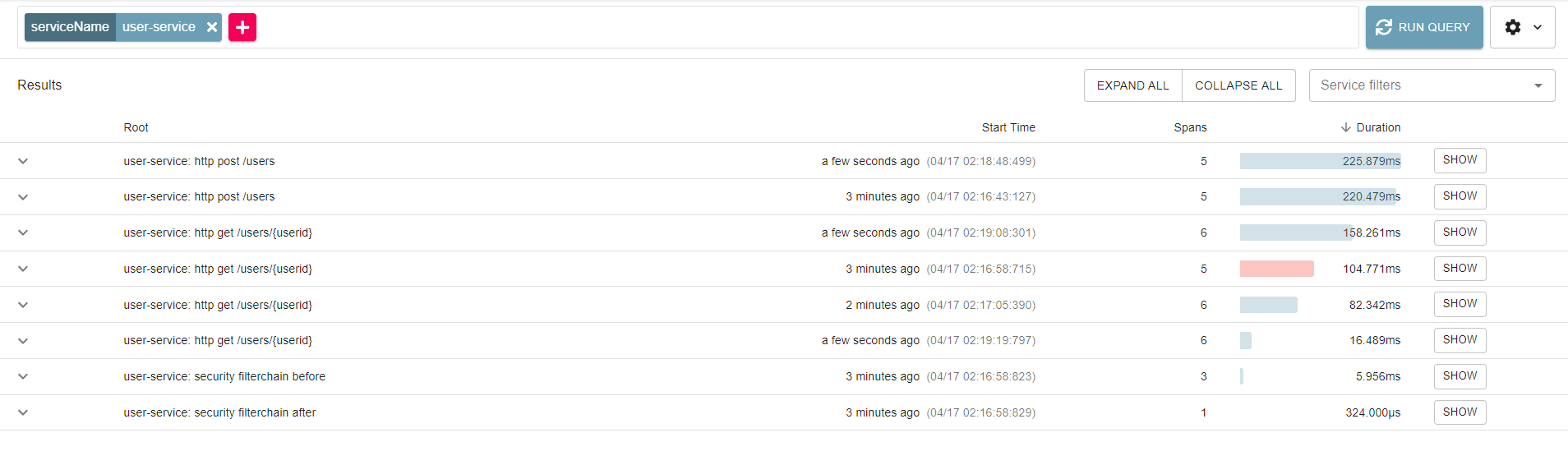
요청 실패 시나리오
