
참고 포스팅
👀 lower_bound와 upper_bound 차이
직역하면 lower bound 는 하한, upper bound는 상한을 의미합니다.
lower bound, 즉 하한은 찾고자 하는 값 이상의 값이 처음으로 나타나는 위치를 의미합니다.
즉, 를 찾는 것을 말합니다.
그림으로 나타내면 아래와 같습니다.
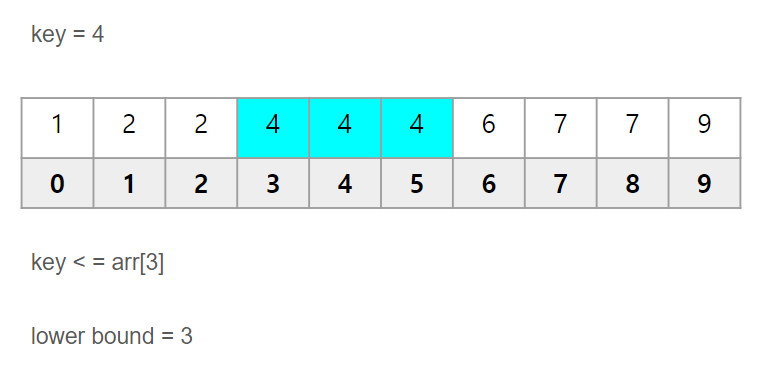
처음으로 마주하는 key 값 이상을 갖는 인덱스는 3입니다.
즉, lower bound는 3이라는 값이 됩니다.
upper bound는 상한을 의미하며, 찾는 값을 초과하는 값을 처음 만나는 위치를 말합니다.
즉, 를 찾는 방식입니다.
그림으로 나타내면 다음과 같습니다.
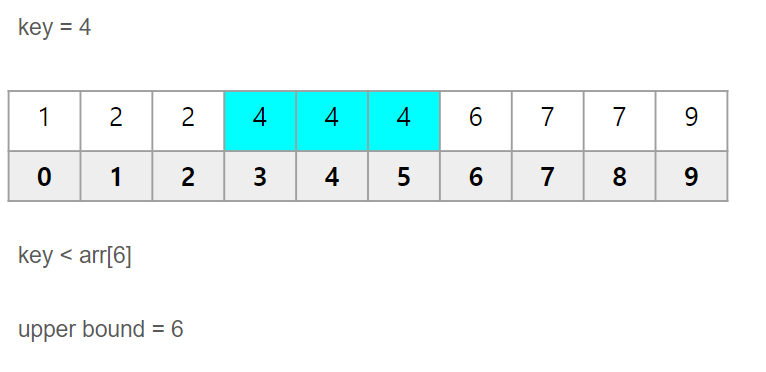
그림에서 key 값인 4를 초과한 값을 처음 만나는 인덱스는 6입니다.
👀 심화
조금만 더 깊게 생각해보면 다음과 같은 그림에서, key 값이 5인 경우, lower bound와 upper bound의 위치는 어디를 의미할까요?
위 방식 그대로 적용하면, 5 이상의 값을 가진 인덱스(lower bound), 5를 초과하는 값을 가진 인덱스(upper bound)를 찾으면 됩니다.
그림으로 나타내면 다음과 같습니다.
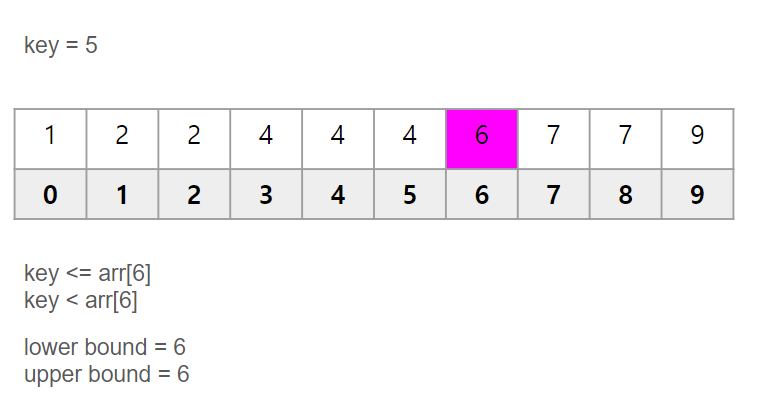
위처럼 배열에 없는 값의 경우, 같은 위치를 의미하게 됩니다.
👀 정리
이처럼 위와 같은 방식을 통해서 중복 원소에 대한 길이를 상한 - 하한 이라는 식을 통해서 구할 수 있습니다.
위 방식은 원소가 배열에 존재하지 않더라도 상한과 하한이 같은 인덱스를 가리키기 때문에 0이 출력되므로 예외가 발생할 확률이 줄어 안전합니다.

백엔드 서버 엔지니어