
이전 포스트에서 이어지는 내용입니다.
JVM은 기본적으로 Runtime Data Area라는 곳에 저장한다. 클래스 로더에 의해 로드된 클래스부터, 인스턴스 변수까지 모두 이곳에 저장된다.
Runtime Data Area
는 크게 5가지로 나뉜다.
- Method Area
- Heap
- Java Stacks
- PC register
- Native Method Stacks
이 중 PC register, Native Method Stacks는 각각 스레드 실행과 다른 언어로 작성된 메소드를 다루는 영역이다.
자바 프로그램 작성 시 프로그래머가 주로 신경쓰게 되는 영역은 위 세가지, Method Area, Heap, Java Stacks 인데 이에 대해 자세히 알아보자.
Method Area
는 JVM이 실행될 때 단 하나만 생성되며, 종료 시 사라진다. 인스턴스 생성을 위한 객체 구조, 생성자, 필드 등이 저장된다.
여기서 눈여겨 볼 것은 static 키워드가 붙은 클래스 변수, 메소드들 또한 이 곳에 저장된다는 것이다.
Method Area는 단 하나만 생성되기 때문에 모든 Thread가 공유해서 사용하므로, 동시성 문제가 발생할 수 있어 주의해야 한다.
Stack
은 각 Thread 별로 따로 할당되는 영역이다. 지역 변수, 파라미터 등이 저장되며, Thread가 소유하는 공간이기 때문에 동시성 문제에서 자유로울 수 있다.
Heap
영역은 Method Area와 마찬가지로 JVM 당 하나만 생성된다. new 키워드를 통해 생성된 객체는 Heap에 저장된다. 객체는 기본적으로 Heap 영역에 생성되고 변수에 주소가 참조되는 형태로 동작한다.
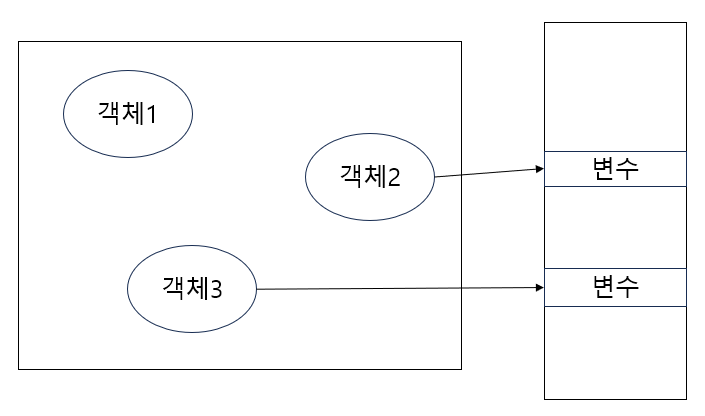
객체는 변수에 참조되어 사용된다. 위 그림을 보면 더이상 참조되지 않는 객체1이 메모리를 차지하고 있는데, 객체1처럼 더이상 참조되지 않는 객체를 지워주는 역할을 Garbage Collector가 하게 된다.
Garbage Collector
C언어를 생각해보자. 프로그램 실행 중 메모리를 할당받고 싶다면 malloc 함수를 사용해야 하고, 할당한 메모리는 반드시 해제해줘야 한다. 결국 메모리 사용에 대한 책임을 프로그래머가 지게 된다.
Java는 메모리 할당을 위해 new 키워드를 사용한다. 이를 통해 Heap 영역에 런타임에 동적으로 메모리를 할당받을 수 있다. 또한, Garbage Collector가 사용하지 않는 메모리를 제거해줌으로써 프로그래머는 메모리의 할당 및 해제의 책임으로부터 자유로워질 수 있다.
비유해보자면 가비지 콜렉터는 청소 시간을 정하지 못하는 로봇 청소기와 같다. 청소에 신경쓰지 않아도 되기 때문에 편하지만 새벽에 동작해서 잠을 다 깨울수도 있는 것이다.
제거 과정
기본적으로 가비지 콜렉터, GC는 힙 영역에서 주로 발생한다. 전통적인 Heap 영역은 다음과 같이 구성된다.

GC는 Mark and Sweep 이라는 동작을 통해 객체를 제거하게 된다.
- 참조가 존재하는지 확인하는 Mark
- 참조가 존재하지 않는 객체를 제거하는 Sweep
- Sweep 후 남은 객체를 Heap의 시작 주소로 모으는 Compact
새로 생성된 객체는 Eden 영역에 생성되고, Eden 영역이 가득차게 되면 Eden 영역을 지우는 GC가 동작하며, 이를 Minor GC 라고 한다.
이후 Survivor 영역에서 살아남을 때마다 Age 값이 증가하고, 특정 수준을 넘게 되면 Old 영역으로 이동된다.
위 과정을 반복하며, Old 영역또한 가득차게 되면 Old 영역을 지우는 GC가 동작하며, 이를 Major GC 혹은 Full GC 라고 한다.
그렇다면 왜 GC를 두 동작으로 구분한걸까?
그 이유는 Heap의 메모리 구조 때문이다. Heap 영역은 2가지 전제(Weak Generational Hypothesis)를 기반으로 설계되었다.
- 대부분의 객체는 금방 접근 불가능한 상태(Unreachable)가 된다.
- 오래된 객체에서 새로운 객체로의 참조는 아주 적게 존재한다.
이러한 특성 때문에 크게 Young(New)와 Old 2가지 영역으로 구분하며, GC 또한 각 영역에 맞춰 두 단계로 구분되었다.
기본적으로 Eden 영역보다 Old 영역의 크게가 상대적으로 큰데, 이는 Minor GC가 Major GC보다 훨씬 자주 일어나며 시간 또한 적게 걸린다는 것을 의미한다.
여기서 중요한 점은 GC가 동작할 때 스레드가 멈추는 Stop the World 현상이 발생한다는 것인데, 이 때문에 GC가 일어날 때마다 애플리케이션이 멈춘다는 것이다.
이 때문에, 오래 걸리는 Major GC를 최대한 적게 발생시키는 것이 애플리케이션의 성능에 좋은 것이다.
다만, 위 내용은 자바 8의 이전의 GC(Parellel GC)에 적용되는 내용이며, Java 9 이후부턴 G1GC가 디폴트 GC로 설정되었다.
G1GC는 물리적으로 고정된 역할을 나누지 않고, Region이라는 개념을 도입했다. 각 Region은 동적으로 역할이 부여되며, 메모리를 탐색하지 않고 가득 찬 Region을 우선적으로 처리한다.
이후 ZGC라는 새로운 GC도 나왔는데, ZGC는 역할 뿐만 아니라 영역의 크기까지 동적으로 할당할 수 있는 ZPage라는 개념을 도입한 GC이다.
그렇다면 디폴트로 설정된 G1GC가 가장 좋을까?
GC 알고리즘의 선택은 애플리케이션의 특성과 GC 튜닝 과정을 통해 선택해야 한다. jstat과 같은 모니터링 툴을 이용해 GC가 어떻게 이루어지는지 확인하고, 원하는 방식으로 바꿔 나가면 된다. GC가 너무 자주 발생한다면 Heap 영역의 크기를 늘릴 수도 있지만, 이 때는 Stop the World 시간이 그만큼 길어지는 것을 염두에 둬야 한다.
참고 자료
정프로 블로그 - JVM 구조와 자바 런타임 메모리 구조
Inpa-Dev - GC 총정리
Tecable - JVM Part 3, Runtime Data Area
