
들어가기에 앞서
프로젝트를 진행하며 동시성 문제가 발생했다.
단일 시스템
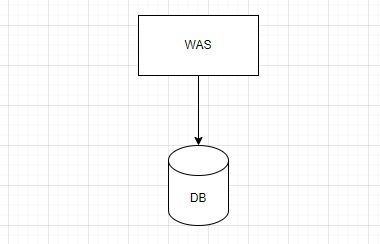
이전 포스트에선 synchronized 키워드를 통해 임계 영역을 지정하여 해결하는 전통적인 방식을 구현해보았다.
분산 시스템
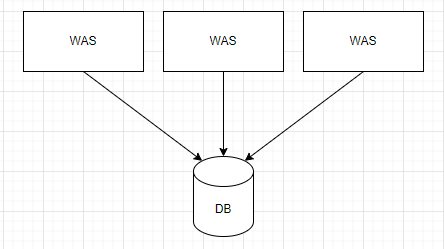
다만 위와 같은 방법은 여러 컴퓨터가 네트워크를 통해 연결되어 하나의 시스템처럼 동작하도록 설계된 분산 시스템에선 의도한대로 동작하지 않는다.
그렇다면 분산 시스템에선 어떻게 동시성 문제를 해결해야 할까?
데이터베이스 락킹
비관적 락과 낙관적 락
DB 레벨에서의 락킹을 찾아봤을 때 가장 먼저 나온 것들이다.
비관적 락 은 현재 변경하고자 하는 레코드를 다른 트랜잭션에서도 변경할 수 있다는 비관적인 가정 을 하기에 비관적 락 이라고 부르며,
낙관적 락 은 각 트랜잭션이 같은 레코드를 변경할 가능성이 희박할 것이라 낙관적인 가정 을 하기에 낙관적 락 이라 부른다.
무슨 차이가 있을까?
아이러니하게도 낙관적 락은 보통 DB 레벨에서 지원하지 않는다. 낙관적 락은 보통 어플리케이션 레벨에서 지원하며, JPA는 보다 간단하게 낙관적 락을 사용할 수 있도록 지원하고 있다.
비관적 락은 변경하고자 하는 레코드에 대한 락을 획득한 후 작업을 진행한다. 기본적으로 MySQL의 InnoDB 엔진은 비관적 락을 채택하고 있다.
아쉽게도 이 포스트에선 낙관적 락을 다루지 않는다. 다만, 잘 정리된 포스트가 존재하기에 공유해본다.
잡설
비관적 락 과 낙관적 락 을 공부하며 개인적으로 synchronized 와 CAS 알고리즘 의 차이가 떠올랐다.
synchronized 는 메소드 혹은 블록 수준에 임계 영역을 지정하여 다른 스레드로부터의 접근을 차단하는 방법이다.
CAS 알고리즘 은 Atomic한 자료형에서 사용하는 방법인데, 기대하는 값과 다르다면 연산을 진행하지 않는 방법이다.
공유 락과 배타적 락
비관적 락은 크게 공유 락 과 배타적 락 으로 구분된다.
공유 락 은 다른 트랜잭션이 읽거나 또 다른 공유 락 의 접근을 허용한다. 다만, 배타적 락 의 접근, 즉 쓰기 작업을 제한한다.
# 공유 락
SELECT * FROM table_name WHERE id = 1 FOR SHARE;배타적 락 은 다른 트랜잭션이 해당 레코드에 접근하는 것 자체를 막는다. 단, 락을 사용하지 않는 읽기 작업은 접근을 허용한다.
# 배타적 락
SELECT * FROM table_name WHERE id = 1 FOR UPDATE;구현
현재 비즈니스 로직은 다음과 같다.
그룹 가입 시, 현재 인원이 제한 인원에 걸리는지 확인 후 가입을 진행한다.
두 트랜잭션이 동시에 접근한다고 가정해보자. 처음 접근한 트랜잭션이 완료된 후 현재 인원을 확인해야 한다. 따라서 배타적 락 을 사용해 동시성 문제를 해결하였다.
JPA에선 어노테이션을 통해 간편하게 배타적 락 을 사용할 수 있다.
// GroupRepository
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT g FROM music_group g WHERE g.id = :id")
Optional<Group> findByIdWithLock(@Param("id") Long id);그룹을 조회할 때 위 메소드를 사용하도록 변경했다.
@Transactional
public void joinGroup(GroupJoinRequestDto dto, Long groupId) {
Group group = groupService.findGroupByIdWithLock(groupId);
...
}발생하는 쿼리를 확인해보자.
2024-06-13T00:06:58.984+09:00 DEBUG 15024 --- [group-service] [nio-8082-exec-1] org.hibernate.SQL : select g1_0.id,g1_0.created_date,g1_0.description,g1_0.group_scope,g1_0.group_size,g1_0.join_condition,g1_0.name,g1_0.owner_user_id,g1_0.profile_count,g1_0.state,g1_0.updated_date from music_group g1_0 where g1_0.id=? for updatefor update 가 붙은 query가 발생함을 확인할 수 있다.
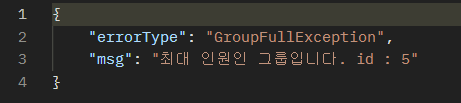
보다 늦게 실행된 두번째 요청은 정상적으로 실패함을 확인할 수 있었다.
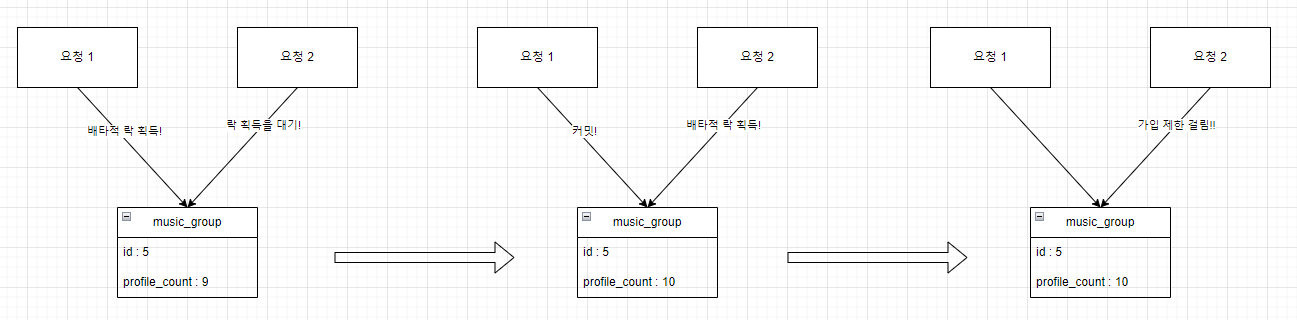
왜?
1. 트랜잭션 격리 수준
이전 포스트에서 synchronized 키워드를 통해 문제를 해결할 때도 발생했던 문제가 있다. 바로 트랜잭션 격리 수준, 그 중 MySQL의 기본 수준인 Repeatable Read와 관련된 문제이다.
트랜잭션이 시작된 시점의 데이터만을 조회한다.
@Transactional 어노테이션을 동일하게 사용했기에 두번째 요청 의 트랜잭션은 여전히 첫번째 요청 커밋 전에 시작된다. 그렇다면 두번째 요청 이 조회해도 변경이 적용되지 않은 데이터가 조회되어야 하는게 아닐까?
다행히도 Real MySQL 5.7 책에 동일한 내용을 찾을 수 있었다.
REPEATABLE READ 수준의 동일 트랜잭션 내에서 SELECT 쿼리 결과는 항상 동일해야 한다.
SELECT .. FOR UPDATE 쿼리는 SELECT 하는 레코드에 쓰기 잠금을 걸어야 하는데, 언두 레코드에는 잠금을 걸 수 없다.
그래서 SELECT .. FOR UPDATE 나 SELECT .. LOCK IN SHARE MODE 로 조회되는 레코드는 언두 영역의 변경 전 데이터를 가져오는 것이 아니라 현재 레코드의 값을 가져오게 되는 것이다.
잡설
언두(UNDO) 영역은 트랜잭션의 롤백과 트랜잭션 격리 수준의 요구를 구현하기 위해 사용된다.
REPEATABLE READ는 언두 영역에 존재하는 데이터를 확인함으로써 트랜잭션 시작 시점의 데이터를 조회할 수 있다.
2. 성능 이슈
레코드 자체에 락을 건다는 건 해당 레코드에 접근하는 다른 요청들이 대기해야 한다는 의미다.
또한 두 요청이 각각의 레코드 락을 보유한 채로 서로의 레코드 락을 얻기 위해 대기한다면 데드락이 발생할 수도 있다.
3. 다른 방법은?
1. USER LOCK
user-level-lock, 혹은 Named Lock이라고도 불리는 방법이다.
이 락은 특이하게도 테이블, 레코드와 같은 데이터베이스 객체를 잠그지 않고, 특정 문자열(String)를 통해 락을 획득하고 해체하는 락킹 기법이다.
배타적 락 을 사용했을 때, 레코드 자체의 접근을 제한함으로써 다른 요청에서 동일한 레코드에 접근하기 위해 대기해야 하는 성능 문제가 발생한다고 했다.
유저 락을 지정한다면 특정 문자열, 즉 그룹 가입이라는 락을 따로 두어 다른 작업 시 대기하는 성능 문제와 데드락 문제를 해결할 수 있다.
2. 분산 락
동시성 문제를 해결하기 위해 가장 흔히 보이는 방법이다. 보통 Redis를 이용하며, 인메모리 캐시라는 특성 상 빠른 속도를 자랑한다.
마치면서
DB Level에서 동시성 문제를 해결할 수 있는 비관적 락, 그 중 배타적 락에 대해 알아보았다.
다음 포스트에선 위의 두가지 방법에 대해 구현하며 알아보겠다.

참고 자료
Real MySQL
mysql docs
flab - 분산 시스템 설계의 핵심: 분산 락의 이해와 적용
LJH - 동시성 문제 해결하기 V1 - 낙관적 락
hudi.blog - MySQL 8.0의 공유 락(Shared Lock)과 배타 락(Exclusive Lock)
haon.blog - MySQL 네임드 락으로 분산 환경에서의 동시성 이슈를 해결해보자!
