
Java의 Collection들은 각각 특별한 특징이 있다.
List는 Array와는 다르게 가변 길이의 목록을 지원하며, Set은 중복되지 않는 집합을, Map은 Key : Value 쌍으로 이루어져 Key를 통해 빠르게 값을 찾을 수 있다.
Java에서는 HashMap으로 이러한 Map의 특성을 구현하였다. HashMap은 이론상 O(1)의 시간 복잡도를 갖는다고 하는데, 어떻게 빠르게 값을 찾을 수 있다는 걸까?
들어가기에 앞서
중복을 허용하지 않는 자료 구조인 HashSet을 열어보면 다음과 같이 구현되어 있는 것을 볼 수 있다.
transient HashMap<E,Object> map;
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}HashSet은 내부적으로 HashMap을 통해 구현되어 있다. 값 삽입 시 Value에 빈 객체를 저장하며, Key를 통해 값을 저장하고 관리한다.
구조
동작을 이해하기 위한 최소한의 필드들만 가져왔다.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
transient int modCount;
int threshold;
final float loadFactor;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final float DEFAULT_LOAD_FACTOR = 0.75f;여기서 눈여겨 볼 것은 Node<K, V>[] table 이다. 해당 필드를 통해 데이터를 저장하고, 빠르게 읽을 수 있다. 방법은 이후에 살펴보고, 생성자를 보자.
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}ArrayList와 마찬가지로, 데이터가 저장되는 변수를 초기화하지 않는 Lazy Initialize 구조를 가진다.
loadFactor는 값 삽입 시에 알아보도록 하자.
동작
값 삽입 시의 동작을 살펴보자.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}hash(key) 메소드를 통해 해시 값을 얻고, putVal() 메소드를 호출한다.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}hash() 메소드를 살펴보면 key의 hashCode 값을 비트 연산을 통해 가공한 값을 반환하는데, 이는 해시 값의 고른 분포를 위해 사용된다. 동작을 확인해보자.
@Test
void hashTest() {
String str1 = "Hello1";
String str2 = "Hello2";
System.out.println("str1.hashCode() = " + str1.hashCode());
System.out.println("str2.hashCode() = " + str2.hashCode());
System.out.println("hash(str1) = " + hash(str1));
System.out.println("hash(str2) = " + hash(str2));
}위 코드를 실행하니 다음과 같은 값들이 반환되었다.
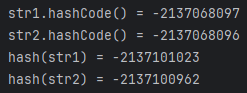
hashCode를 통해 반환된 값은 1 차이지만, 추가적으로 비트연산을 진행한 후엔 꽤 큰 차이가 나는 것을 볼 수 있다.
값을 삽입하는 putVal() 메소드를 확인해보자.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}굉장히 복잡하다.. 부분별로 쪼개서 확인해보자.
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; 이 부분에서 초깃값을 세팅한다. table이 비었다면 resize()를 통해 table 필드를 초기화한다.
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); 위에서 살펴봤던 hash() 메소드를 통해 만들어진 hash 값을 사용한다. 이건 뭘까?
위로 돌아가보면 n 은 현재 테이블의 길이다. 즉, 테이블의 최대 크기와의 논리 연산을 통해, 큰 값을 갖는 hash() 메소드의 결과를 table의 인덱스에 들어갈 수 있도록 변경한다.
위 부분은 결국 key의 해시값을 table의 인덱스에 매칭시키고, 해당 인덱스가 비었을 시 인덱스에 새로운 노드를 할당한다.
테이블의 인덱스를 "버킷" 이라고 부르기도 한다.
해시 충돌?
hash() 메소드를 통해 해시를 고르게 분포했더라도, 동일한 해시 값이 나올 수도 있다. 이 때, table에서 동일한 인덱스를 찾게 되는데, 이를 해시 충돌이 발생했다고 한다.
HashMap은 해시 충돌이 발생하면, 해당 버킷의 뒤로 LinkedList 를 연결하여 해결한다. 이러한 기법을 Separate Chaining 이라고 한다.
하지만 LinkedList 로 연결된 데이터가 많아질수록 값을 찾기 위해 순회하는 데이터가 많아지므로, 결국에는 이론상 O(1)이라는 좋은 성능을 잃어버리게 된다.
HashMap의 필드를 다시 확인해보자.
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;HashMap은 이러한 단점을 극복하기 위해 LinkedList가 일정 이상 이어지게 된다면 Tree 구조로 변환하여 빠른 검색이 가능하도록 조치한다.
else {
...
}이후 부분은 해시 충돌이 발생하여 LinkedList 의 가장 끝을 찾아가는 로직이다.
if (++size > threshold)
resize();마지막 부분을 보면 size 와 threshold 의 비교를 통해 resize() 를 진행하는 코드가 있다.
threshold는 resize() 내부에서 정해진다.
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);간단하게 살펴보면 loadFactor 과의 곱을 통해 다음 threshold가 정해진다.
Load Factor?
필드를 다시 살펴보자.
static final float DEFAULT_LOAD_FACTOR = 0.75f;이는 생성자를 통해 설정할 수 있는 값이기도 하다.
동작을 확인해보자. 보다 쉽게 확인하기 위해 가장 처음 실행되는 resize() 부분을 가져왔다.
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); 다음 threshold 는 0.75 * 16 이 된다. 즉, 저장된 데이터가 12개가 넘으면 다음 로직이 실행되고, 리사이즈가 진행된다는 것이다.
if (++size > threshold)
resize();loadFactor 를 1로 지정한다면 어떻게 될까 생각해보자.
다음 threshold 값이 1 * 16 이 되므로 16개, 버킷이 가득 찰 수도 있을 때가 되어야 resize() 가 실행된다.
resize() 가 실행될 땐 기존 데이터들을 새로 할당된 table에 다시 넣는 rehash 작업이 진행되는데, 이는 다른 작업에 비해 큰 리소스를 사용한다.
결국
rehash 가 너무 빈번하게 일어나지도 않고, 해시 충돌 또한 적당히 일어나는 수준의 loadFactor 를 지정해야 한다는 결론이 나온다.
개인적인 생각은 큰 문제가 없다면 기본 값인 0.75를 사용하는 게 좋다고 생각한다.
equals()와 hashCode()
HashMap은 기본적으로 중복 키를 허용하지 않는다. equals() 메소드를 통해 같은지 키가 같은지 확인하며, hashCode() 를 사용하여 데이터가 들어갈 버킷을 정한다.
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;다음 예시를 보자
static class Sample {
private String name;
public Sample(String name) {
this.name = name;
}
}
@Test
void equalsTest() {
Map<Sample, String> sampleMap = new HashMap<>();
Sample sample1 = new Sample("Hello");
Sample sample2 = new Sample("Hello");
System.out.println(sample1.equals(sample2));
sampleMap.put(sample1, "good");
sampleMap.put(sample2, "nice");
System.out.println("sampleMap.size() : " + sampleMap.size());
}키로 같은 내용을 갖는 Sample 객체를 사용했다. 키는 중복을 허용하지 않기 때문에 sampleMap 의 size는 1 이어야 한다.

실행 결과가 예상과 다르다. 이는 두 Sample 객체가 논리적으로 같다는 것을 알려주지 않아 발생한다.
equals() 메소드를 재정의하고 다시 실행해보자.
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Sample sample = (Sample) o;
return Objects.equals(name, sample.name);
}
아직도 사이즈가 2인것을 볼 수 있다. 이는 hashCode() 메소드가 재정의되지 않아 서로 다른 해시 값을 생성해 발생한다.
System.out.println("hash(sample1) = " + hash(sample1));
System.out.println("hash(sample2) = " + hash(sample2));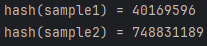
논리적으로 동일한 객체지만 서로 다른 hash를 생성하는 것을 볼 수 있다. 이 때문에, 동일한 값이 서로 다른 버킷에 저장되는 불상사가 발생한 것이다.
이제 hashCode() 메소드를 재정의 해보자.
@Override
public int hashCode() {
return Objects.hash(name);
}
드디어 원하는 값이 나왔다. HashMap의 key로 객체를 사용할 때는 반드시 equals() 와 hashCode() 를 재정의 하자.
이러한 중복 키 문제는 HashMap 자체에서도 문제가 되지만, HashMap을 내부적으로 사용하는 HashSet 에서는 더 큰 문제로 다가온다.
번외
다음 코드를 실행해보았다.
@Test
void sameHashTest() {
Map<Sample, String> sampleMap = new HashMap<>();
long start = System.currentTimeMillis();
for (int i=0;i<100000;i++) {
sampleMap.put(new Sample("Hello"+i), "");
}
long end = System.currentTimeMillis();
System.out.println(end-start);
}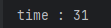
31ms가 소요되었다.
그렇다면 hashCode() 를 다음과 같이 재정의하면 어떻게 될까?
@Override
public int hashCode() {
return 1;
}
기존보다 4000배가 넘는 시간이 걸렸다. 이유가 뭘까?
위 예제에선 모두 같은 해시를 반환한다. 모든 데이터에서 해시 충돌이 발생하며, Separate Chaining에 의해 동일한 버켓에 들어가게 된다. 값을 삽입하기 위해 해당 LinkedList 혹은 Tree 를 순회하여 동일 값이 있는지 확인해야 하며, 이를 N번 반복하게 된다.
해시 충돌이 적을수록 성능이 좋다.
라는 개념을 단편적으로 이해할 수 있던 예시였다.
결론
해시맵이 키를 이용해 O(1)의 시간으로 값을 찾는지 알 수 있었다.
어떠한 문제를 해결할 때 순차적으로 값에 접근하는 ArrayList 와 키를 통해 값을 빠르게 찾는 HashMap 중 잘 고민해서 필요한 컬렉션을 골라서 사용하면 되겠다!

참고 자료
자바의 신 VOL.2
modiday - hashmap 원리
Tecoble - equals, hashCode 재정의
