들어가기에 앞서
모두의 음악 프로젝트엔 가상의 결제 서비스 가 존재합니다. 이 결제 기능 은 두가지 조건을 가정하고 있어요.
- 결제 과정에 꽤 긴 시간이 소요된다.
- 결제 실패 후 단순 재시도 시 중복 결제가 발생한다.
1번의 경우 Kafka를 도입해 비동기 통신으로 전환했으며, 2번은 DB를 통한 이벤트 추적 방식으로 처리된 시점을 기록해 중복 결제를 방지했죠.
왜 비동기를 사용해야 할까?
Springboot의 기본 WAS인 Apache Tomcat은 Thread per Request, 즉 하나의 요청을 하나의 스레드가 전담하여 처리합니다.
Thread 생성 비용을 줄이기 위해 ThreadPool을 통해 스레드를 재사용하게 되는데, 이 때문에 시간이 오래 걸리는 작업이 존재한다면 해당 스레드가 반납되지 않고 오래 점유되어 스레드를 할당받지 못한 요청들이 대기를 하게 되죠.
그게 얼마나 큰 차인데?
말로는 알아도 얼마나 차이가 날지는 잘 모르겠어요. 그래서 해봤습니다!
Sync vs Async 실험
전제
보다 극적인 성능 차이를 관측하기 위해 결제 기능 에 5초 의 sleep을 주었습니다. 이제 결제 기능 은 실행 시 5초 가 걸리는 엄청난 동작이 된거죠.
Sync with RestTemplate
동기 방식의 실험은 위 그림과 같은 흐름으로 진행했어요. 프로젝트가 MSA 구조를 띄고 있다 보니, API-GATEWAY 를 통해 HTTP 요청을 보냈죠.
이제 GROUP-SERVICE 에서 발생한 요청과 그에 대응하는 스레드는 PAYMENT-SERVICE 의 처리가 끝나야 같이 마무리 될 거예요.
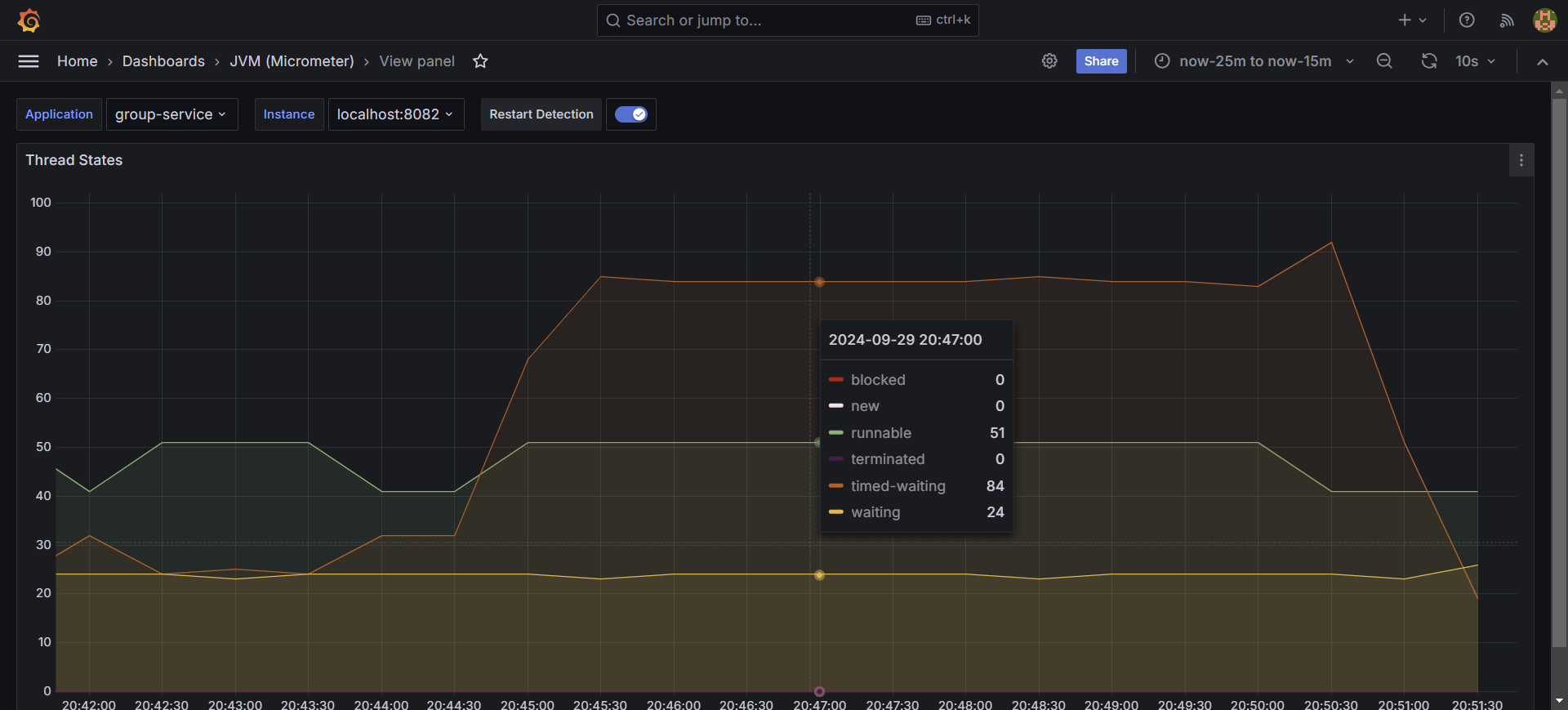
JMeter 결과

요청 조건은 다음과 같습니다.
payment → Thread 30, Ramp-up : 10, Duration : 300
search → Thread 50, Ramp-up : 1, Duration : 300
시간이 지날수록 search 기능의 속도가 기하급수적으로 느려졌어요. 이는 오랜 시간을 필요로 하는 payment 기능이 대부분의 스레드를 점유하고 있기 때문이죠.
결과적으론 약 12TPS의 성능을 보여줬네요.
Grafana
스레드 상태를 모니터링해보니 timed-waiting 이 많이 늘은 걸 볼 수 있었어요. 많은 스레드들이 결제 기능 에 묶여있는 걸 확인할 수 있었죠.
Async with kafka
그렇다면 Kafka를 통한 비동기 방식은 어떨까요? 요청 조건은 위와 동일하게 설정했어요.
JMeter

처음엔 잘못 본 줄 알았습니다. 1006 TPS를 기록했네요. 기존과 89.82배나 차이나는 결과를 얻었습니다.
Grafana
스레드 상태는 기존과 차이가 별로 없네요.
비교
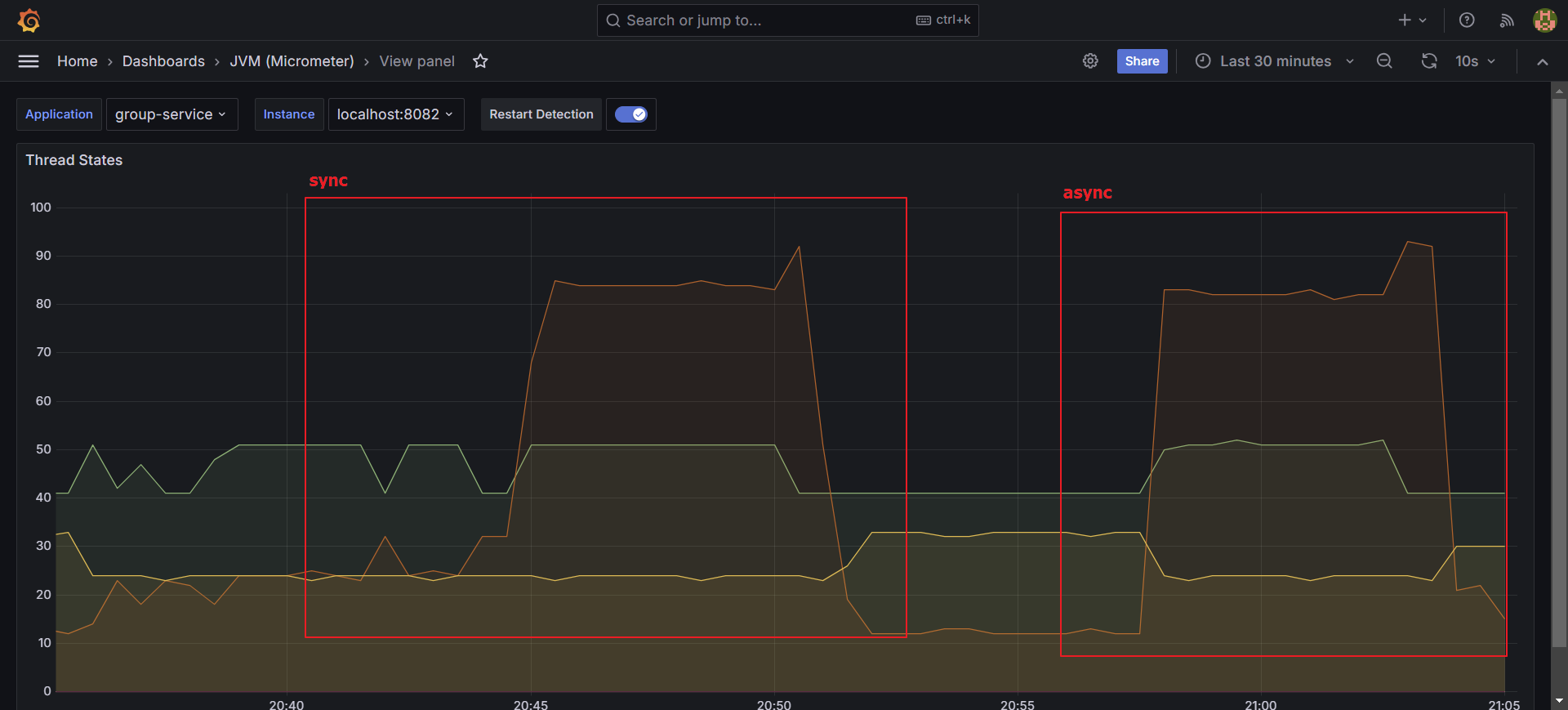
두 요청의 스레드 상태 변화를 관측했더니 굉장히 유사한 모습을 보여줍니다. 다만 성능은 89배 차이라는 점..!
비동기 적용 이후
드라마틱한 성능 향상을 보여준 비동기, 드디어 광명 찾은걸까요?
컨슈머 랙

카프카 컨슈머 랙을 확인해봤습니다.
또 잘못본 줄 알았습니다. 요청된 결제 기능 11만 9100건 중 11만 8900건이 처리되지 않고 대기중이네요.
결국 실질적으로 결제 처리가 된건 약 200건밖에 되지 않는다..는 겁니다.
이러면 안되는거 아니냐
실제 처리된 결제 기능 의 수는 조금 아쉽지만, 그럼에도 불구하고 굉장한 효과가 있어요.
GROUP-SERVICE는 더이상 결제 성능에 영향을 받지 않습니다.
기존 결과를 다시 봐볼까요?
오래 걸리는건 결제 기능 인데도 불구하고, 단순한 조회 요청에 대한 성능도 엄청나게 떨어졌죠.
Tomcat 자체 성능에 영향을 끼치는 스레드 점유 문제를 해결한 것만으로도 충분히 제 할일을 해주었다고 봐요.
그럼 컨슈머 랙은?
결제 기능 이 5초나 걸리는 조금 과장된 전제가 깔려서일까요? 굉장한 컨슈머랙이 발생했는데요.
발생한 요청의 개수는 5분간 약 12만건, 분당 2만 4천건의 결제 이벤트가 발생합니다.
컨슈머랙을 완전히 발생시키지 않으려면 초당 400건의 이벤트를 처리해야 하고, 5초가 걸리는 특성 상, 해당 토픽의 파티션과 컨슈머 그룹의 컨슈머 개수가 약 2000개는 되어야겠네요.
