
들어가기에 앞서
동시성 문제와 synchronized 에선 과금을 통해 그룹의 최대 회원수를 늘리는 비즈니스 모델을 제안, 구현했어요.
이번 포스트에선 결제를 담당하는 임의의 서비스 payment-service 를 구현하고 group-service 와 카프카를 통해 요청을 주고 받는 내용에 대해 적어보겠습니다.
방법
1. 직접 통신
가장 처음 생각해본 방법이예요. HTTP API를 통해 요청하는 방식이죠. 프로젝트 구성을 볼까요?
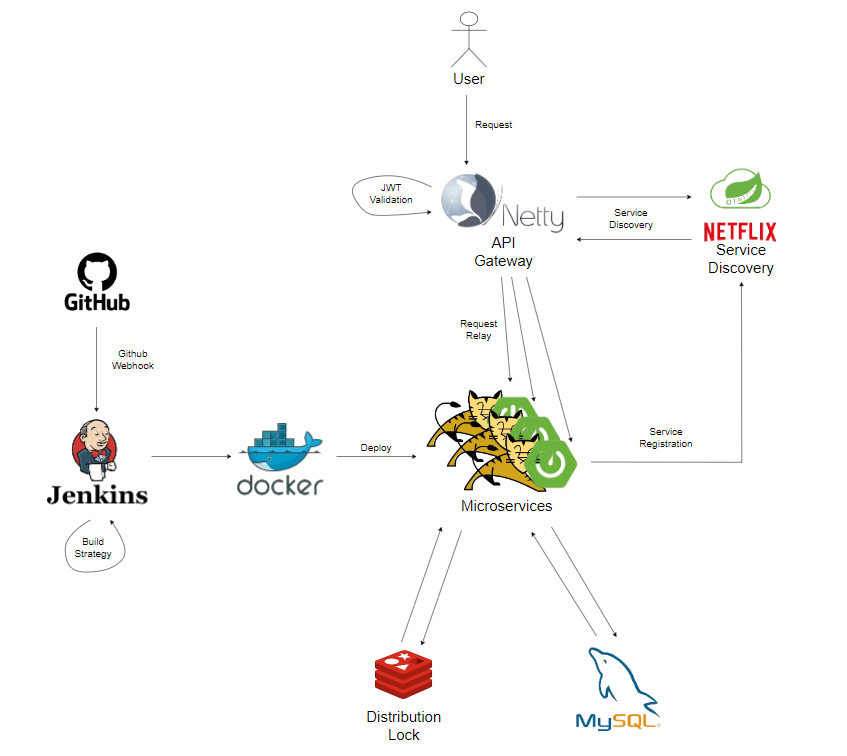
요청이 들어올 시 API Gateway를 통해 요청이 각각의 서비스로 relay 됩니다.
조금 더 현재 상황에 맞춰볼까요?

group-service 는 결제를 요청하기 위해 payment-service 가 제공하는 HTTP API로 요청을 보냅니다. 이후, API Gateway를 통해 요청이 전달되고, 결제 성공 여부에 따라 gruop-service 에서 추가적인 로직이 수행되겠죠.
다만, 이러한 방식은 몇가지 문제가 존재합니다. 문제점은 아래에서 조금 더 자세히 적어볼게요.
2. 중간에 무언가 존재하는 방식

통신을 담당하는 미들웨어가 존재하는 방식입니다. 이 미들웨어엔 주로 메시지 브로커인 RabbitMQ나 이벤트 스트리밍 플랫폼 Kafka를 주로 사용합니다.
선택
전 위 방법들 중 미들웨어가 존재하는 방식, 그 중 Kafka를 사용한 방식을 채택했습니다.
1. 동기적 방식의 문제
직접 통신 방식에서 발생하는 문제입니다. Spring mvc 의존성의 기본 WAS인 Apache Tomcat은 하나의 요청을 하나의 스레드가 처리하는 Request per Thread 모델입니다. 즉, 동시에 처리될 수 있는 요청 수가 Thread-pool 개수로 정해지죠.
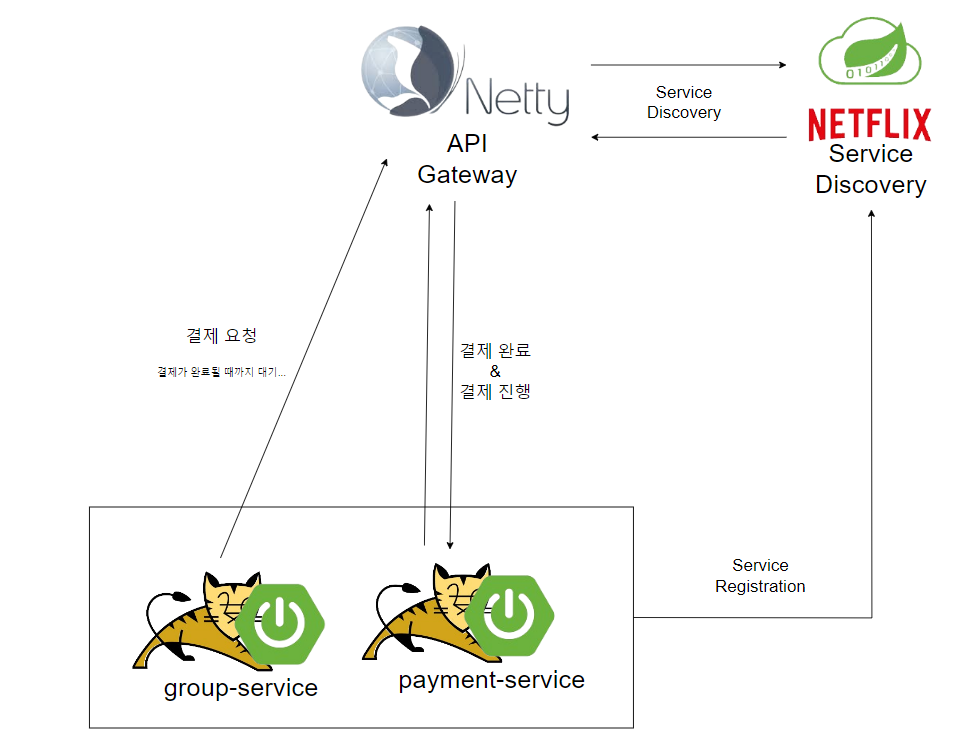
직접 통신의 경우 group-service 의 요청은 결제 서비스의 모든 동작이 끝날때까지 기다립니다. payment-service 에서 1초, 2초, 10초가 걸리면 그 시간동안 group-service 의 스레드가 대기해야하므로 서버의 성능이 그만큼 저하될 거예요.
2. Kafka를 선택한 이유
전통적인 메세지 브로커, RabbitMQ와 같은 미들웨어도 존재하지만 Kafka를 선택한 이유는 다음과 같아요.
1) pub / sub 모델
Kafka는 메시지 브로커가 아닌 Event-Streaming-Platform 이라는 정체성을 갖고 있습니다. 이는 일반적인 메시지 브로커와는 다른 몇가지 특징이 있기 때문인데, 그 중 한가지는 발행 / 구독 모델을 사용한다는 거예요.
Kafka는 크게 3가지로 구성되어 있습니다.
이벤트를 보관하는 토픽, 토픽에 이벤트를 발행하는 Producer, 토픽에서 데이터를 가져가는 Consumer로 구성됩니다.
Kafka의 이벤트는 메시지 브로커와는 달리 영속합니다. 특정 토픽을 구독하는 Consumer A가 존재한다고 가정해볼게요. 메시지 브로커의 경우 소비한 메세지는 사라지지만, Kafka는 그렇지 않습니다.
동일한 토픽을 구독하는 Consumer B가 토픽에 존재하는 모든 이벤트를 동일하게 수신할 수 있습니다.
컨슈머 그룹이 달라야겠지만요!
이런 특성 덕분에 높은 확장성을 가진다고 느껴졌습니다.
현재 모두의 음악 프로젝트엔 별도의 로깅 시스템이 존재하지 않습니다. 이를 추후 구현할 개발 과제로 남겨두고 있는 상황이예요.
Kafka를 사용하게 될 시, 이후 추가될 로깅 시스템 연동이 굉장히 편할 것 같았으며, 로깅 시스템이 개발되기 전에 발생한 이벤트 또한 영속시키기에 임시 이벤트 저장소로 사용할 수도 있을 것 같았어요.
2) 분산 시스템
Kafka는 분산 시스템에서 동작하는 것을 목적으로 제작되었습니다.
클러스터링, 레플리케이션을 직접 지원하므로 브로커(카프카 서버)가 다운되어도 데이터 유실을 방지할 수 있죠. 이는 또한 대용량 데이터 처리라는 장점으로도 다가와요.
서비스가 마이크로서비스 아키텍처를 지향하고 있기 때문에, 확장에 용이한 Kafka가 프로젝트에 더 적합할 것 같았습니다.
마치며
한 포스트에 전부 적을 생각이였지만 구현하며 한 고민들이 많기에 두개의 포스트로 나눠 적기로 결정했습니다..!
다음 포스트엔 구현과 구현하며 한 고민들에 대해 적어보겠습니다!!
참고 자료
도서 - 아파치 카프카 애플리케이션 프로그래밍 with 자바
[서버] 메세지 큐(Message Queue) 을 알아보자
