1. 기술 선정 배경
본 프로젝트는 여러 언론사의 RSS 데이터를 수집하고, 기사 단위로 스크래핑 및 분석을 수행하여 실시간 트렌드 키워드를 산출하는 시스템입니다. 뉴스 수집량이 증가함에 따라 비동기 처리와 시스템 안정성을 확보하기 위해 메시지 큐(MQ) 도입이 필수가 되었고 , 그 과정에서 아래 두 가지 기술을 최종 후보로 선정했습니다.
- Kafka: 대규모 실시간 스트리밍 처리의 업계 표준
- BullMQ: Redis 기반 Job Queue로, Node.js/NestJS 환경에 최적화된 도구
본 글에서는 두 기술의 단순 기능 나열이 아닌, 실제 서비스 요구사항 관점에서의 의사결정 과정을 기록합니다.
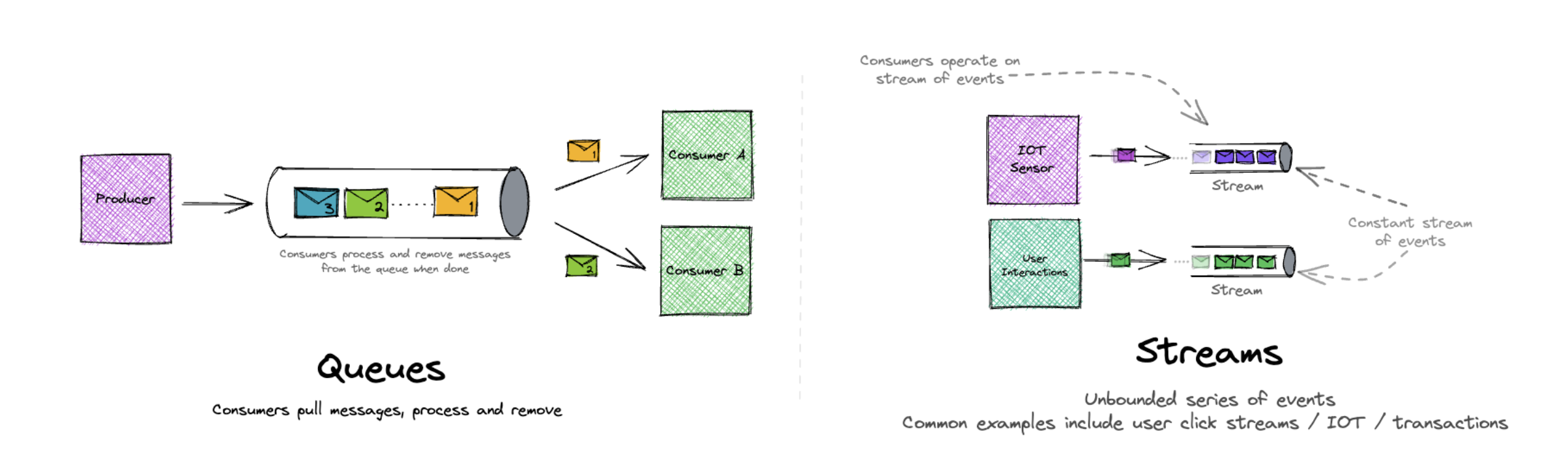
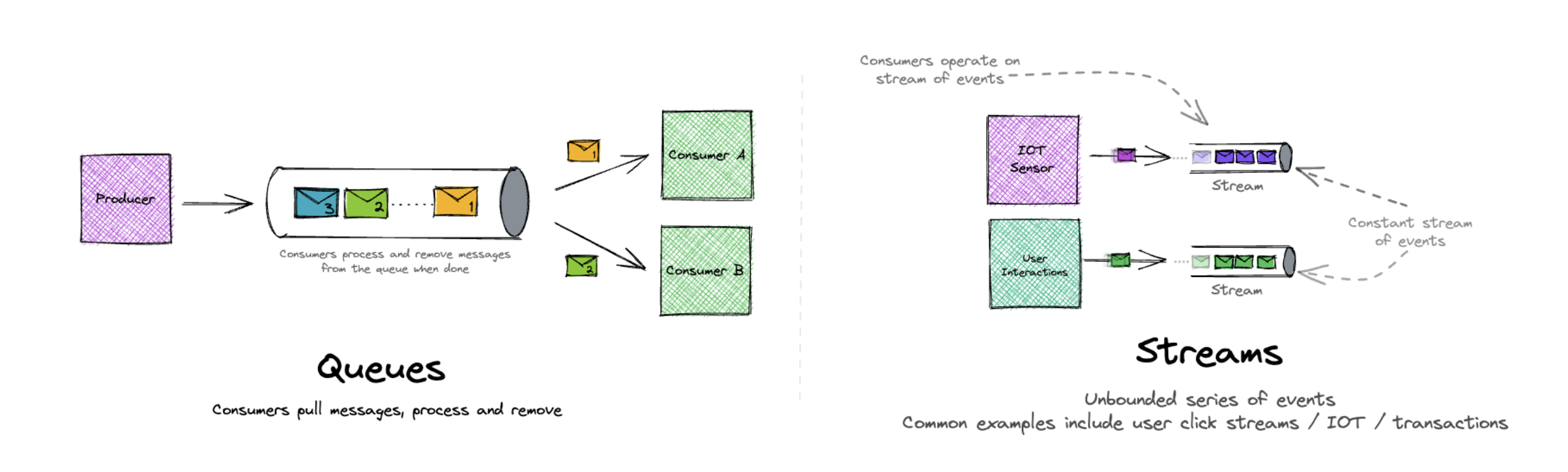
2. 핵심 판단 기준: “메시지”가 아니라 “작업(Job)”
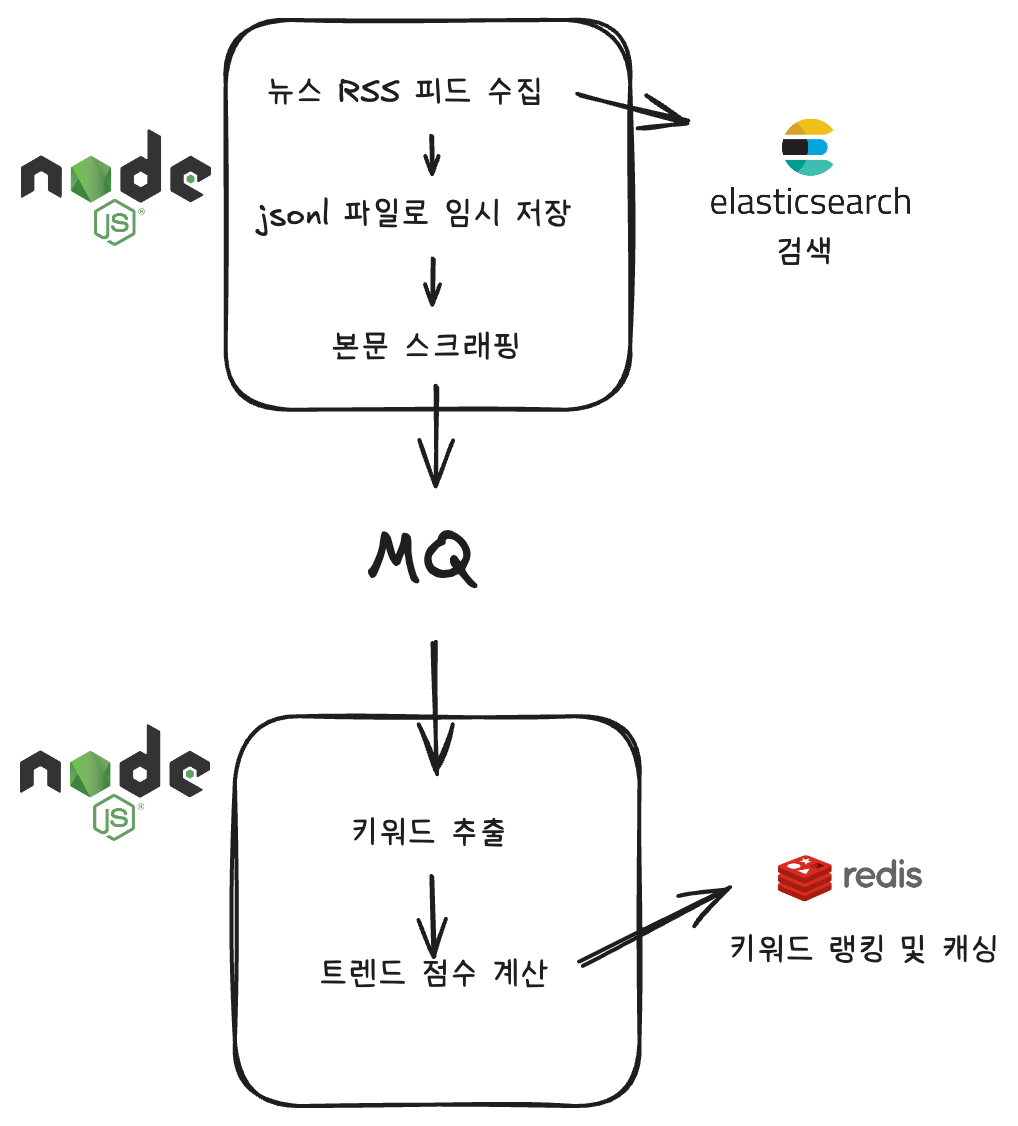 (기사 1건을 하나의 Job으로 처리하는 뉴스 분석 파이프라인
(기사 1건을 하나의 Job으로 처리하는 뉴스 분석 파이프라인
RSS 수집부터 트렌드 점수 계산까지를 단일 작업 단위로 분리하여,실패·재시도·지연을 개별 Job 단위로 제어한다.)
이 프로젝트에서 MQ가 처리해야 할 대상은 단순한 데이터 전달이 아니라 명확한 작업 단위(Job)였습니다. 기사 1건당 처리 흐름은 다음과 같습니다.
기사 1건 = RSS 수집 → 본문 스크래핑 → Elasticsearch 인덱싱 → 트렌드 점수 계산
따라서 선정될 MQ는 반드시 다음 요건을 충족해야 했습니다.
- 기사(Job) 단위의 세밀한 실패 감지
- 개별 작업의 재시도(Retry) 및 지연(Delay) 제어
- 전체 파이프라인 중단 없는 부분 복구 가능성
3. Kafka 검토 결과
3.1 작업 단위 제어의 한계
Kafka는 스트리밍 로그 처리에 최적화된 구조를 가집니다.
- 구조적 특성: Offset 기반의 메시지 소비 방식이며, 재처리는 Consumer Group 단위로 수행됩니다.
- 제어의 복잡성: 특정 언론사 RSS 장애나 일부 기사 스크래핑 실패와 같은 상황에서 문제 발생 기사만 선택적으로 재처리하기에는 개별 Job 단위 제어 모델이 부족했습니다.
3.2 단일 인스턴스 환경에서의 운영 부담
본 프로젝트는 AWS EC2 단일 인스턴스에서 Docker Compose 기반으로 배포되는 환경입니다.
- 오버헤드: Kafka는 JVM 기반 브로커와 Zookeeper(또는 KRaft) 운영이 필수적이며, 메모리 점유율 및 운영 오버헤드가 큽니다.
- 효율성: 소규모 환경에서 Kafka를 운영하는 것은 성능 대비 관리 복잡도가 과도하다고 판단했습니다.
3.3 처리 모델의 불일치
Kafka는 끊임없이 흘러오는 이벤트 스트림과 높은 처리량(Throughput)에 강점이 있습니다. 하지만 뉴스 수집은 주기적으로 발생하는 대량 작업 큐(Task Queue) 성격이 강했기에, Kafka를 선택하는 것이 기술적으로 가능했지만, 운영과 구현 복잡도를 감수할 이유는 없다는 판단이었습니다.
즉, Kafka로도 구현은 가능했지만
기사 단위 제어를 애플리케이션 레벨에서 직접 구현해야 했고, 이것이 MQ 도입의 목적과 어긋난다고 판단했습니다.
4. BullMQ를 선택한 이유
4.1 Job 중심 처리 모델 (Best-fit)
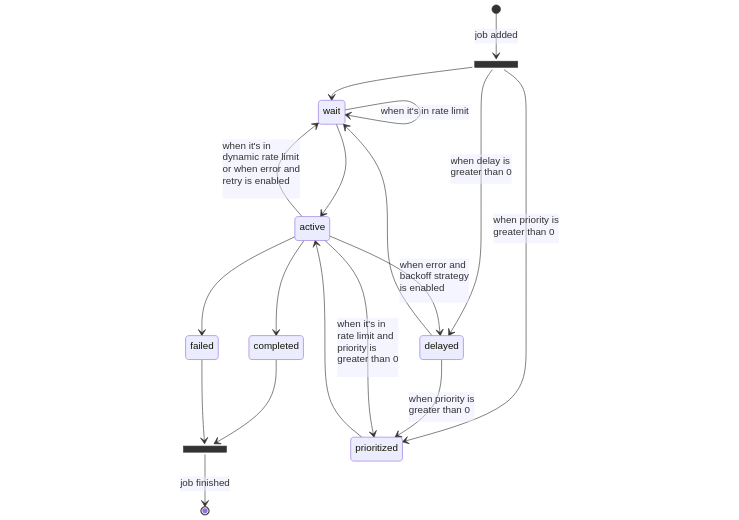
BullMQ는 기사 단위의 Job 생성과 개별 Retry/Delay 처리를 완벽히 지원합니다.
- 장애 격리: 특정 언론사에서 장애가 발생하더라도 해당 기사 Job만 재시도 설정에 따라 처리되며, 전체 뉴스 수집 및 트렌드 계산 파이프라인은 정상적으로 유지됩니다.
4.2 상태 가시성과 운영 편의성
Redis를 기반으로 Waiting, Active, Completed, Failed 등 작업 상태를 명확히 추적할 수 있습니다. 4,000건 이상의 기사가 몰리는 상황에서도 시스템 상태를 직관적으로 파악할 수 있어 디버깅 및 운영 난이도가 크게 낮아졌습니다.
4.3 인프라 효율성 극대화
이미 프로젝트에서는 실시간 트렌드 랭킹 조회를 위해 Redis를 도입한 상태였습니다.
- 비용 절감: 별도의 브로커 설치 없이 기존 Redis를 공용하여 추가 인프라 비용이 발생하지 않았습니다.
- 최적화: 단일 인스턴스 환경에서 리소스 효율을 극대화할 수 있는 합리적인 선택이었습니다.
5. 최종 결론
Kafka는 분명 강력한 기술이지만, 모든 문제의 정답은 아닙니다. 본 프로젝트에서는 스트리밍 처리보다 작업 단위 제어를, 확장성보다 운영의 현실성을 우선시했고, 그 결과 BullMQ가 가장 합리적인 선택이었습니다.
물론 향후 수집 대상이 수십만 건 규모로 증가하고, 다수의 소비자가 동일 스트림을 공유해야 하는 시점이 온다면 Kafka를 재검토할 수도 있습니다. 하지만 현재 서비스 규모와 요구사항에서는 BullMQ가 가장 현실적인 선택이라고 생각합니다.
기술 선정은 단순히 유명한 기술을 고르는 것이 아니라, 현재 직면한 문제를 해결하는 가장 적합한 도구를 찾는 과정임을 이번 프로젝트를 통해 다시 한번 확신할 수 있었습니다.
