GDSC
GDSC 미니 스터디 자바잡아 심화반을 위한 자료에요.
목차
- Generics
- Collection
- Lambda
- Optional
- Stream
- Annotation
- JSON
Generics
제네릭은 아래와 같이 일반적인 이라는 뜻을 가지고 있어요.
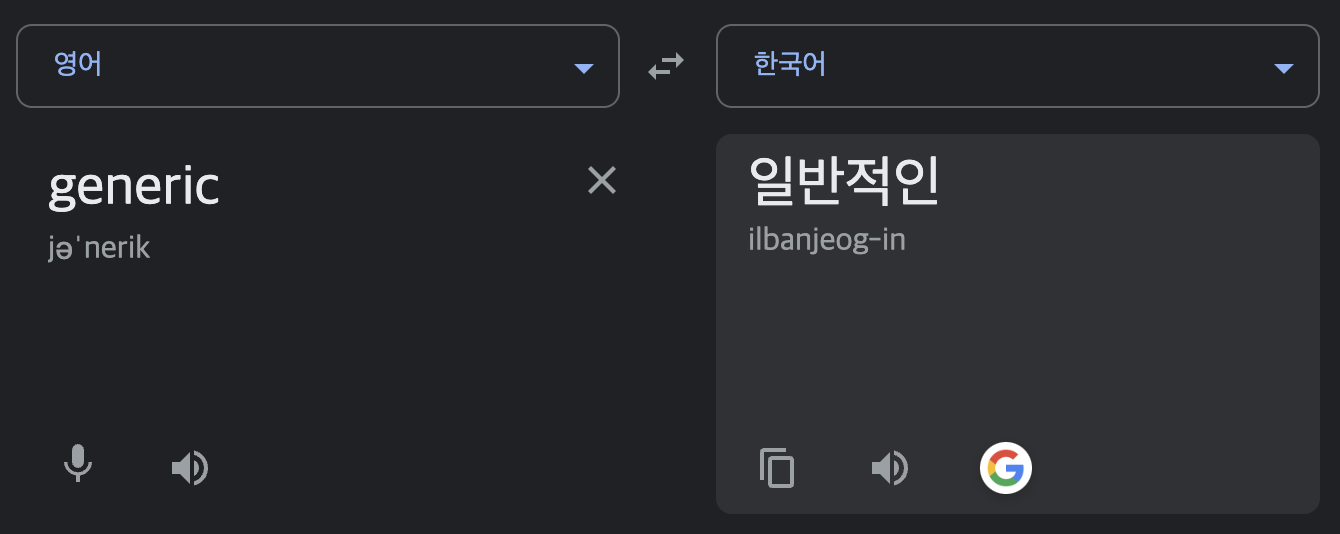
자바에서 제네릭이란 데이터의 타입을 일반화한다. 라고 말할 수 있어요. 더 자세히 설명하면, 제네릭은 클래스 내부에서 지정하는 것이 아닌 외부에서 사용자에 의해 지정되는 것을 말해요.
제네릭을 사용하면, 클래스나 메소드에서 작업할 데이터의 타입을 외부에서 사용자가 직접 지정할 수 있어요. 이렇게 하면 컴파일 시에 타입 체크를 수행하여 안정성을 높일 수 있고, 잘못된 타입 사용에 따른 런타임 오류를 방지할 수 있어요.
JDK 1.5부터 도입된 제네릭을 사용하면 컴파일 시에 미리 타입이 정해지므로, 타입 체크나 타입 변환과 같은 번거로운 작업을 생략할 수 있게 돼요.
즉, 어떤 클래스가 자료형에 전혀 영향을 받지 않고 같은 기능을 제공하며, 일종의 다형성이라고 할 수 있어요.
아마 Java를 어느 정도 사용해봤다면, 제네릭을 이미 한 번씩은 사용해봤을 거에요.
List<String> list = new ArrayList<>();
Map<Long, String> map = new HashMap<>();이처럼 <> 안에 들어가는 타입을 지정했을 거에요.
만약 list에 Integer(정수형 Wrapper 클래스)를 담고 싶다면 아래와 같이 <> 부분만 수정하면 돼요.
List<Integer> list = new ArrayList<>();이렇게 할 수 있는 이유를 찾아볼게요.
public interface List<E> extends Collection<E> {
...
}List 인터페이스는 이렇게 작성되어 있어요.
보면 인터페이스 이름 옆에 <E> 라고 작성되어 있는 것을 볼 수 있어요.
여기서 E는 Element를 뜻하며, List 객체에 담길 원소 타입을 지정해서 사용하라는 뜻이에요.
이렇게 타입을 나타내는 것들을 타입 파라미터 라고 해요.
즉, List<Integer> 는 원소 타입이 Integer 객체인 List 객체를 만들겠다는 뜻이에요.
이외에도 여러 타입 파라미터가 존재해요.
| 타입 | 설명 |
|---|---|
<T> | Type |
<E> | Element |
<K> | Key |
<V> | Value |
<N> | Number |
제네릭 실습
클래스나 인터페이스 이름 옆에 <> 를 붙이고 타입 파라미터를 지정하면 제네릭을 사용하여 클래스나 인터페이스를 만들 수 있어요.
public class ClassName <T> { ... }
public interface InterfaceName <T> { ... }나만의 제네릭 클래스를 만드는 실습을 해볼게요.
public class MyBox<T> {
private T item;
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}클래스 내부 코드는 동일한 타입을 사용하여 setItem(T item) 메소드 처럼 작성하면 돼요.
public class MyBoxTest {
public static void main(String[] args) {
// 문자열 객체를 담는 제네릭 클래스 객체 myBox를 만들고 "선물" 문자열을 저장해요.
MyBox<String> myBox = new MyBox<>();
myBox.setItem("선물");
// 출력해요.
System.out.println(myBox.getItem());
}
}우리가 만든 MyBox 제네릭 클래스의 인스턴스를 생성하는 방법은 매우 간단해요. MyBox<String> 과 같은 형태로 타입 파라미터를 지정하면, 해당 MyBox 인스턴스는 String 타입의 값을 저장할 수 있게 돼요.
위의 예제에서, 우리는 "선물"이라는 문자열을 myBox에 저장하고 getItem() 메소드를 호출하여 저장한 값을 출력했어요.
제네릭을 사용함으로써 우리는 특정 타입의 데이터만 처리하는 코드를 작성할 수 있게 되었고, 컴파일러가 이러한 타입 제약사항을 체크해주므로 런타임 오류 발생 가능성도 줄일 수 있게 되었어요.
참고로 자바 SE 7버전부터는 제네릭 클래스의 생성자를 호출할 때, 타입 인수를 구체적으로 작성하지 않아도 돼요. 그 이유는 컴파일러가 문맥에서 타입을 추측하기 때문이에요. “<>”를 다이아몬드라고 표현한다.
이전 버전에서는 직접 타입 인수를 작성해줘야 해요.
지금까지는 일반적인 예시였어요. 방금 실습처럼 MyBox 타입 파라미터에 String을 넣으면 T는 String이 돼요. 하지만 사용할 수 있는 타입을 특정 범위로 좁히고 싶다면 어떻게 할까요?
이 때 필요한 것이 바로 extends, super, ?(물음표)에요. ? 는 와일드 카드라고 해서 쉽게 말해 '알 수 없는 타입'이라는 의미에요.
<K extends T> // T와 T의 자손 타입만 가능해요 (K는 들어오는 타입으로 지정 돼요.)
<K super T> // T와 T의 부모(조상) 타입만 가능해요. (K는 들어오는 타입으로 지정 돼요.)
<? extends T> // T와 T의 자손 타입만 가능해요.
<? super T> // T와 T의 부모(조상) 타입만 가능해요.
<?> // 어떠한 타입도 허용하며, <? extends Object>`와 같은 의미에요.쉽게 요약해보면 다음과 같아요.
extends T : Upper Bound, 지정한 클래스(T)와 그 자손들만 가능하게 해요.
? super T : Lower Bound, 지정한 클래스(T) 및 그 조상들을 포함하는 객체를 소비(consume)하는 경우에 사용돼요.이번 시간에는 간단하게 제네릭이 무엇이고 어떠한 방식으로 만들고 사용되는지 알아봤어요.
제네릭 자세한 내용 해당 블로그에 잘 정리되어 있으니 확인하면 많은 도움이 될거에요.
Collection
먼저 Collection이 무엇인지 공식 문서를 읽어봐요.
A collection represents a group of objects, known as its elements
쉽게 말해 객체의 모음이라고 볼 수 있어요.
자바에서 모든 컬렉션 클래스와 인터페이스를 포함하는 Collection Framework 라는 개념이 JDK 1.2에서 정의가 되었어요.
Collection 인터페이스를 사용하는 이유는 다음과 같아요.
-
성공적인 추상화 구현: Collection의 일관된 API를 사용하여 Collection 밑에 있는 모든 클래스(ArrayList, Vector, LinkedList 등) Collection에서 상속받아 통일된 메서드를 사용하게 돼요. -
골라먹기: 자료구조, 알고리즘을 구현하기 위한 코드를 직접 작성하지 않고, 이미 구현된 Collection 클래스를 목적에 맞게 선택하여 사용하면 돼요. Collection 인터페이스는 List, Set 및 Queue와 같은 하위 인터페이스를 확장하는데, 예를 들어 List는 순서가 있는 데이터를 저장하고, Set은 중복을 허용하지 않는 데이터를 저장해요. 이러한 다양한 인터페이스는 다양한 요구 사항에 맞게 선택하여 사용할 수 있어요. -
강력함: 이미 수많은 사용으로 검증되었으며, 고도로 최적화되어 있어요.
구조
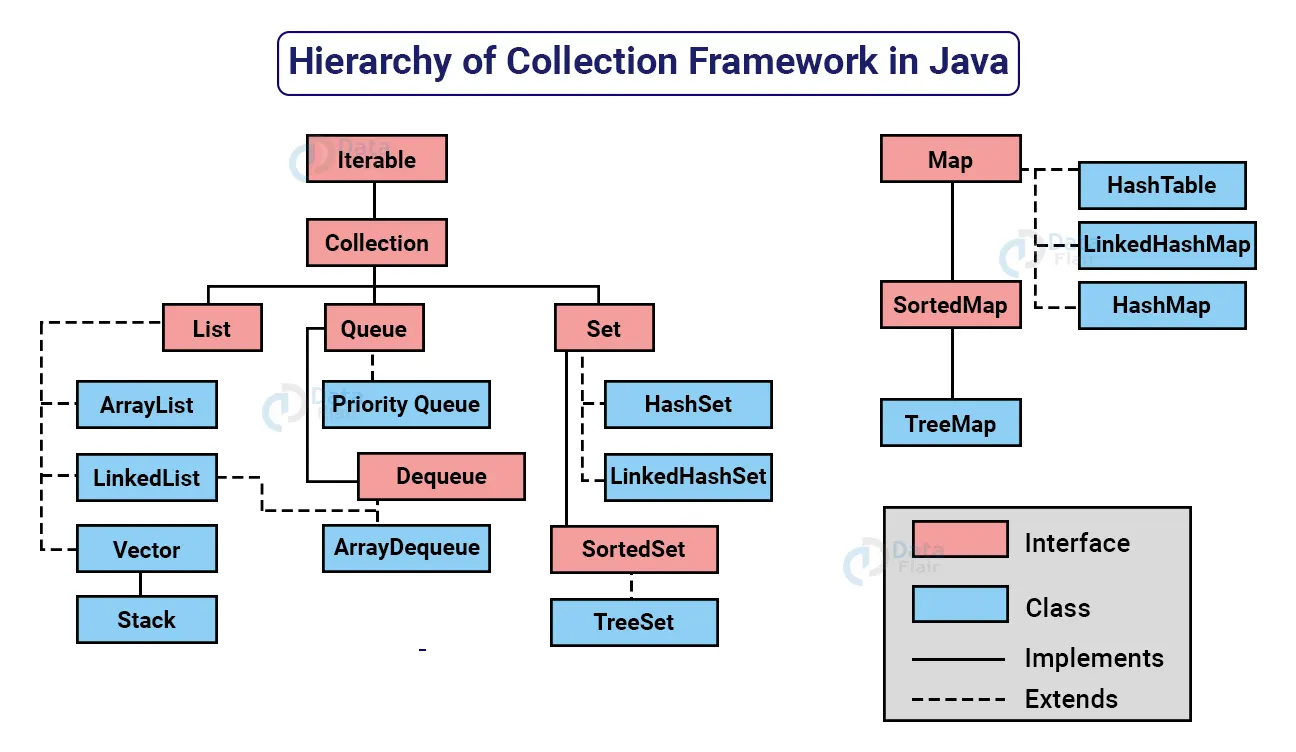
Collection은 대표적인 인터페이스를 알아볼게요.
List: 목록에서 각 요소가 삽입되는 위치를 정확하게 제어할 수 있는 순서가 지정된 컬렉션이에요. (시퀀스라고도 해요.)Queue: 대기열이라는 이름 답게 선입선출 개념을 기본적으로 사용하는 컬렉션이에요. 순서가 중요한 업무에서 주로 사용해요.Set: 이름에서 유추할 수 있듯이 수학적 집합 추상화를 모델링하며, 중복된 값을 저장할 수 없는 컬렉션이에요. 고유한 데이터만 저장해야하는 경우 사용돼요.Map: 데이터를 Key-Value 형태로 매핑하는 데이터 구조에요. 맵에는 중복 키가 포함될 수 없으며, 각 키는 최대 하나의 값에 매핑될 수 있어요.
컬렉션 실습
문제 1
괄호 "(" 와 ")" 로만 이루어진 문자열을 입력한다. 예시 -> "(())", "())(", ")(()" 등
이때 괄호의 모양이 바르게 구성된 문자열을 입력받은 경우 "YES" 출력, 아닌 경우 "NO" 출력하는 프로그램을 만드시오.
입력 예시 1 출력 예시 1
(()()) YES
입력 예시 2 출력 예시 2
((())) YES
입력 예시 3 출력 예시 3
(()()(() NOpublic class StackProblem {
public static void main(String[] args) {
...
}
}Stack 관련 문제에요. 위 코드를 가져가서 완성해보세요.
문제 2
가지고 있는 과일의 개수를 먼저 입력 받는다.
입력 받은 과일의 개수만큼 과일을 입력 받는다.
모두 입력 받았다면, 각 과일이 몇 개씩 있는지 출력한다.
출력 순서는 상관없다.
입력 예시 1 출력 예시 1
3 사과: 2
사과 포도: 1
사과
포도
입력 예시 2 출력 예시 2
4 감귤: 1
감귤 키위: 2
키위 포도: 1
키위
포도public class MapProblem {
public static void main(String[] args) {
...
}
}Map 관련 문제에요. 아래의 코드를 가져가서 완성해보세요.
Lambda
람다, 정확히는 람다식(Lambda Expression), 함수를 하나의 식으로 나타낸 것이에요.
식으로 나타내는 것이기 때문에 따로 이름이 필요 없는 익명 함수(Anonymous Function)이며, 변수처럼 사용도 가능해요.
변수처럼 사용 가능하니 당연히 매개 변수로 전달도 가능해요.
람다식의 기본 형태는 다음과 같아요. ( 매개 변수 ) -> { 함수 식; }
(int a) -> { System.out.println(a); }
// 각각 하나씩인 것이 보장되면 괄호 제거가 가능해요.
a -> System.out.println(a);이런 람다식을 사용하기 위해서는 함수형 인터페이스를 사용해야 해요.
@FunctionalInterface 어노테이션을 인터페이스 위에 적어주면, 해당 인터페이스는 멤버로 함수 하나만을 가질 수 있도록 강제해요.
public class FuncInterfaceLambda {
public static void main(String[] args) {
// 함수형 인터페이스를 구현
// accept 메소드를 람다식으로 정의
MyConsumer consumer = (int a) -> System.out.println(a);
// 구현한 메소드 사용
consumer.accept(1);
}
}
// 함수형 인터페이스
// 정수 타입을 매개변수로 받아 아무 결과도 반환하지 않는 accept 메소드가 선언되어 있음
@FunctionalInterface
interface MyConsumer {
void accept(int a);
}코드를 보면 함수형 인터페이스 MyConsumer의 멤버 메소드인 accept를 람다식으로 아주 간단하게 오버라이딩 했어요.
추가로 더욱 간단하게 아래와 같이 작성해도 돼요.
MyConsumer consumer = (int a) -> System.out.println(a);
// 위 아래 같은 람다식이에요.
MyConsumer consumer = System.out::println;:: 는 메소드 레퍼런스라고 해요.
Java 8때 도입되었고, 람다 표현식을 더욱 간단하게 표현하는 방법이에요.
주의할 점은 (인스턴스의 자료형)::(메소드) 형식으로 작성해야 해요.
Lambda 실습
위에서 배운 Collection 중에서 List 인터페이스의 구현체인 ArrayList를 정렬하는 코드를 작성해볼게요.
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class LambdaTest {
public static void main(String[] args) {
// 리스트에 과일 추가
List<String> list = new ArrayList<>();
list.add("pear");
list.add("apple");
list.add("banana");
list.add("melon");
list.add("orange");
// 리스트 정렬
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
for (String fruit : list) {
System.out.println(fruit);
}
}
}
// 결과
apple
banana
melon
orange
pear결과는 잘 출력되지만, 어딘가 복잡해보이고 한 번에 이해하기 쉽지 않은 코드에요.
이 코드를 람다식을 활용하여 간단하게 만들게요.
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class LambdaTest {
public static void main(String[] args) {
// 리스트에 과일 추가
List<String> list = new ArrayList<>();
list.add("pear");
list.add("apple");
list.add("banana");
list.add("melon");
list.add("orange");
// 리스트 정렬
Collections.sort(list, (o1, o2) -> o1.compareTo(o2));
for (String fruit : list) {
System.out.println(fruit);
}
}
}확실히 코드를 이해하기 쉬워졌어요. 하지만 앞에서 사용한 :: 메소드 레퍼런스를 사용하고
Collections 클래스의 정적 메소드 대신에 List 인터페이스에 정의된 sort 메소드를 사용하면 더욱 코드가 짧아져요.
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class LambdaTest {
public static void main(String[] args) {
// 리스트에 과일 추가
List<String> list = new ArrayList<>();
list.add("pear");
list.add("apple");
list.add("banana");
list.add("melon");
list.add("orange");
// 리스트 정렬
list.sort(String::compareTo);
for (String fruit : list) {
System.out.println(fruit);
}
}
}Optional
Oracle docs - Optional
Optional은 Java 8 버전에서 등장한 NullPointerException을 더 효과적으로 처리할 수 있는 클래스에요.
null값 포함이 가능한 것을 감싸는 Wrapper 클래스로, 참조하더라도 NPE가 발생하지 않도록 도와줘요.
설명보다는 직접 코드를 작성해봐야 이해하기 좋을 것 같아요.
Optional 실습
import java.util.Optional;
public class OptionalTest {
public static void main(String[] args) {
String realString = "abc";
String nullString = null;
Optional<String> realOptional = Optional.of(realString);
// Optional<String> nullOptional = Optional.of(nullString); // NullPointerException 발생
}
}Optional.of() 메소드는 null이 아닌 객체를 담고 있는 Optional 객체를 반환해요.
만약 of 메소드를 사용할 때 인자로 전달되는 값이 null이라면, NullPointerException이 발생해요.
import java.util.Optional;
public class OptionalTest {
public static void main(String[] args) {
String realString = "abc";
String nullString = null;
Optional<String> realOptional2 = Optional.ofNullable(realString);
Optional<String> nullOptional2 = Optional.ofNullable(nullString);
}
}Optional.ofNullable() 메소드는 null일 수도 있는 객체를 담고 있는 Optional 객체를 반환해요.
값이 null이 아니라면, 해당 값을 가지는 Optional 객체를 반환해요.
null이라면, 비어있는(empty) Optional 객체를 반환해요.
import java.util.Optional;
public class OptionalTest {
public static void main(String[] args) {
String nullString = null;
Optional<String> nullOptional = Optional.ofNullable(nullString);
if (nullOptional.isPresent()) {
System.out.println(nullOptional.get());
} else {
System.out.println("null");
}
}
}어떤 결과가 나올 것 같나요?
isPresent 메소드를 통해 nullOptional이 존재하는지 확인하고 존재한다면, nullOptional에서 값을 꺼내 출력하고 null이라면, "null"을 출력하게 돼요. 즉, 결과는 "null"을 출력해요.
지금은 null로 넣어두고 실습했기 때문에 이점이 크게 체감되지 않을 수 있어요. 아래의 코드를 보고 이점을 알아봐요.
public class OrderService {
... // orderRepository는 데이터베이스와 상호작용하는 객체에요.
// 주문 정보를 가져오는 메소드에요.
public Optional<Order> getOrderById(String orderId) {
// 주문 번호를 사용하여 주문 정보를 조회해요.
Order order = orderRepository.findById(orderId);
return Optional.ofNullable(order);
}
// 주문 상세 내역을 업데이트하는 메소드에요.
public boolean updateOrderDetails(String orderId, OrderDetails newDetails) {
Optional<Order> optionalOrder = getOrderById(orderId);
if (optionalOrder.isPresent()) {
Order order = optionalOrder.get();
order.setOrderDetails(newDetails);
orderRepository.save(order);
return true;
}
return false;
}
...
}getOrderById메소드는findById를 통해 주문 정보를 가져오고, 해당 주문이 존재하면 Optional로 감싸서 반환해요. 이렇게 함으로써 주문 정보의 존재 여부를 명시적으로 나타낼 수 있어요.updateOrderDetails메소드는getOrderById를 사용하여 주문 정보를 가져오고, 그 다음에 주문 정보가 존재할 경우에만 주문 상세 내역을 업데이트하고 저장해요. 이를 통해 주문 정보가 null인 경우에 대한 예외(NPE)를 방지하면서 안전하게 업데이트할 수 있게 돼요.
얻을 수 있는 이점을 정리해볼게요.
- 값이 없는 경우에 빈 Optional을 반환하므로 더 이상 null 체크를 수동으로 하지 않아도 돼요.
- 코드에서 값이 없는 상황을 더 명확하게 표현하고, 다른 개발자들에게도 해당 상황을 알리는 데 도움을 줄 수 있어요.
- orElse, orElseGet, orElseThrow 등의 메소드를 사용하여 값이 없을 때 기본 값을 제공하거나 예외를 던질 수 있습니다.
Stream
Java 8 버전에서 등장한 Stream은 데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소라고 할 수 있어요.
Stream을 이용하면 선언형으로 컬렉션 데이터를 처리할 수 있어요.
파이프라이닝: 여러 개의 스트림 연산을 연결하여 데이터 처리 파이프라인을 만들 수 있어요. 이를 통해 중간 연산과 최종 연산을 조합하여 복잡한 작업을 수행할 수 있어요.지연 연산: 스트림 연산은 요청할 때만 실제로 수행되므로, 불필요한 연산을 피하고 효율적으로 처리할 수 있어요.병렬 처리: 스트림은 병렬로 처리할 수 있는 기능을 제공하여 멀티코어 CPU를 활용하여 성능을 향상시킬 수 있어요.
Stream을 사용하는 방법은 크게 3가지로 나뉘어요. 생성 - 가공 - 소비
스트림 생성
기능을 사용한 데이터 소스를 Stream으로 만드는 과정이에요.
// ArrayList 객체를 스트림으로 만들었어요.
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();stream(): 데이터 소스를 스트림으로 만드는 메소드에요. 여기서 데이터 소스는 컬렉션 객체, 배열, 파일 등을 말해요.
스트림 가공 (중간 연산)
스트름 객체에서 데이터를 뽑아서 특정 작업을 하거나, 특정 기준에 따라 필터링 하는 것처럼 가공할 수 있어요.
가공 단계에 해당하는 메소드들은 가공된 결과를 스트림으로 반환해요.
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream()
.filter(s -> s.contains("a"));filter():Predicate<T>를 파라미터로 받아서 Predicate가 true인 모든 요소를 포함하는 스트림을 반환하는 메소드에요.Predicate<T>는 T에대한 조건에 대해서 true / false를 반환하는 Functional Interface에요. (쉽게 설명하면 조건에 충족하는 요소만 통과할 수 있는 필터 역할!)
즉, 위에서 사용해본 람다식을 사용할 수 있어요.
문자열_스트림.filter(s -> s.contains("a"))는 문자열 스트림에서 "a"가 포함된 문자열 요소를 가진 스트림을 반환해요.
이외에도 많은 중간 연산이 존재하지만, 모두 설명하기에는 무리가 있어서 예시를 보고 설명하면서 넘어가려고 해요.
// map()은 스트림 내에 존재하는 요소를 특정 형태로 변환해요. 람다를 사용할 수 있어요.
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream()
.map(String::toUpperCase); // 요소를 대문자로 변환
// distinct()는 스트림 내에 존재하는 요소의 중복을 제거해요.
List<String> list = Arrays.asList("a", "a", "c");
Stream<String> stream = list.stream()
.distinct() // 중복 제거
.filter(s -> s.contains("a"));
// limit()은 스트림 내에 존재하는 요소 개수를 제한해요.
List<String> list = Arrays.asList("a", "a", "c", "d");
Stream<String> stream = list.stream()
.limit(3) // 여기부터 3개 요소만 연산
.filter(s -> s.contains("a"));
// sorted()는 스트림 내에 존재하는 요소를 정렬해요.
List<String> list = Arrays.asList("b", "a", "c", "d");
// a b c d
Stream<String> stream = list.stream()
.sorted();
// d c b a
Stream<String> stream = list.stream()
.sorted(Comparator.reverseOrder());스트림 소비 (최종 연산)
스트림 API에서 중간 연산을 통해 변환된 스트림은 마지막으로 최종 연산을 통해 각 요소를 소비해요.
즉, 지연(lazy)되었던 모든 중간 연산들이 최종 연산 시에 모두 수행돼요.
이렇게 최종 연산 시에 모든 요소를 소비한 스트림은 재사용할 수 없게 됩니다.
Stream.of("b", "a", "c", "d")
.sorted()
.forEach(System.out::println);forEach(): 모든 요소를 순회해요. 주로 출력을 위해 사용해요.
List<String> list = Stream.of("b", "a", "c", "d")
.sorted()
.collect(Collectors.toList());collect(): 모든 요소를 수집할 때 사용해요. 예시를 보면 스트림 내에 존재하는 모든 요소를 리스트로 수집해서 반환해요.
// count()는 스트림 요소의 개수를 반환해요. 아래의 코드의 결과는 2에요.
int count = Stream.of("tiger", "bird", "dog", "cat")
.filter(s -> s.length == 3)
.count();
// findFirst()는 주어진 조건에 맞는 첫 번째 요소를 Optional에 감싸서 반환해요.
Optional<String> first = Stream.of("dog", "bird", "apple", "cat")
.filter(s -> s.length() == 3)
.findFirst(); // "cat"이 옵셔널 객체에 담겨 반환돼요.이외에도 다양한 최종 연산을 지원하기 때문에 필요에 따라 찾아서 사용하는 것을 추천드려요.
생각해보기
일반적인 for문, if문으로 구성된 문장보다는 스트림 API를 사용하는 것이 가독성, 표현력 부분에서 이점을 가져가요. 추가적으로 지연 연산(lazy evaluation), 병렬 처리 등 장점이 많기 때문에 그러면 항상 스트림으로 사용하면 되는 것 아닌가? 라는 생각이 들 수 있어요.
스트림은 내부적으로 최적화된 알고리즘이 사용되기 때문에 직접 알고리즘을 구현하여 사용하는 방법보다는 컴퓨팅 리소스를 효율적으로 사용할 수 있어요. 하지만 복잡하거나 대량의 데이터를 처리하는 경우에는 스트림 사용으로 인한 오버헤드가 발생하여 성능 저하로 이어질 수 있어요. 또한, 스트림의 파이프라인과 연산들을 학습하고 이해하는 추가 비용이 발생할 수 있어요.
하고 싶은 말은 "그냥 스트림이 더 좋아서 썼어요." 가 아니라
가독성, 편리함 그로 인한 유지보수 비용 절감이나 데이터 크기와 복잡성 등 컴퓨팅 비용, 개발자의 학습 비용, 프로젝트 성격 등을 복합적으로 고려하면서
스트림 사용이 최선의 선택인지 생각하는 시간을 가져야 한다는 것이에요.
Annotation
어노테이션을 정의하는 방법보다는 어노테이션이 어떻게 쓰이고 있는지 보여주려고 해요.
@Getter, @Setter, @Deprecated 등
JSON
JSON(JavaScript Object Notation)은 데이터를 효과적으로 표현하고 전송하기 위한 경량의 데이터 교환 형식이에요. 주로 웹 애플리케이션에서 서버와 클라이언트 간의 데이터 전달에 사용돼요.
JSON은 인간이 읽고 쓰기 쉽고, 기계가 파싱하고 생성하기도 쉬운 형식이에요.
단일 객체(JSON Object)
{
"id": 1,
"name": "홍길동",
"age": 20
}배열(JSON Array)
[
{
"id": 1,
"name": "홍길동",
"age": 20
},
{
"id": 2,
"name": "이순신",
"age": 30
}
]스프링 부트 애플리케이션에서 HTTP API 엔드포인트를 만들 때, 클라이언트가 JSON 형식으로 데이터를 전송하면 해당 JSON 데이터가 자바 객체로 변환되어 처리될 수 있어요. 마찬가지로 서버에서 클라이언트에게 응답할 때도 자바 객체가 JSON 형식으로 변환되어 전송돼요.
실제 스프링 부트를 실행하고 보여주면서 진행하려고 해요.
참고
