
자바로 여러 프로젝트를 진행하면서 byte와 short는 사용한 적이 없는 것 같아요. 왜 그랬는지 생각해봤는데, 많은 레퍼런스에서도 사용한 것을 본 적이 없는 것 같아요. 또한 범위가 작다는 것도 이유가 될 것 같아요.
범위가 작고, 남들이 사용하지 않는다는 것만으로 충분한 이유가 될 수 있지만, 약간의 불편함이 생겨서 왜 사람들은 자바에서 byte와 short를 사용하지 않는지 찾아보기로 했어요.
사용하지 않는 이유가 납득되지 않는다면, 일부분을 크기가 작은 타입으로 바꿔서 메모리를 더욱 효율적으로 사용할 수 있지 않을까요?
byte는 너무 short해요.

-
Java Language Specification에서 볼 수 있는 정수형 타입과 값의 범위에요.
-
byte 타입은 -128부터 127까지 표현할 수 있어요. (1byte, 2⁸)
-
short 타입은 -32768부터 32767까지 표현할 수 있어요. (2byte, 2¹⁶)
저는 대부분의 자바 사용을 스프링 부트 애플리케이션을 만들 때 사용했어요. 즉, 제 눈에 보이는 레퍼런스들도 대부분 스프링과 관련되어 있어요. 배달 서비스를 만든다고 가정할 때 대부분의 필드에서 필요로 하는 값의 범위를 충분히 포괄하지 못할 것 같아요. (테이블의 PK, 가격, 음식점 개수 등)
상위 타입인 int만 사용하더라도 표현할 수 있는 값의 범위가 (상황에 따라 다르겠지만) 충분히 커지기 때문에 굳이 byte와 short를 사용하지 않는 것 같아요.
그냥 작아서?
생각해보면 작은 범위를 가진 타입으로도 충분히 표현할 수 있는 부분이 있을 것 같아요. 예를 들어, 작은 반복문이나 초등학교의 학급 수 필드는 byte 타입으로 선언해도 괜찮지 않을까요?
자바를 처음 배울 때 마주치는 반복문, 특히 일반적인 for문 사용 예제를 보면 대부분 아래와 같이 int 타입을 사용해요.
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
System.out.println("hello world");
}
}
// 결과: 세상에게 다섯 번의 정중한 인사여기서 0부터 4의 값만 들어간다면, 반복문의 i를 byte로 초기화하면 더 작은 메모리를 사용하지 않을까요?
public static void main(String[] args) {
for (byte i = 0; i < 5; i++) {
System.out.println("hi");
}
}
// 결과: 다섯 번의 짧은 인사더 많은 반복이 실행된다면, 메모리 차이가 보이지 않을까? 라는 생각을 해봤지만 byte 타입의 범위는 매우 작기 때문에 사실 차이는 엄청 작을 것 같아요.
Casting
위에서 말한 것처럼 비즈니스적으로 교내 학급 수처럼 적은 범위를 사용하는 경우 byte나 short를 사용해도 되지 않을까? 라는 마음으로 간단하게 테스트를 하던 중에 발견한 문제(?)가 있어요.
public class School {
private String name;
private String address;
private byte classCount;
public School() {
}
public School(String name, String address, byte classCount) {
this.name = name;
this.address = address;
this.classCount = classCount;
}
// getter..
}
public class SchoolTest {
public static void main(String[] args) {
School school = new School("초등학교", "서울특별시", (byte) 5); // 형변환이 필요해요.
}
}자바에서는 byte 타입 리터럴을 직접적으로 표기하는 문법은 없기 때문에 byte 타입 필드의 값을 넣기 위해서 형변환이 필요해요. (long, float의 경우에는 L, F와 같이 리터럴을 직접적으로 표기할 수 있는 문법이 존재해요.)
또한, 아래와 같은 경우처럼 충분히 byte 범위 안에 들어갈 수 있는 값이라도 캐스팅이 필요해요. (여러 학교의 학급 수를 구하는 코드)
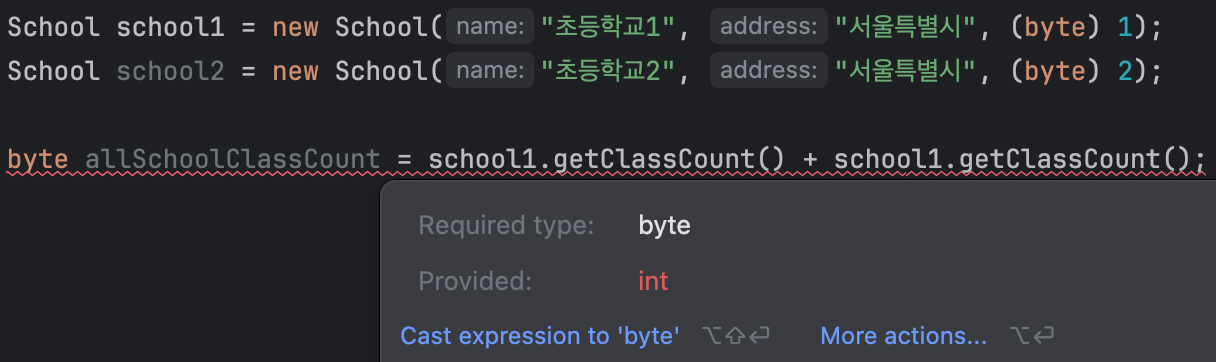
그 이유는 자바에서 + 연산자의 결과 타입이 int이기 때문이에요.
Binary Numeric Promotion

자바의 Binary Numeric Promotion은 이항 연산 시 각 피연산자에 대해 적용되는 규칙으로, 기본 숫자 타입의 변환 방식을 정의해요. 이 규칙은 자바에서 연산을 수행할 때 피연산자의 타입을 어떻게 처리할지 결정해요.
필요한 내용만 요약하면, 자바의 + 연산자를 포함하여 여러 연산자들은 피연산자가 byte, short, char 타입이라면, Widening Primitive Conversion을 통해 int 타입으로 승격시킨다고 해요.
만약 long + int라면 long으로 승격, byte + short는 int로 승격 즉, int보다 아래의 타입들은 기본적으로 int로 승격돼요.
Widening Primitive Conversion(넓이 기본 변환)은 기본 자료형 간의 변환 규칙을 정의하며, 데이터 타입을 더 큰 범위로 변환할 때 어떻게 처리되는지를 설명해요. 이 변환은 데이터의 손실 없이, 또는 최소한의 손실로 이루어지며, 자바에서 타입을 안전하게 변환하는 데 중요한 역할을 수행해요.
(예시: char charValue = 'A'; // 65로 변환돼요.) Widening Primitive Conversion
어 그러면 for문은?
앞서 작성한 코드에요.
public static void main(String[] args) {
for (byte i = 0; i < 5; i++) {
System.out.println("hi");
}
}
// 결과: 다섯 번의 짧은 인사byte 타입의 덧셈 결과는 int인데, 위 코드에서는 byte에 1씩 더하는데 에러가 왜 안날까요?
증감 연산자는 변수의 값을 증가시키고 그 결과를 반환한다고 해요. 즉, byte 타입 변수에 대해 증감 연산자를 사용하면, 결과 타입도 여전히 byte에요. 예를 들어 실행 중에 ++ 연산자가 적용되면, 변수의 값에 1이 더해지고 이 값은 다시 변수에 저장돼요. (값의 타입은 변하지 않아요.)
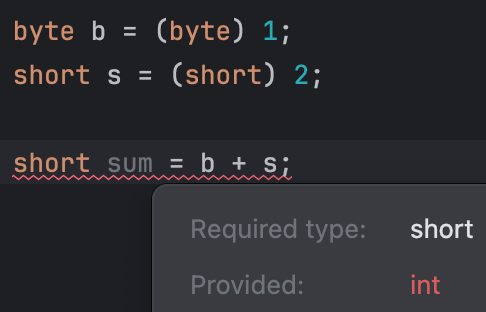

byte 타입과 short 타입의 + 연산 결과는 int로 승격되어 캐스팅 혹은 타입 변환을 요구하지만, 증감 연산자를 사용할 때는 문제가 없는 것을 볼 수 있어요.
귀찮아요
코드를 작성할 때 + 연산은 꽤 많이 사용해요. 필드의 값을 변경하거나 여러 필드의 값을 계산하기도 해요. 이때마다 타입을 바꾸거나 캐스팅을 해야 한다는 것은 너무나도 귀찮은 일이에요. 나의 실수가 아닌데, 고민거리가 하나 늘어난다는 것은 매우 큰 불편함이라고 생각해요.
즉, 자바에서 기본 타입의 이항 연산 결과를 최소 int로 반환하도록 지원하고 있으니, byte와 short의 필요성이 더욱 떨어지는 것 같아요.
메모리 절약
표현 범위도 작고 캐스팅도 불편하지만! 기준(적은 범위가 필요한 필드 등)에 맞는 곳에서 메모리를 절약할 수 있다면, 쓸만하지 않을까요?
JVM의 데이터
값에 대한 기본 크기 단위는Word입니다.Word는 각 JVM 벤더가 선택한 고정 크기입니다.Word크기는 byte, short, int, 등을 보관할 만큼 커야 합니다. 따라서 구현 설계자는 최소 32비트인 단어 크기를 선택해야 하지만 그렇지 않은 경우 가장 효율적인 구현을 제공하는 단어 크기를 선택할 수 있습니다.단어 크기는 종종 호스트 플랫폼의 네이티브 포인터 크기로 선택됩니다. The JVM by Bill Venners
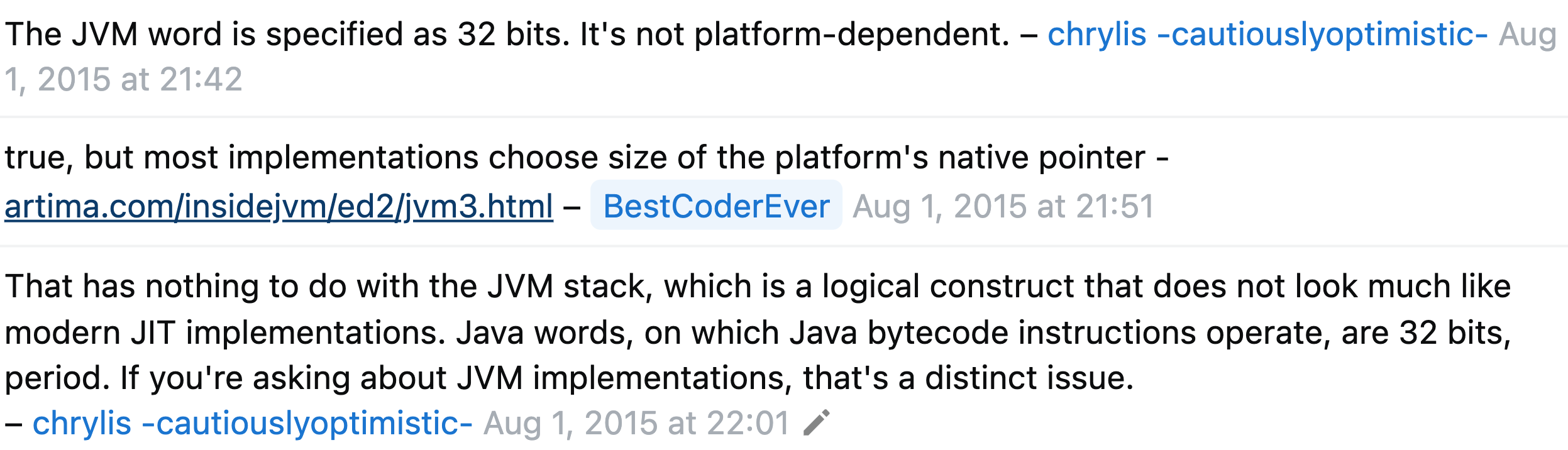
기본 타입 간의 연산은 JVM Operand Stack에 할당돼요. JVM의 스택의 사이즈는 종종 호스트 플랫폼의 네이티브 포인터 크기(32bit, 64bit)를 따라간다는 의견도 있고, 논리적으로 구현되어 항상 32bit라는 의견도 있어요. (공식 문서에서 보고 싶었지만 찾기 힘들었어요..) StackOverFlow
일단 그럼 최소 32bit(4byte)라고 했을 때, 바로 생각나는 점은 byte 타입과 short 타입의 크기에요. 각각 1byte, 2byte의 크기를 가지기 때문에 남은 공간은 낭비가 되지 않을까? 라는 생각과 반대로 여러 연산에서 기본 반환값으로 지정해둔 int의 경우에는 4byte이기 때문에 남는 공간 없이 효율적으로 사용할 수 있나? 라는 생각을 했어요. 즉, 적은 표현 범위를 가진 byte라고 무조건 메모리를 효율적으로 사용하는 것은 아닐 수 있다!
실제로 그렇다고 하더라도 얼마나 차이가 날지 궁금하기도 하네요.
이 부분은 더 공부가 필요한 부분인 것 같아요. 더 정확한 정보를 알고 계신 분은 알려주세요..
메모리 용량은 매우 저렴하기 때문에, 메모리 용량을 절약하기 보다는 개발 속도나 효율에 초점을 맞추는 것이 더욱 효과적이라고 말씀하신 분도 봤어요.
마무리
- 현대의 많은 서버 애플리케이션에서 사용하기 어려운 작은 크기(표현 범위)
- 연산자의 기본 반환 타입 및 캐스팅 이슈
- (심증 기반) 생각보다 메모리를 절약할 수 있을지 모르겠다?
위와 같은 이유로 저도 다른 사람들과 비슷하게 특별한 이유가 없다면, byte와 short 타입은 사용하지 않을 것 같아요. (파일 전송, 복사 등은 byte 단위이기 때문에 주의해야 해요. 그냥 안 쓸래! X)
아쉬운 부분
- 메모리 효율성에 대한 실험적 데이터
- 사용 사례 예시
- 자바와 다른 언어 비교?
- 명확하지 않은 결론 (위 내용이 충족되면 해결될 것 같아요.)
참고 자료

글 잘 읽었습니다. 최근에 메모리 관리 프로그램을 구현할 때 ByteArray를 사용한 적이 있는데, 바이트가 아닌 값을 인자로 받아서 저장할 때는 비트 마스킹과 시프트로 일일이 변환해야 하고, 배열에 저장되는 값이 바이트 값이다 보니까 가독성이 너무 떨어지더라고요.
저의 경우에는 이미 할당된 메모리 공간을 명확하게 나타내려고 ByteArray를 사용했는데, 제대로 활용하지 못해서 그런건지 큰 메리트는 느끼지 못한 것 같습니다.