
많은 서비스에 구현된 로그인 기능을 어떻게 구현하면 좋을 지 고민하며 작성하는 글이에요. 또한, 왜 그렇게 하고 싶은가?를 포함하여 프로젝트 팀원에게 제안하기 위한 글이에요.
이전 글에서 세션 쿠키 방식으로 인증을 구현하기로 결정했어요. 사용자가 원활하게 서비스를 이용하기 위해서는 세션을 잘 보관하는 것은 중요해요. 만약 서비스 중 저장된 세션이 지워진다면, 사용자는 다시 로그인을 해야 해요. 추가로 보관을 잘못하여 세션 정보가 이상하다면 다른 사람의 계정으로 활동하게 될 수도 있어요.
이번 글에서는 세션 정보를 어디에 어떻게 보관할 것인지를 중점적으로 고민해보려고 해요.
상황
우선 프로젝트에서 만드는 Spring Boot 애플리케이션을 기준으로 설명해요.
현재 세션 로그인 기능은 구현했지만, 별도의 설정을 하지 않아 톰캣 서버 내에 세션을 저장하고 서버를 끄면 사라져요. 세션 관리 방법에 대해 살펴보고 최선의 선택을 하려고 해요.
추가로 일반적인 기능과 채팅 기능을 분리해서 개발한 후 따로 배포할 수도 있어요. 또한 사용자가 많아지거나 공부 목적으로 Scale Out 전략을 사용할 수도 있어요. 즉, 배포할 때 여러 개의 서버로 구성될 가능성이 있다는 말이에요.
Scale Up? Scale Out?
Scale Up이란 서버의 사양을 높이는 것을 말해요. 기존 서버에 자원(CPU, 메모리 등)을 추가하거나 서버 자체를 높은 사양의 서버로 교체하여 서버의 성능을 향상시켜요. 즉, 서버 한 대의 성능을 높여요.
Scale Out이란 서버의 수를 늘리는 것을 말해요. 기존 서버와 비슷한 사양의 새로운 서버를 추가하여 트래픽을 분산시켜 응답 속도(성능)를 개선해요.
세션 저장소 유형
세션 저장소는 사용자가 로그인한 후 유지해야 할 정보를 저장하는 공간입니다. 어떤 저장소를 선택하느냐에 따라 시스템의 복잡성, 확장성 등에 영향을 미치기 때문에 신중하게 고민해보려고 해요.
톰캣 세션 사용하기: 가장 기본적인 방식으로, 아무런 설정을 하지 않으면 톰캣 서버 내에서 세션이 관리돼요.데이터베이스 사용하기: MySQL, PostgreSQL와 같은 데이터베이스에 세션을 저장하고 관리해요.인-메모리 데이터베이스 사용하기: Redis와 같은 인-메모리 데이터베이스를 사용하여 세션을 저장하고 관리해요.
톰캣 세션 사용하기
일반적으로 별다른 설정을 하지 않았을 때, 기본적으로 적용되는 방식이에요.
초기 프로젝트에서는 톰캣 세션을 사용하는 것이 간단하고 빨라요. 저도 초기 개발 단계에서는 톰캣 세션을 사용했어요. 하지만 서버 재시작 시 세션 손실, 여러 서버 간 세션 동기화 등 고려할 사항이 많아요.
장점
- 별도의 외부 저장소나 복잡한 설정 없이도 바로 사용할 수 있기 때문에 초기 구현에 유리해요.
- 세션 정보를 서버 메모리에 저장하기 때문에 속도가 빨라요.
단점
- 서버가 재시작하거나 장애가 발생하면 세션 정보가 손실될 수 있어요.
- 서버가 여러 대일 경우 각 서버의 세션이 독립적이에요. 즉, 세션 동기화를 위한 추가적인 구현이 필요해요.
- 많은 사용자가 동시에 접속하면 서버의 메모리 용량을 초과할 수 있어요.
데이터베이스 사용하기
세션을 MySQL, PostgreSQL 등의 관계형 데이터베이스에 저장하는 방식이에요. 각 서버가 같은 데이터베이스를 참조하기 때문에 서버가 여러 대일 때도 동일한 세션 정보를 공유할 수 있어요.
장점
- 서버를 재시작해도 세션이 유지돼요.
- 여러 서버가 세션을 공유할 수 있기 때문에 확장성이 좋아요.
- 데이터베이스에 저장하기 때문에 세션 정보가 영구적으로 저장돼요.
단점
- 세션 조회 및 업데이트가 데이터베이스 쿼리를 통해 이루어지므로, 데이터베이스의 부하가 커질 수 있고, 성능 또한 비교적 느려요.
- 데이터베이스 스키마 설계 및 관리가 필요하며, 세션 만료 시 삭제되는 로직도 별도로 구현해야 해요.
테스트
implementation 'org.springframework.session:spring-session-jdbc'spring:
session:
jdbc:
initialize-schema: always # 세션 및 세션 속성 테이블을 자동으로 생성해줘요.
# 추가로 jdbc.table-name을 통해 테이블 이름도 변경할 수 있다.의존성을 추가하고 아래의 설정을 추가하면 바로 테스트를 진행할 수 있어요. 간단히 만든 로그인 기능을 실행하고 저장된 세션 정보를 살펴보면 아래와 같아요. (MySQL을 사용했어요.)
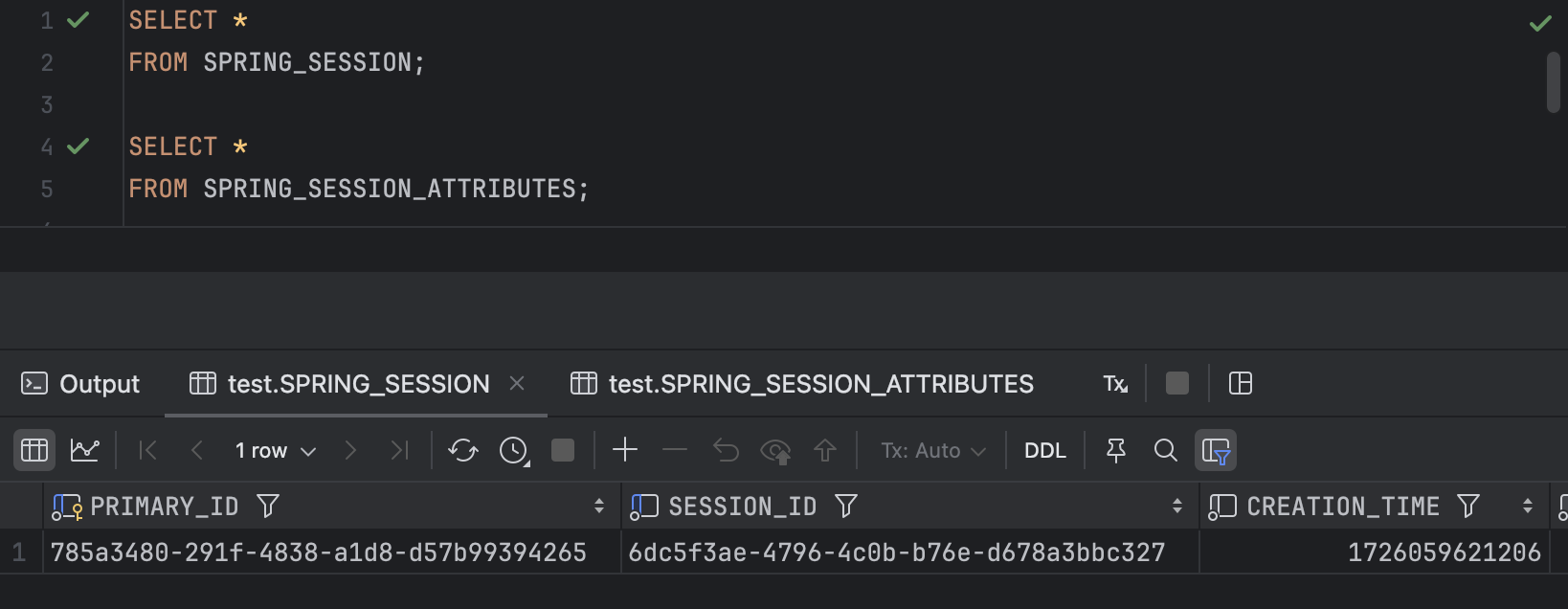
세션 저장을 위한 테이블이 자동으로 생성되어 저장되는 것을 볼 수 있어요.
생각보다 구성은 어렵지 않은 편이지만, 하드 디스크에 저장하는 데이터베이스 특성상 메모리에 저장하는 방식들보단 시간이 오래 걸려요. 정확한 지표가 될 순 없겠지만, 실제로 여러 번 요청을 테스트해본 결과에요.
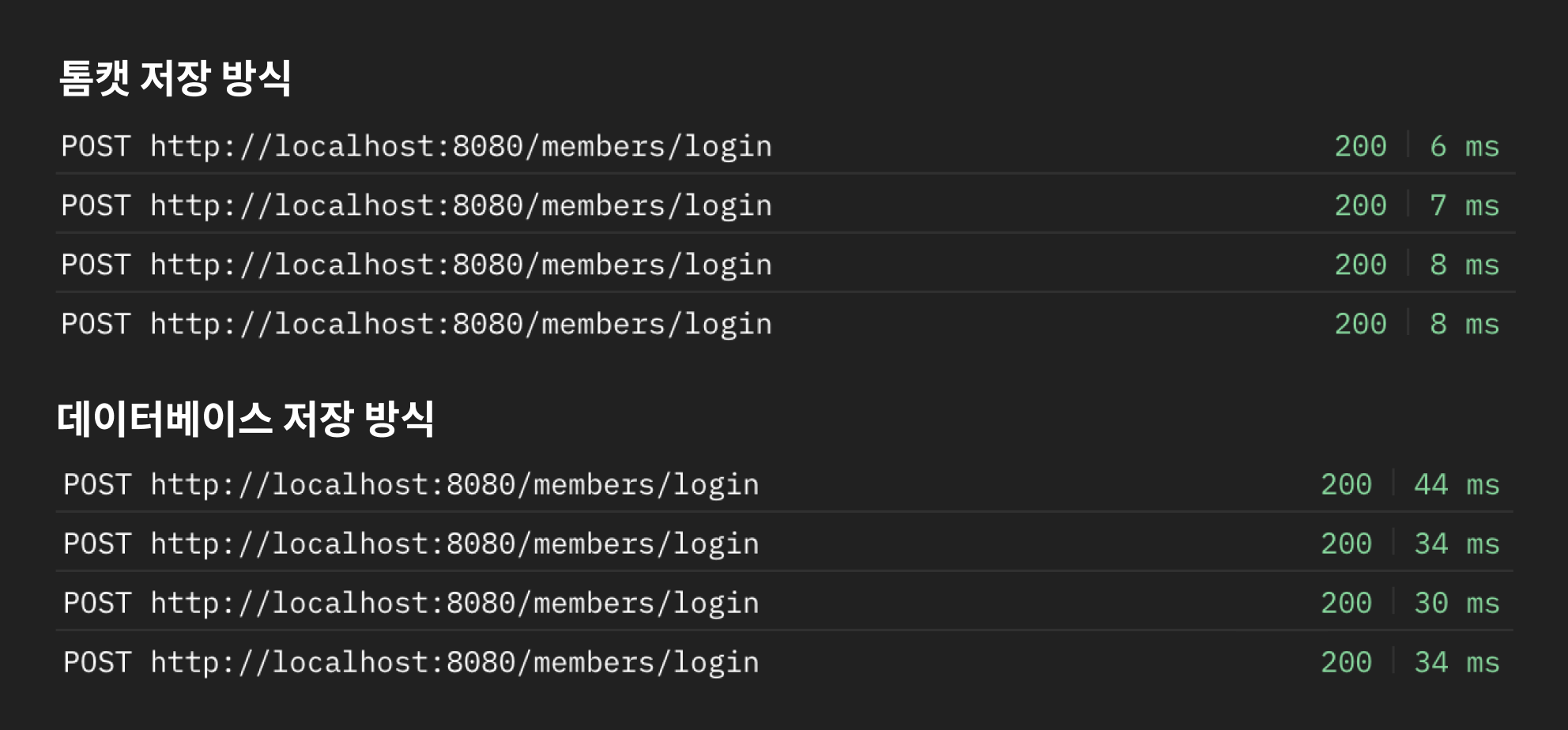
로그인 과정 마지막에 생성된 세션을 저장소에 저장하는 코드가 있는데, 톰캣 서버에 세션을 저장하는 방식은 메모리 기반이기 때문에 비교적 빨리 write 되어 응답 속도에 차이가 있어요.
인-메모리 데이터베이스 사용하기
Redis와 같은 인-메모리 데이터베이스에 세션을 저장하는 방식이에요. 서버의 메모리가 아닌 외부의 고성능 인-메모리 데이터베이스를 사용하여 세션을 빠르게 관리하며, 데이터베이스 사용 방식과 동일하게 서버 간 세션을 공유할 수 있어요.
장점
- 메모리 기반 데이터베이스이므로 빠른 응답 속도를 보장해요.
- 여러 서버 간 세션을 공유할 수 있으며, 서버 수를 늘리거나 클러스터를 구성하여 확장할 수 있어요.
- Redis의 경우 기본적으로 인-메모리 데이터베이스지만, 디스크에 백업할 수 있기 때문에 안정성을 챙길 수 있어요.
단점
- 인-메모리 서버를 추가적으로 운영해야 하며, 세션 만료 및 데이터 정리를 위한 정책을 관리해야 해요.
- 클라우드에서 Redis와 같은 인-메모리 데이터베이스를 사용하면 추가 비용이 발생할 수 있어요.
테스트
원활한 테스트를 위해 레퍼런스가 가장 많았던 Redis를 활용해봤어요.
// Redis와의 통신 및 데이터 처리를 위한 라이브러리
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
// Redis를 세션 저장소로 사용하기 위한 Spring Session 통합 라이브러리
implementation 'org.springframework.session:spring-session-data-redis'# Spring Boot 애플리케이션이 Redis 서버와 통신할 수 있도록 설정
spring:
data:
redis:
host: localhost
password: 1234
port: 6379
# Redis에서 세션 데이터를 저장할 때 사용할 네임스페이스를 설정
session:
redis:
# Redis의 키를 session-test:sessions로 접두어를 붙여 세션을 저장
namespace: session-test:sessions
# 세션 쿠키의 이름을 설정 (아래 이미지로 확인)
server:
servlet:
session:
cookie:
name: GOODSESSIONID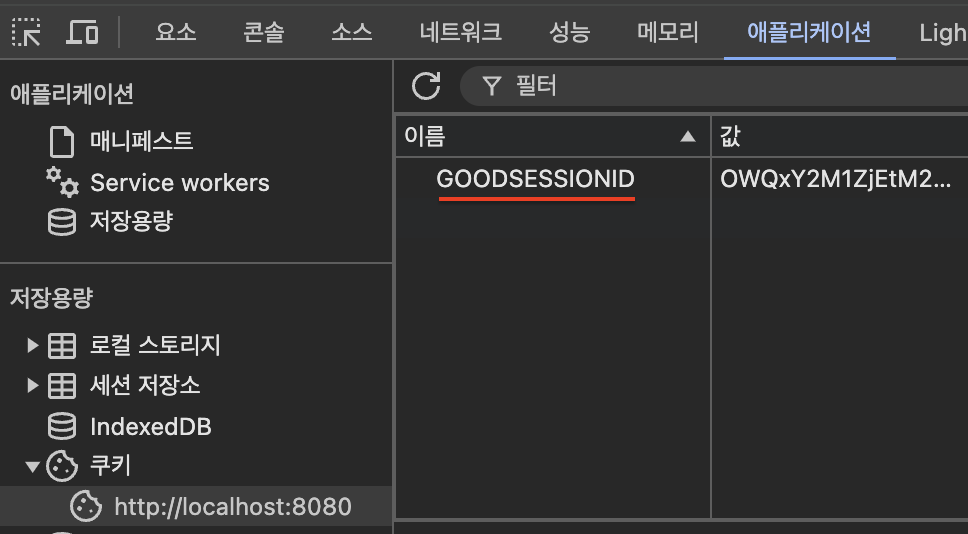
의존성을 변경하고 application.yml 설정 값을 추가해주면, 바로 사용할 수 있어요. (Redis는 직접 구동해야 해요.)
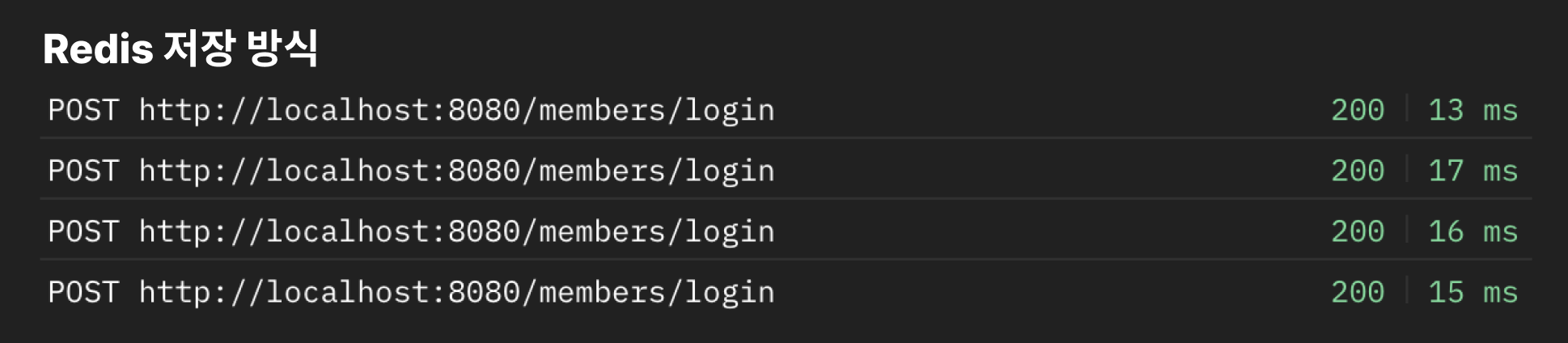
데이터베이스 저장 방식보다 확실히 평균 응답 속도가 빨라진 것을 볼 수 있어요.
분산 서버 환경에서 발생하는 데이터 불일치
앞서 말한 프로젝트의 상황
일반적인 기능과 채팅 기능을 분리해서 개발한 후 따로 배포할 수도 있어요. 또한
사용자가 많아지거나공부 목적으로Scale Out전략을 사용할 수도 있어요.
우리 프로젝트는 일반적인 기능과 채팅 기능을 분리하여 배포하거나 공부 목적으로 Scale Out 전략을 사용할 수도 있어요. 여러 대의 서버가 배포될 가능성이 있다는 말이에요.
(특별히 설정이나 구현을 하지 않은) 톰캣 서버에 저장하는 방식의 경우 각 서버마다 세션 저장소에 저장된 세션 정보들이 다른 서버와 공유되지 않아요. 즉, 세션 정보 저장 방식에 따라 데이터 불일치 문제가 발생할 수 있어요.
데이터 불일치 상황
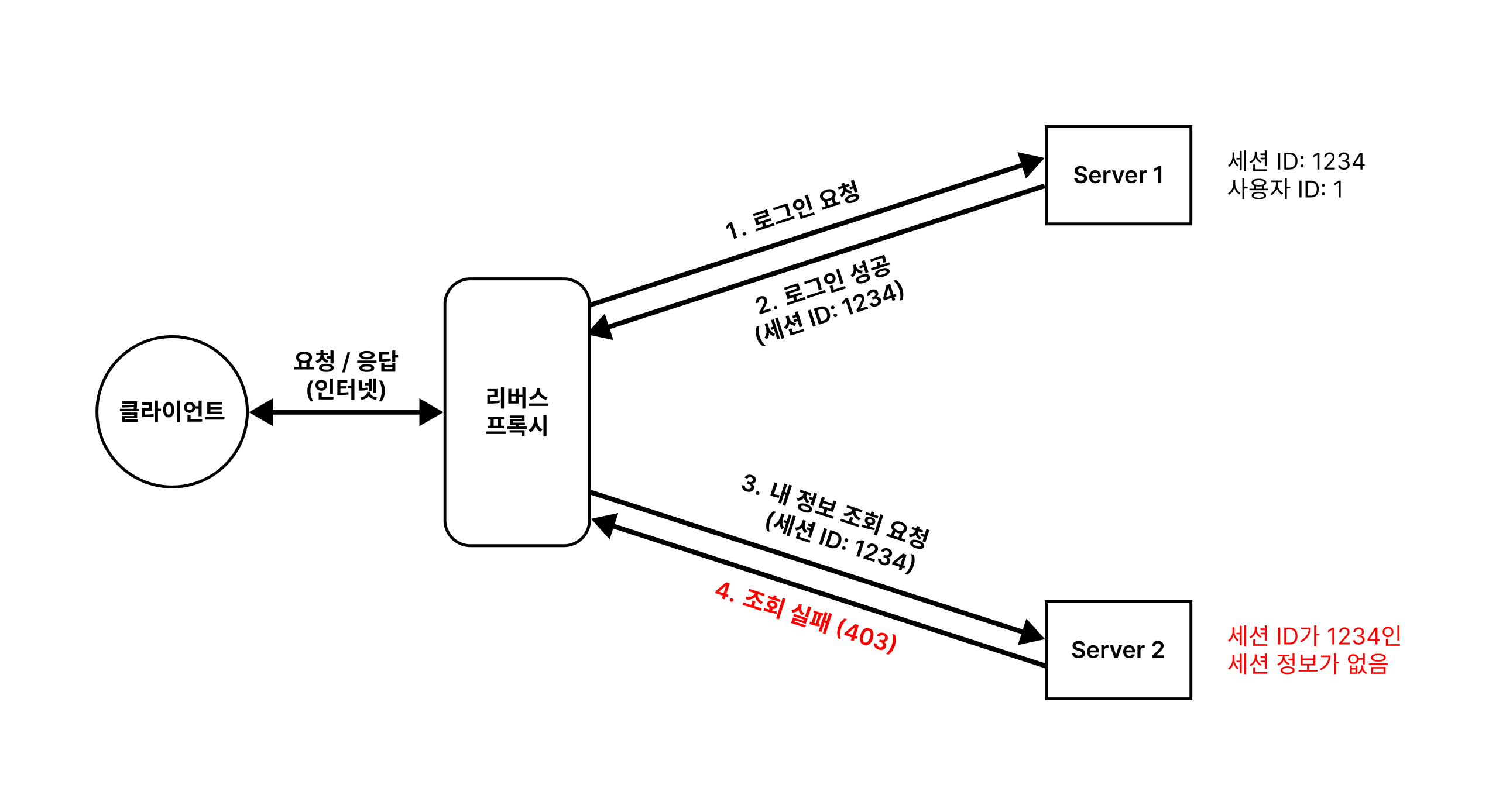
각 서버마다 세션 저장소가 존재하는 경우 위와 같은 상황이 발생할 수 있어요. (편의를 위해 간단하게 그렸어요.)
- 클라이언트의 로그인 요청은 리버스 프록시에 의해
Server 1에 전달되고, 인증 과정을 거쳐 세션 ID를 발급 받아요. (해당 서버에만 세션 정보가 저장돼요.) - 클라이언트의 조회 요청이 이번에는
Server 2에 전달돼요. 하지만Server 2의 세션 저장소에는 해당 사용자의 세션 정보가 없기 때문에(인증을 하지 못해요.) 조회를 실패해요.
따라서 사용자는 다시 로그인을 요청해야 해요. 하지만 그렇다고 문제가 해결되진 않아요. 분산 서버 환경인 경우 특별한 설정 없이는 사용자의 요청이 세션 정보가 저장된 서버로 전송된다는 보장이 없기 때문이에요.
이처럼 여러 대의 서버가 존재하는 경우 일관성있게 세션 정보를 관리하는 것이 필요해요.
Reverse Proxy (리버스 프록시)
인터넷-서버 사이에 존재하는 프록시를 말해요. 여기서 리버스 프록시는 사용자의 요청을 여러 서버 중 하나로 전달해주는 중간 서버 역할을 해요. 사용자는 리버스 프록시에 직접 요청을 보내고, 리버스 프록시는 해당 요청을 기준에 따라 적절한 서버로 전달해요. 이 과정에서 리버스 프록시는 클라이언트에게 서버의 세부 정보를 숨기고, 클라이언트가 요청하는 데이터를 서버에게 받아 클라이언트로 전달하는 역할도 해요.
참고: 로드 밸런싱, 캐싱, SSL Termination, 장애 대응으로 가용성 높이기 등 여러 이점을 누릴 수 있어요.
Sticky Session
먼저, 데이터 불일치 상황을 해결하기 위해 Sticky Session 방법이 있어요. 이는 사용자의 세션을 처음 생성된 서버에 바인딩하여 이후 동일한 사용자로부터 들어오는 모든 요청을 처음 바인딩 된 서버로 보내는 방법이에요.
위에서 살펴본 상황처럼 Server 1 에서 로그인하고 Server 2 에서 다른 요청을 보내면, 세션 정보가 없어 인증에 실패할테니 그냥 처음 정해진 서버인 Server 1 로 계속 요청을 보내는 것을 말해요. (너의 세션은 저기 저장되어 있으니 저기로 가라. 반복 )
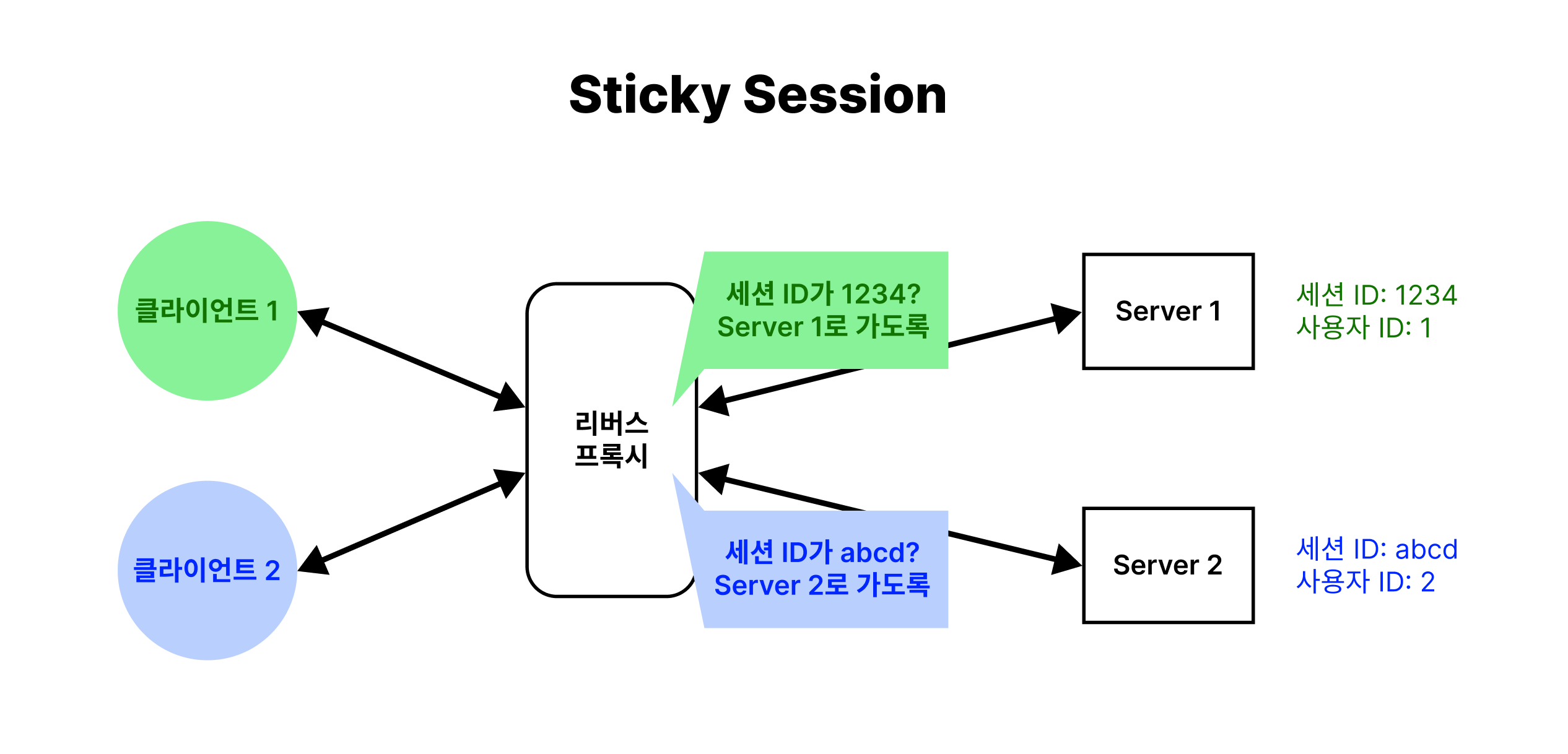
각 클라이언트가 보낸 요청들을 리버스 프록시가 받으면, 요청을 보낸 사용자의 IP 주소나 쿠키로부터 어떤 서버에 고정되어 있는지 확인한 후, 해당 요청을 지정된 서버로 보내요. 따라서, 사용자는 세션이 유지되는 동안에는 같은 서버로 요청을 주고 받기 때문에 데이터 불일치가 발생하지 않아요.
이처럼 데이터 불일치 문제는 해결했지만, 이 방법은 아래의 단점을 가져요.
-
트래픽 불균형: 처음에는 리버스 프록시(로드 밸런서)가 사용자 요청을 서버에 고르게 분배해요. 하지만 시간이 지나면서 일부 사용자가 이탈하게 되면, 세션이 바인딩된 서버에 남아있는 사용자가 몰릴 수 있어요. 예를 들어, 처음 10만 명의 사용자가 5만 명씩 두 서버에 나뉘었다가, 한쪽 서버의 사용자가 이탈하면 남은 5만 명은 계속 한쪽 서버에만 접속하게 돼요. 이로 인해 한 서버에 몰리면서 과부하가 발생할 수 있어요. -
세션 정보 사라짐: 한 서버가 갑작스럽게 종료되면, 해당 서버에 저장된 세션 정보도 함께 사라져요. 세션 정보가 없으면 사용자는 다시 로그인해야 하는 불편을 겪게 되며, 사용자 경험에 영향을 미칠 수 있어요.
Session Clustering
Session Clustering이란 여러 서버에서 생성된 세션을 하나의 그룹으로 묶어, 각 서버가 동일한 세션 정보를 공유할 수 있도록 만드는 기술을 말해요. 일반적으로 여러 서버가 동시에 실행되고 있는 환경에서 사용자의 요청이 어느 서버로 전달되더라도 일관된 세션 정보에 접근할 수 있어야 해요.
세션 클러스터링에서 중요한 점은 세션 복제(Session Replication)에요. 여러 대의 서버가 서로 세션 정보를 공유하려면, 한 서버에서 생성된 세션이 다른 서버에도 동일하게 존재해야 해요. 이를 위해, 서버들은 서로 세션 정보를 복제하여 일관성있는 세션 정보를 유지해요.
톰캣은 각 서버에서 생성된 모든 세션 정보들을 클러스터로 묶인 모든 서버에 복제하는 all-to-all 세션 복제 방식을 사용하고 있어요. 이 방식을 기준으로 한번 살펴볼게요.
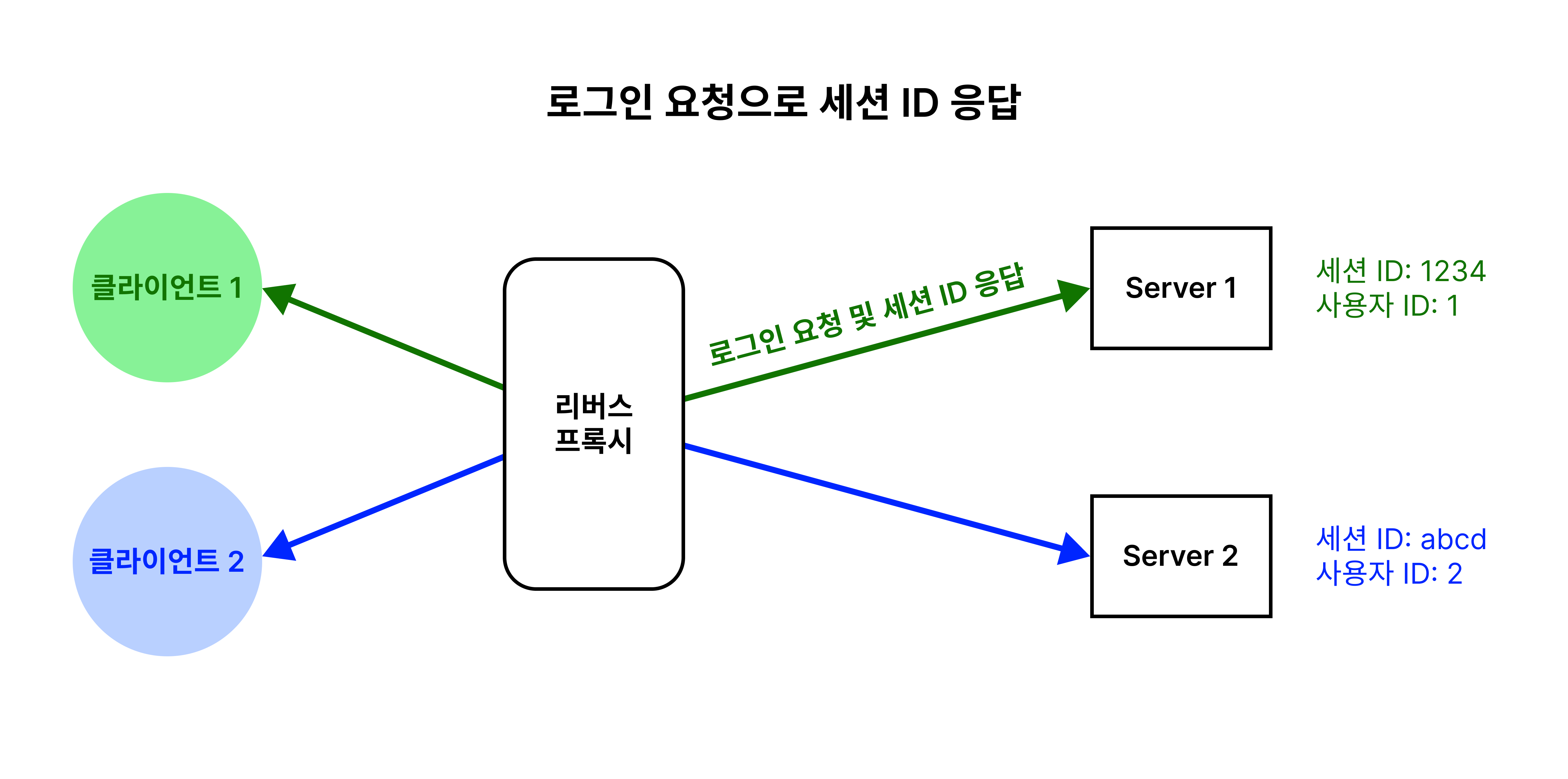
사용자가 로그인을 하면 새로운 세션을 생성하고 응답해요.
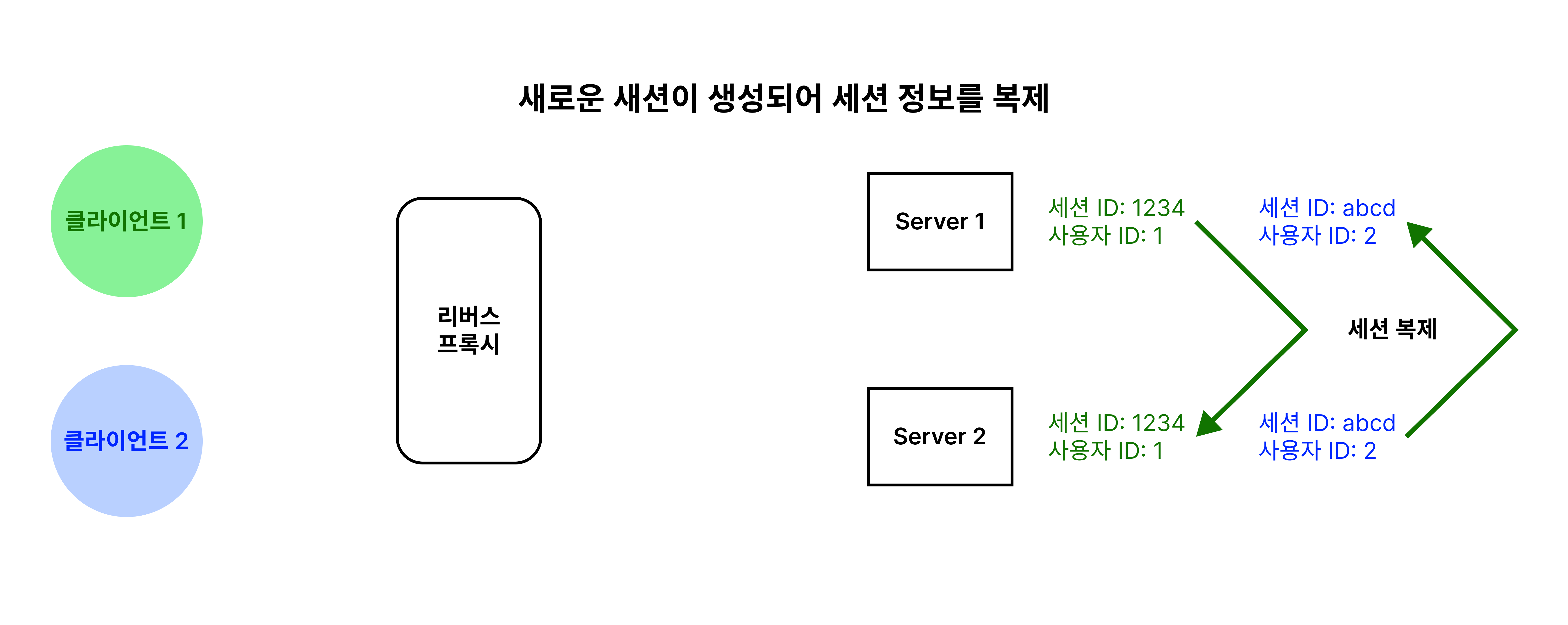
이처럼 새로 세션이 생성되었거나 세션 정보가 변경될 때마다 모든 서버에 복제해요.
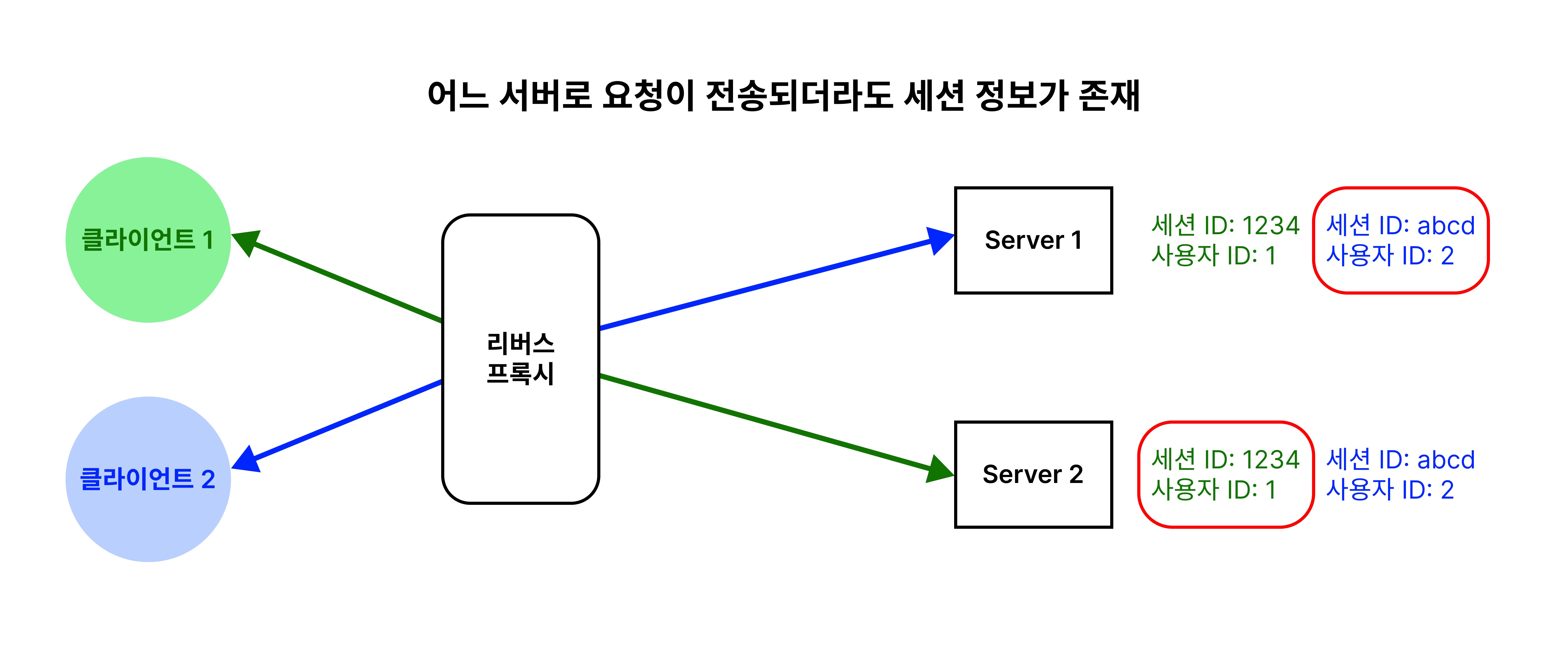
따라서 모든 서버가 일관성있는 세션 정보를 가지고 있을 수 있어요. 그렇다는 것은 다른 서버로 요청이 전송되더라도 로그인을 다시 할 필요없이 계속해서 서비스를 이용할 수 있다는 말이에요.
Sticky Session 방식의 한계였던, 트래픽 불균형과 세션 정보 안전성을 어느 정도 해결했다고 볼 수 있어요.
그러나 세션 복제 방식 자체에는 피할 수 없는 단점이 있어요. 바로 서비스를 이용하는 사용자가 늘어날수록 세션 복제도 늘어나요. (복제할 세션 정보도 많아져요.)
This works great for smaller clusters, but we don't recommend it for larger clusters — more than 4 nodes or so. Also, when using the DeltaManager, Tomcat will replicate sessions to all nodes, even nodes that don't have the application deployed.
Clustering/Session Replication How-To - Tomcat docs
톰캣 공식 문서에서는 이 방식이 소규모 클러스터에는 적합하지만 노드가 4개 이상인 대규모 클러스터에는 권장되지 않는다고 해요. 또한, 세션 복제 과정은 클러스터에 묶인 모든 서버에서 수행되기 때문에 웹 애플리케이션이 운영되고 있지 않은 서버에도 세션 데이터를 복제한다고 해요.
이처럼 Session Clustering 방식은 세션 정보가 변경될 때마다 세션을 복제해야 하기 때문에 사용자 수가 늘어난다면 성능 부분에서 문제가 발생할 수 있어요.
성능 이슈: 세션이 변경될 때마다 모든 서버에 세션을 복제하는 작업을 수행하기 때문에 대규모 클러스터에는 권장되지 않는 방식이에요. 또한, 서버에 따라 사용되지 않을 수 있는 세션 정보를 항상 가지고 있어야 해요.
이런 문제를 해결하기 위해 세션 저장소를 분리하는 방법을 고려할 수 있어요. 세션 저장소를 분리하면, 모든 서버가 동일한 세션 정보를 조회할 수 있기 때문에 서버 간 세션 불일치 문제를 해결할 수 있으며, 서버를 재시작하더라도 세션 정보가 사라지지 않아요.
세션 저장소 분리
각 서버 메모리에 세션을 저장하는 톰캣 기본 방식과 달리 세션 저장소를 분리하는 방식이에요. 앞에서 세션 저장소 유형에서 살펴봤던 데이터베이스나 인-메모리 데이터베이스를 사용하는 것이 세션 저장소를 분리했다고 말할 수 있어요.
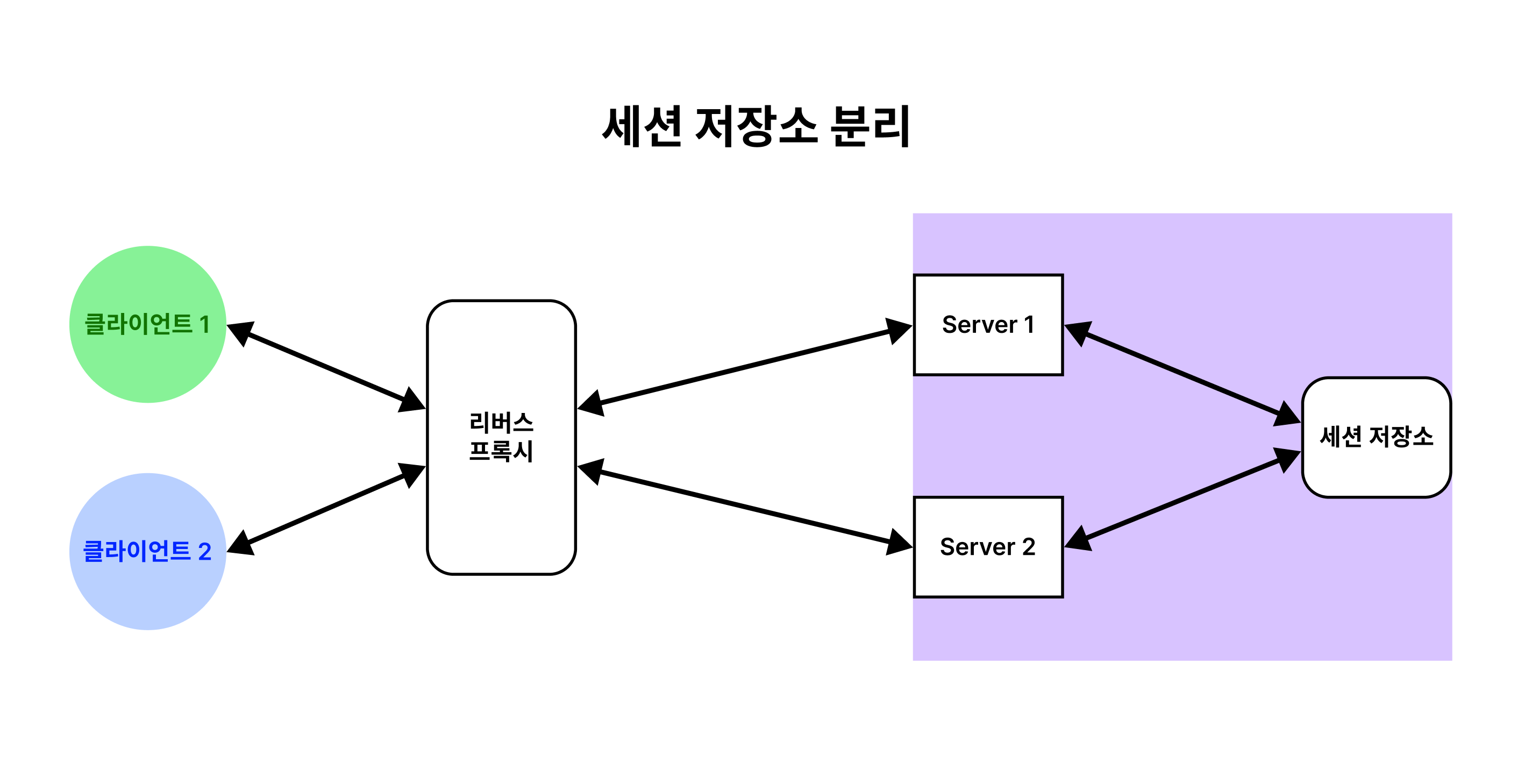
Sticky Session 방법처럼 특정 세션이 서버에 바인딩 되지 않으면서 데이터 불일치 문제를 해결할 수 있어요. 또한, 데이터 정합성을 위해 Session Clustering 방법처럼 세션을 복제할 필요가 없어요. (모두가 같은 곳에서 세션을 조회하기 때문이에요.)
보라색 영역에 존재하는 서버들은 하나의 세션 저장소만 접근하기 때문에, 모두 일관성 있는 세션 정보를 조회할 수 있어요. 덕분에 서버를 추가하거나 제거하는 것이 쉬워져요.
그러나 그림에서는 세션 저장소가 하나이기 때문에 세션 저장소에 문제가 생긴다면 서비스 전체에 문제가 발생해요. 그렇기 때문에 세션 저장소에 대한 클러스터링도 별도로 진행하면 좋다고 해요.
제안
저는 서버 외부에 인-메모리 데이터베이스(Redis)를 사용하여 세션 저장소를 만들면 좋을 것 같아요.
개발 단계에서는 톰캣 서버 자체에 세션을 저장하는 방식으로 빠르게 개발하는 것도 좋을 것 같아요. 미리 다른 설정을 하는 경우 모든 팀원이 같은 환경을 구축해야 하기 때문에 개발 편의성이 조금 떨어질 수 있을 것 같아요. 아니면 로컬 환경에서는 그대로 사용하고 배포 및 테스트 환경에서는 따로 설정하는 것도 좋을 것 같다고 생각해요.
여러 대의 서버가 존재할 경우 발생할 수 있는 데이터 불일치 문제는 세션 저장소를 분리하는 것이 가장 효과적인 방법이라고 생각해요. Sticky Session 방식은 트래픽 불균형을 초래할 수 있으며, 여전히 서버가 종료되는 경우 세션 정보가 사라질 수 있어요. 또한 인증을 위한 세션과 세션 일관성을 위한 정보 등 서버의 상태가 늘어나는 것은 서버의 부담 및 잠재적인 위험을 키울 수 있는 요소이며, HTTP의 Stateless와도 어울리지 않다고 생각해요.
이를 해결하기 위해 Session Clustering 방식을 사용할 수도 있지만, 사용되지 않을 수 있는 세션 정보들을 복제하여 가지고 있는 것은 낭비이며, 서버의 복잡성을 늘리는 요소라고 생각해요. 세션 저장소를 분리하는 것이 훨씬 간단하고 부담이 적은 방법인 것 같아요.
왜 인-메모리 데이터베이스?
-
빠른 응답 시간: 인-메모리 데이터베이스는 메모리에서 직접 데이터를 처리하기 때문에 디스크 기반인 데이터베이스보다 훨씬 빠른 응답 시간을 제공해요. 따라서 세션 정보처럼 자주 읽고 쓰는 데이터를 다루는 데 매우 적합하다고 생각해요. -
확장성: Redis와 같은 인-메모리 데이터베이스는 클러스터링과 샤딩을 통해 여러 서버에 데이터를 분산하여 저장할 수 있어요. 이를 통해 트래픽이 증가해도 성능 저하 없이 세션 데이터를 처리할 수 있으며, 서버 확장성 문제도 효과적으로 해결할 수 있다고 해요. (직접 사용해본 경험은 없어요.) -
관리의 분리: 비즈니스 데이터(사용자 정보, 게시글 등)와 세션 데이터는 성격이 다르다고 생각해요. 비즈니스 데이터는 장기적으로 유지되어야 하지만, 세션 데이터는 일시적으로 유지돼요. 인-메모리 데이터베이스를 통해 세션 데이터를 분리하여 저장하면, 데이터베이스 부하를 줄이고 관심사를 적절하게 나눌 수 있을 것 같아요.
왜 Redis?
세션 스토리지로 어떤 것이 더 적합한가? Redis VS Memcached - Liiot
저는 위 포스팅을 읽고 공감가서 Redis가 좋다고 생각했어요. 이거에 대해서는 함께 이야기해보면 더 좋을 것 같아요!
마무리
이번 글에서는 여러 대의 서버가 존재할 수 있는 프로젝트에서 세션 정보를 안전하고 일관성 있게 관리할 수 있는 방법을 찾기 위해 여러 방법을 살펴봤어요. 항상 정답은 없겠지만, 그 상황에서 최선의 선택을 하기 위해 학습하려고 해요. 다소 시간이 걸리는 단점이 있지만, 여러 가능성을 살펴보고 고민하는 것이 재밌는 것 같아요.
잘못된 부분이나 궁금한 점이 있으시면 말씀 부탁드립니다. 긴 글 읽어주셔서 감사합니다!
참고
