
조회수는 사용자가 콘텐츠에 대한 관심을 가장 직관적으로 확인할 수 있는 지표에요. 서비스의 품질과 사용자 경험에 긍정적인 영향을 주는 기능이지만, 단순한 구현은 신뢰도를 떨어뜨릴 위험이 있어요. 따라서 조회수가 제공해야 하는 가치와 신뢰할 수 있는 지표의 역할을 어떻게 설계할지 알아보려고 해요.
조회수의 가치
조회수는 무엇을 위한 지표인가?
제가 만들 조회수는 피드(게시글)의 인기를 나타내는 지표로 사용될 예정이에요.
단순 게시판 형태를 가진 서비스에서 조회수는 사용자가 서비스 내에서 주목받는 콘텐츠를 쉽게 식별하도록 돕는 역할을 해요. 예를 들어, 사용자가 오늘의 화제나 트렌드를 알고 싶을 때, 조회수가 높은 피드를 통해 즐거움을 느낄 수 있어요.
이처럼 조회수는 콘텐츠를 주목받게 하고 사용자들에게 탐색의 동기를 제공해요. 하지만 부정확하거나 신뢰를 떨어뜨리는 조회수는 오히려 사용자 경험에 부정적인 영향을 미칠 수 있다고 생각해요.
다른 곳에서의 조회수?
-
유튜브의 인기 급상승 동영상: 조회수 외의 더 많은 요소가 영향을 주겠지만, 사용자의 호기심을 자극하거나 재미를 주는 요소임은 분명해요. (인기 급상승 동영상에 자신의 영상이 게시되었다고 감사하다는 말을 남기는 유튜버도 있을 정도예요.) -
여러 블로그의 개설 이후 총조회수: 꾸준히 전달된 콘텐츠의 가치를 나타내며, 커뮤니티 규모를 파악하는 데 도움을 받을 수 있어요. -
이 상품 몇 명이 보고 있어요: 커머스 앱을 사용하다 보면 UI나 알림으로 n명이 보고 있다는 정보를 보게 되는 경우가 있어요. 이는 빼앗기는 것을 좋아하지 않는 사용자의 구매 심리를 자극해요. 이러한 기능은실시간성과중복 제거를 위해 더 복잡한 구현이 필요할 것 같아요. -
인터넷 방송 플랫폼의 시청자 수: 실시간으로 방송을 시청하고 있는 사용자의 수를 나타내요. 실시간 시청자 수를 집계하여 순위 정보를 제공하는 서비스도 있는 만큼 인터넷 방송 생태계에서는 중요하게 작용한다고 이해할 수 있어요.
피드 조회수에서의 차별점
제가 구현하려는 피드 조회수 기능은 위 사례들과는 달리 조회수가 작성자의 직접적인 수익으로 연결되지 않아요. 하지만 서비스 품질과 신뢰도를 위해서는 직관적이고 유효한 정보를 제공해야 하는 점은 동일한 것 같아요.
예를 들어, 오늘의 인기 피드가 조회수로 추천되었음에도 불구하고 부적절한 콘텐츠(광고, 불쾌한 내용 등)라면, 이는 사용자 경험에 부정적 영향을 미칠 수 있어요.
따라서 단순히 조회수를 증가시키는 구현이 아니라, 정확하고 신뢰할 수 있는 조회수 기능을 통해 서비스 품질을 위한 설계가 필요할 것 같아요.
참고
반면, 서비스의 유의미한 발전을 위해 수집되거나 Velog의 조회수처럼, 내부 인원만 볼 수 있는 지표도 있어요.
-
데이터 분석 및 활용: 사용자 행동 데이터를 기반으로 서비스를 개선하거나, 맞춤형 콘텐츠를 추천하는 데 활용할 수 있어요. -
작성자의 만족: 글을 작성한 사용자가 자신의 글이 얼마나 읽혔는지 확인하면서 개인적인 성취감이나 동기 부여를 느낄 수 있어요. (추천 지표로 사용될 수 있기도 해요)
구현
다양한 사례를 살펴보니, 조회수 기능은 서비스마다 제공하려는 가치가 다르게 설정된다는 점을 알 수 있었어요. 따라서 각 팀이나 프로젝트에서 조회수를 통해 제공하고자 하는 가치를 명확히 정의하고, 이를 기반으로 기획 및 기술적 결정을 내린다면 더 나은 결과를 얻을 수 있을 것 같아요.
Spring Boot, Spring Data JPA, MySQL을 사용해요.
가장 간단한 방법
@Entity
@Getter
@Table(name = "feeds")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Feed {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
private long viewCount = 0;
public Feed(String title, String content) {
this.title = title;
this.content = content;
}
public void addViewCount() {
this.viewCount++;
}
}
...
// Service 계층 메서드
@Transactional
public FeedResponse view(Long feedId) { // 특정 피드 조회
return feedRepository.findById(feedId)
.map(feed -> {
feed.addViewCount(); // 조회수 필드 +1
return FeedResponse.from(feed);
})
.orElseThrow();
}가장 간단한 방법은 피드에 조회수 필드를 추가하고, 이를 조회할 때마다 viewCount 필드를 증가시키는 것이에요.
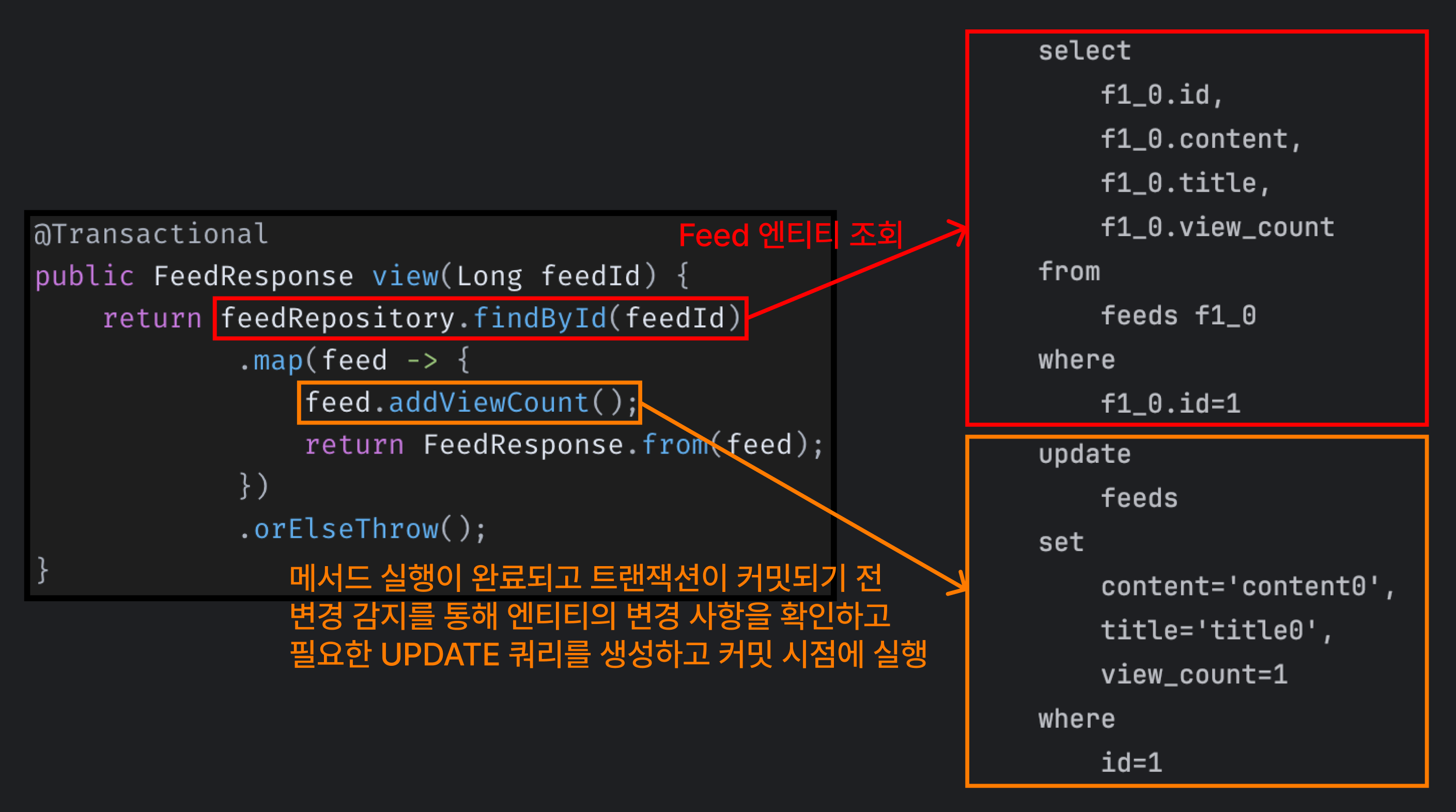
피드를 조회하기 때문에 당연히 SELECT 쿼리가 실행돼요. 이후 조회수 증가를 위해 엔티티를 변경했기 때문에 메서드 실행이 완료되고 트랜잭션이 커밋되기 전에 영속성 컨텍스트에서 가지고 있던 스냅샷과 비교하여 변경 사항을 적용하기 위한 UPDATE 쿼리를 생성하고 커밋 시점에 이를 실행해요.
즉, 조회가 발생할 때마다 Feed 엔티티를 조회하는 SELECT 쿼리와 조회수 필드를 변경하는 UPDATE 쿼리가 실행된다는 말이에요.
(참고) 왜 조회수 필드만 변경했는데 모든 컬럼이 수정되나요?
JPA의 기본 전략이기 때문이에요.
그러면 모든 필드를 데이터베이스에 전송해야 하기 때문에 전송량이 증가하지 않나요?
네. 그러나 아래와 같은 장점으로 모든 필드를 업데이트한다고 해요.
- 모든 필드를 수정한다면, 수정 쿼리는 항상 같아요.
- 데이터베이스에 동일한 쿼리를 보내면 데이터베이스는 이전에 한 번 파싱된 쿼리를 재사용할 수 있어요.
필드가 많거나 저장되는 내용이 너무 크다면 수정된 데이터만 사용해서 동적으로 UPDATE 쿼리를 생성할 수 있는 방법이 있어요. 아래와 같이 @DynamicUpdate 를 사용하면 돼요.
@Entity
@Getter
@DynamicUpdate // 추가하기
@Table(name = "feeds")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Feed { ... }상황에 따라 다르지만 컬럼이 2~30개가 넘어가지 않는 이상 대부분 기본 전략이 효율적이라고 해요. 따라서 기본 전략을 사용하다가 더욱 타이트한 최적화가 필요한 경우 고려하면 좋아보여요. (인덱스가 많거나, 특정 컬럼의 데이터가 너무 큰 경우 등)
정확하지 않은 조회수
위 코드의 구현은 간단하지만, 동시에 여러 요청이 들어오는 상황에서는 정합성 문제가 발생할 수 있어요.
public static void main(String[] args) {
int taskCount = 100; // 실행 흐름의 수
ExecutorService executorService = Executors.newFixedThreadPool(100);
for (int i = 0; i < taskCount; i++) {
// FeedReadTask는 특정 Feed를 조회하는 API를 호출하는 작업을 수행해요.
executorService.submit(new FeedReadTask("http://localhost:8080/feeds/1"));
}
executorService.shutdown();
}100개의 실행 흐름으로 같은 피드를 조회했지만, 테스트 결과 평균적으로 조회수가 10.9 정도로 기록되었어요. (테스트 10회, 단순 조회 작업이라 속도 및 결과에 편차가 크지 않다고 판단했어요.)
100번 호출했으니 조회수는 100이 되어야 하지만, 결과는 터무니없이 적은 값이 나왔어요.
처음에는...
처음에는 조회수의 정확도는 크게 중요하지 않다고 생각했어요. 인스타그램의 좋아요 수나 유튜브 구독자 수처럼, 숫자가 커질수록 대략적인 부피감만 보여주는 방식이 일반적이기 때문이에요. 사용자 입장에서도 몇 명이 좋아했는지와 같은 상세한 수치보다 얼마나 인기가 많은가를 비교할 수만 있다면 괜찮은 접근이라고 생각했어요.
다시 생각해보니...
그러나 결과적으로 최종 데이터는 올바르게 반영되어야 하는게 맞지 않나? 라는 의문이 들었어요. 커다란 부피감과는 별개로 서로 다른 2명이 동시에 피드를 조회했을 때 그 순간에는 아직 나 혼자 봤네라고 느낄 수 있지만, 언젠가는 조회수가 2로 반영되어야 올바른 데이터라고 말할 수 있다고 생각했어요.
그럼 왜 이런 문제가 발생할까?
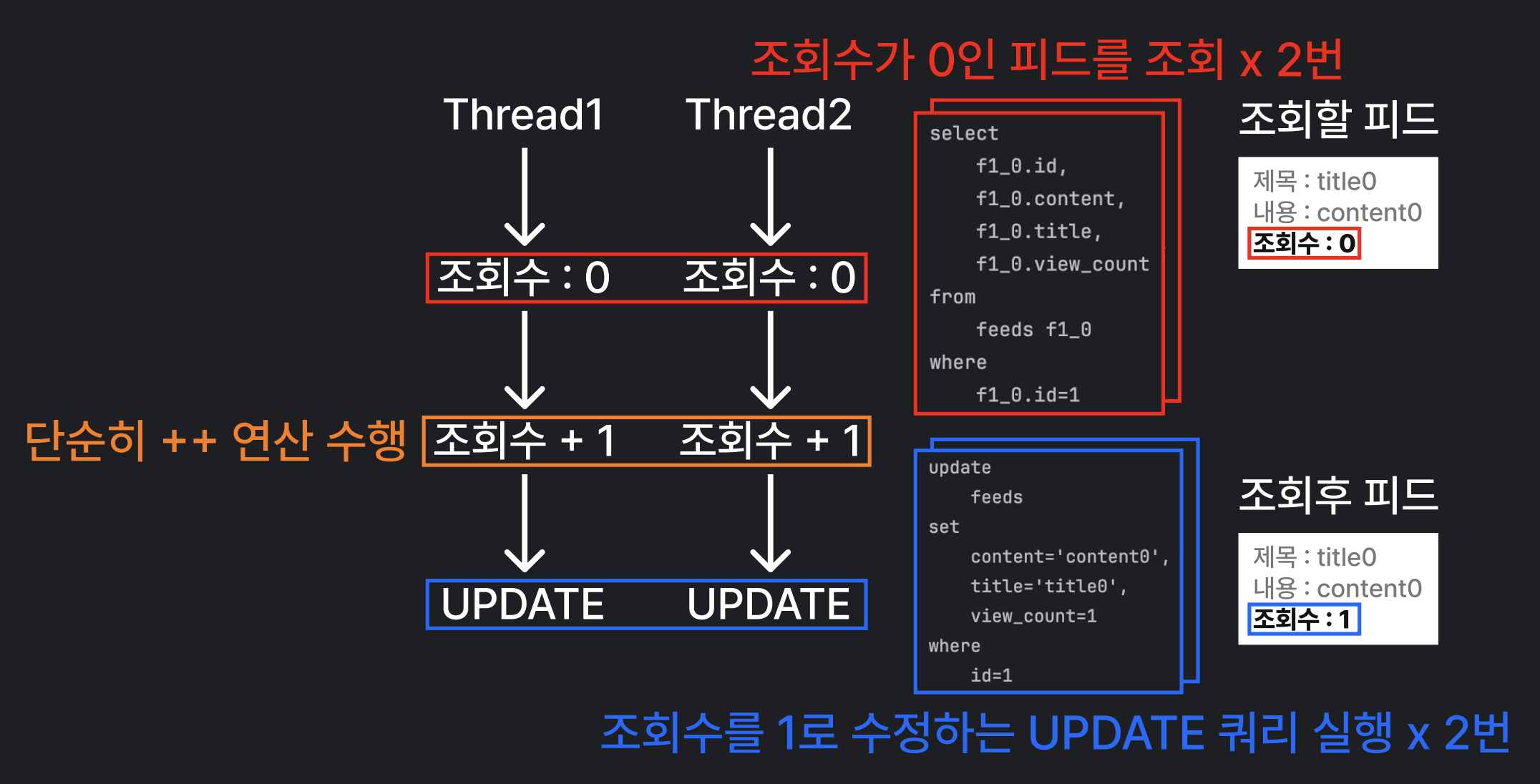
현재의 구현에서는 조회수의 데이터를 가져와 값을 1 증가시키고 저장해요. 하지만 동시에 여러 요청이 들어오는 경우, 각 요청은 서로의 작업을 고려하지 않고 독립적으로 처리돼요. 여러 사용자가 동시에 같은 피드(조회수 0)를 조회하고 조회수를 1 증가시키려고 할 때, 각 요청은 자신이 조회한 데이터를 기반으로 viewCount를 증가시키고, 이를 DB에 저장해요.
두 사용자가 동시에 조회수를 1 증가시키려 할 때
- 첫 번째 사용자는 viewCount가 0인 데이터를 읽고 1로 증가시켜요.
- (첫 번째 사용자의 조회수 반영이 끝나기 전에) 두 번째 사용자도 같은 데이터를 읽고, 역시 0에서 1로 증가시켜요.
- 두 사용자는 각각 UPDATE 쿼리를 실행하지만, 첫 번째 사용자가 업데이트한 값은 두 번째 사용자의 업데이트로 덮어씌워져요.
결국, 두 명의 사용자가 각각 1씩 증가시키려고 했지만, 최종적으로 반영되는 viewCount는 1로만 기록되고, 첫 번째 사용자의 변경은 누락되었어요. (Race Condition)
문제가 발생한 이유는 이러한 동시성 이슈를 고려하지 않았기 때문이에요.
동시성 문제를 해결하는 방법
동시성 문제를 해결하기 위해 여러 가지 접근 방식을 찾아봤어요. 적절한 방법을 선택하기 위해 간단한 테스트를 진행했어요.
synchronized 키워드 사용
조회수를 변경하는 메서드에 synchronized 키워드를 사용하여 하나의 쓰레드만 접근하여 작업할 수 있게 바꾸면 어떨까요?
// Feed 엔티티 내부
public synchronized void addViewCount() {
this.viewCount++;
}addViewCount() 메서드에 synchronized 키워드를 추가하면, 하나의 스레드만 이 메서드에 접근할 수 있기 때문에 동시성 문제가 해결될 것처럼 보이지만, 결과는 이전과 비슷했어요.
왜 synchronized로 해결되지 않았을까요?
이는 JPA의 동작 방식과 관련이 있어요.
- 엔티티 조회 :
findById()로 엔티티를 조회하면 영속성 컨텍스트에 엔티티가 저장돼요. - 엔티티 수정 :
addViewCount()로 필드를 변경하면 영속성 컨텍스트에서 변경된 엔티티를 관리해요. - 트랜잭션 커밋 : 트랜잭션이 끝나면 영속성 컨텍스트에서 변경 감지를 수행하고, 필요한 경우 UPDATE 쿼리를 실행해요.
문제는 동일한 Feed 엔티티를 동시에 조회하고 수정하는 요청이 들어올 경우, 각 요청이 서로 독립적으로 SELECT 쿼리를 실행하고 같은 초기 상태의 데이터를 기반으로 수정한다는 점이에요.
첫 번째 트랜잭션: viewCount = 0 -> viewCount = 1 -> UPDATE두 번째 트랜잭션: viewCount = 0 -> viewCount = 1 -> UPDATE (첫 번째 트랜잭션 변경 사항 덮어씀)
결국, synchronized 키워드는 메서드 수준에서만 동기화를 보장하며, 데이터베이스 레벨에서의 동시성 제어는 하지 않아요.
데이터에 동시에 하나의 스레드만 접근이 가능하다는 조건은 하나의 프로세스에서만 보장돼요.
예를 들어, Scale-out을 진행하여 서버가 여러 대일 때 동시성이 보장되지 않는다는 말이에요.
비관적 락(Pessimistic Lock)
동일한 데이터에 대해 동시에 여러 작업이 수행되지 않도록 데이터에 잠금을 거는 방식이에요. JPA에서 @Lock 어노테이션을 사용하여 구현할 수 있어요.
// Repository 계층..
public interface FeedRepository extends JpaRepository<Feed, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE) // 읽기 쓰기 잠금
@Query("SELECT f FROM Feed f WHERE f.id = :feedId")
Optional<Feed> findByIdForUpdate(@Param("feedId") Long feedId);
}
// Service 계층..
@Transactional
public FeedResponse view(Long feedId) {
return feedRepository.findByIdForUpdate(feedId) // 변경
.map(feed -> {
feed.addViewCount();
return FeedResponse.from(feed);
})
.orElseThrow();
}위와 같이 설정하면, SELECT ... FOR UPDATE 쿼리가 실행되어 다른 트랜잭션이 해당 데이터를 수정하거나 읽을 수 없도록 읽기 쓰기 잠금을 설정해요.
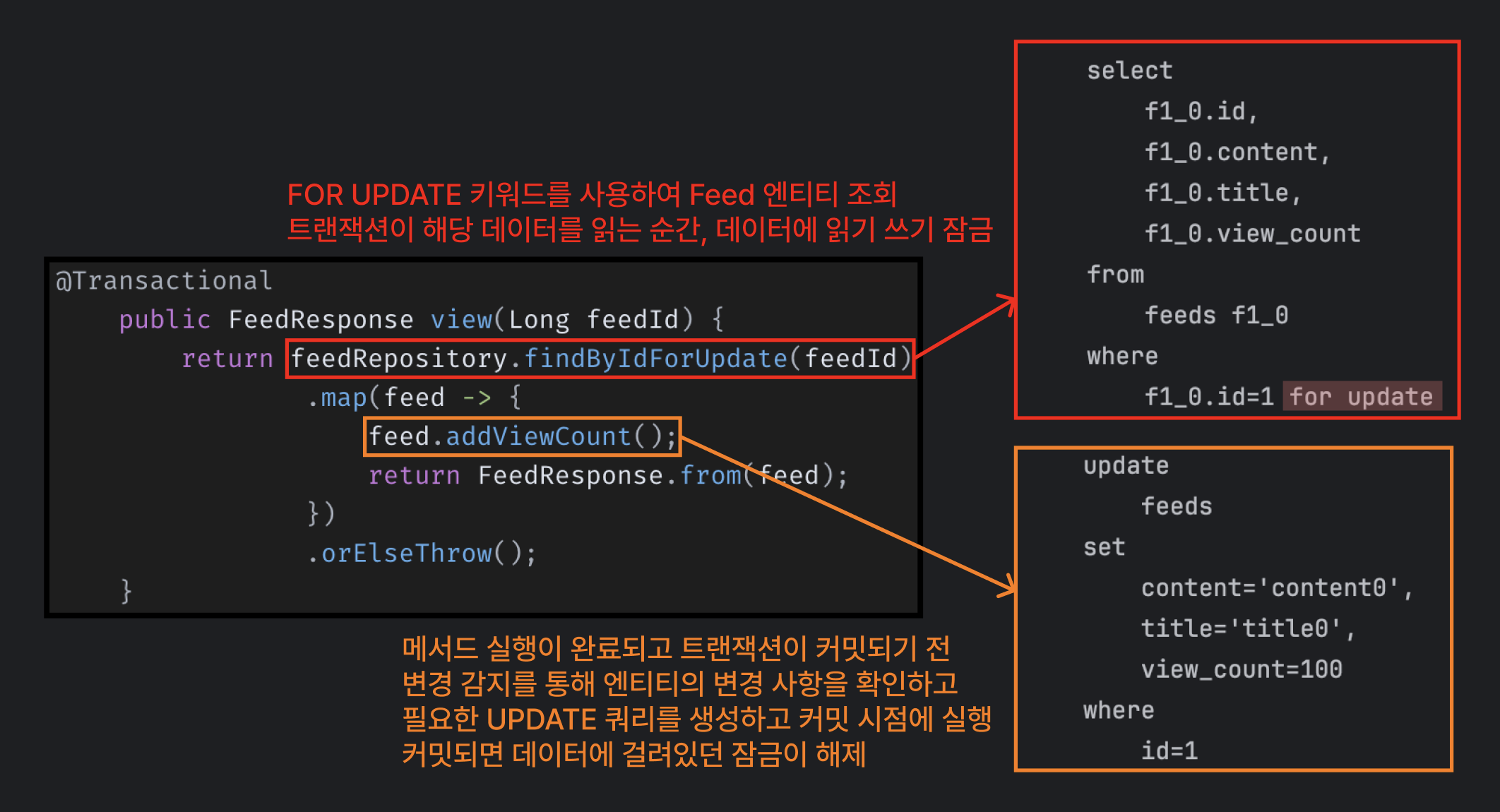
FOR UPDATE 키워드가 사용되면, 트랜잭션이 해당 데이터를 읽는 순간, 데이터에 잠금이 걸려서 읽거나 수정할 수 없게 돼요.
- 잠금이 걸린 데이터는 다른 트랜잭션이 수정할 수 없어요.
- 다른 트랜잭션이 동일한 데이터를 읽으려고 시도하면, 잠금을 해제할 때까지 대기해요.
- 잠금은 트랜잭션 범위 내에서만 유효하며, 트랜잭션이 커밋되거나 롤백되면 해제돼요.
각 요청의 트랜잭션이 시작될 때 잠그고 커밋(반영)될 때 해제하기 때문에 두 트랜잭션이 동시에 동일 데이터를 수정하려 할 경우, 한 트랜잭션이 완료될 때까지 다른 트랜잭션이 대기하기 때문에 동시성 문제가 확실히 해결돼요.
그러나 트랜잭션을 완전히 기다리기 때문에 대기 시간이 길어지고 높은 트래픽 환경에서는 성능 저하를 초래할 가능성이 높은 편이에요.
비관적 락은 데이터 정합성이 매우 중요하거나, 충돌 가능성이 높은 경우에 적합해 보여요. 예를 들어, 쇼핑몰에서 한정 상품의 재고를 감소를 처리하거나 은행 계좌의 잔액을 수정할 때 사용할 수 있을 것 같아요.
낙관적 락(Optimistic Lock)
낙관적 락은 동시성 충돌을 허용하지만, 충돌이 발생하면 이를 감지하고 처리하는 방식이에요. 일반적으로 @Version 어노테이션을 사용해 구현하며, 데이터를 수정할 때 버전 정보를 기반으로 변경 충돌을 감지해요.
// Repository 계층..
public interface FeedRepository extends JpaRepository<Feed, Long> {
@Lock(LockModeType.OPTIMISTIC) //
@Query("SELECT f FROM Feed f WHERE f.id = :feedId")
Optional<Feed> findByIdWithOptimisticLock(@Param("feedId") Long feedId);
}
// Feed 엔티티
@Entity
@Getter
@Table(name = "feeds")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Feed {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
private long viewCount = 0;
@Version // 낙관적 락을 위한 버전 필드 추가
private Integer version;
...
}낙관적 락은 트랜잭션이 시작될 때 잠금을 걸지 않고, 트랜잭션이 커밋될 때 버전 정보를 비교하여 충돌 여부를 확인해요. 만약 버전 정보가 일치한다면 트랜잭션을 커밋하고 (버전값 증가 후 저장), 그렇지 않으면 충돌이 발생한 것으로 간주하고 예외가 발생해요.
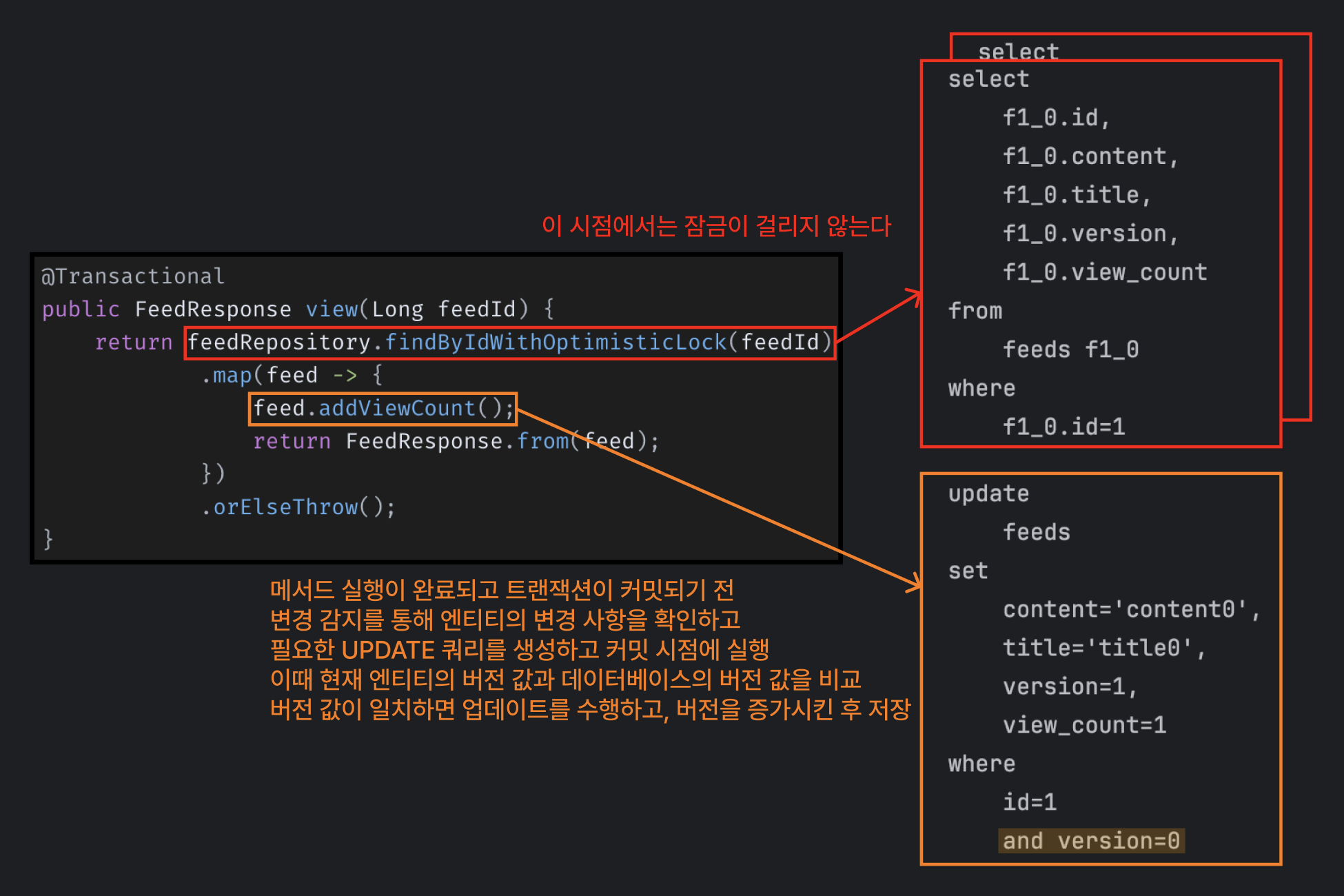
위와 같이 @Version 어노테이션을 추가한 필드인 version은 트랜잭션이 커밋될 때 자동으로 검증되고, 충돌이 발생하면 ObjectOptimisticLockingFailureException 예외를 던져요.
ObjectOptimisticLockingFailureException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect): [dev.bang.viewtest.entity.Feed#1]]
그러나 우리는..
그러나 이렇게 예외가 발생하여 프로그램이 종료되거나 무시되지 않고, 다시 정확한 데이터를 위해 수정 쿼리가 실행되는 것을 원해요.
그렇게 하기 위해서는 ObjectOptimisticLockingFailureException 예외가 발생했을 때 처리해야 하는 로직을 직접 구현해야 해요.
해당 요청을 다시 시도하거나 사용자에게 이를 알리는 방법으로 구현할 수 있을 것 같아요. 하지만 조회수가 집계되지 않았습니다. 라고 사용자에게 전달할 정도는 아니기 때문에 다시 시도하는 방법이 좋을 것 같아요.
// 재시도 로직 처리 예시
@Transactional
public FeedResponse view(Long feedId) throws InterruptedException {
int retryCount = 0;
while (retryCount < 3) { // 최대 3번 재시도
try {
return feedRepository.findByIdWithOptimisticLock(feedId)
.map(feed -> {
feed.addViewCount();
return FeedResponse.from(feed);
})
.orElseThrow(() -> new EntityNotFoundException("Feed not found"));
} catch (ObjectOptimisticLockingFailureException e) {
retryCount++;
if (retryCount >= 3) {
// 예외를 던지거나 추가 로직 구현
}
// 예외 발생 시 잠시 대기 (재시도 전에 잠시 대기)
Thread.sleep(5000); // 예시: 5초 대기 후 재시도
}
}
// 재시도 실패 후 예외 처리 등
}예시를 작성해 봤어요. 재시도 횟수를 설정하여 과도한 재시도를 방지하거나 상황에 맞게 지연시간을 설정해야 할 것 같았어요. 대기 큐를 사용하는 방법도 있을 것 같아요.
낙관적 락은 동시성 문제가 발생할 수 있는 환경에서 충돌이 발생할 경우 이를 감지하고, 예외를 처리하여 데이터를 정확하게 수정할 수 있도록 도와줘요.
비관적 락보다 잠금 시간이 짧기 때문에 성능이 더 나을 수 있지만, 재시도 로직으로 인해 더 많은 시간이 걸릴 수도 있을 것 같아요. 프로젝트 상황에 맞는 처리 로직을 구현하여 시스템의 일관성을 유지하면서도 사용자 경험을 방해하지 않도록 해야 해요.
데이터 충돌이 자주 일어나지 않을 것이라고 예상할 수 있고, 조회 성능이 중요한 경우에는 괜찮은 방법이라고 생각해요.
직접 수정 쿼리를 작성하기
하나의 트랜잭션 단위 내에서 @Modifying과 @Query를 이용한 업데이트 쿼리 방식은 명시적인 업데이트 쿼리를 통해 트랜잭션 내에서 즉시 수정하는 방법도 있어요.
// Repository 계층..
public interface FeedRepository extends JpaRepository<Feed, Long> {
@Modifying
@Query("UPDATE Feed f SET f.viewCount = f.viewCount + 1 WHERE f.id = :feedId")
void incrementViewCount(@Param("feedId") Long feedId);
}
// Service 계층..
@Transactional
public FeedResponse view(Long feedId) {
feedRepository.incrementViewCount(feedId);
return feedRepository.findById(feedId)
.map(FeedResponse::from)
.orElseThrow();
}incrementViewCount() 메서드는 JPQL을 통해 단일 UPDATE 쿼리로 실행되므로, 1000개 스레드 환경에서도 동시성 문제 없이 안전했어요.
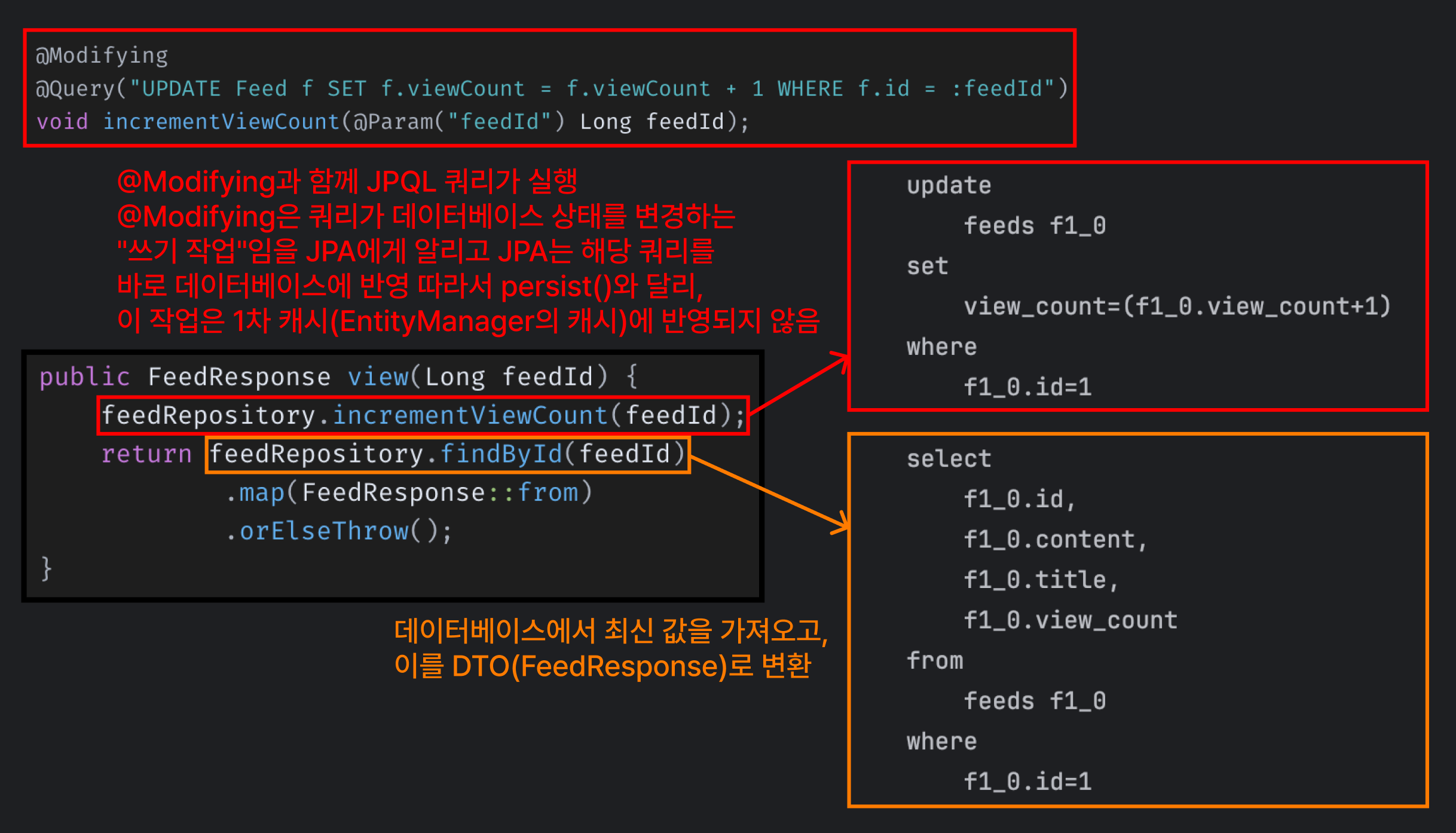
어떻게 동시성 문제를 잘 처리할 수 있었을까요?
이전에는 애플리케이션 수준에서 값을 읽고 증가시키고 반영했어요. 예를 들어, 두 명의 사용자가 동시에 조회수가 0인 피드를 조회했다면 모두 해당 피드의 조회수 필드를 1로 UPDATE 하는 쿼리를 실행할 수 있어요.
그러나 이 방법은 데이터베이스 수준에서 값을 증가시켜요. 조회수 필드에 +1 연산을 수행하라고 UPDATE 쿼리를 실행해요. 이때 데이터베이스는 트랜잭션 직렬화 메커니즘을 활용하여 동시 접근 시 순차적 처리를 보장해요. 즉 모든 연산이 순차적으로 실행되는 것을 보장하기 때문에 동시성 이슈가 발생하지 않아요. (트랜잭션 격리 수준 구성이나 롤백 여부에 따라 달라질 수 있어요.)
-
데이터베이스의 원자적 증가 연산: UPDATE 문에서f.viewCount = f.viewCount + 1는 데이터베이스 레벨에서 원자적으로 수행되므로, 동시성 문제가 발생하지 않아요.이는 애플리케이션 레벨에서 값을 읽고 수정하는 기존 방식(findById → 증가 → 저장)과 다르게, DB 내부에서 연산하므로 두 트랜잭션이 동시에 동일 값을 업데이트하더라도 최종적으로 모든 연산이 반영돼요. 따라서 동시 실행 환경에서도 조회수 증가 연산이 안전해요.
-
트랜잭션 격리 수준의 보장: 대부분의 데이터베이스에서 기본 격리 수준인READ_COMMITTED이상에서는 트랜잭션이 다른 트랜잭션이 진행 중인 데이터 변경사항을 읽지 못하도록 보장해요. UPDATE 쿼리는 락(Lock)을 동반하여 실행되며, 동일 데이터에 대한 충돌을 방지하기 위해 순차적으로 실행돼요. 따라서 동시성 문제를 피할 수 있어요.
트랜잭션 범위와 격리 수준을 잘 확인하고 사용해야 해요.
transaction isolation level 설명합니다! - 쉬운 코드 제가 본 유튜브 영상이 괜찮아서 추천드려요.
Redis 사용하기
지금까지의 방법은 모두 피드 조회와 조회수 컬럼 수정 쿼리가 모두 발생했어요. 테스트와는 다르게 엄청나게 많은 사용자가 특정 피드를 조회하는 경우 성능에 영향을 미칠 수 있어요. 특히, 수정 작업에서의 정합성을 맞추기 위해 더 많은 시간이 걸릴 것으로 예상돼요.
그래서 이번에는 Redis를 사용한 방법을 알아보려고 해요.
우선 피드를 조회하기 위한 SELECT 쿼리만 수행하도록 해요. 이때 조회했다는 것을 Redis에 저장해요. 이후 특정 시간이 지나면 Redis에 쌓인 값을 확인하고 UPDATE 쿼리를 실행하는 방법이에요.
@Service
@RequiredArgsConstructor
public class FeedService {
private final FeedRepository feedRepository;
private final RedisTemplate<String, Long> redisTemplate;
@Transactional(readOnly = true)
public FeedResponse view(Long feedId) {
addViewCount(feedId); // Redis에 조회수 증가를 알림
return feedRepository.findById(feedId) // 일반적인 조회 및 DTO 변환
.map(FeedResponse::from)
.orElseThrow();
}
private void addViewCount(Long feedId) {
String redisKey = FEED_VIEW_COUNT_PREFIX + feedId;
redisTemplate.opsForValue()
.increment(redisKey, 1L);
}
}
@Service
@RequiredArgsConstructor
public class FeedSyncService {
private final FeedRepository feedRepository;
private final RedisTemplate<String, Long> redisTemplate;
// 1분마다 작업을 수행
@Scheduled(cron = "0 * * * * *")
@Transactional
public void syncFeedViewsToDb() {
Set<String> keys = redisTemplate.keys(FEED_VIEW_COUNT_PREFIX + "*");
if (keys.isEmpty()) { // Redis에 담긴 변경사항이 없는 경우 작업 종료
return;
}
// Redis에 담긴 값을 순회하며 쌓인 조회수를 UPDATE 쿼리로 반영 (동기화)
keys.forEach(redisKey -> {
Long feedId = Long.parseLong(redisKey.replace(FEED_VIEW_COUNT_PREFIX, ""));
long redisViewCount = Optional.ofNullable(redisTemplate.opsForValue().get(redisKey))
.orElse(0L);
if (redisViewCount > 0) { // 0 이상의 조회수가 쌓인 경우 동기화
syncViewCount(redisKey, feedId, redisViewCount);
}
});
}
private void syncViewCount(String redisKey, Long feedId, long redisViewCount) {
feedRepository.incrementViewCount(feedId, redisViewCount); // DB에 조회수 증가
redisTemplate.delete(redisKey); // Redis에서 해당 키 삭제
}
}아래는 Redis와 Scheduling 관련 구성이에요.
// Redis
@Configuration
public class RedisConfig {
public static final String FEED_VIEW_COUNT_PREFIX = "feed:view:";
@Bean
LettuceConnectionFactory connectionFactory() {
return new LettuceConnectionFactory();
}
@Bean
public RedisTemplate<String, Long> redisTemplate(LettuceConnectionFactory connectionFactory) {
RedisTemplate<String, Long> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new GenericToStringSerializer<>(Long.class)); // 조회수가 Long 타입
return template;
}
}
// 스케줄링
@Configuration
@EnableScheduling
public class SchedulingConfig {
}즉, 피드만 실시간으로 가져와서 조회하고 조회수는 추후에 반영하는 방법이에요. (특정 시간마다 동기화를 진행하거나, 특정 값을 넘기면 동기화를 진행하거나 여러 방법이 있을 수 있어요.)
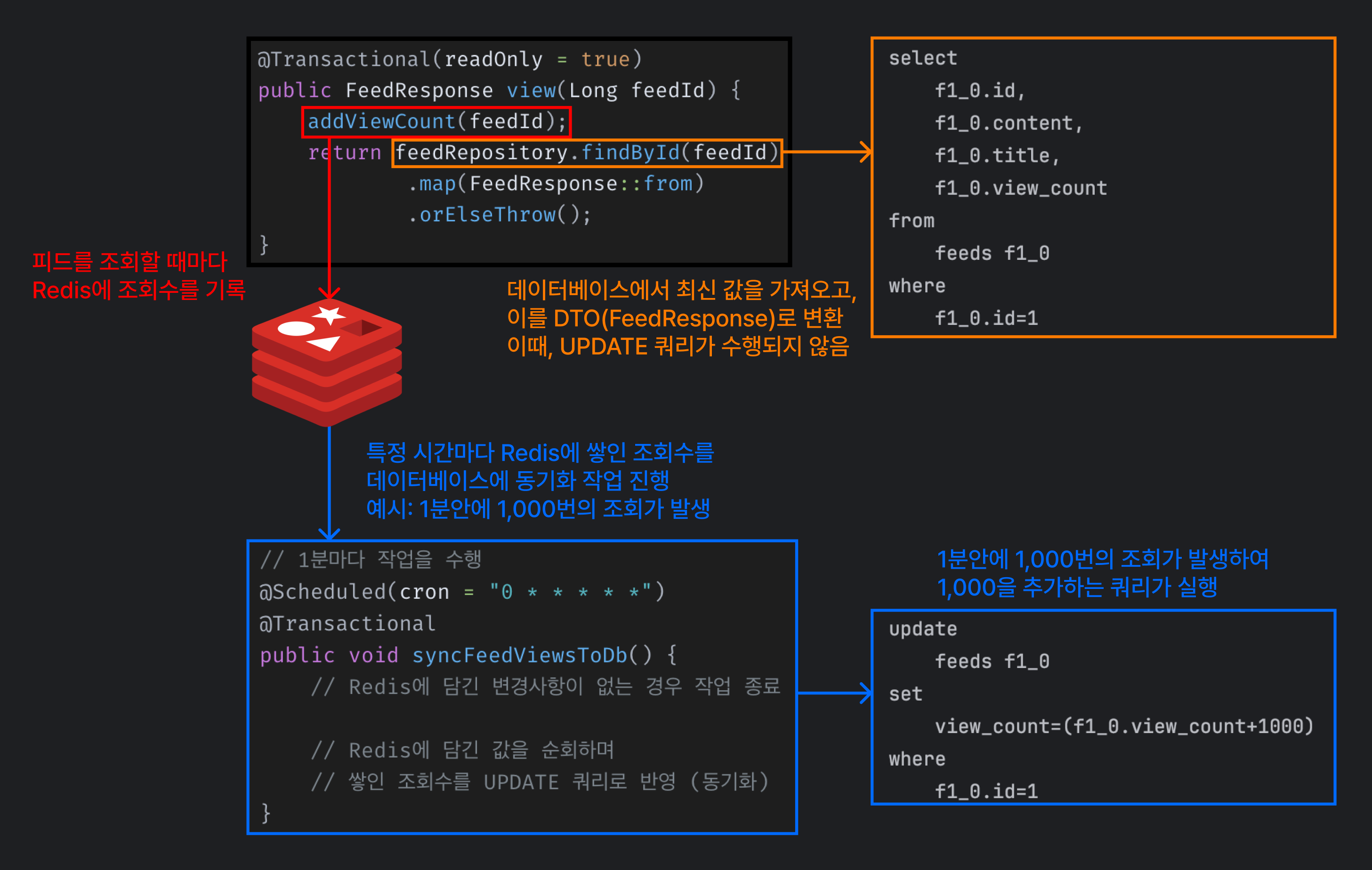
피드를 조회할 때 조회수 추가를 위한 UPDATE 쿼리가 발생하지 않는다는 것이 장점이에요. (특히 UPDATE 쿼리의 정합성을 위해 비교적 많은 시간이 필요했기 때문이에요.)
그러나 이 방법에도 단점이 있어요.
-
실시간성 부족: 만약 코드 예시처럼 1분마다 동기화를 진행한다면, 글을 작성하자마자 1,000명의 사용자가 글을 조회하는 경우 해당 사용자들은 모두 조회수를 0(또는 클라이언트 상에서 +1을 시켜주는)으로 보게 돼요. 조회수 자체가 사용성에 크게 민감하지 않다면 괜찮을 수 있어요.사용성을 위해 더 짧은 주기로 동기화를 수행하거나, 일정 수의 조회수가 누적되었을 때 동기화를 트리거하는 방법도 가능할 것 같아요.
-
캐시 서버에 문제가 생긴 경우 정합성: 데이터베이스에서 조회할 때마다 Redis에 흔적을 남겨둬요. 이때 만약 Redis 서버에 문제가 생겨 종료된다면 그동안 쌓인 (동기화 되지 못한) 조회수들은 사라져요.Redis 서버에 장애가 발생했을 때 동기화를 일시적으로 중단하고 조회수 증가가 DB에 반영되도록 구현하고, 복구된 후 동기화 작업을 다시 수행하게 하는 방법으로 해결할 수 있을 것 같아요.
-
복잡성 증가: Redis 서버를 별도로 구축하거나 스케줄링, 관련 구현 작업이 필요해요. 현재 상황에서 조회 성능 이슈(속도 등)가 발생하지 않는다면 굳이 복잡성을 늘릴 필요가 있을까요?
성능 확인
살펴본 방식들을 정합성, 속도 측면에서 확인해 보려고 해요.
k6를 사용했고, 간단한 스크립트를 작성했어요. 사용 방법 참고 블로그
import http from "k6/http";
import { sleep } from "k6";
export let options = {
vus: 1000, // 1,000명의 가상 유저
duration: "1m", // 테스트 진행 시간 1분
};
export default function () {
let getUrl = "http://localhost:8080/feeds/1"; // 요청할 URL
// GET 요청을 보냄
http.get(getUrl);
// 1초 동안 기다림 (이 시간 동안 테스트가 계속 진행됨)
sleep(1);
}테스트 환경의 차이도 무시할 수 없기 때문에 가볍게 비교만 해보는 느낌으로 테스트를 진행해봤어요. 최대한 같은 환경에서 시도하려고 노력했어요.
- 데이터 정합성은 (실행된 요청 - 실패한 요청)과 데이터베이스의 조회수 필드의 값을 비교했어요.
가장 간단한 방식
JPA의 findById() 메서드를 사용하여 조회하고 단순히 조회수 필드를 증가시키는 방식이에요.
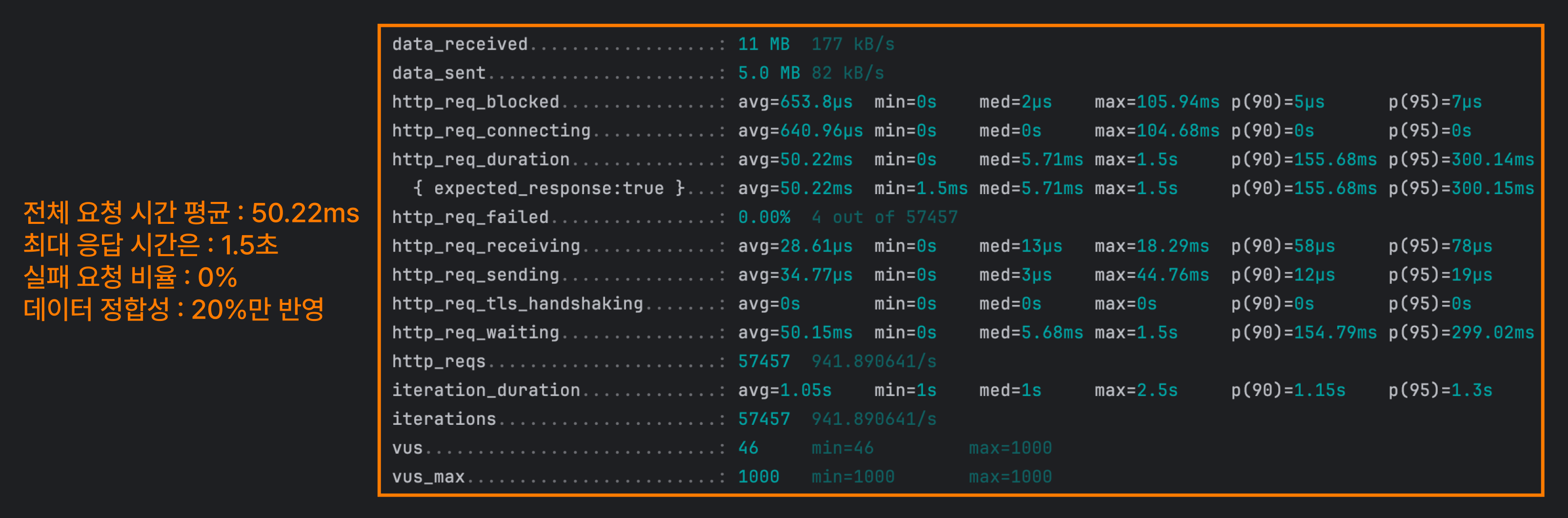
동시성 문제를 신경쓰지 않기 때문에 요청 속도가 빠른 편이에요. 다만 정합성 문제가 크기 때문에 선택하기 어려워요.
비관적 락
FOR UPDATE를 사용하여 읽기 쓰기 잠금을 사용하는 방식이에요.
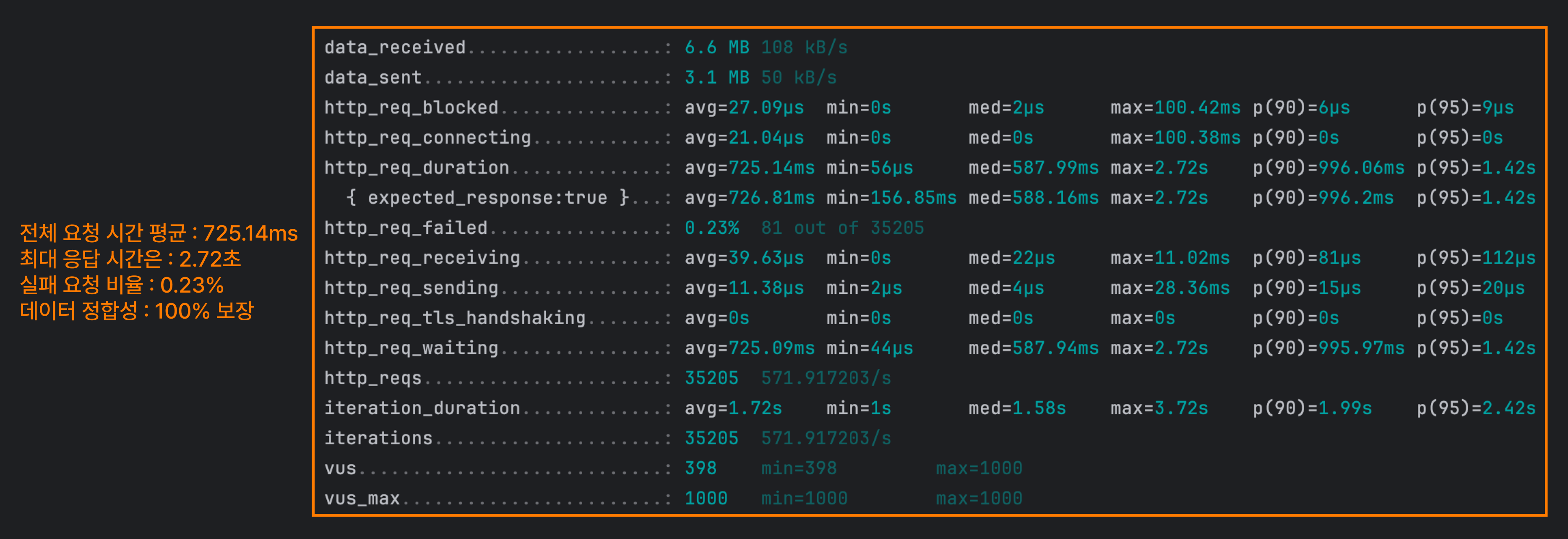
기존 방식보다 속도가 확실히 느려진 것을 볼 수 있어요. 다른 방식들과 비교하면 데이터 정합성에 올인한 케이스라고 볼 수 있어요.
낙관적 락
@Version을 사용하여 UPDATE 쿼리가 실행될 때 충돌을 확인하고, 충돌인 경우 재시도하는 방식이에요.
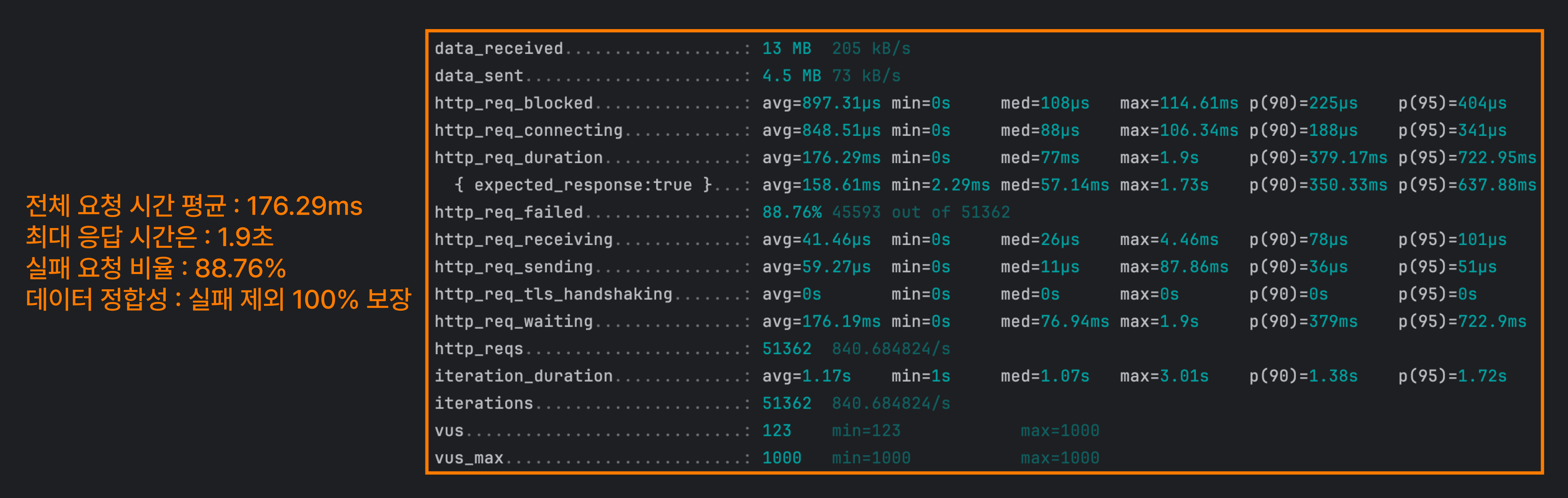
실패율이 매우 높은 것을 볼 수 있는데, 버전 차이로 예외가 발생했을 때 처리하는 로직에 문제인 것 같았어요. 그래도 확실히 읽기 쓰기 잠금을 거는 비관적 락보다는 빨라진 것을 볼 수 있어요.
직접 수정 쿼리를 작성하는 방식
@Modifying과 JPQL을 사용하여 원자적인 수정 쿼리를 실행하고 조회하는 방식이에요.
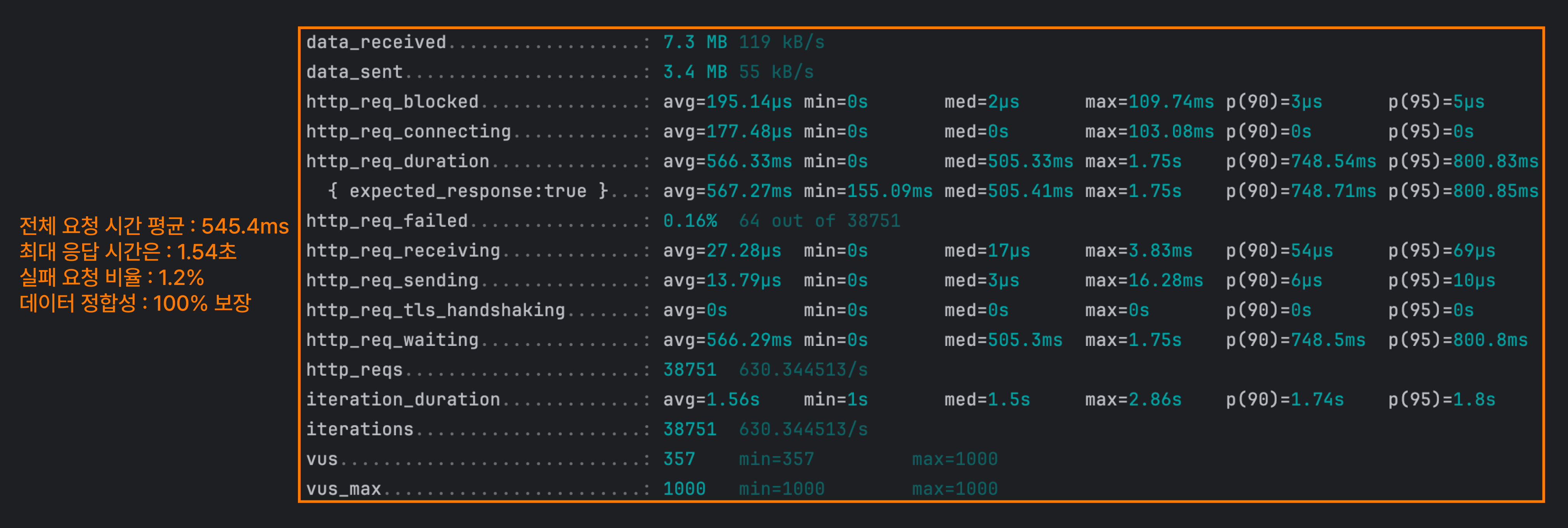
비관적 락과 낙관적 락의 중간 정도의 속도를 보여줬어요. 또한 실패율이 매우 낮은 편이에요. 추가로 데이터 정합성은 100% 보장된 것을 확인할 수 있었어요.
Redis 방식
일반적인 조회 쿼리만 실행하고 Redis에 조회수 정보를 남겨두는 방식이에요. 이후 일정 시간(또는 이벤트)마다 데이터베이스에 동기화해서 정합성을 맞추도록 구현해요.
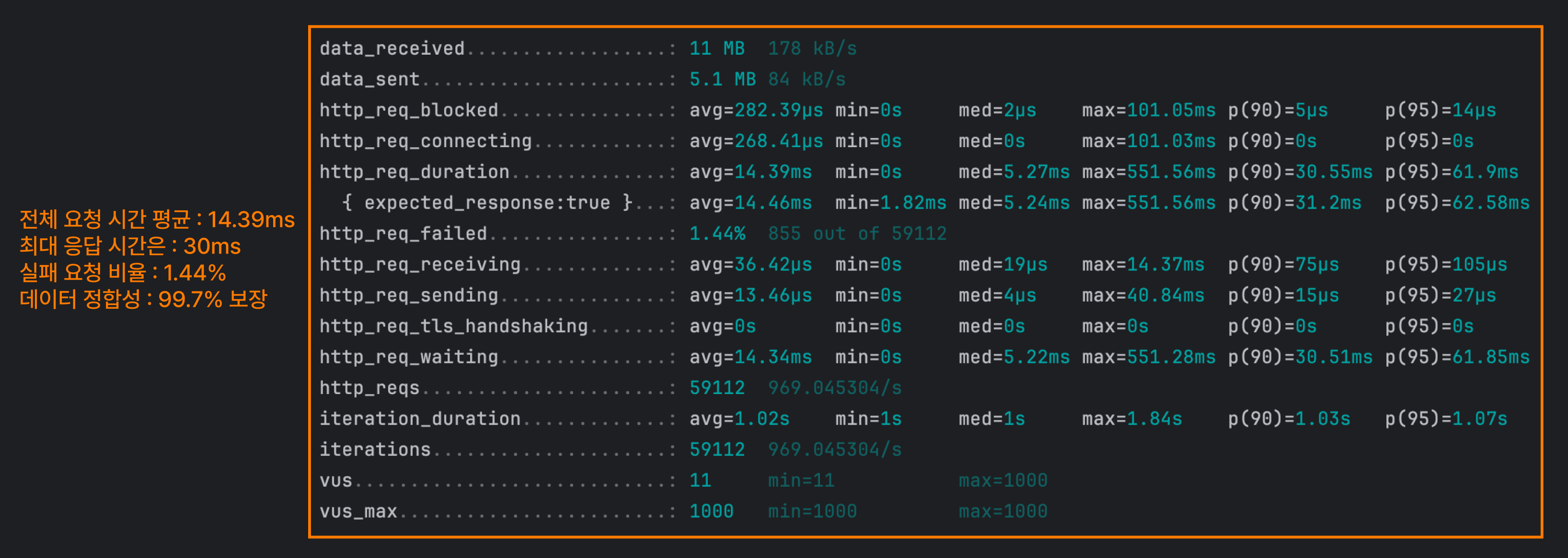
평균 요청 시간이 압도적으로 빠른 것을 볼 수 있어요. 아무래도 수정 쿼리나 수정 쿼리 시 정합성을 위한 작업을 진행하지 않기 때문인 것 같아요. 그러나 어떤 이유인지는 모르겠으나 테스트 환경에서 데이터 정합성이 완벽히 보장되지 않았어요.
(작성 후 추가 내용) 테스트 시 Redis 정합성 문제가 발생한 이유를 살펴보려고 해요.
Reids 방식 과정은 아래와 같아요.
1. Redis에서 조회수 증가 : 사용자가 페이지를 조회하면 Redis에 조회수를 저장(증가)해요.
2. 데이터베이스 수정 : 주기적으로 Redis 데이터를 데이터베이스에 동기화해요.
3. Redis 초기화 : 동기화 후 Redis 데이터를 초기화(삭제)해요.
테스트에서 사용한 간격인 1분이 되어 데이터베이스 동기화 작업 중 Redis 조회수가 추가되면, 해당 조회수는 (동기화 이후에 키를 삭제하기 때문)삭제되면서 데이터 정합성이 깨질 수 있었어요. 또한 테스트 시간도 1분이고 스케줄링이 1분이다 보니까 정확한 시간에 맞춰 끝내지 않는 이상 문제가 발생했던 것 같아요.
그렇다면 어떻게 해결할 수 있을까요?
데이터베이스를 동기화하고 키를 제거하는 방법 대신 조회수만큼 차감하는 방식이라면 정합성을 지킬 수 있어요.
초기 Redis 조회수를 = 10이라고 가정할게요.
1. 데이터베이스 수정 작업을 시작해요.
2. 수정 작업 중 Redis에서 추가 조회가 발생한다고 가정해요.(+3 → Redis 조회수 = 13)
3. 수정 완료 후 데이터베이스에 10을 저장(Update)하고 Redis에서 -10을 차감해요.(Redis 조회수 = 3).
결과적으로 추가된 조회수(+3)는 Redis에 살아있어요.
private void syncViewCount(String redisKey, Long feedId, long redisViewCount) {
// 1. 데이터베이스에 Redis 조회수만큼 증가
feedRepository.incrementViewCount(feedId, redisViewCount);
// 2. Redis에서 증가된 조회수 차감
redisTemplate.opsForValue()
.decrement(redisKey, redisViewCount);
}코드를 변경하고 동일한 환경에서 여러 번 테스트를 진행했을 때 데이터 정합성을 지킬 수 있었어요. 조회 성능이 가장 좋기 때문에 이 방법을 다시 고려하게 되었어요.
정리
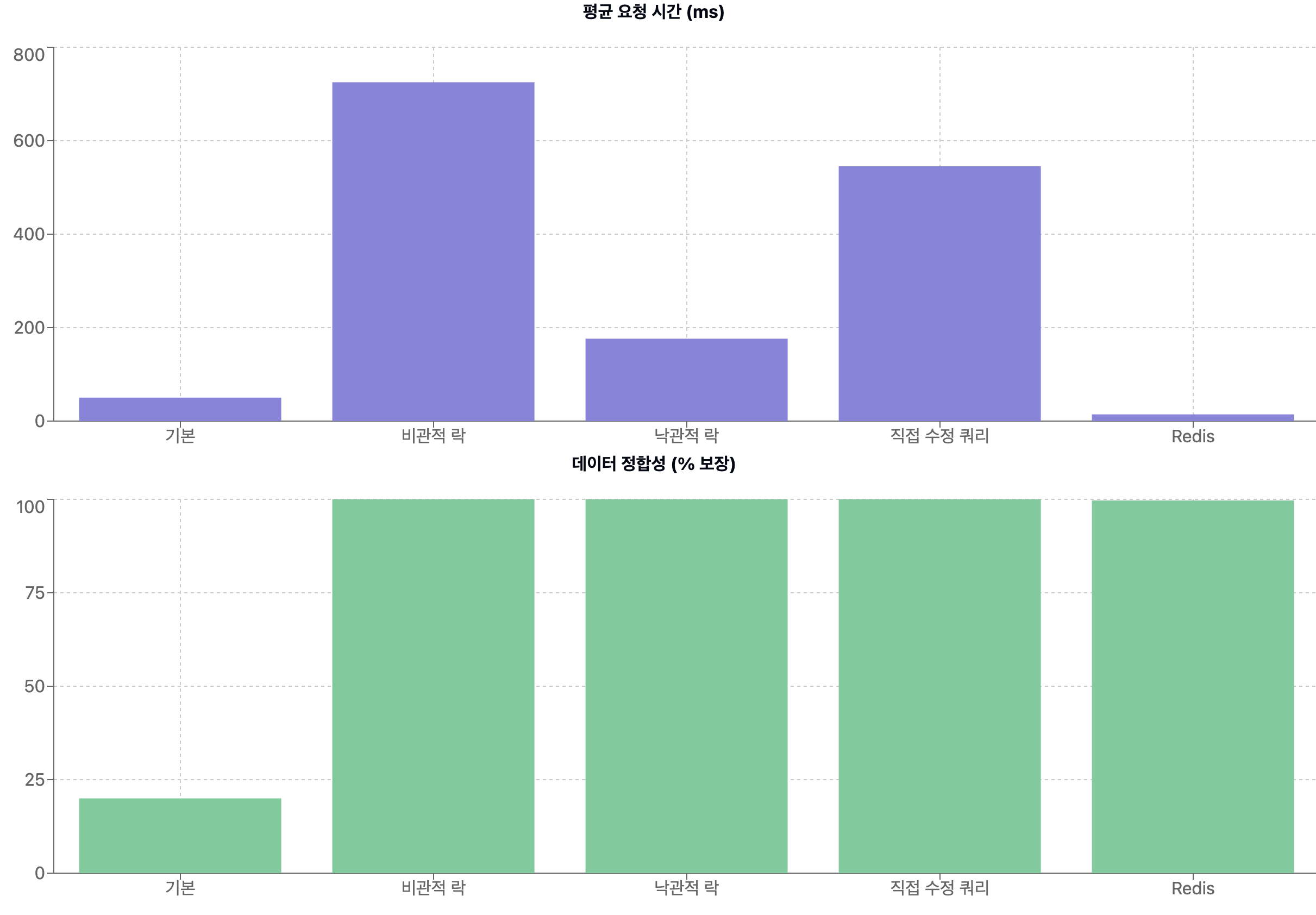
기본 방식은 동시성 문제를 전혀 제어하지 않기 때문에 사용성을 생각해서 사용하지 않을 것 같아요.
비관적 락은 동시성 문제를 매우 강력하게 처리하지만 그만큼 요청 속도가 줄어들기 때문에 피드 구현 정도라면 저는 사용하지 않을 것 같아요. (충분히 정합성을 지킬 수 있는 방식이 있었기 때문이에요.)
낙관적 락은 조회 성능도 준수하고, 프로젝트 규모나 특성상 동시에 피드를 조회하는 경우가 적다면 충분히 좋은 전략이 될 것 같아요. 물론 저는 높은 실패율을 보였지만, 낙관적 락 방식에서 버전 차이로 수정 작업 시 발생한 예외를 처리하는 로직을 잘 구현한다면 좋은 방식이 될 것 같아요.
직접 수정 쿼리를 작성한 방식은 비교적 무난한 방식 같아요. 매우 쉽게 구현할 수 있고, 현재 규모에서 속도도 느리지 않고, 테스트 환경에서 정합성을 100% 보장했기 때문이에요.
현재 상황에서 조회 성능의 향상이 중요하다면 Redis 방식을 사용하는 것이 좋을 것 같아요. 물론 Redis 서버의 장애가 생길 수 있기 때문에 안정성을 위해 이에 대한 구현도 필요해요. (데이터 정합성 부분도 체크가 필요해요.) 또한, 복잡도가 상승한다는 것도 충분히 고려가 필요할 것 같아요. (장애 포인트가 늘어난다는 것은 할 일이 늘어나기 때문이에요. 해당 정보가 프로젝트에 중요한지 검토가 필요할 것 같아요.)
저희 팀은 우선 직접 수정 쿼리를 작성해서 실행하는 방식으로 사용하기로 했어요.
왜 선택했나요?
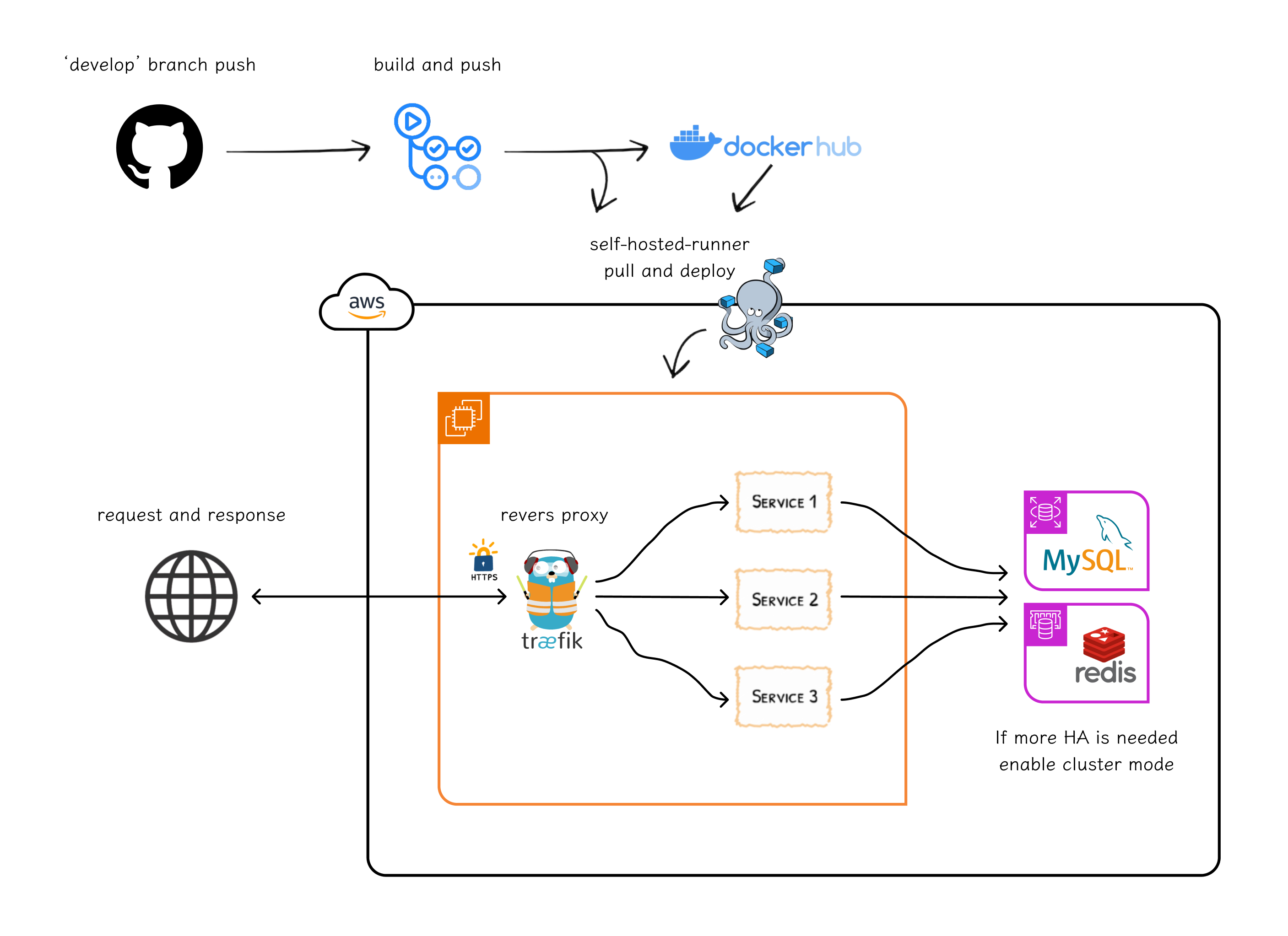
이미 사용자의 세션 정보를 위해 Redis 서버를 사용하고 있어요. 조회수를 위해 다른 Redis 서버를 사용하려면 추가적인 비용 문제가 발생하고, 실제 사용자가 없기 때문이에요. 추가로 사용자 세션을 담고 있는 Redis 서버에 조회수 필드도 함께 저장하는 방식도 고민해 봤지만, 더 빠른 응답 속도가 필요하다고 느낀 상황이 아니라 복잡성을 낮추고 적당한 조회 성능을 선택했어요.
여러 개념이나 적용 방법, 테스트 방식 등이 사실과 다를 수 있어요. 혹시 발견하신다면 댓글 부탁드려요.
추가
현재는 교내 LMS처럼 게시글을 조회할 때마다 조회수가 증가해요.

이 방식은 부정확한 인기 지표를 나타낼 가능성이 있으며, 사용성에 영향을 줄 수 있어요. 이를 개선하기 위해 쿠키와 만료 시간을 활용하여 12시간(혹은 하루) 동안 동일 사용자의 반복 조회가 조회수 증가에 영향을 주지 않도록 구현해 볼 예정이에요.
긴 글 읽어주셔서 감사합니다.
참고

18개의 댓글




"직접 수정 쿼리를 작성하는 방식" 에서 실패한 케이스는 무엇을 의미하는 걸까요? 내부 로직 상 어느 구간에서 실패한 건지 궁금합니다.

redis에 저장된 값을 바로 사용하지 않고, db에 다시 업데이트해서 사용하는 이유가 뭔지 알 수 있을까요? redis에서 고가용성을 확보한다면 db와 redis 사이의 처리하는 복잡한 과정을 단순화하지 않을까 싶어요


와, 이거 엄청 오래 걸리셨겠는데요..? ㄷㄷ
동시성 문제에 대한 해결을 여러 방면에서 고민해보며 해결한 흔적이 있어서 깔끔하게 잘 봤습니다!

조회수 지표가 정말 중요한(유튜브처럼 수익과 직결되는) 서비스가 아니라면, Redis 같은 캐시를 활용해 실시간 정합성은 포기하되 조회 속도를 높이는 쪽이 낫겠네요!