
분산 추적 디버깅
마이크로서비스는 본질적으로 분산되어 있기 때문에 문제가 발생한 위치를 디버깅하는 것은 매우 번거로운 작업이다. 분산된 서비스의 특징은 여러 서비스와 물리 머신, 다양한 데이터 저장소에 걸쳐 단일 또는 복수 트랜잭션을 추적한 후 정확히 상황을 종합하려고 노력해야 한다는 것이다.
이번 시간에는 분산 디버깅을 위한 기술과 기법을 살펴보자.
-
스프링 클라우드 슬루스(Sleuth) : 스프링 클라우드 프로젝트는 유입되는 HTTP 요청을 상관관계 ID라고 알려진 추적ID(traceID)로 측정한다. 이 작업을 위해 필터를 추가하고 다른 스프링 컴포넌트와 상호작용하여 생성된 상관관계ID를 모든 시스템에 호출한다
-
집킨(Zipkin) : 집킨은 여러 서비스 간의 트랜잭션 흐름을 보여 주는 오픈 소스 데이터 시각화 도구다. 집킨을 사용하면 트랜잭션을 컴포넌트별로 분해하고 성능 병목점을 시각적으로 확인할 수 있다.
-
ELK 스택 : ELK 스택은 세개의 오픈 소스 도구인 일레스틱서치, 로그스태시, 키바나를 결합하여 실시간으로 로그를 분석, 검색, 시각화 할 수 있다
- 일레스틱서치(Elasticssearch)는 모든 유형의 데이터(정형, 비정형, 숫자, 텍스트 기반 데이터 등)를 위한 분산 분석 엔진이다.
- 로그스태시(logstash)는 여러 소스의 데이터를 동시에 추가 및 수집하고 일레스틱서치에서 인덱싱 되기 전에 로그를 변환할 수 있는 서버 사이드 데이터 프로세싱 파이프라인이다
- 키바나(Kibana)는 일레스틱서치용 시각화 및 데이터 관리 도구이며 차트와 맵, 실시간 히스토그램을 제공한다.
이를 활용하여
1) 상관관계 ID를 사용하여 여러 서비스 간 트랜잭션 연결
2) 다양한 서비스에서 전송된 로그 데이터를 검색 가능한 단일 소스로 수집
3) 트랜잭션 성능 특성의 각 부분을 이해하고자 여러 서비스간 사용자 트랜잭션 흐름을 시각화
4) ELK 스택을 이용한 실시간 로그 데이터 분석, 검색, 시각화
를 구현해보고자 한다.
스프링 클라우드 슬루스와 상관관계 ID
이전 장에서 스프링 클라우드 게이트웨이 필터를 사용하여 유입되는 모든 HTTP 요청을 검사하고 상관관계 ID가 없을 때는 요청에 삽입하도록 하고,
상관관계 ID가 요청에 존재하면 각 서비스에서 스프링 HTTP 필터를 사용자가 정의해서 유입된 변수를 UserContext 객체에 매핑하여 수동으로 로그를 확인했다.
또한 아웃바운드 호출의 HTTP 헤더에 상관관계 ID를 추가하여 서비스의 모든 HTTP 호출에 상관관계 ID가 전파되도록 스프링 인터셉터도 작성했다.
스프링 클라우드 슬루스는 이러한 모든 코드 인프라스트럭처와 복잡성을 관리해 준다.
아래는 진행하고자하는 서비스들의 소스를 참고할 깃헙 주소이다.
https://github.com/hyeokjinON/microservice_study/tree/master/chapter11
라이선싱 및 조직 서비스에 스프링 클라우드 슬루스 추가
pom.xml
<dependency>
<groupId> org.springframework.cloud </groupId>
<artifactId> spring-cloud-starter-sleuth</artifactId>
</dependency>스프링 클라우드 슬루스 추적 분석
스프링 클라우드 슬루스를 이용해 추적 정보를 조직 서비스에서 출력되는
로그를 살펴보자
(이 데이터는 사용자 요청에 대한 서비스 호출을 연결하는 데 효과가 있다)
아래 호출을 해보자
http://localhost:8072/organization/v1/organization/e839ee96-28de-4f67-bb79-870ca89743a0
organization-service | 2022-08-20 16:08:59.296 DEBUG [organization-service,5b931c61cc4e430a,bca4792d986927b0,true] 1 --- [nio-8081-exec-9] c.o.o.controller.OrganizationController : Entering the getOrganization() method for the organizationId: e839ee96-28de-4f67-bb79-870ca89743a0-
애플리케이션 이름 : organization-service (로깅되는 서비스 이름)
-
추적 ID : 5b931c61cc4e430a (사용자 요청에 대한 고유 식별자이며 해당 요청의 모든 서비스 호출에 전달된다.)
-
스팬 ID : bca4792d986927b0 (사용자 요청 내 한 세그먼트에 대한
고유 식별자다. 여러 서비스 간 호출에서 사용자 트랜잭션 내 서비스 호출당 하나의 스팬 ID가 할당된다.) -
집킨 전송 여부 : true (추적을 위해 집킨 서버에 데이터를 전송할지 여부 플래그이다. 여기서는 설정을 미리 해논상태다)
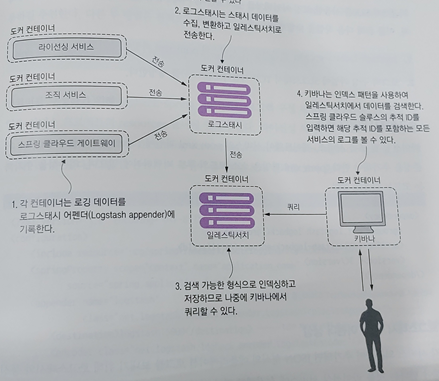
동작하는 스프링 클라우드 슬루스/ELK 스택 구현
이제 슬루스와 ELK 스택으로 구현을 해보자 다음과 같은 작업을 수행한다.
- 서비스에서 로그백을 구성한다.
- 도커 컨테이너에서 ELK 스택을 정의하고 실행한다.
- 키바나를 구성한다.
- 스프링 클라우드 슬루스에서 생성된 상관관계 ID 기반으로 쿼리를 실행하여 구현을 테스트 한다.
아래와 같은 ELK 스택으로 통합 로깅 아키택처를 빠르게 구현할 수 있다.
서버에서 로그백 구성
- logstash-logback-encoder 의존성을 각 서비스의 pom.xml 파일에 추가
- 로그백 구성 파일에 로그스태시 TCP 어펜더 생성(3가지 방법)
1) logstashEncoder 클래스 사용
2) loggingEventCompositeJsonEncoder 클래스 사용
2) 로그스태시로 일반 텍스트 로그 데이터 파싱
라이선싱 및 조직 서비스, 게이트웨이 서비스 pom.xml에 추가한다
pom.xml
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.3</version>
</dependency>이 예 에서는 로그백에 1) logstashEncoder 클래스 사용한다
로그백은 프로젝트의 resource 폴더에 있어야 한다.
logback_spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/base.xml"/>
<springProperty scope="context" name="application_name" source="spring.application.name"/>
<!-- 로그스태시와 통신하려고 TcpSocketAppender를 사용한다 -->
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!-- TCP 통신을 위한 로그스태시 호스트 이름과 포트 번호다. -->
<destination>logstash:5000</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="logstash"/>
<appender-ref ref="CONSOLE"/>
</root>
<logger name="org.springframework" level="INFO"/>
<logger name="com.optimagrowth" level="DEBUG"/>
</configuration>LogstashEncoder로 형식을 맞춘 애플리케이션 로그를 보면 LogstashEncoder가 기본적으로 스프링 MDC 로거에 저장된 모든 값을 포함하고, 슬루스 의존성을 서비스에 추가했기 때문에 traceID, X-B3-traceID, spanID, X-B3-spanID, spanExportable 필드가 로그에 포함되어 나온다. ( X-B3로 시작하면 스프링 클라우드 슬루스가 사용하는 기본 헤더를 서비스간 전파한다는 뜻이다 )
도커에서 ELK 스택 애플리케이션 정의 및 실행
ELK 스택 컨테이너를 설정해보자
- 로그스태시 구성 파일 만들기
- 도커 구성안에 ELK 스택 애플리케이션 정의
그 전에 로그스태시 파이프라인을 보면 두 개의 필수 엘리먼트와 한 개의 선택적 엘리먼트가 포함한다는 것을 알아야한다
필수 엘리먼트 :
- input(특정 이벤트 소스를 읽을 수 있다. 깃허브, HTTP, TCP, 카프카 등 입력 플러그인이다)
- output(이벤트 데이터를 특정 목적지로 보내는 역할을 한다. CSV, 일레스틱서치, 이메일, 파일, 몽고DB, 레디스, stdour 등 다양한 플러그인을 지원한다.)
선택 엘리먼트 :
- filter(변환, 새 정보 추가, 날짜파싱, 필드 줄이기등 이벤트에 대한 중간 처리 수행)이제 로그백 TCP 어펜더(LogstashEncoder 이용) 를 input 플러그인으로 사용하고
일레스틱서치 엔진을 output 플러그인으로 사용하는 구성 파일을 추가하자.
해당 파일은 도커 컴포즈가 위치하는 상위폴더 docker/cofig/logstash.config 에 넣었다
logstash.config
input {
<!-- TCP 소켓에서 이벤트를 읽어 오는 TCP input 플러그인-->
tcp {
<!-- 로그스태시 포트-->
port => 5000
codec => json_lines
}
}
filter {
<!-- 이벤트에 특정 태그를 추가하는 mutate 필터-->
mutate {
add_tag => [ "manningPublications" ]
}
}
output {
<!-- 일레스틱서치 엔진에 로그 데이터를 보내는 일레스틱 서치 output 플러그인-->
elasticsearch {
<!-- 일레스틱서치 포트-->
hosts => "elasticsearch:9200"
}
}구성 파일을 만들었으니 이제 도커 컴포즈안에 ELK 스택을 구성하자
여기서 중요한 점은 키바나, 일레스틱서치, 로그스태시 모두 같은 버전을 사용해야 한다. 모두 7.12.0으로 셋팅했다.
docker-compose.yml
# 파일 일부 내용 및 구성을 생략한다.
elasticsearch:
# 컨테이너로 만들 일레스틱서치 이미지를 지정한다
image: docker.elastic.co/elasticsearch/elasticsearch:7.12.0
container_name: elasticsearch
environment:
- node.name=elasticsearch
- discovery.type=single-node
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata1:/usr/share/elasticsearch/data
ports:
- 9300:9300 # 클러스터의 통신 포트로 9300 포트 번호에 매핑한다
- 9200:9200 # REST 통신 포트로 9200 포트 번호에 매핑한다.
networks:
backend:
aliases:
- "elasticsearch"
kibana:
# 사용할 키바나 이미지를 지정한다
image: docker.elastic.co/kibana/kibana:7.12.0
container_name: kibana
environment:
# 일레스틱서치 URL를 설정하고 node/transport API로 9300 포트 번호를 지정한다.
ELASTICSEARCH_URL: "http://elasticsearch:9300"
ports:
- 5601:5601 # 키바나 웹 애플리케이션 포트를 매핑한다.
networks:
backend:
aliases:
- "kibana"
logstash:
# 로그스태시 이미지를 지정
image: docker.elastic.co/logstash/logstash:7.12.0
container_name: logstash
command: logstash -f /etc/logstash/conf.d/logstash.conf # 특정 디렉터리와 파일에서(-f 옵션) 로그스태시 구성정보를 로드한다
volumes:
- ./config:/etc/logstash/conf.d # 구성파일을 컨테이너에 실행되는 로그스태시에 마운트한다. (호스트경로:로그스태시 마운트경로 복사)
ports:
- "5000:5000" # 로그스태시 포트를 매핑한다.
networks:
backend:
aliases:
- "logstash"
키바나 구성
키바나에 액세스하려면 웹브라우저에서 http://localhost:5601/ 에 접속해야 한다.
그전에 도커 환경을 실행먼저 하자
// pox.xml 파일경로에서 실행한다.
mvn clean package dockerfile:build
docker-compose -f docker/docker-compose.yml uphttp://localhost:5601/ 접속하면 웰컴페이지가 나온다.
Explore on my own 링크를 클릭하자.
왼쪽 메뉴바를 클릭하고 - Discover 아이콘을 클릭한다.
(키바나 설정 페이지, 키바나 애플리케이션을 구성할 수 있는 옵션을 제공한다)
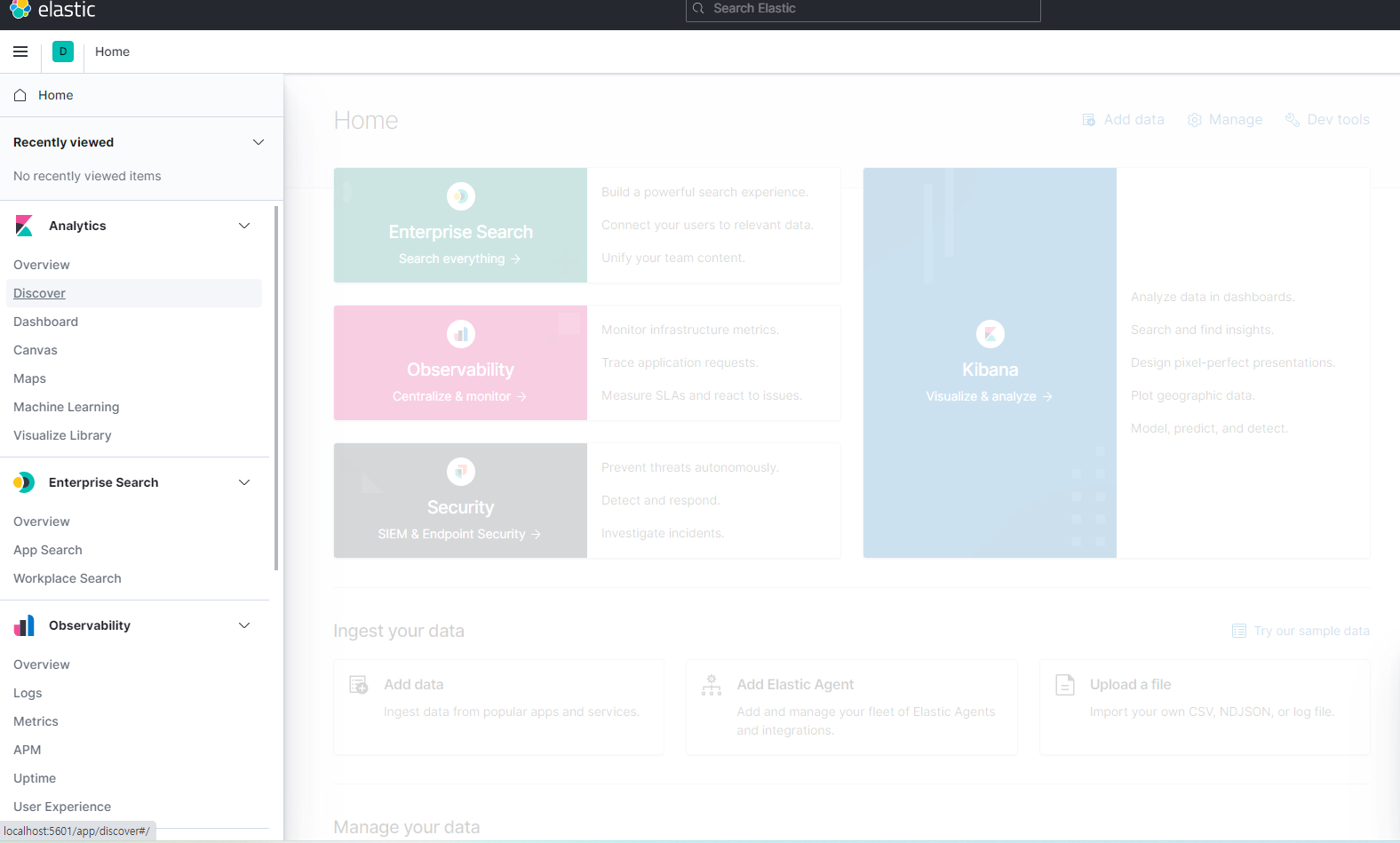
키바나는 일련의 인덱스 패턴을 사용하여 일레스틱서치 엔진에서 데이터를 검색하기 때문에 인덱스 패턴을 생성해야한다.
인덱스 패턴은 탐색하려는 일레스틱서치 인덱스를 키바나에 알려 주는 역할을 한다.
이 예제에서는 일레스틱서치에서 모든 로그스태시 정보를 검색한다는 것을 의미하는 인덱스 패턴을 생성한다.
왼쪽의 키바나 섹션 아래 Index Pattern 링크를 클릭한다.
'Create index pattern' 페이지에서 인덱스 설정을 완료하려면 이 인덱스 패턴을 지정해야한다.
(인덱스 패턴은 logstash-*이다)
인덱스 패턴이 설정되면 오른쪽 버튼을 클릭하여 다음 단계로 넘어가면 된다
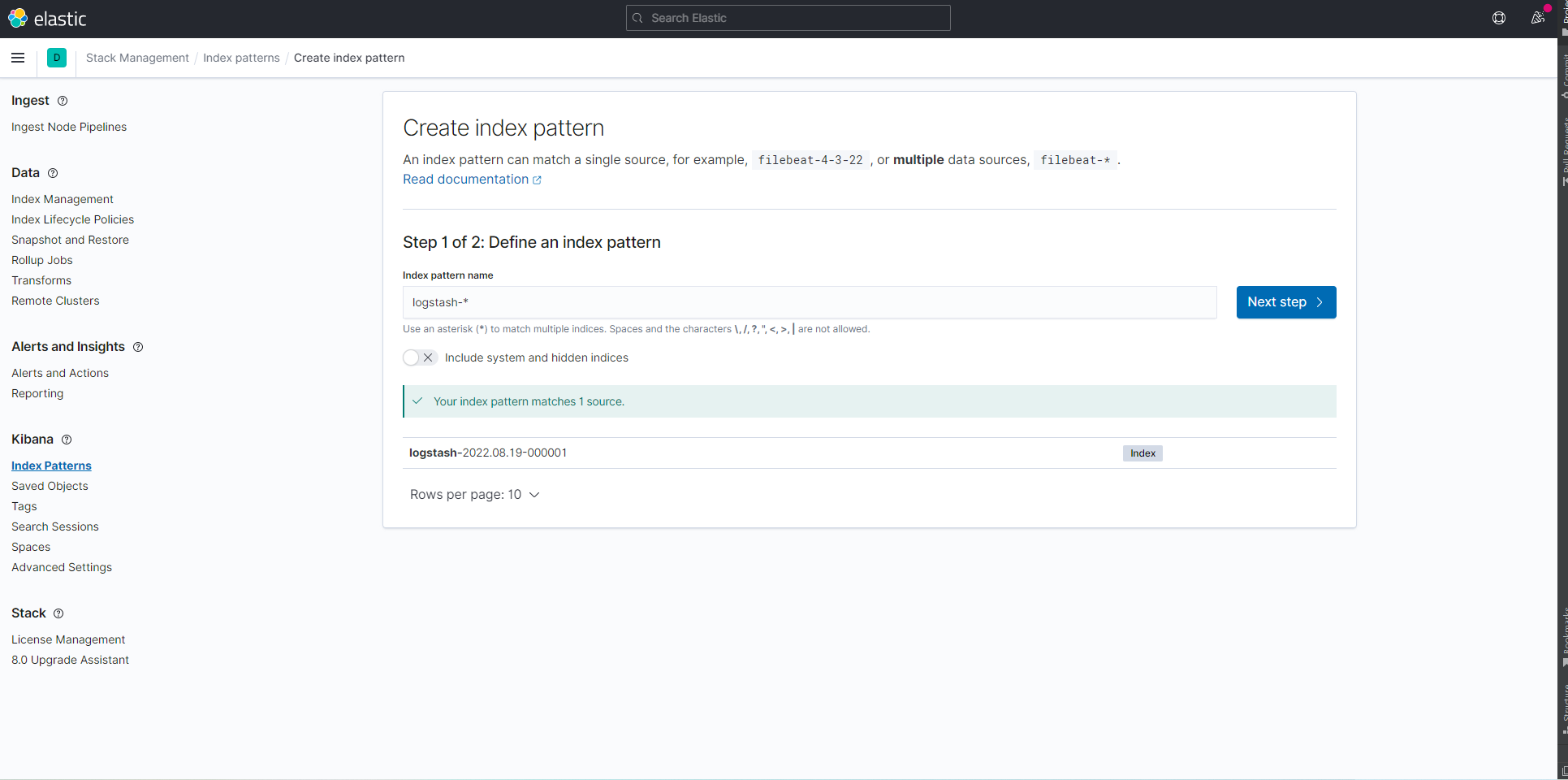
시간 필터를 지정한다. '시간 필터의 필드 이름' 드롭다운 메뉴에서 @timestamp 옵션을 선택한 후 오른쪽 아래 인덱스 패턴 만들기 버튼을 누르면 완료된다.
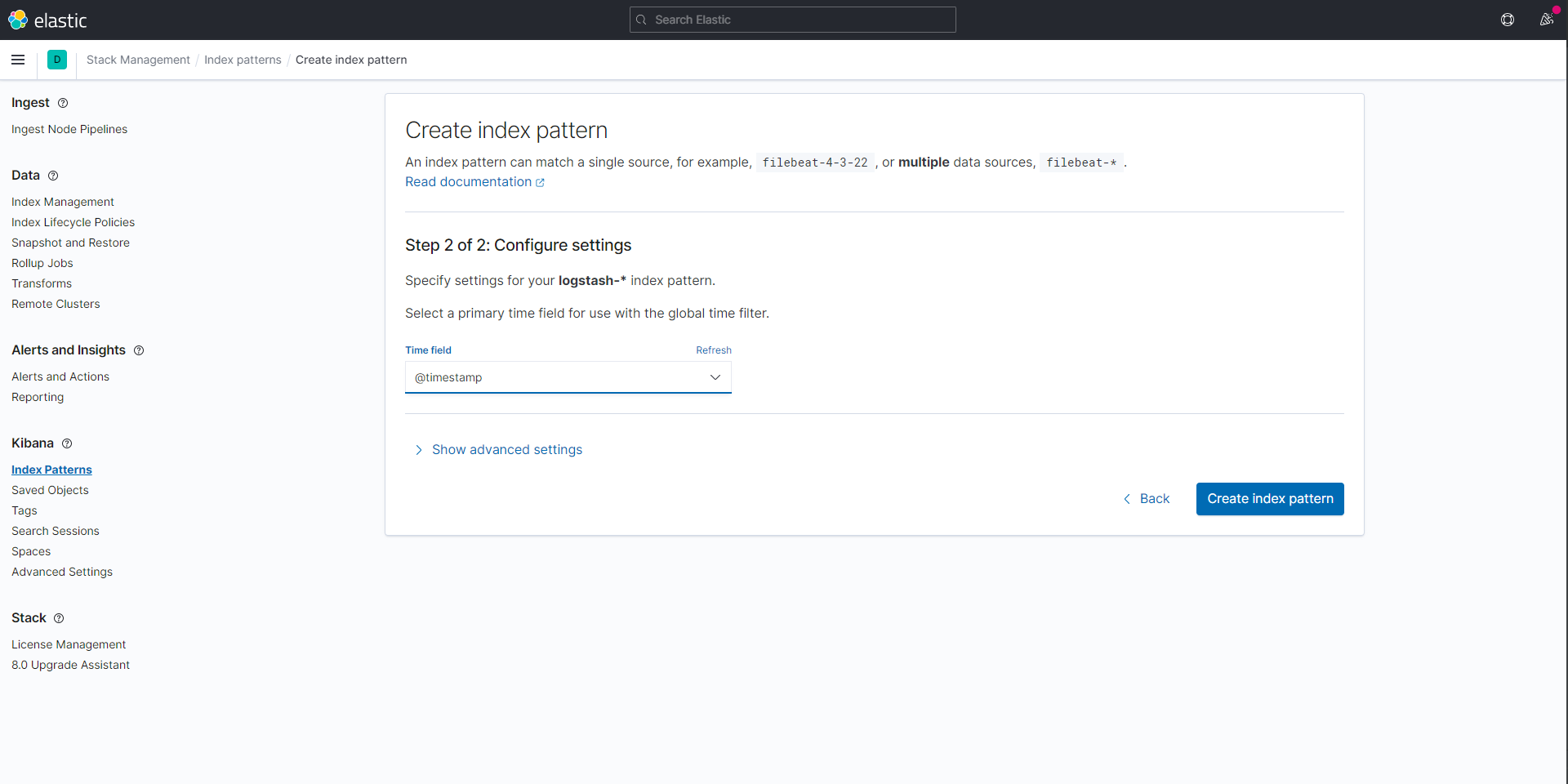
키바나에서 실시간 로그를 보기 위해 서비스에 요청을 보낼 수 있다.
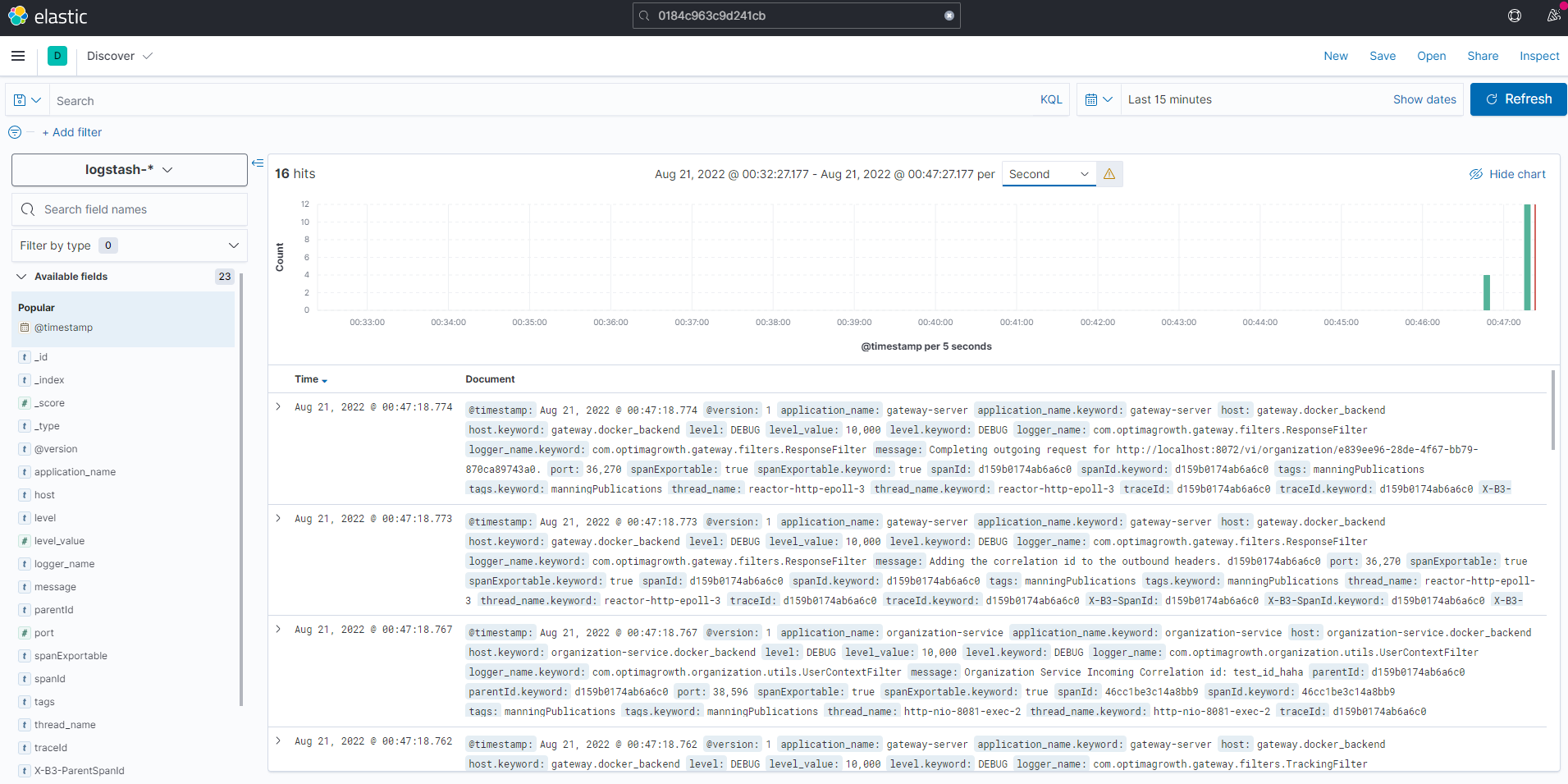
아래 그림은 ELK로 전송된 데이터가 어떻게 표시되는지 보여준다 (메뉴 - Discover 화면이다)
상단의 차트는 Second로 설정 하면 초당 요청수를 볼 수 있고, 하단은 각 로그의 이벤트를 볼 수 있다.
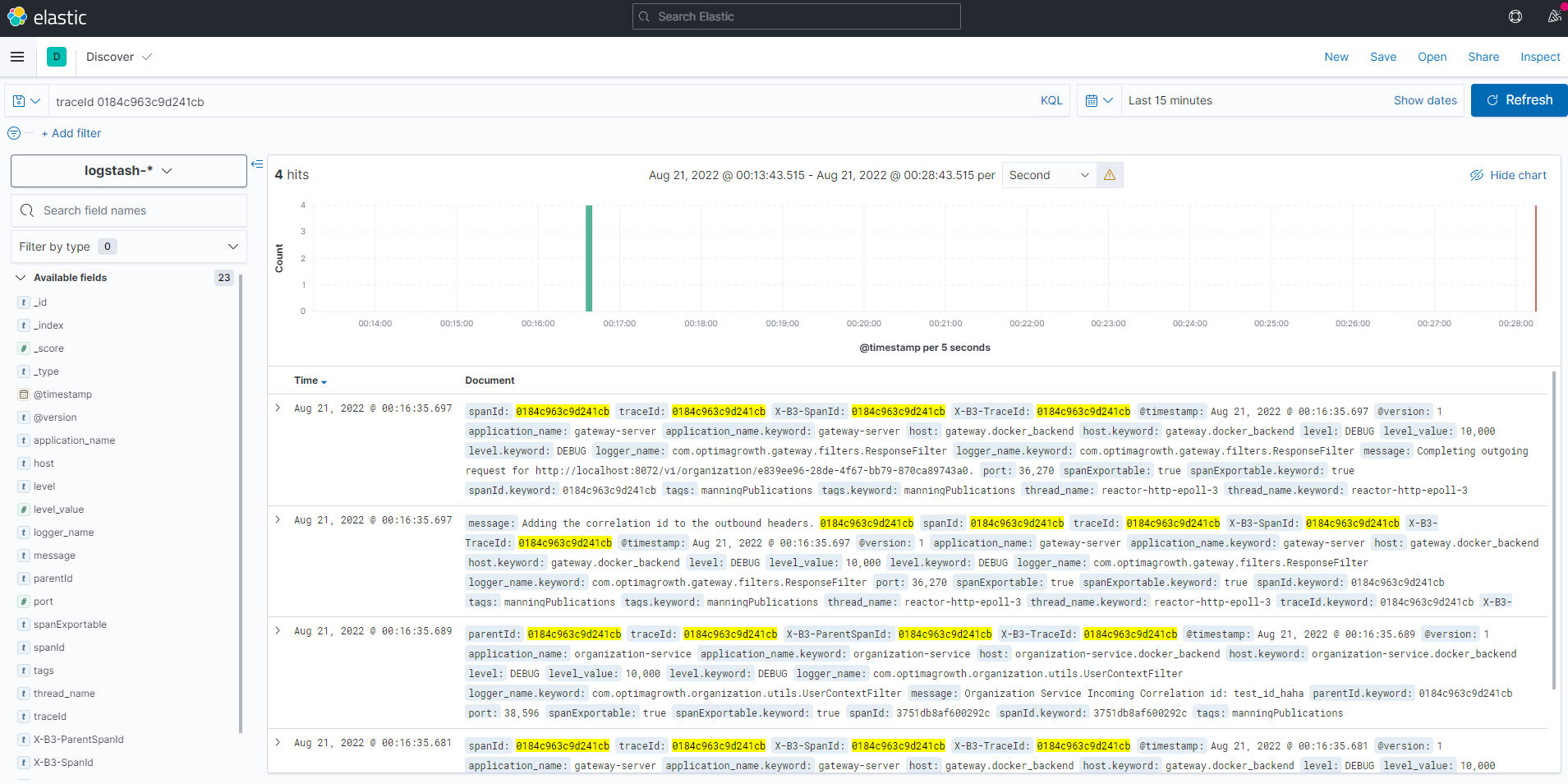
아래는 슬루스의 추적ID로 쿼리한 화면이다
한 트랜잭션과 관련된 모든 로그 항목을 쿼리(조회) 하려면 왼쪽상단에 쿼리할 스프링 클라우드 슬루스의 추적ID를 가져와 쿼리하면 된다.
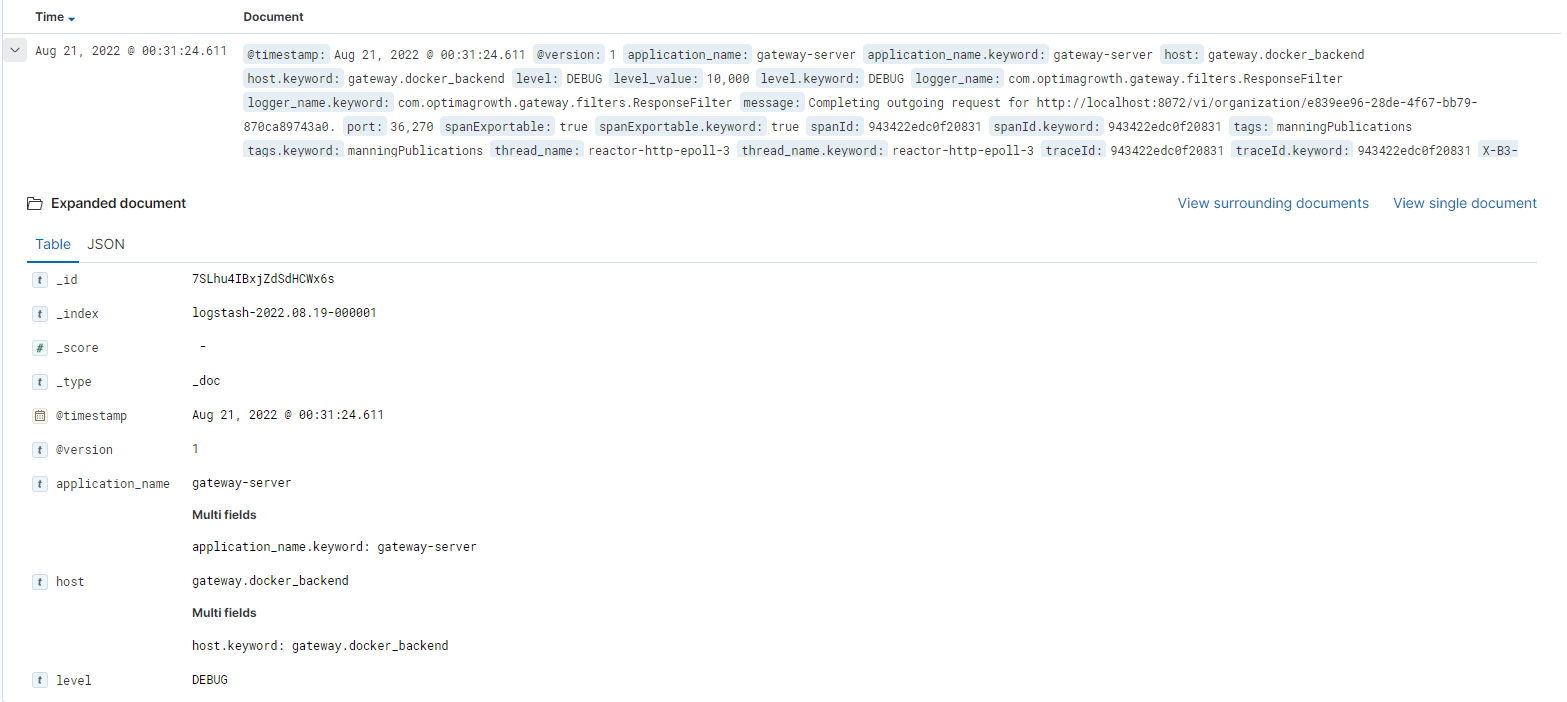
키바나에서 한 로그 이벤트을 클릭하면 상세정보가 표시된다
대표적인 것만 살펴본다
_index : logstash-2022.08.19-000001
(타임스탬프의 인덱스 패턴)
application_name :gateway-server
(스프링 애플리케이션 이름)
logger_name : com.optimagrowth.gateway.filters.ResponseFilter
(Logger 클래스)
spanId : 943422edc0f20831
(스프링 클라우드 슬루스의 스팬 ID)
tags : manningPublications
(로그스태시에 추가했던 태그)
traceId : 943422edc0f20831
(스프링 클라우드 슬루스의 추적 ID)


스프링 클라우드 슬루스를 이용한 서비스 호출의 HTTP 응답을 검사하면 추적ID 가 HTTP에 응답에 반환되지 않는걸 확인할 수 있다. 마지막 추적 데이터를 반환하면 잠재적 보안 문제가 될 수 있다고해서 HTTP 응답에 반환되지 않는다.
하지만 디버깅할 때 HTTP 응답에서 상관관계 또는 추적 ID 반환이 매우 중요하다.
게이트웨이 필터를 작성하여 HTTP 응답에 추적 ID를 삽입하는 방법으로 응답을 확인할 수 있다.
pom.xml
게이트웨이 pom.xml에도 슬로스 의존성을 추가한다.
<dependency>
<groupId> org.springframework.cloud </groupId>
<artifactId> spring-cloud-starter-sleuth</artifactId>
</dependency>응답 필터를 이용하여 스프링 크라우드 슬루스 추적ID를 추가한다
ResponseFilter.java
package com.optimagrowth.gateway.filters;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import brave.Tracer;
import reactor.core.publisher.Mono;
@Configuration
public class ResponseFilter {
final Logger logger =LoggerFactory.getLogger(ResponseFilter.class);
// 추적 ID 및 스팬 ID 정보에 접근하는 진입점 설정
@Autowired
Tracer tracer;
@Autowired
FilterUtils filterUtils;
@Bean
public GlobalFilter postGlobalFilter() {
return (exchange, chain) -> {
return chain.filter(exchange).then(Mono.fromRunnable(() -> {
// 슬루스 추적ID의 응답 헤더 tmx-correlation-id에 스팬을 추가한다
String traceId = tracer.currentSpan().context().traceIdString();
logger.debug("Adding the correlation id to the outbound headers. {}", traceId);
exchange.getResponse().getHeaders().add(FilterUtils.CORRELATION_ID, traceId);
logger.debug("Completing outgoing request for {}.", exchange.getRequest().getURI());
}));
};
}
}이 코드를 적용 후 게이트웨이를 이용하여 서비스를 호출하면
HTTP 응답에는 tmx-correlation-id 헤더와 스프링 클라우드 슬루스의 추적 ID 값이 있는것을 확인할 수 있다
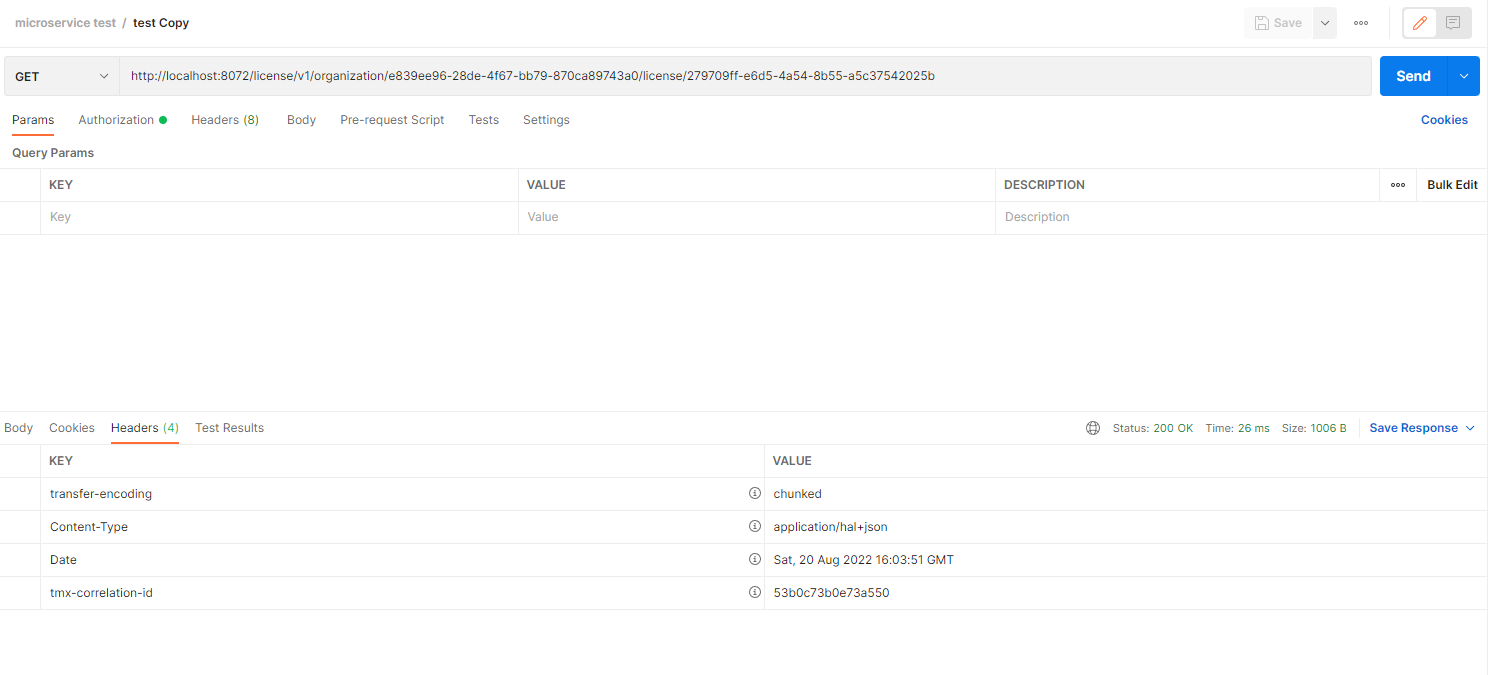
집킨을 사용한 분산추적
집킨을 사용하면 트랜잭션에 소요된 시간을 그래픽으로 확인하고 호출과 관련된 각 마이크로서비스별 소요 시간을 분석할 수 있다.
로그 추적을 벗어나 마이크로서ꈰ스 간 이동하는 트랜잭션 흐름을 시각화 하는 방법을 알아보자
슬루스와 집킨을 설정하는 것은 다음과 같다
- 추적 데이터를 캡쳐하는 서비스에 스프링 클라우드 슬루스와 집킨의 JAR 파일 추가
- 추적 데이터를 수집할 집킨 서버에 접속하도록 각 서비스의 스프링 프로퍼티 구성
- 데이터를 수집하는 집킨 서버 설치 및 구성
- 각 클라이언트가 추적 정보를 전송하는 데 필요한 샘플링 전략 정의
스프링 클라우드 슬루스와 집킨 의존성 설정
라이선싱 및 조직 서비스에 집킨 의존성을 추가한다
pom.xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
집킨 연결을 위한 서비스 구성 설정
조직 및 라이선싱 서비스에 집킨과 통신에 사용되는 URL을 정의하는 스프링 프로퍼티인 spring.zipkin.baseUrl 을 설정
(로컬에서 실행하면 localhost:9411로 설정하지만, 도커로 실행하기 때문에 zipkin:9411로 설정한다)
organization-service.properties, licensing-service.properties
spring.zipkin.baseUrl:http://zipkin:9411집킨 서버 구성
집킨 서버를 실행하려면 약간의 구성 설정이 필요하다.
집킨을 실행할 때 구성해야 하는 몇 가지 중 하나는 추적 데이터를 저장하는 데 사용할 백엔드 데이터 저장소다.
집킨은 다음 네 가지 백엔드 데이터 저장소를 지원한다
- 인메모리 데이터
- MySQL
- 카산드라
- 일레스틱서치
이 예제에서는 일레스틱서치를 구성했기 때문에 일레스틱서치를 데이터 저장소로 사용한다.
도커 컴포즈 구성 파일의 environment 섹션에 있는 STORAGE_TYPE 과 ES_HOSTS 변수를 추가하는 것이다.
도커 컴포즈에 집킨 서버 구성이다
docker-compose.yml
zipkin:
image: openzipkin/zipkin
container_name: zipkin
depends_on:
- elasticsearch
environment:
- STORAGE_TYPE=elasticsearch
- "ES_HOSTS=elasticsearch:9300"
ports:
- "9411:9411"
networks:
backend:
aliases:
- "zipkin"추적 레벨 설정
기본적으로 집킨은 모든 트랜잭션의 10%만 집킨 서버에 기록한다.
각 서비스가 집킨에 데이터를 기록할 빈도를 정의하는 프로퍼티로
spring.sleuth.sampler.percentage 를 설정함으로써 제어할 수 있다.
이 프로퍼티는 0과 1사이의 값을 취한다.
값이 0이면 스프링 클라우드 슬루스가 집킨에 트랜잭션을 전송하지 않는다.
값이 .5이면 스프링 클라우드 슬루스가 집킨에 트랜잭션의 50%를 전송한다.
값이 1이면 스프링 클라우드 슬루스가 집킨에 트랜잭션의 100%를 전송한다.조직 및 라이선싱 서비스 구성파일에 추가하자
organization-service.properties, licensing-service.properties
spring.sleuth.sampler.percentage: 1사용자 정의 스팬
집킨으로 모니터링되지 않는 써드파티 서비스를 추적하는 방법이다.
예를 들어 특정 레디스나 postgres SQL 호출에 대한 추적 및 타이밍 정보를 얻으려고 한다면
슬루스와 집킨을 사용하여 사용자 정의 스팬을 추가하여 써드파티 호출과 관련된 실행 시간을 추적할 수 있다.
라이선싱 서비스의 레디스에서 데이터를 가져오는데 걸린 시간을 추적하는 다음과 같은 코드를 추가한다
(경로는 라이선싱 서비스의 OrganizationRestTemplateClient.java 파일이다)
OrganizationRestTemplateClient.java
package com.optimagrowth.license.service.client;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpMethod;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestTemplate;
import com.optimagrowth.license.model.Organization;
import com.optimagrowth.license.repository.OrganizationRedisRepository;
import com.optimagrowth.license.utils.UserContext;
import brave.ScopedSpan;
import brave.Tracer;
@Component
public class OrganizationRestTemplateClient {
@Autowired
RestTemplate restTemplate;
// Tracer는 스프링 클라우드 슬루스의 추적 정보를 액세스한다.
@Autowired
Tracer tracer;
@Autowired
OrganizationRedisRepository redisRepository;
private static final Logger logger = LoggerFactory.getLogger(OrganizationRestTemplateClient.class);
public Organization getOrganization(String organizationId){
logger.debug("In Licensing Service.getOrganization: {}", UserContext.getCorrelationId());
Organization organization = checkRedisCache(organizationId);
if (organization != null){
logger.debug("I have successfully retrieved an organization {} from the redis cache: {}", organizationId, organization);
return organization;
}
logger.debug("Unable to locate organization from the redis cache: {}.", organizationId);
ResponseEntity<Organization> restExchange =
restTemplate.exchange(
"http://gateway:8072/organization/v1/organization/{organizationId}",
HttpMethod.GET,
null, Organization.class, organizationId);
/*Save the record from cache*/
organization = restExchange.getBody();
if (organization != null) {
cacheOrganizationObject(organization);
}
return restExchange.getBody();
}
// checkRedisCache 메서드는 레디스 캐시를 확인하는 부분이다
private Organization checkRedisCache(String organizationId) {
// readLicensingDataFromRedis 라는 사용자 정의 스팬을 생성한다.
ScopedSpan newSpan = tracer.startScopedSpan("readLicensingDataFromRedis");
try {
return redisRepository.findById(organizationId).orElse(null);
}catch (Exception ex){
logger.error("Error encountered while trying to retrieve organization {} check Redis Cache. Exception {}", organizationId, ex);
return null;
}finally {
// tag 정보를 스팬에 추가하고 집킨이 캡처할 서비스 이름을 지정한다.
newSpan.tag("peer.service", "redis");
newSpan.annotate("Client received");
// 스팬을 닫고 종료한다. 이것을 수행하지 않으면 스팬이 열린 상태라는 오류 메시지 로그가 표시된다.
newSpan.finish();
}
}
private void cacheOrganizationObject(Organization organization) {
try {
redisRepository.save(organization);
}catch (Exception ex){
logger.error("Unable to cache organization {} in Redis. Exception {}", organization.getId(), ex);
}
}
}다음으로 getOrgDBCall 이라는 사용자 정의 스팬을 조직 서비스에 추가하여 Postgres 데이터베이스에서 조직 데이터를 검색하는 데 소요되는 시간을 모니터링한다.
(조직서비스의 OrganizationService.java 파일이다)
OrganizationService.java
package com.optimagrowth.organization.service;
import java.util.Optional;
import java.util.UUID;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.optimagrowth.organization.events.source.SimpleSourceBean;
import com.optimagrowth.organization.model.Organization;
import com.optimagrowth.organization.repository.OrganizationRepository;
import com.optimagrowth.organization.utils.ActionEnum;
import brave.ScopedSpan;
import brave.Tracer;
@Service
public class OrganizationService {
private static final Logger logger = LoggerFactory.getLogger(OrganizationService.class);
@Autowired
private OrganizationRepository repository;
@Autowired
SimpleSourceBean simpleSourceBean;
// tracer 추가
@Autowired
Tracer tracer;
public Organization findById(String organizationId) {
Optional<Organization> opt = null;
// getOrgDBCall 사용자 정의 스팬 생성
ScopedSpan newSpan = tracer.startScopedSpan("getOrgDBCall");
try {
// 조직서비스 데이터베이스 조회
opt = repository.findById(organizationId);
// 카프카 비동기 메시지 전송, 라이선싱 서비스 레디스 캐시 ActionEnum.GET 과 맵핑하여 전달됨
simpleSourceBean.publishOrganizationChange(ActionEnum.GET, organizationId);
if (!opt.isPresent()) {
String message = String.format("Unable to find an organization with the Organization id %s", organizationId);
logger.error(message);
throw new IllegalArgumentException(message);
}
logger.debug("Retrieving Organization Info: " + opt.get().toString());
}finally {
// 태그정보를 스팬에 추가하고 집킨이 캡쳐할 이름 지정 (postgres)
newSpan.tag("peer.service", "postgres");
newSpan.annotate("Client received");
// 스팬을 닫고 종료시켜준다.
newSpan.finish();
}
return opt.get();
}
public Organization create(Organization organization){
organization.setId( UUID.randomUUID().toString());
organization = repository.save(organization);
simpleSourceBean.publishOrganizationChange(ActionEnum.CREATED, organization.getId());
return organization;
}
public void update(Organization organization){
repository.save(organization);
simpleSourceBean.publishOrganizationChange(ActionEnum.UPDATED, organization.getId());
}
public void delete(String organizationId){
repository.deleteById(organizationId);
simpleSourceBean.publishOrganizationChange(ActionEnum.DELETED, organizationId);
}
@SuppressWarnings("unused")
private void sleep(){
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
logger.error(e.getMessage());
}
}
}집킨을 이용한 트랜잭션 추적
집킨을 사용하여 집킨 서비스가 추적하는 트랜잭션을 관찰해보자 http://localhost:9411/
몇 가지 기본 쿼리 필터와 함께 추적할 서비스를 선택할 수 있는 기본 화면이다
serviceName=gateway-server 등 쿼리할 서비스 선택을 할수 있다
RUN QUERY 는 쿼리를 조회하며
아래 목록은 쿼리결과가 조회된다.
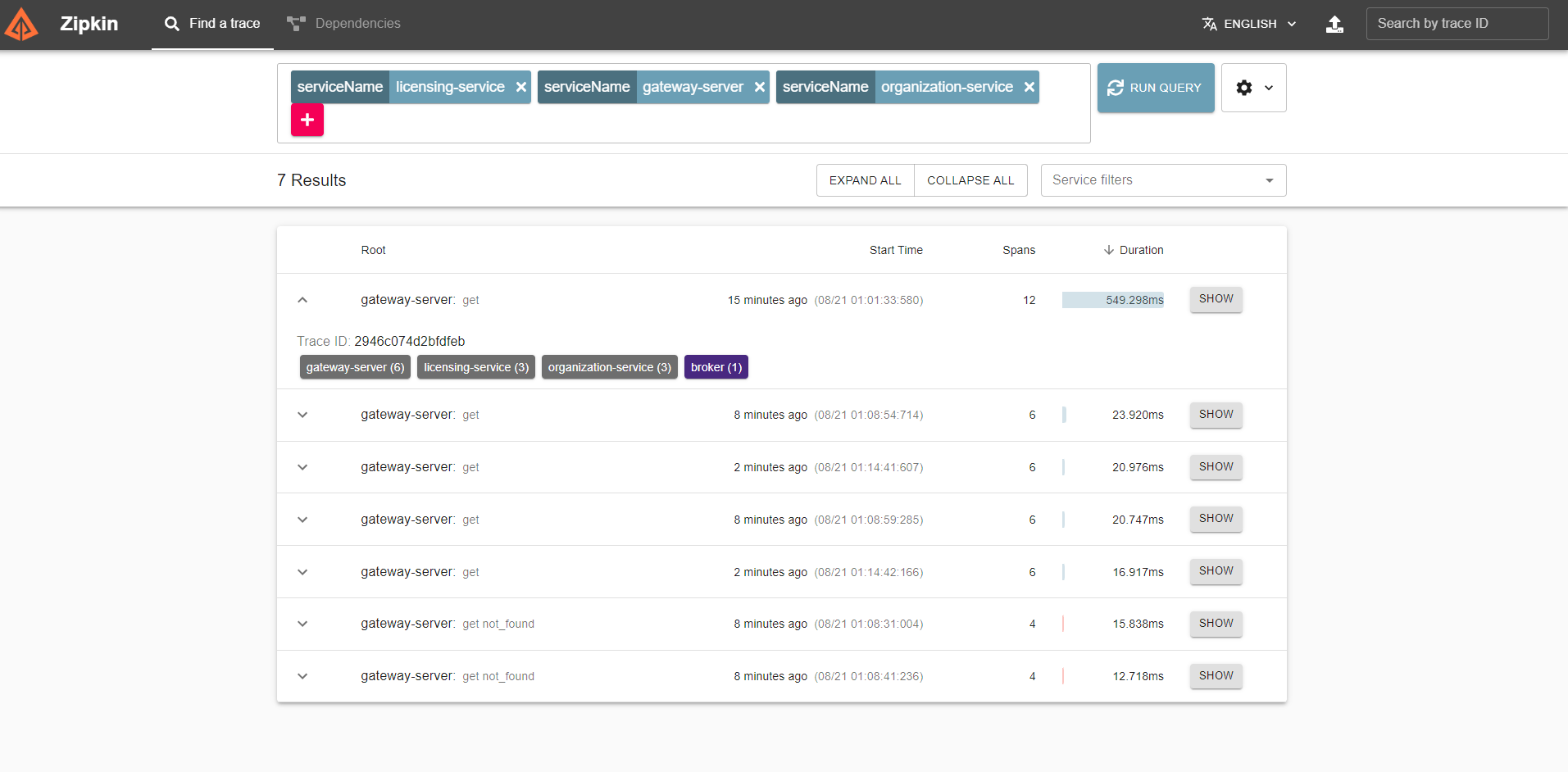
쿼리결과에서 show버튼을 클릭하면 서비스 호출에 대한 자세한 화면을 보여준다
-
트랜잭션은 개별 스펜으로 나뉘고 스펜은 측정된 트랜잭션의 일부를 나타낸다. 여기서 트랜잭션에 포함된 각 스팬에 대한 총 시간이 표시된다.
-
트랜잭션에 여러개의 스팬이 있다(게이트웨이 소요 시간, 조직 서비스 소요 시간, 라이선싱 서비스 소요 시간 등)
-
각 스팬을 클릭하면 스팬에 대한 추가 정보가 표시된다.
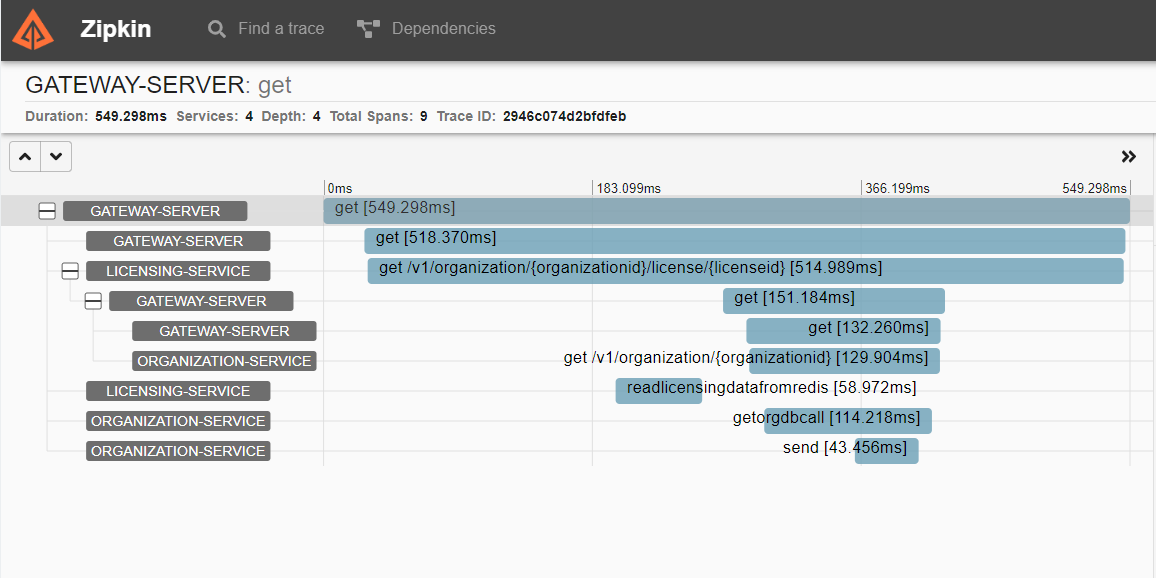
각 스팬을 클릭하면 HTTP 호출과 타이밍에 대한 상세 정보가 제공된다.
-
상세 정보를 클릭하면 서비스를 호출한 시간, 요청을 받은 시간, 클라이언트가 요청을 다시 받은 시간등 확인 할 수 있다.
-
Tags 부분에는 HTTP 호출에 대한 일부 기본 정보도 제공한다.
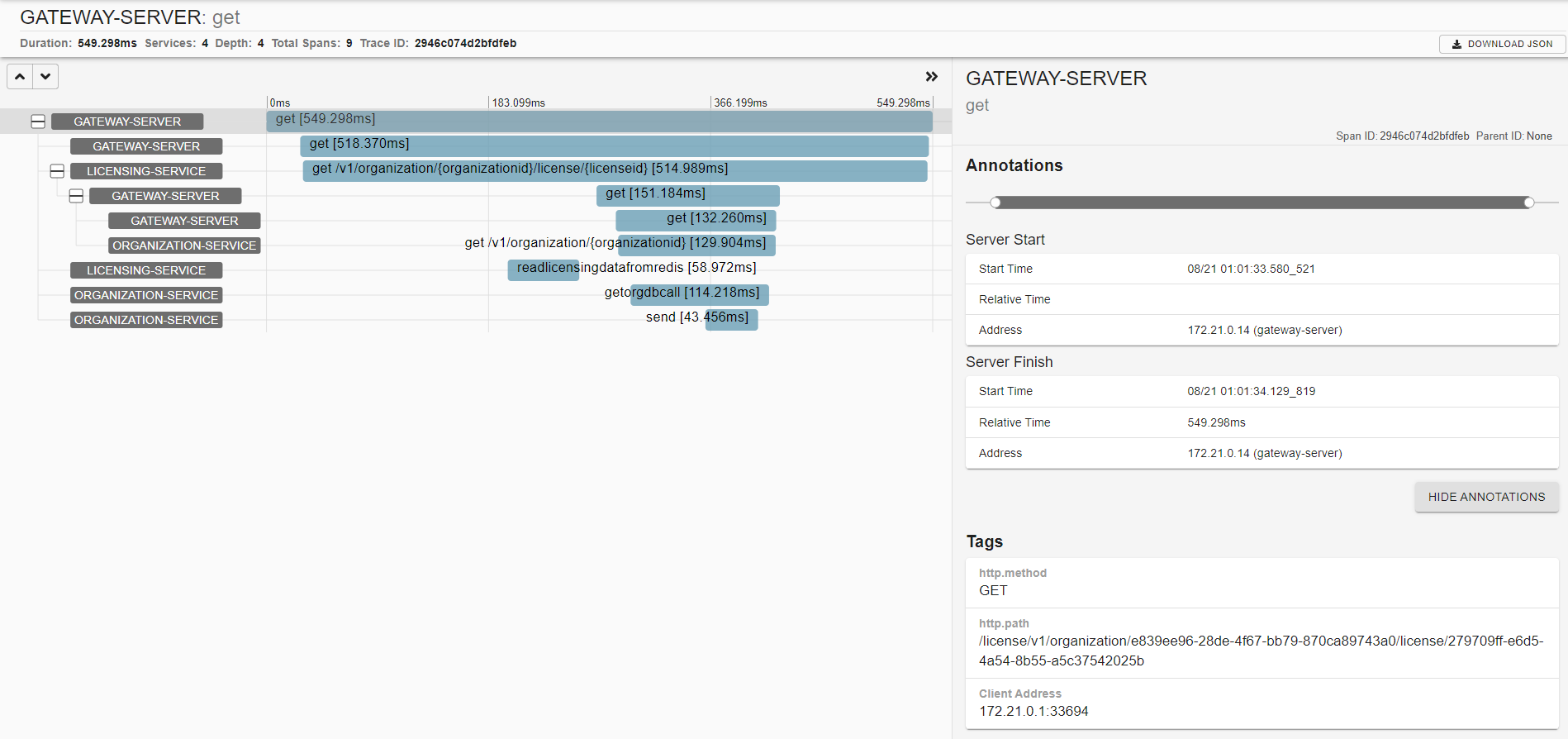
맨위 상단 오른쪽에 보면 추적ID 기준으로도 검색하여 트랜잭션을 쉽게 찾을 수 있다.
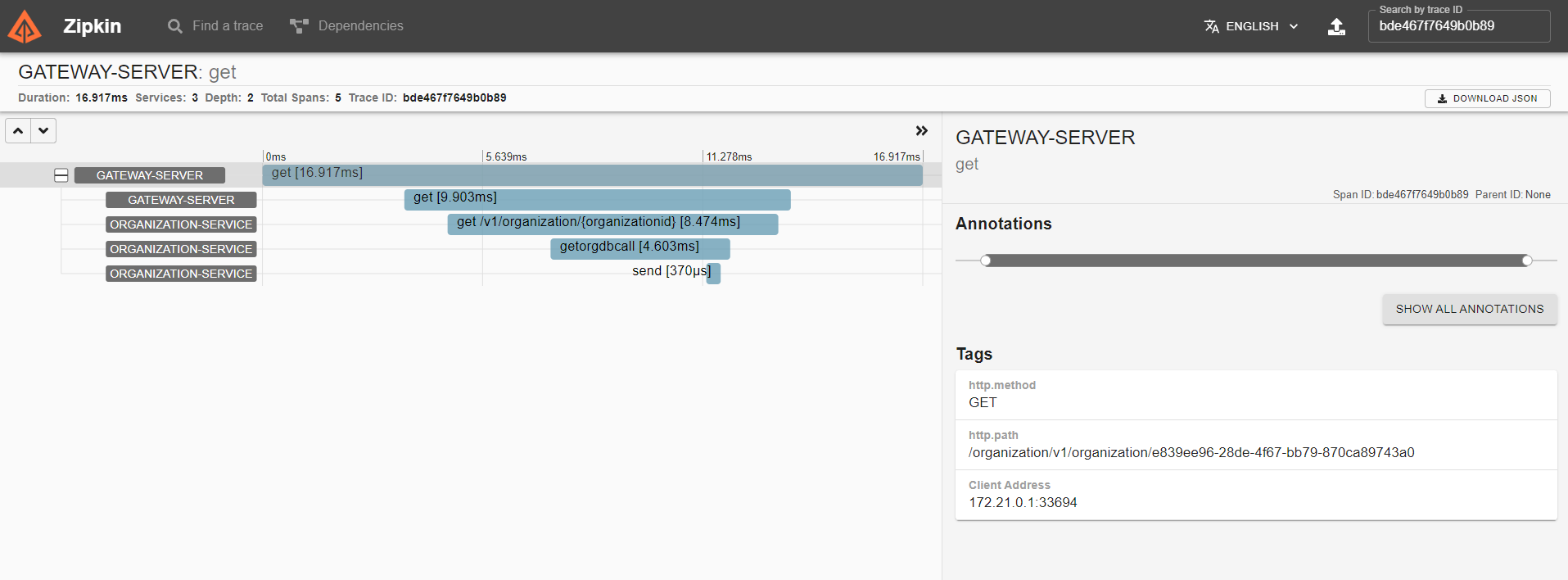
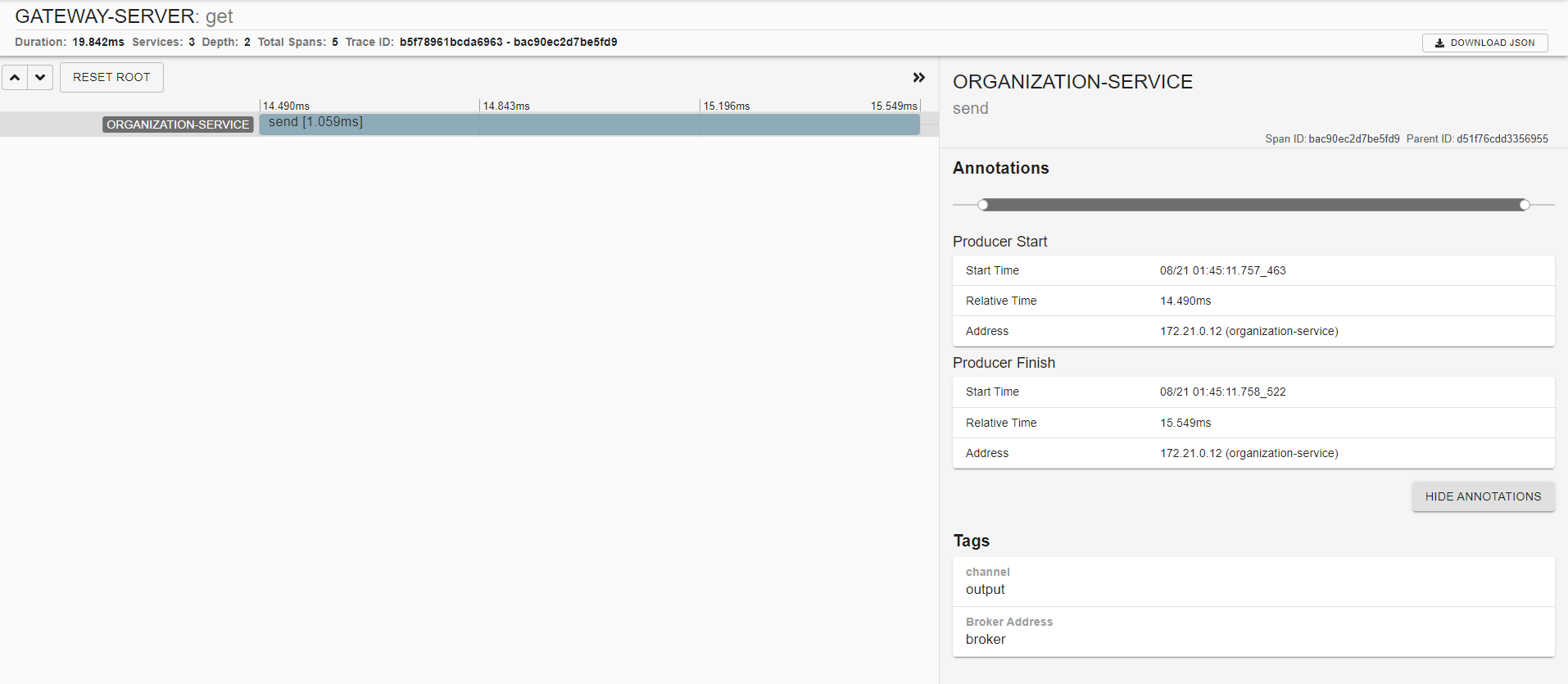
조직 및 라이선싱 서비스의 메시지 통신에 대해 자동으로 추적하고 집킨을 이용해 상세 정보를 볼 수 있다.
상세 내용에서는 메시지가 발행되는 카프카 메시지를 볼 수 있다.
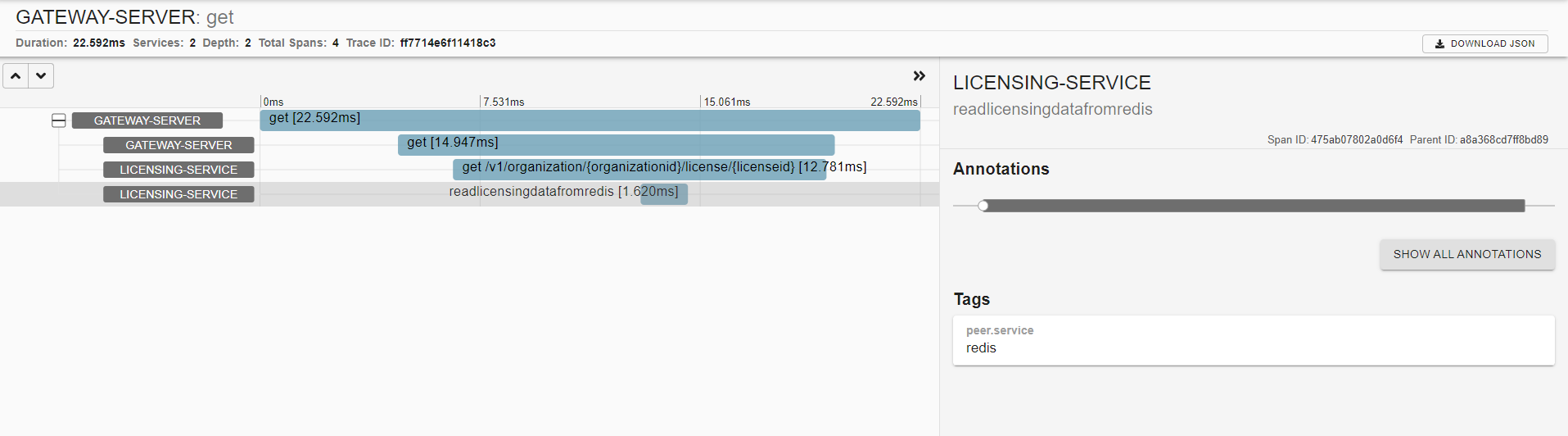
사용자 정의 스팬을 구현하여 써드파티인 레디스, PostgreSQL 호출에 대한 트랜잭션 추적도 살펴볼수 있다
아래 사진은 레디스 소요시간을 캡쳐한 부분이다
이렇게 슬루스+ELK를 이용해 로그를 수집하고 zipkin을 이용하여 시각화 된 분산추적 로그를 살펴보았다!
🧨 다음 챕터는 이제 까지 구축한 마이크로서비스에 대해 AWS 에서 빌드 및 배포를 해보도록 하겠다.
