Abstraction
거대한 데이터셋에서 단어를 연속적인 벡터로 표현하기 위한 두가지 새로운 모델 아키텍처를 제안한다. Continuous vector representations의 품질은 단어 유사도 task를 통해 측정한다. 훨씬 낮은 cost로 정확도는 크게 향상되어 16억 개의 단어 datasets에서 단어 벡터를 학습하는 데에 하루도 걸리지 않는다. Vector representation은 syntatic, semantic 유사도를 측정하기 위한 test set에서 state-of-the-art를 보인다.
Introduction
본 연구에서 목표는 고품질의 word vector를 학습하는 것이다. 유사한 단어는 vector space에서 가까이에 위치할 뿐만 아니라, 여러 유사도를 가질 수 있을 것이라 기대한다.
놀랍게도, 유사한 단어의 representation는 간단한 구문 규칙성을 발견했다. 간단한 선형 연산을 통해 vector("King")-vector("Man")+vector("Woman")의 결과가 Queen의 vector 표현과 가까운 것을 확인했다.
본 연구에서 단어 간의 선형 규칙성을 보존하는 새로운 모델 아키텍처를 개발하여 vector 연산의 정확도를 높이고자 한다. Syntactic, semantic 규칙성 모두 측정할 수 있는 test set을 설계했고 많은 규칙들이 높은 정확도로 학습되었다.
Model Architecture
본 연구에서는 distributed representations of words에 집중하였다.
- Distributed representation of words
기존의 one-hot encoding으로 표현된 word vector는 벡터 대부분이 0으로 채워져 메모리 비효율성이 있다. 각 차원이 고유한 의미를 가지고, 단어 간 차이를 명확하게 구분할 수 있으나 의미적으로 비슷한 단어의 관계를 표현하기 어렵다. (서로 다른 one-hot vector를 내적하면 항상 0)
Distributed representation을 통해 여러 차원에서 단어 하나의 의미를 표현할 수 있다. 앞서 본 sparse representation(one-hot)과 달리 연속적인 실수 값으로 단어를 표현할 수 있다. 유사한 의미를 가진 단어는 벡터 공간에서 가까운 위치에 존재하며 고차원의 정보를 적은 크기의 벡터로 나타낼 수 있다.
New Log-linear Models
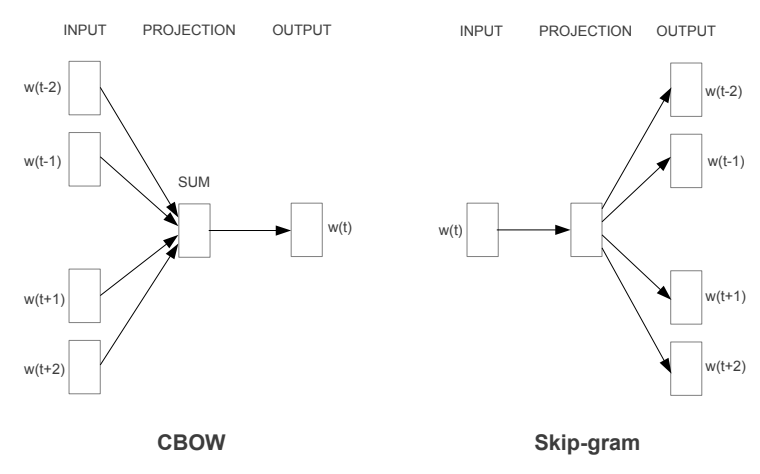
Continuous Bag-of-Words Model
feedforward NNLM에서 non-linear hidden layer가 삭제된 구조로, 모든 단어는 같은 position에 평균값으로 계산되어 투영된다.
- Bag-of-words model: 단어의 빈도만 고려하여 문단을 수치화하는 것
한 Bag에서 수영장, 수모, 물안경 같은 단어가 자주 등장하면 수영 관련 문서라고 볼 수 있다.- Context를 통해 중심 단어를 예측하는 방식
- CBOW는 연속될 실수값을 사용한다.
- Input
- 예측할 단어의 이전 N개, 이후 N개의 단어를 입력으로 사용한다.
- Vocabulary size가 V일 때 입력 단어는 차원의 one-hot encocing vectors이다.
- Projection
- 가중치 를 입력 단어 각각 곱하고 평균을 계산하여 projection을 구한다.
- 입력 단어는 one-hot 형태이므로 의 번째 row를 slicing 한 뒤 평균을 계산하는 것과 같다.
- 의 각 row를 임베딩 벡터로 사용하게 된다.
- 각 입력 단어와 를 곱한 값이 Summation(or average) 계산되기 때문에 입력된 단어의 순서는 의미가 없다.
- 가중치 를 입력 단어 각각 곱하고 평균을 계산하여 projection을 구한다.
- Output
- 차원의 Projection 값을 가중치 와 곱하고 softmax 계산을 통해 구하고자 한 중심 단어의 one-hot encoding과 동일한지 구한다.
- Loss: 최종적으로 구하고자 한 중심 단어의 one-hot encoding과 cross entropy를 계산한다.
Continuous Skip-gram Model
중심 단어를 통해 주변 단어를 예측하는 것
- 학습 시간이 오래 걸리지만, 전반적으로 CBOW 보다 성능이 더 좋다.
