Motivation
- Clustering
- 복잡한 real-valued data point를 하나의 categorical variable로 요약하는 것
- Dimensionality reduction
- 고차원 data를 단순화하는 방법
- 고차원 data로 학습을 진행하면 overfitting 되기 쉽다.
- Real valued vector를 낮은 차원의 data로 요약, 단순화하는 것
Data points의 차원이 d 일 때
y=θTx then, x=⎣⎢⎢⎢⎢⎡x1x2⋮xd⎦⎥⎥⎥⎥⎤
- d 보다 작은 r 차원으로 바꾼다.
- 차원을 낮출 때 정보의 손실을 최소화 해야 한다.
Data Compression
Parameter θ의 복잡도를 낮추는 정규화와 달리 데이터에 초점을 두고 x의 차원을 줄인다.
- 이때 Data의 분포가 넓은 방향으로 축소해야 한다.
- 정보 손실이 적은 쪽으로 축소해야 한다.
- 따라서 분산이 큰 축을 찾아야 한다. → PCA
- 이때 d 차원의 Data를 가장 잘 설명하는 축 상위 r개를 찾기만 하면 된다.
- Reduce from 2-dim to 1-dim: Projection error를 최소화하는 projection 할 방향 벡터 u(1)∈Rn을 찾는다.
- Reduct from d-dim to r-dim: Proejction error를 최소화하는 projection 할 방향 벡터 u(1),u(2),⋯,u(r)를 찾는다.
PCA의 Goal
- Points의 mean vector μ와 공분산 행렬 ∑을 계산한다.
- ∑의 고유벡터와 고유값을 계산한다.
- 최상위 r 개의 고유벡터를 선택한다.
- Points를 subspace로 투영한다.
Covariance
- Variance and Covariance: 중심으로부터 points가 퍼진(spread) 정도
- Variance: 1 차원에서 평균값으로부터 편차
- Covariance: 2 차원에서 points 분포의 경향성
- Covariance는 두 차원에서의 관계를 나타낸다.
- 1 차원에서 Covariance는 variance와 같다.
- 2 차원에서 points의 분포를 variance로 계산한다면 서로 정반대의 분포이더라도 동일한 값이 나오는 문제가 있다.
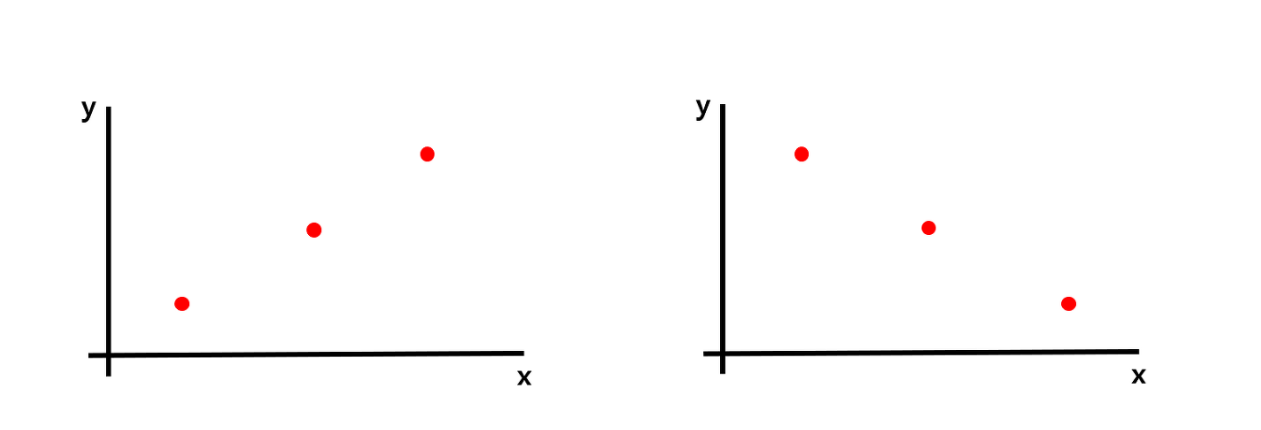
- 고차원 데이터가 있을 때 차원 간의 관계를 찾기 위해 공분산을 사용한다.
- j 차원과 k 차원의 Covariance qjk
qjk=N1i=1∑N(Xij−E(Xj))(Xik−E(Xk))
- 다차원 확장

- Covariance matrix
- x=[x1,⋯,xn]T: sample data, n차원 column 벡터
- C=E[(x−mx)(x−mx)T]: n×n 행렬
- <C>ij=E[(xi−mxi)(xj−mxjT)]: i번째 성분과 j번째 성분의 공분산
- C는 대칭 행렬이다.
C=⎣⎢⎢⎡C11⋮Cn1⋯⋱⋯C1n⋮Cnn⎦⎥⎥⎤
고유값과 고유벡터
Mv=[m11m21m12m22][v1v2]=λvˉ
-
Eigenvector: 정방 행렬 M을 곱하여 선형변환 했을 때 길이만 변하는 벡터 vˉ
- 고유벡터는 크기만 달라지며 방향의 변화는 없다.
- Mv=λv를 만족하는 0이 아닌 벡터여야 한다.
- 행렬 M의 λ에 대한 고유벡터
-
Eigenvalue: 정방 행렬 M을 곱했을 때 벡터 vˉ의 길이 변화 λ
- 행렬 M의 고유값
- 고유값으로 분산을 계산하여 PCA 계산에 활용한다.
- 가장 큰 고유값은 분산이 가장 크다.
-
고유값과 고유벡터는 없을 수도 있고 행렬의 차원(n)에 따라 n개까지 있을 수도 있다.
-
Example: M=[4325]
-
Mv=λv
-
(M−λI)v=0
-
(M−λI)v의 역행렬이 존재한다면 v=(M−λI)−10, v=0으로 모순이다.
-
Eigenvector v는 0이 될 수 없으므로 (M−λI)=0이고 역행렬이 존재하지 않아야 한다.
-
det(M−λI)=0
| Mv=[4325][x1x2]=λv | 4x1+2x2=λx1
3x1+5x2=λx2 |
|---|
| (M−λI)v=0 | (4−λ)x1+2x2=0
3x1+(5−λ)x2=0 |
| det(M−λI)=0 | |
| ∣∣∣∣∣4−λ325−λ∣∣∣∣∣=0 | (λ−7)(λ−2)=0 |
- λ=2
[−332−2][x1x2]=[00]
- λ는 고유한 값이지만 고유값에 대응하는 고유벡터는 여러 개일 수 있다.
- x1=32x2로, 방향은 정해져 있지만 크기는 달라질 수 있다.
- λ=7
[−232−3][x1x2]=[00]
Principal Component Analysis
데이터가 넓게 퍼진 분산값이 높은 축을 찾아 그 방향으로 projection하는 것
공분산 행렬 C를 구하고, 고유값이 큰 것에 해당하는 고유벡터로 projection한다.
- Input: x∈RD:D=x1,…,xN
- 차원이 축소된 uxT=z=z1,…,zK의 분산이 최대여야 한다.
- 즉, Var(uxT)=uTVar(x)u=uTCu를 최대로 하는 u를 찾아야 한다.
- projection 된 zi의 분산
n1∑i(xi⋅u)2
=n1(xu)T(xu)
=n1uTxTxu
=uTCu
- 위 식을 만족하는 u는 많을 수 있으므로 ∣u∣=1 제약 조건을 걸어 라그랑지안 문제(조건부 최적화)로 해결한다.
- Basis vector: U=[u1,…,uk]
- 벡터 공간을 형성하는데 사용되는 기초적인 벡터
- Symmetirc matrix의 고유벡터는 직교하므로 ujTuj=0이 성립한다.
- New Data representation: zj=uj⋅x
- h(x)=[z1,…,zK]T
- h(x)=UTx
PCA 과정
- 데이터 x의 공분산 행렬 C를 구한다.
- Cu=λu
- 공분산 행렬의 λ에 대한 고유벡터 u를 찾는다.
- u는 데이터를 나타낼 새로운 축으로 x가 N차원이라면 u도 N 차원이다.
- λ가 큰 순서대로 u를 정렬한다.
- λ는 해당 축 ui이 데이터를 얼마나 잘 나타내는지 의미한다.
