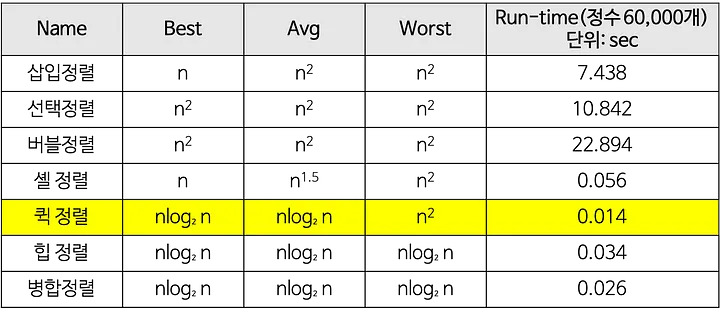
정렬
- 알고리즘의 기본 정렬에 대해 알아보자
- 특정한 기준(오름차순 or 내림차순 ...etc)으로 수열을 배열하는 것
- 여러 정렬 알고리즘에 대해 알아보자
- 단순 but 비효율적: 삽입, 선택, 버블
- 복잡 but 효율적: 퀵, 힙, 합병, 기수
1. 삽입 정렬(Insertion Sort)
- 제자리 정렬 알고리즘 : 정렬 시, 추가 메모리를 요구하지 않음
- 손 안의 카드를 정렬하는 방법
- 정해진 카드 하나(key index)와 앞에 카드들를 비교한다 생각해봐라
- 알고리즘
- 카드를 오름차순으로 정렬하게 된다면,
- key index의 카드가 왼쪽보다 작으면 swap
- key index의 카드가 왼쪽보다 크면 중단할 것
- ...
- 모든 카드에 대해 위 방식을 진행
- 삽입 정렬 특징
- [장점1]: 안정 정렬 : 값이 같은 두 원소의 순서가 바뀌지 않음
- [장점2]: 레코드의 수가 적음 or 정렬이 대부분 되어있는 경우 효율적
- [단점1]: 레코드의 수가 많을 경우 비효율적
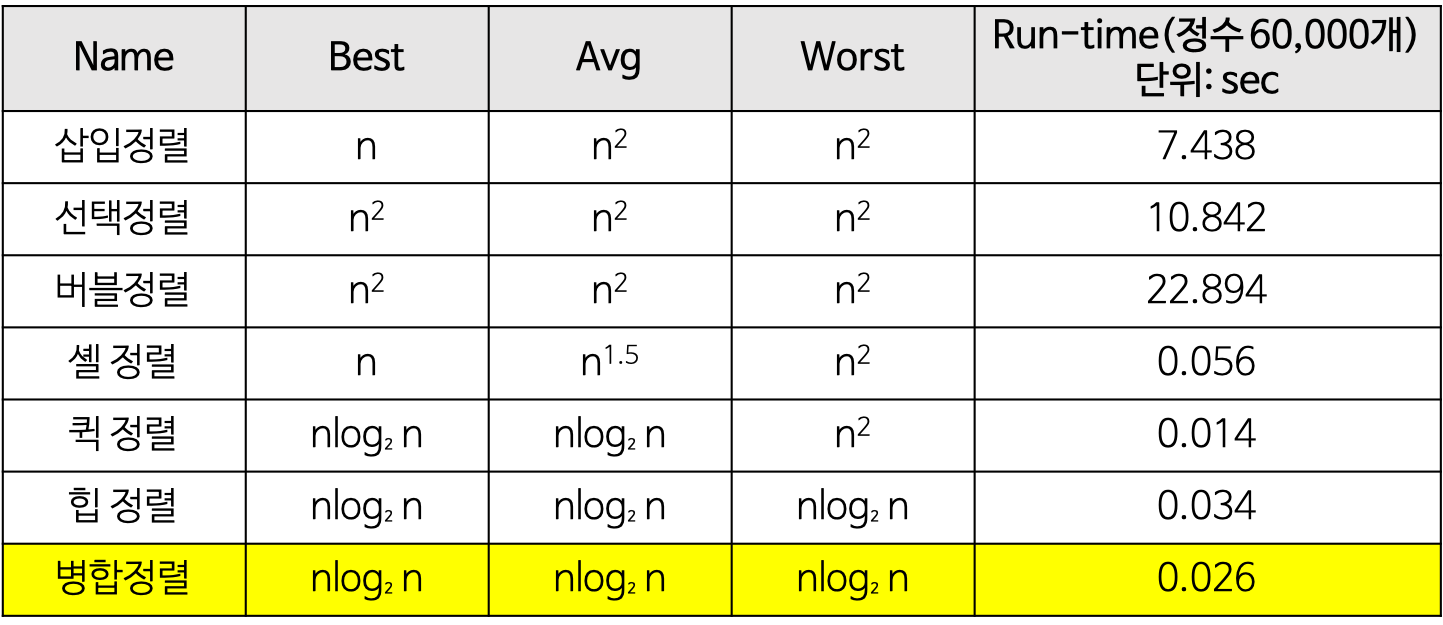
- 시간 복잡도
- 최선:
- 평균[default]:
- 최악[default]:
- 삽입 정렬 코드
# include <stdio.h> # define MAX_SIZE 5 // 삽입 정렬 void insertion_sort(int list[], int n){ int i, j, key; // 인텍스 0은 이미 정렬된 것으로 볼 수 있다. for(i=1; i<n; i++){ key = list[i]; // 현재 삽입될 숫자인 i번째 정수를 key 변수로 복사 // 현재 정렬된 배열은 i-1까지이므로 i-1번째부터 역순으로 조사한다. // j 값은 음수가 아니어야 되고 // key 값보다 정렬된 배열에 있는 값이 크면 j번째를 j+1번째로 이동 for(j=i-1; j>=0 && list[j]>key; j--){ list[j+1] = list[j]; // 레코드의 오른쪽으로 이동 } list[j+1] = key; } } void main(){ int i; int n = MAX_SIZE; int list[n] = {8, 5, 6, 2, 4}; // 삽입 정렬 수행 insertion_sort(list, n); // 정렬 결과 출력 for(i=0; i<n; i++){ printf("%d\n", list[i]); } }
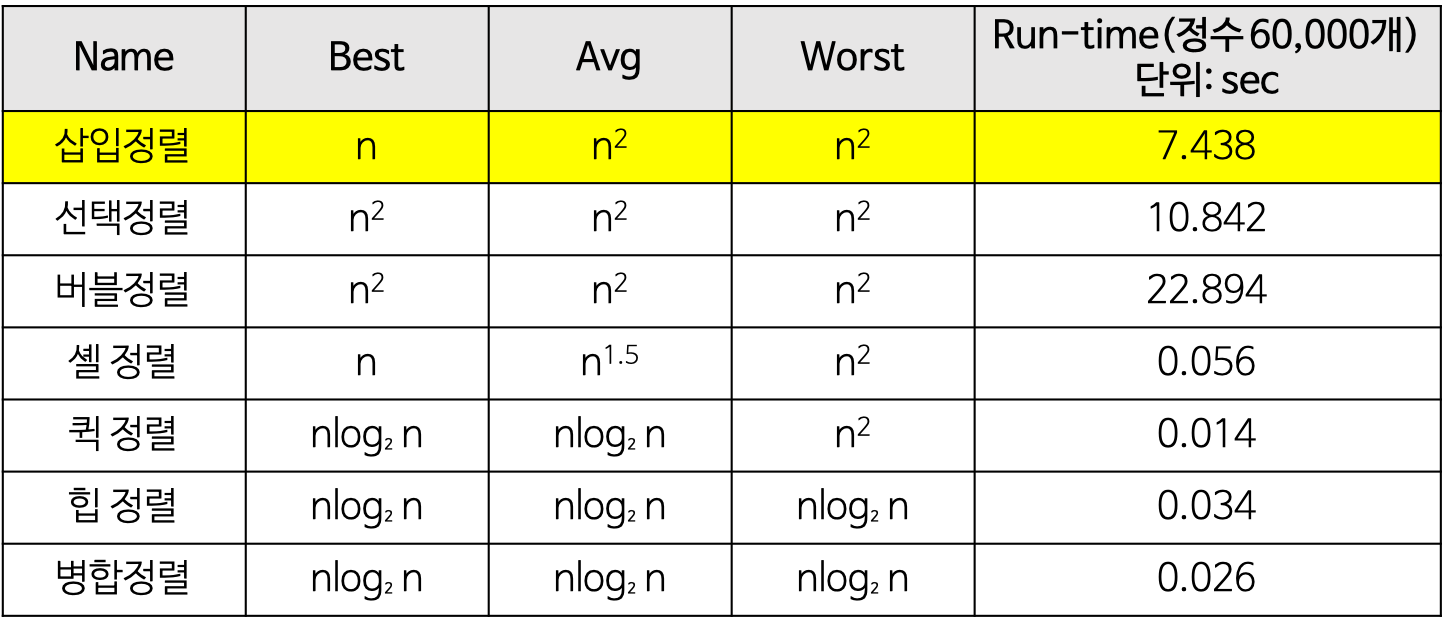
2. 선택 정렬(Selection Sort)
- 제자리 정렬 알고리즘 : 정렬 시, 추가 메모리를 요구하지 않음
- 배열 전체를 보고, 특정 기준에 맞는 값을 첫번째 값부터 선택해나감
- 선택된 원소는 제외
- 알고리즘
- 카드를 오름차순으로 정렬하게 된다면,
- 0번째 인덱스에 들어갈 가장 작은 원소를 전체 배열에서 찾음
- 1번째 인덱스에 들어갈 가장 작은 원소를 전체 배열 - 1(선택된 원소 제외)에서 찾음
- 2번째 인덱스에 들어갈 가장 작은 원소를 전체 배열 - 2(선택된 원소 제외)에서 찾음
- ...
- 모든 카드에 대해 위 방식을 진행
- 선택 정렬 특징
- [장점1]: 구현이 쉽다.
- *[장점2]: 메모리 소비가 작다.
- [단점1]: 불안정 정렬
- 시간 복잡도
- 최선:
- 평균[default]:
- 최악:
- 선택 정렬 코드
# include <stdio.h> #define SWAP(x, y, temp)((temp) = (x), (x) = (y), (y) = (temp)) # define MAX_SIZE 5 // 선택 정렬 void selection_sort(int list[], int n){ int i, j, least, temp; // 마지막 숫자는 자동으로 정렬되기 때문에 (숫자 개수-1) 만큼 반복한다. for(i=0; i<n-1; i++){ least = i; // 최솟값을 탐색한다. for(j=i+1; j<n; j++){ if(list[j]<list[least]) least = j; } // 최솟값이 자기 자신이면 자료 이동을 하지 않는다. if(i != least){ SWAP(list[i], list[least], temp); } } } void main(){ int i; int n = MAX_SIZE; int list[n] = {9, 6, 7, 3, 5}; // 선택 정렬 수행 selection_sort(list, n); // 정렬 결과 출력 for(i=0; i<n; i++){ printf("%d\n", list[i]); } }

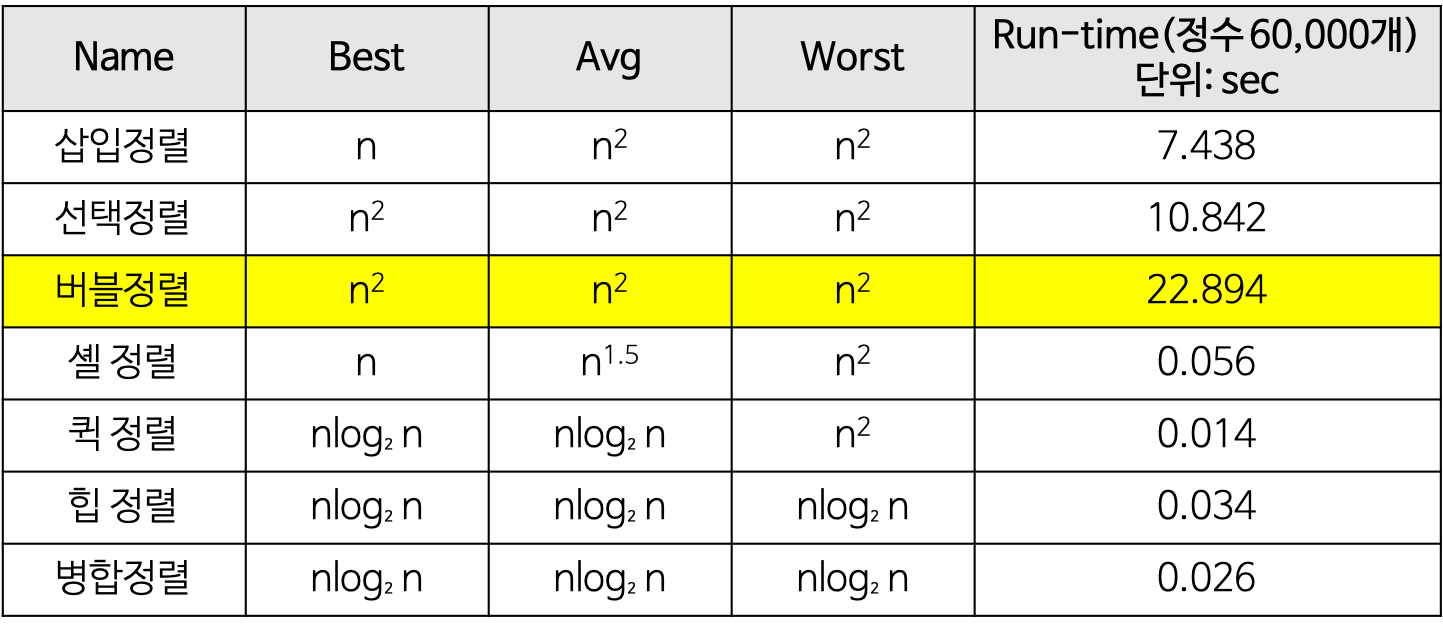
3. 버블 정렬(Bubble Sort)
- 거품(버블)이 올라오듯 정렬되는 알고리즘
- 서로 인접한 두 원소를 검사해 정렬
- 선택정렬과 알고리즘이 유사(선택: 앞부터 / 버블: 뒤부터)
- 알고리즘
- 카드를 오름차순으로 정렬하게 된다면,
- k번째 인덱스와 k+1번째 인덱스 중 큰것을 비교
- SWAP을 통해 큰 원소가 뒤 인덱스에 위치하도록 변경
- 마지막 인덱스에 가장 큰 원소 배치
- 마지막 - 1 인덱스에 두번째로 큰 원소 배치
- ...
- 모든 카드에 대해 위 방식을 진행
- 버블 정렬 특징
- [장점1]: 구현이 쉽다.
- [단점1]: 불안정 정렬
- [단점2]: 인접한 요소와 교환(SWAP)만을 수행
- 교환작업(SWAP) 비용 > 이동작업(MOVE) 비용이라 버블정렬은 거의 사용하지 않음
- 즉 비효율적
- 시간 복잡도
- 최선:
- 평균[default]:
- 최악:
- 버블 정렬 코드
# include <stdio.h> # define MAX_SIZE 5 // 버블 정렬 void bubble_sort(int list[], int n){ int i, j, temp; for(i=n-1; i>0; i--){ // 0 ~ (i-1)까지 반복 for(j=0; j<i; j++){ // j번째와 j+1번째의 요소가 크기 순이 아니면 교환 if(list[j]<list[j+1]){ temp = list[j]; list[j] = list[j+1]; list[j+1] = temp; } } } } void main(){ int i; int n = MAX_SIZE; int list[n] = {7, 4, 5, 1, 3}; // 버블 정렬 수행 bubble_sort(list, n); // 정렬 결과 출력 for(i=0; i<n; i++){ printf("%d\n", list[i]); } }
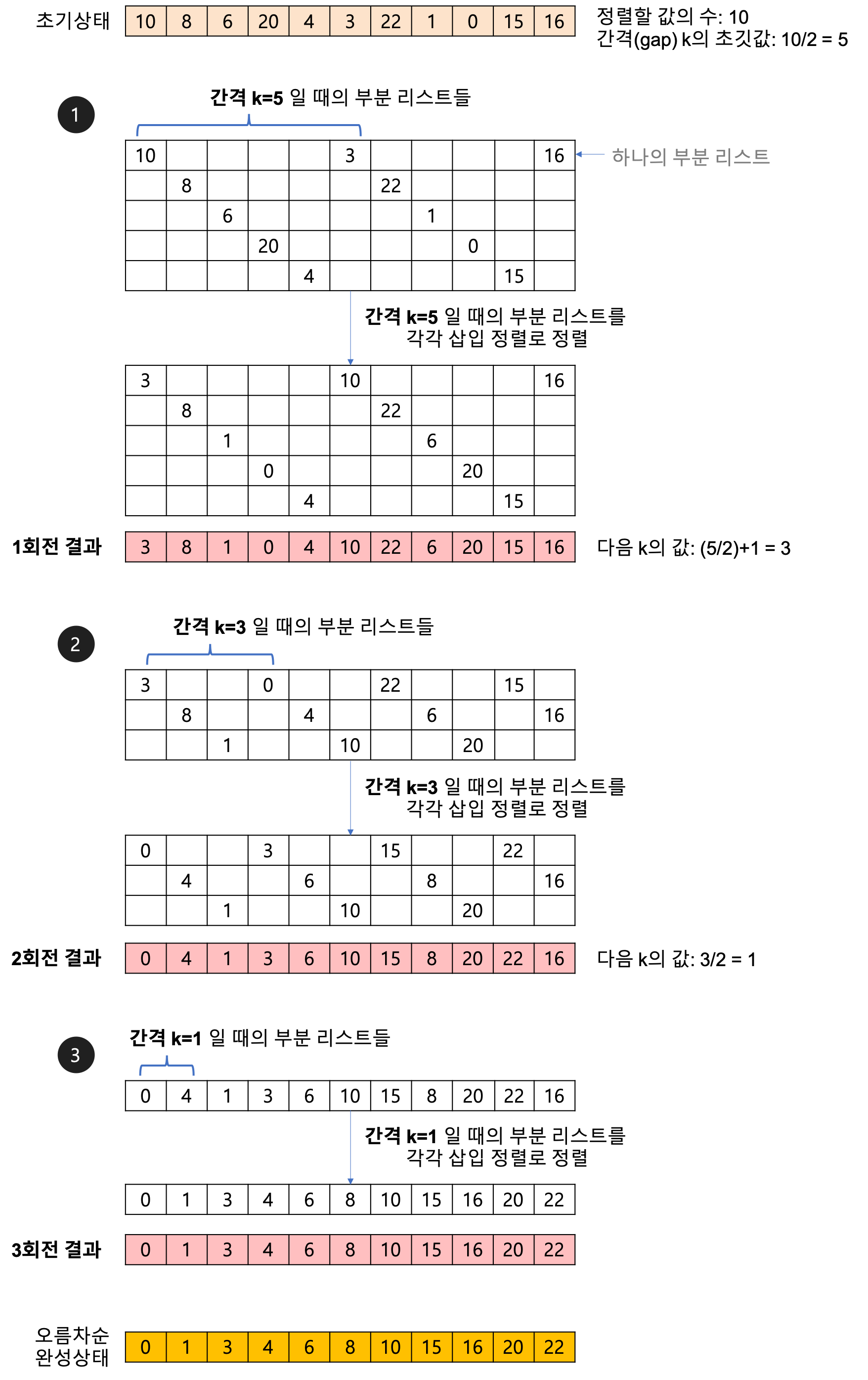
4. 셸 정렬(Shell Sort)
- 삽입 정렬 업그레이드 버전
- 삽입 정렬 문제점인 인접 원소간 교환(SWAP)의 문제점을 보완
- 삽입 정렬이 어느정도 정렬된 배열에 대해 대단히 빠른 것에서 착안
- 셸 정렬은 전체 배열을 한 번에 정렬하지 않음
- 전체 배열을 부분 리스트로 나눠 삽입 정렬 수행
- 알고리즘
- 카드를 오름차순으로 정렬하게 된다면,
- 전체 배열의 k(간격 = gap)번째 요소를 추출해 부분 리스트를 만든다.
- 간격의 초깃값 : (전체 배열의 크기) / 2
- 생성된 부분 리스트의 개수 = k
- 각 회전마다 k를 절반씩 줄인다.
- 즉, 각 부분 리스트의 개수는 감소하고, 원소의 개수는 증가한다.
- 간격(k)은 홀수로 설정하는 것이 좋다.
- 간격(k)이 짝수로 나온다면 +1을 수행한다.
- 위 방식을 간격(k) = 1이 될 때까지 진행
- 셸 정렬 특징
- [장점1]: 부분 리스트 사용 -> 교환되는 요소들이 삽입 정렬보다 최종 위치에 있을 가능성이 높아진다. -> 평균 이동 거리 감소
- [장점2]: 삽입 정렬보다 더욱 빠르게 수행된다.
- [장점3]: 간단한 알고리즘으로 쉬운 구현 가능
- 시간 복잡도
- 최선:
- 평균[default]:
- 최악:
- 셸 정렬 코드
# include <stdio.h> # define MAX_SIZE 10 // gap만큼 떨어진 요소들을 삽입 정렬 // 정렬의 범위는 first에서 last까지 void inc_insertion_sort(int list[], int first, int last, int gap){ int i, j, key; for(i=first+gap; i<=last; i=i+gap){ key = list[i]; // 현재 삽입될 숫자인 i번째 정수를 key 변수로 복사 // 현재 정렬된 배열은 i-gap까지이므로 i-gap번째부터 역순으로 조사한다. // j 값은 first 이상이어야 하고 // key 값보다 정렬된 배열에 있는 값이 크면 j번째를 j+gap번째로 이동 for(j=i-gap; j>=first && list[j]>key; j=j-gap){ list[j+gap] = list[j]; // 레코드를 gap만큼 오른쪽으로 이동 } list[j+gap] = key; } } // 셸 정렬 void shell_sort(int list[], int n){ int i, gap; for(gap=n/2; gap>0; gap=gap/2){ if((gap%2) == 0)( gap++; // gap을 홀수로 만든다. ) // 부분 리스트의 개수는 gap과 같다. for(i=0; i<gap; i++){ // 부분 리스트에 대한 삽입 정렬 수행 inc_insertion_sort(list, i, n-1, gap); } } } void main(){ int i; int n = MAX_SIZE; int list[n] = {10, 8, 6, 20, 4, 3, 22, 1, 0, 15, 16}; // 셸 정렬 수행 shell_sort(list, n); // 정렬 결과 출력 for(i=0; i<n; i++){ printf("%d\n", list[i]); } }

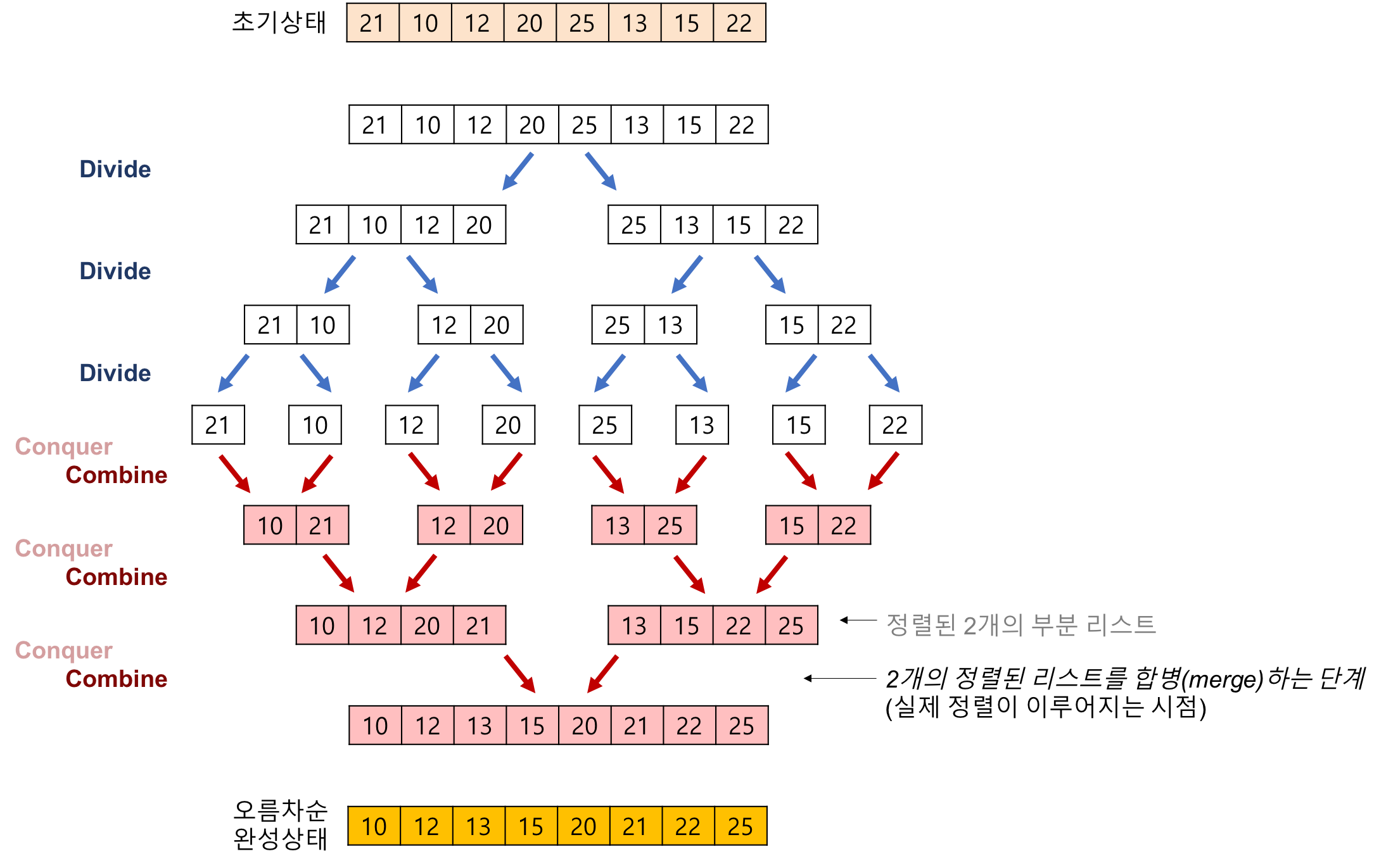
5. 합병 정렬(Merge Sort)
- 분할 정복 알고리즘을 활용한 정렬
- 작은 두개의 문제로 전체 문제를 분리하고 해결한 각각의 답을 모아 전체 문제를 해결
- 제자리 정렬X: 추가 메모리 공간(리스트) 필요
- 안정 정렬
- 알고리즘
- 리스트의 길이가 1 or 0이면 정렬된 것으로 본다.
- 그렇지 않은 경우
분할: 입력 배열을 같은 크기의 2개의 부분 배열로 분할한다.
합병 정렬: 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복
병합: 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용해 다시 분할 정복
실제 정렬이 이루어지는 과정
- 합병 정렬 특징
- [장점1]: 안정 정렬
- 데이터 분포에 영향을 덜 받는다.
- 입력 데이터와 상관없이 정렬 시간이 동일하다 =>
- [단점1]: 임시 배열(메모리) 필요
- [단점2]: 각 레코드들의 크기가 큰 경우 이동 횟수가 많아 매우 큰 시간적 낭비 초래
- [단점3]: 힙정렬보다 다소 메모리가 많이 필요함(단, 상대적으론 빠름)
- 시간 복잡도
- 최선:
- 평균[default]:
- 최악:
- 합병 정렬 코드
# include <stdio.h> # define MAX_SIZE 8 int sorted[MAX_SIZE] // 추가적인 공간이 필요 // i: 정렬된 왼쪽 리스트에 대한 인덱스 // j: 정렬된 오른쪽 리스트에 대한 인덱스 // k: 정렬될 리스트에 대한 인덱스 /* 2개의 인접한 배열 list[left...mid]와 list[mid+1...right]의 합병 과정 */ /* (실제로 숫자들이 정렬되는 과정) */ void merge(int list[], int left, int mid, int right){ int i, j, k, l; i = left; j = mid+1; k = left; /* 분할 정렬된 list의 합병 */ while(i<=mid && j<=right){ if(list[i]<=list[j]) sorted[k++] = list[i++]; else sorted[k++] = list[j++]; } // 남아 있는 값들을 일괄 복사 if(i>mid){ for(l=j; l<=right; l++) sorted[k++] = list[l]; } // 남아 있는 값들을 일괄 복사 else{ for(l=i; l<=mid; l++) sorted[k++] = list[l]; } // 배열 sorted[](임시 배열)의 리스트를 배열 list[]로 재복사 for(l=left; l<=right; l++){ list[l] = sorted[l]; } } // 합병 정렬 void merge_sort(int list[], int left, int right){ int mid; if(left<right){ mid = (left+right)/2 // 중간 위치를 계산하여 리스트를 균등 분할 -분할(Divide) merge_sort(list, left, mid); // 앞쪽 부분 리스트 정렬 -정복(Conquer) merge_sort(list, mid+1, right); // 뒤쪽 부분 리스트 정렬 -정복(Conquer) merge(list, left, mid, right); // 정렬된 2개의 부분 배열을 합병하는 과정 -결합(Combine) } } void main(){ int i; int n = MAX_SIZE; int list[n] = {21, 10, 12, 20, 25, 13, 15, 22}; // 합병 정렬 수행(left: 배열의 시작 = 0, right: 배열의 끝 = 7) merge_sort(list, 0, n-1); // 정렬 결과 출력 for(i=0; i<n; i++){ printf("%d\n", list[i]); } }
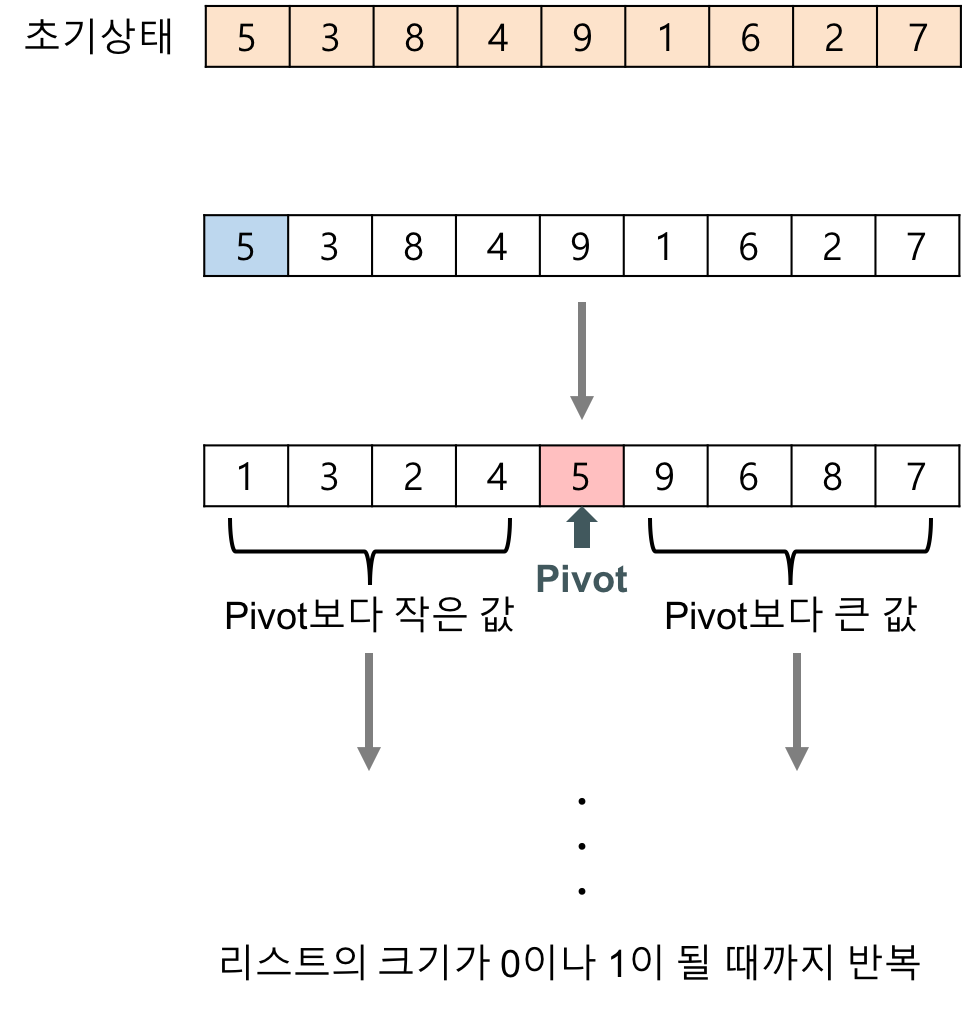
6. 퀵 정렬(Quick Sort)
- 분할 정복 알고리즘을 활용한 정렬
- 작은 두개의 문제로 전체 문제를 분리하고 해결한 각각의 답을 모아 전체 문제를 해결
- 불 안정 정렬
- 알고리즘
- 부분 리스트들이 더 이상 분할 불가능할 때(리스트의 크기 = 0 or 1)까지 아래 과정을 반복한다.
- 분할(Devide): 입력 요소들을 피봇(Pivot)을 기준으로 비균등하게 2개의 부분 배열로 분할한다.
- 정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 재귀 호출을 통해 분할한다.
- 결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
- 순환 호출이 이뤄질 때마다 최소한 하나(피봇 위치)의 원소 위치가 결정되어 반드시 끝남을 보장
- 리스트 안에 한 요소 피봇을 선택
- 피봇보다 작은 원소는 왼쪽으로 이동
- 피봇보다 큰 원소는 오른쪽으로 이동
- 피봇을 제외한 왼쪽 리스트와 오른쪽 리스트 재귀 호출로 재정렬
- 퀵 정렬 특징
- [장점1]: Quick(빠르다)
- STL에서 사용하는 정렬 코드가 퀵정렬 = 그만큼 효율적이라는 의미
- [장점2]: 제자리 정렬
- O(logn)의 적은 메모리 공간만이 필요
- [단점1]: 정렬된 상태의 리스트의 경우 불균형 분할의 특성 상 수행 시간이 많이 걸린다.
- 보완: 피봇 선택 방법에 따라 퀵 정렬의 불 균형 분할 방지 or 완화
midian of three: 중간값(medium)을 피봇으로 선택- 시간 복잡도
- 최선:
- 평균[default]:
- 최악:
- 퀵 정렬 코드
# include <stdio.h> # define MAX_SIZE 9 # define SWAP(x, y, temp) ( (temp)=(x), (x)=(y), (y)=(temp) ) // 1. 피벗을 기준으로 2개의 부분 리스트로 나눈다. // 2. 피벗보다 작은 값은 모두 왼쪽 부분 리스트로, 큰 값은 오른쪽 부분 리스트로 옮긴다. /* 2개의 비균등 배열 list[left...pivot-1]와 list[pivot+1...right]의 합병 과정 */ /* (실제로 숫자들이 정렬되는 과정) */ int partition(int list[], int left, int right){ int pivot, temp; int low, high; low = left; high = right + 1; pivot = list[left]; // 정렬할 리스트의 가장 왼쪽 데이터를 피벗으로 선택(임의의 값을 피벗으로 선택) /* low와 high가 교차할 때까지 반복(low<high) */ do{ /* list[low]가 피벗보다 작으면 계속 low를 증가 */ do { low++; // low는 left+1 에서 시작 } while (low<=right && list[low]<pivot); /* list[high]가 피벗보다 크면 계속 high를 감소 */ do { high--; //high는 right 에서 시작 } while (high>=left && list[high]>pivot); // 만약 low와 high가 교차하지 않았으면 list[low]를 list[high] 교환 if(low<high){ SWAP(list[low], list[high], temp); } } while (low<high); // low와 high가 교차했으면 반복문을 빠져나와 list[left]와 list[high]를 교환 SWAP(list[left], list[high], temp); // 피벗의 위치인 high를 반환 return high; } // 퀵 정렬 void quick_sort(int list[], int left, int right){ /* 정렬할 범위가 2개 이상의 데이터이면(리스트의 크기가 0이나 1이 아니면) */ if(left<right){ // partition 함수를 호출하여 피벗을 기준으로 리스트를 비균등 분할 -분할(Divide) int q = partition(list, left, right); // q: 피벗의 위치 // 피벗은 제외한 2개의 부분 리스트를 대상으로 순환 호출 quick_sort(list, left, q-1); // (left ~ 피벗 바로 앞) 앞쪽 부분 리스트 정렬 -정복(Conquer) quick_sort(list, q+1, right); // (피벗 바로 뒤 ~ right) 뒤쪽 부분 리스트 정렬 -정복(Conquer) } } void main(){ int i; int n = MAX_SIZE; int list[n] = {5, 3, 8, 4, 9, 1, 6, 2, 7}; // 퀵 정렬 수행(left: 배열의 시작 = 0, right: 배열의 끝 = 8) quick_sort(list, 0, n-1); // 정렬 결과 출력 for(i=0; i<n; i++){ printf("%d\n", list[i]); } }
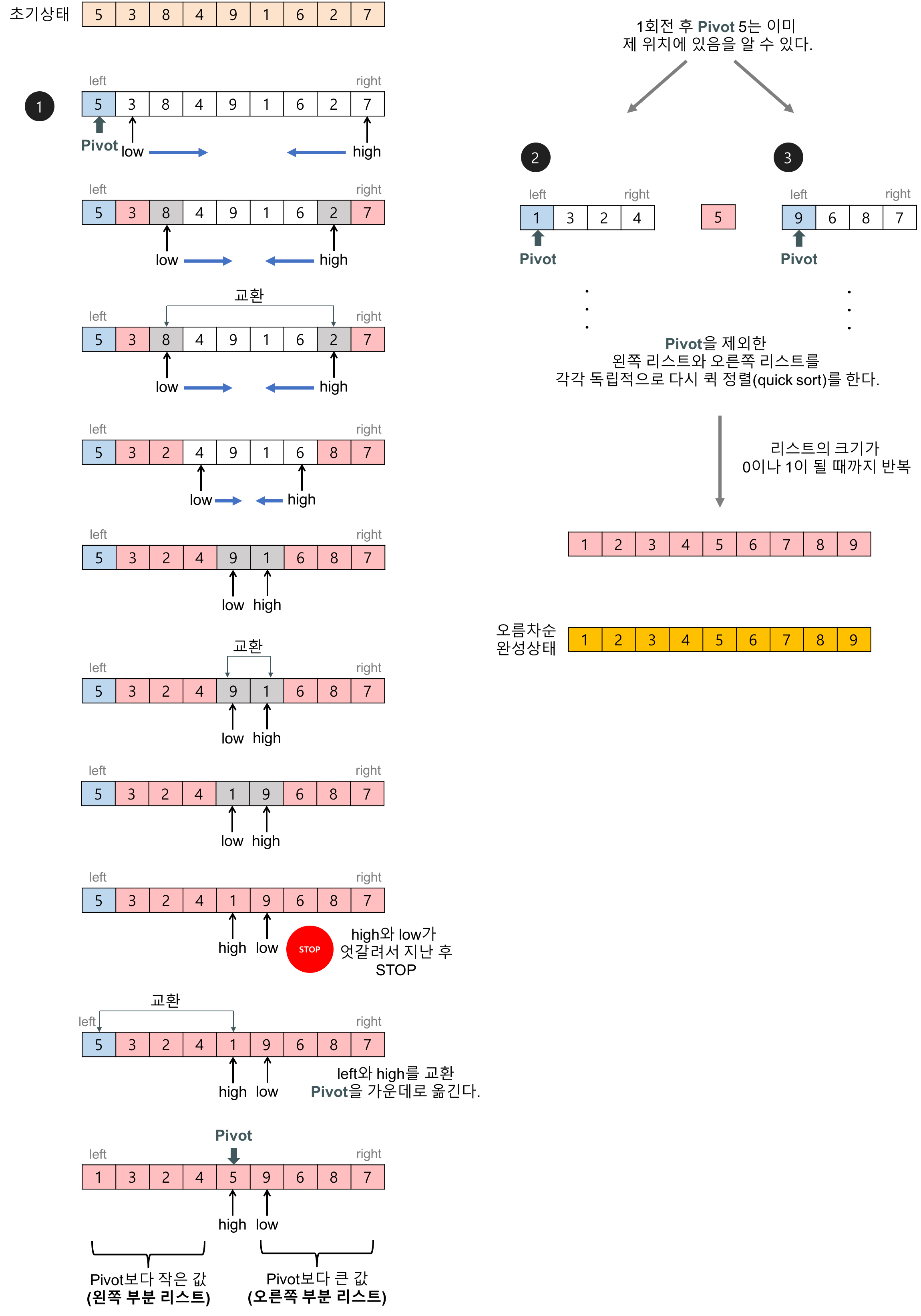

7. 힙 정렬(Heap Sort)
- 자료구조 힙(Heap)을 사용한 정렬
- 힙(Heap): 완전 이진 트리의 일종으로 우선순위 큐를 위해 만들어진 자료구조
- 최댓값, 최솟값을 쉽게 추출[루트]할 수 있는 자료구조
- 최대 힙 트리나 최소 힙 트리를 구성해 정렬
- 최대 힙: 내림차순 정렬
- 최소 힙: 오름차순 정렬
- 알고리즘
- 1. 힙 구성: 정렬할 N개 원소를 정렬 조건에 따라 최대힙 or 최소힙 구성해 정렬을 수행
- 2. 루트 원소 삭제: 루트 원소를 배열에 저장
- 3. 재배치: 삭제된 루트 원소를 채우기 위해 힙 재구성
- 최대 힙 삽입
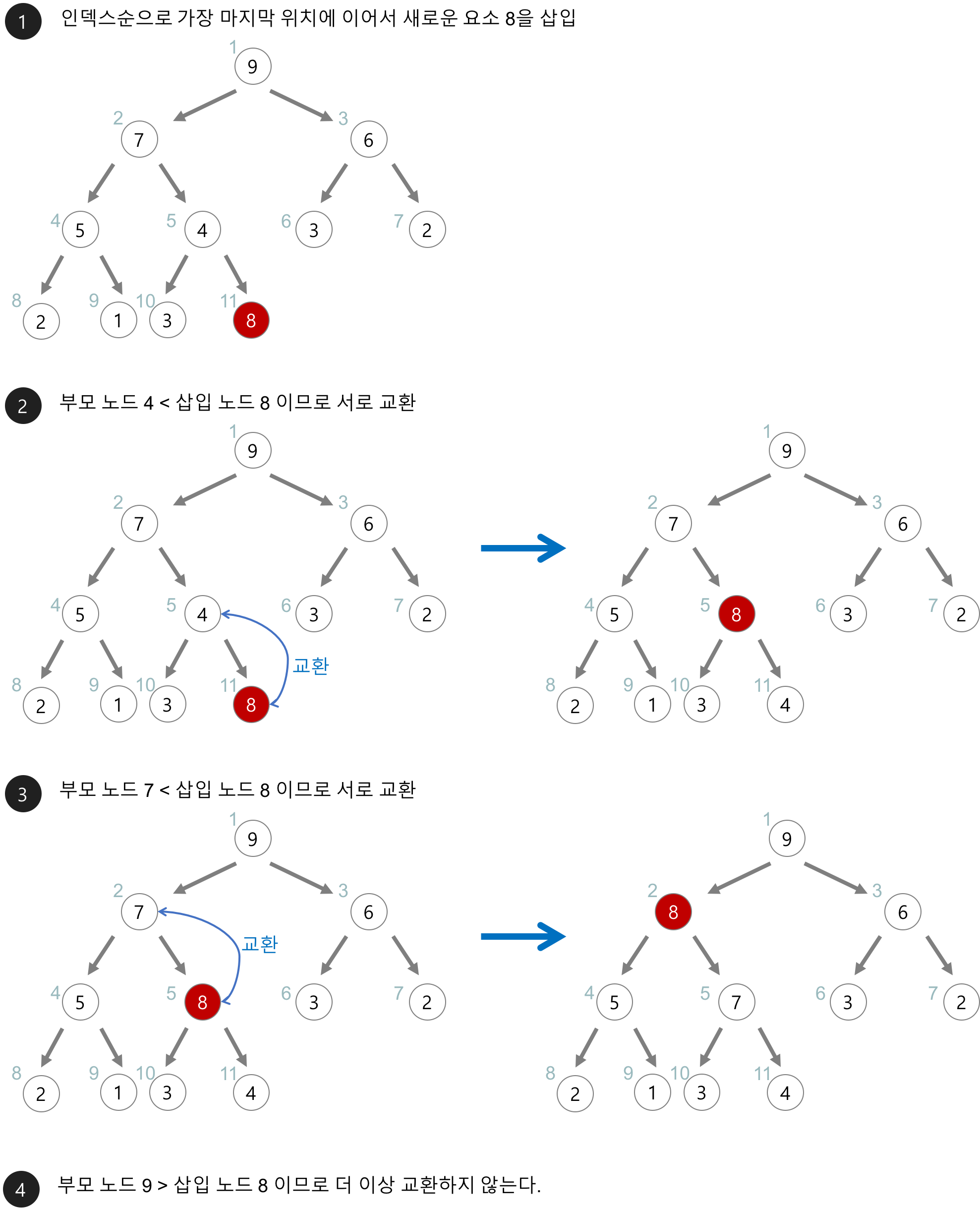
/* 현재 요소의 개수가 heap_size인 힙 h에 item을 삽입한다. */ // 최대 힙(max heap) 삽입 함수 void insert_max_heap(HeapType *h, element item){ int i; i = ++(h->heap_size); // 힙 크기를 하나 증가 /* 트리를 거슬러 올라가면서 부모 노드와 비교하는 과정 */ // i가 루트 노트(index: 1)이 아니고, 삽입할 item의 값이 i의 부모 노드(index: i/2)보다 크면 while((i != 1) && (item.key > h->heap[i/2].key)){ // i번째 노드와 부모 노드를 교환환다. h->heap[i] = h->heap[i/2]; // 한 레벨 위로 올라단다. i /= 2; } h->heap[i] = item; // 새로운 노드를 삽입 }
- 최대 힙 삭제
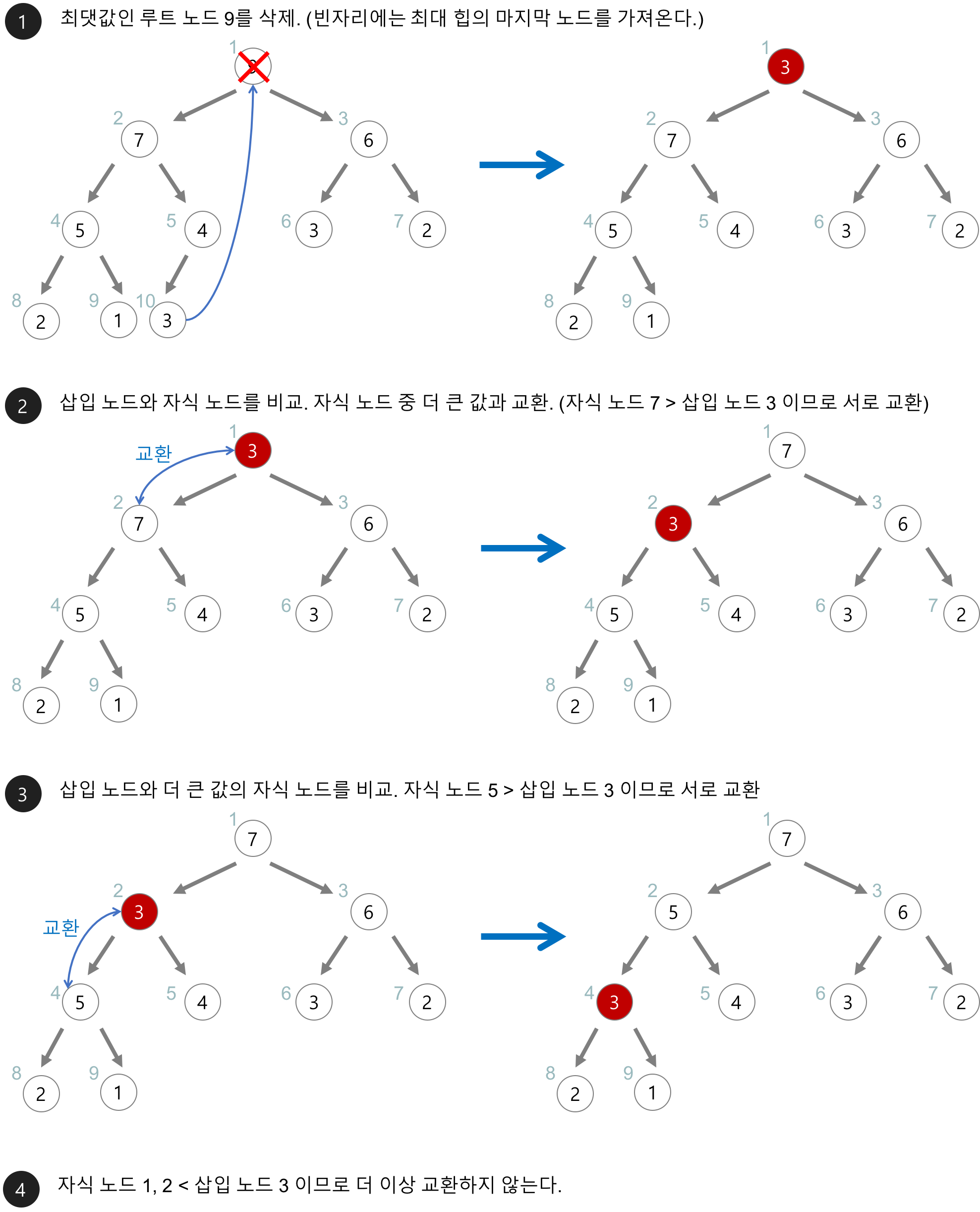
// 최대 힙(max heap) 삭제 함수 element delete_max_heap(HeapType *h){ int parent, child; element item, temp; item = h->heap[1]; // 루트 노드 값을 반환하기 위해 item에 할당 temp = h->heap[(h->heap_size)--]; // 마지막 노드를 temp에 할당하고 힙 크기를 하나 감소 parent = 1; child = 2; while(child <= h->heap_size){ // 현재 노드의 자식 노드 중 더 큰 자식 노드를 찾는다. (루트 노드의 왼쪽 자식 노드(index: 2)부터 비교 시작) if( (child < h->heap_size) && ((h->heap[child].key) < h->heap[child+1].key) ){ child++; } // 더 큰 자식 노드보다 마지막 노드가 크면, while문 중지 if( temp.key >= h->heap[child].key ){ break; } // 더 큰 자식 노드보다 마지막 노드가 작으면, 부모 노드와 더 큰 자식 노드를 교환 h->heap[parent] = h->heap[child]; // 한 단계 아래로 이동 parent = child; child *= 2; } // 마지막 노드를 재구성한 위치에 삽입 h->heap[parent] = temp; // 최댓값(루트 노드 값)을 반환 return item; }
- 힙 정렬 코드
// 우선순위 큐인 힙을 이용한 정렬 void heap_sort(element a[], int n){ int i; HeapType h; init(&h); for(i=0; i<n; i++){ insert_max_heap(&h, a[i]); } for(i=(n-1); i>=0; i--){ a[i] = delete_max_heap(&h); } }- 힙 정렬 특징
- [장점1]:
제자리 정렬: 추가 메모리 필요 X- [장점2]:
최선/평균/최악 O(nlogn): 평균적으로 좋음- [장점3]: 특정 기준에 맞는 값 X개가 필요할 때 유용
- [단점1]: 비안정 정렬: 값이 같은 원소의 순서 보장X
- [단점2]: 병합정렬보다 다소 느릴 수 있음(단, 메모리적으로 좋음)
- 시간 복잡도
- 최선:
- 평균[default]:
- 최악:


GAME DESIGN & CLIENT PROGRAMMING