시간복잡도
.. 참고
알고리즘을 구성하는 명령어들이 몇 번이나 실행이 되는지를 센 결과에 각 명령어의 실행시간을 곱한 합계를 의미
표기법
Big-O Notation(빅오표기법) : 실행 시간 n을 O(n)으로 표기한다. Big-O에서 차수가 가장 높은 최고차항만 두고 나머지는 버린다.

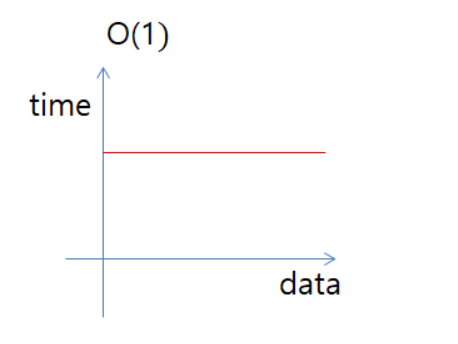
1. O(1) : 입력 데이터의 크기와 상관없이 언제나 일정한 시간이 걸리는 알고리즘을 말한다. (Constant Time) [중요]
- 입력되는 데이터양과 상관없이 일정한 실행 시간을 가진다.
- 알고리즘이 문제를 해결하는데 오직 한 단계만 거친다.예시.
- stack에 push하거나 pop할 때,
- hash table
예제 1)
function(int[] n) {
return (n[0] == 0) ? true : false;
}
예제 2)
function(int[] arrayOfItems) {
System.out.println(arrayOfItems[0]);
}
데이터가 증가함에 따라 성능에 변화가 없는 모습.
인자(=n)는 상관하지 않는다.
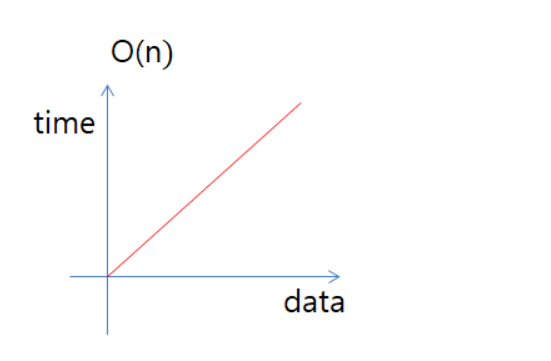
(즉, 상수는 항상 무시) - nO(1) = O(1) - 2*O(1) = 10*O(1) = O(1)2. O(n) : 입력 데이터의 크기에 비례해서 처리시간에 걸리는 알고리즘을 표현할 때 사용 (Linear Time) [중요]
- 데이터양에 따라 시간이 정비례한다.
- Linear search, for 문을 통한 탐색을 생각하면 된다.예시.
- traverse tree
- traverse linked list
예제 1)
function(int[] n) {
for i = 0 to n.length
}
예제 2)
function(int[] arrayOfItems) {
for (int item : arrayOfItems) { System.out.println(item); }
}
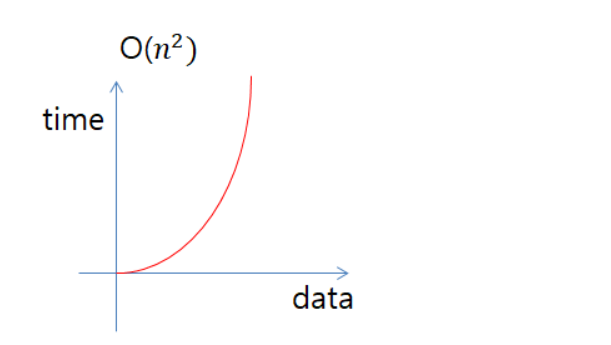
3. O(n^2) : Quadratic Time
- 데이터양에 따라 걸리는 시간은 제곱에 비례한다. (효율이 좋지 않음, 사용 X)
- 해당 유형은 이중 Loop내에서 입력 자료를 처리 하는 경우에 나타난다.
N값이 큰 값이 되면 실행 시간은 감당하지 못할 정도로 커지게 될 것이다.
- 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱예시.
- Insertion Sort(삽입정렬)
- Bubble Sort(거품정렬)
- Selection Sort(선택정렬)
4. O(nm) : (Quadratic time) - 2
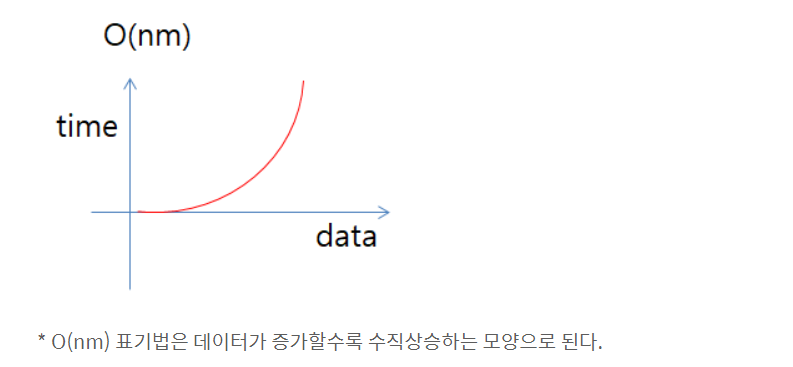
해당 표기법은 O(n^2)표기법과 비슷하지만 해당 표기법은 n은 엄청크고 m은 아주 작을수도 있기 때문에 변수가 다르다면 빅O표기법에도 반드시 다르게 표시하여야한다.
5. O(n^3) : (polynomial / cubic time)
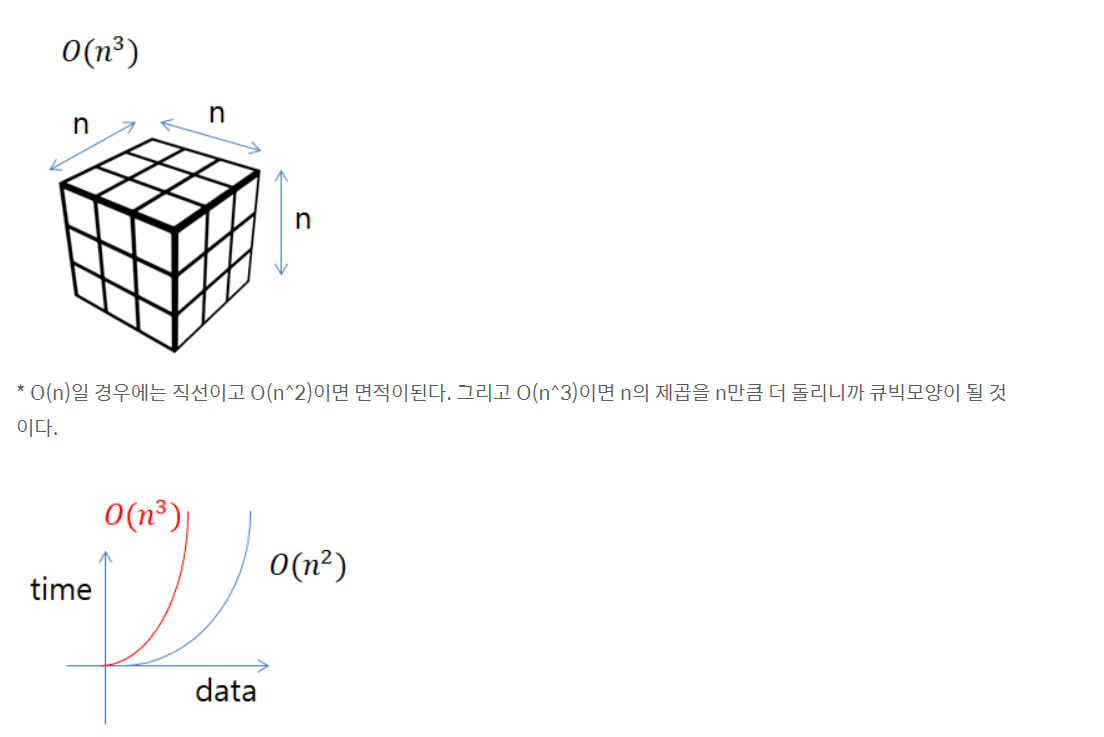
O(n^3)은 O(n^2)와 비슷한 양상을 보이지만 데이터가 늘어남에 따라 가로세로의 높이까지 더해지니까 아무래도 데이터가 증가함에따라 더 급격하게 처리시간이 늘어나는것을 위의 그래프로 확인할 수 있다.
6. O(2^n) : Fibonacci (Exponential Time) -> 해당 표기법은 피보나치수열과 유사하다.
7. O(m^n) : m개씩 n번 늘어나는 알고리즘을 표현(Exponential Time) 즉, 2대신에 m을 써서 표현하면 된다.
8. O(log n) : (Binary search tree access(이진 검색), search(검색), insertion(삽입), deletion(삭제)) [중요]
- 데이터양이 많아져도, 시간이 조금씩 늘어난다.
- 시간에 비례하여, 탐색 가능한 데이터양이 2의 n승이 된다.
- 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어든다.
- 만약 입력 자료의 수에 따라 실행 시간이 이 log N의 관계를 만족한다면
N이 증가함에 따라 실행시간이 조금씩 늘어난다.
주로 커다란 문제를 일정한 크기를 갖는 작은 문제로 쪼갤때 나타나는 유형이다.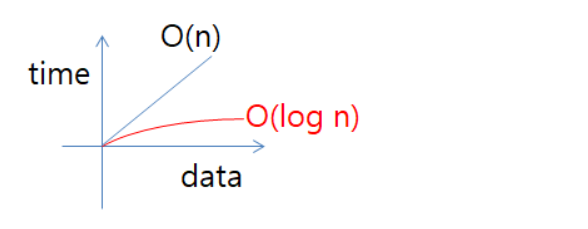
예제 1)
function(k, arr, s, e) {
if (s > e) return -1;
m = (s + e) / 2; // 주어진 range에 중간값을 찾는다.
if (arr[m] == k) {
r eturn m;
}// 찾는값이 중간값보다 작으면 중간지점 바로 전까지 range를 지정해서 다시 호출
else if (arr[m] > k) {
return function(k, arr, s, m-1);
}else {
return function(k, arr, m+1, e);
}
}찾는값이 중간값보다 크면 끝에서 다시 찾아야 하므로 가운데 번호 + 1부터 끝까지 호출하면 한번 함수가 호출될때마다
중간값을 기준으로 절반은 검색영역에서 제외시켜버리기 때문에 순차검색에 비교해서 속도가 현저하게 빠르다.
이렇게 한번 처리가 진행될때마다 검색해야하는 데이터의 양이 절반씩 떨어지는 알고리즘을 O(log n)알고리즘이라 한다.
9. O( Sqrt(n) ) : Square Root // Square Root는 제곱근이라고 한다.
10. O(nlog n) : Quick Sort(빠른 정렬), Merge Sort(병합 정렬), Heap Sort(힙 정렬)
- 데이터양이 N배 많아 진다면, 실행 시간은 N배 보다 조금 더 많아진다.
(정비례 하지 않음)
- 이 유형은 커다란 문제를 독립적인 작은 문제로 쪼개어 각각에 대해 독립적으로
해결하고, 나중에 다시 그것들을 하나로 모으는 경우에 나타난다.
N이 두배로 늘어나면 실행시간은 2배보다 약간 더 많이 늘어난다.Hash
...참고
사전적의미 (잘게썬)
- 임의의 크기를 가진 데이터(Key)를 고정된 크기의 데이터(Value)로 변화시켜 저장하는 것
- 키에 대한 해시값을 사용하여 값을 저장하고 키-값 쌍의 갯수에 따라 동적으로 크기가 증가하는 연관배열이다
- 키에 대한 해시값을 구하는 과정을 hashing(해싱)이라고 하며 이때 사용하는 함수(알고리즘)를 해시함수 라고 한다
- 해시값 자체를 index로 사용하기 때문에 평군 시간복잡도가 O(1) 로 매우 빠르다
직접 주소 테이블(Direct Address Table)
해시 테이블의 아이디어는 직접 주소 테이블이라는 자료구조에서 부터 출발한다. 직접 주소 테이블은 입력받은 value가 곧 key가 되는 데이터 매핑 방식이다.
이렇게 직접 주소 테이블은 값에 접근하기는 편하지만 공간 효율이 좋지 않다는 단점이 있다. 그래서 이 단점을 보완한 게 바로 해시 테이블인 것이다.
해시 테이블은 직접 주소 테이블처럼 값을 바로 테이블의 인덱스로 사용하는 것이 아니라 해시 함수(Hash Function)이라는 것에 한번 통과시켜서 사용한다. 해시 함수는 임의의 길이를 가지는 임의의 데이터를 고정된 길이의 데이터로 매핑하는 함수이다. 이때 이 함수가 뱉어내는 결과물을 해시(Hash)라고 부른다.
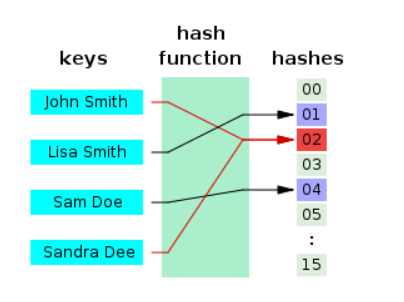
위 이미지는 해시함수가 서로 다른 두 개의 키에 대해 동일한 해시값을 내는 경우로,
h(k1) == h(k2) 성립하면 해시 충돌이 발생 했다고 한다. (h : 해시함수. k1, k2 : 임의의 key값) 이때, k1, k2 를 동의어(synonym)라 한다.
< 해시 충돌 처리 방법 >
Chaining
해시 충돌이 일어나면 연결 리스트 형태로 이어 나가 충돌을 처리하는 기법

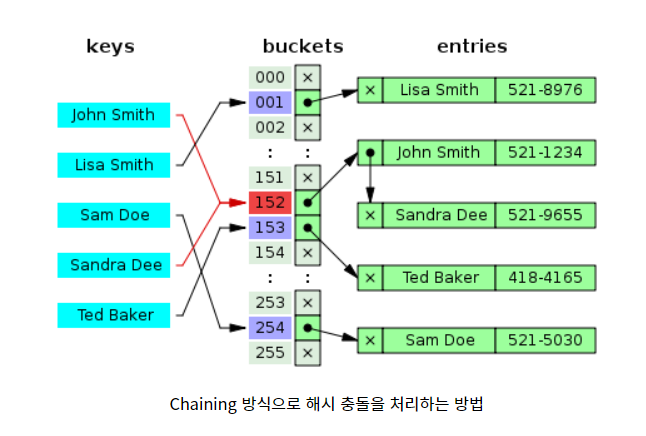
시간 복잡도 분석
최악의 경우 : O(n)
평균 적인 경우 : O(α) (α : 버킷당 평균 요소의 개수)
Open adressing
개방 주소법은 해시 충돌이 발생하면 테이블 내의 새로운 주소를 탐사(Probe)한 후, 비어있는 곳에 충돌된 데이터를 입력하는 방식이다. 해시 함수를 통해서 얻은 인덱스가 아니라 다른 인덱스를 허용한다는 의미로 개방 주소(Open Address)라고 한다.
- 선형 조사법(Linear probing) : 해시충돌 시 고정폭(ex : 1칸)을 옮겨 다음 버킷을 조사하는 방법
 선형 탐사법의 단점은 특정 해시 값의 주변이 모두 채워져있는 일차 군집화(Primary Clustering)문제에 취약하다는 것이다.
선형 탐사법의 단점은 특정 해시 값의 주변이 모두 채워져있는 일차 군집화(Primary Clustering)문제에 취약하다는 것이다.
- 이차 조사법(Quadratic probing) 또는 제곱 탐사법 : 해시충돌 시 제곱수 만큼 건너 뛰어 버킷을 조사하는 방법(1,4,9,...)
첫번째 충돌이 발생했을 때는 충돌난 지점으로 부터 1^2 만큼,
두번째 충돌이 발생했을 때는 2^2,
세번째는 3^2 과 같은 식으로 탐사하는 스텝이 빠르게 커진다.
이렇게 제곱 탐사법을 사용하면 충돌이 발생하더라도 데이터의 밀집도가 선형 탐사법보다 많이 낮기 때문에 다른 해시값까지 영향을 받아서 연쇄적으로 충돌이 발생할 확률이 많이 줄어든다.
그래도 결국 데이터의 군집은 피할 수 없는 숙명이므로 이 현상을 이차 군집화(Secondary Clustering)이라고 부른다. - 이중 해싱(Double hashing) (or rehashing) : 충돌 시 다른 해시 함수를 적용하는 방법

테이블 크기 재할당(Resizing)

