
DRF pagination
Pagination은 서버에서 데이터를 조회할 때 일정한 크기의 덩어리(chunk)로 나눠서 표시하는 것으로 다음의 이유로 사용된다.
-
성능 개선
서버에서 한 번에 많은 양의 데이터를 가져올 경우 서버 부하가 매우 커질 수 있다.
Pagination을 사용하면 한 번에 가져오는 데이터 양을 조절할 수 있기 때문에 서버 부하를 줄일 수 있다. -
사용자 편의
한 번에 많은 양의 데이터가 보여지게 되면 사용자가 원하는 정보를 찾기 어려울 수 있다.
Pagination을 사용하면 사용자가 데이터를 찾기 수월해지고 모바일 기기의 경우 데이터 조회에 걸리는 시간과 데이터 사용량을 줄일 수 있다. -
코드 간소화
DRF에 구현돼있는 pagination 클래스를 상속하여 쉽게 구현할 수 있다. 이를 통해 코드를 간소화할 수 있다.
사용법
공식문서를 통해 알 수 있듯이 여러가지 방법이 있지만 가장 보편적으로 쓰이는 방식인 PageNumberPagination을 사용했다.
전역 설정
기본적으로 settings.py에 다음 코드를 작성하면 전역적으로 pagination을 사용할 수 있다.
REST_FRAMEWORK = {
...
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',
'PAGE_SIZE': 100
...
}PAGE_SIZE는 한번에 표시할 덩어리(chunk)의 양을 의미한다.
전역적으로 사용되지만 필요에 따라 custom해서 사용도 가능하다.
custom 설정
- custom을 위해 필요한 import를 작성한다.
from rest_framework.pagination import PageNumberPagination- 해당 클래스를 상속해서 수정하고자 하는 값을 설정한다.
- pagination 클래스를 따로 모듈화 해도 되고 사용하고자 하는 파일에 같이 위치시켜도 상관 없다.
class LargeResultsSetPagination(PageNumberPagination):
page_size = 1000
page_size_query_param = 'page_size'
max_page_size = 10000
class StandardResultsSetPagination(PageNumberPagination):
page_size = 100
page_size_query_param = 'page_size'
max_page_size = 1000공식문서 해석
custom하기 위해 상속한 PageNumberPagination을 타고 가보면 오버라이딩 한 각각의 속성값들이
page_size = api_settings.PAGE_SIZE
page_size_query_param = None
max_page_size = None인 것을 알 수 있다.
전역 설정을 한 경우 page_size는 그 값을 따르지만 지금과 같이 오버라이딩 하게되면 전역 설정값을 따르지 않게 된다.
따라서 상속을 통해 재정의 한 위의 두 클래스를 사용하게 되면 필요한 경우에 필요한 값을 지정해서 사용할 수 있게 된다.
나머지 page_size_query_param, max_page_size의 경우는 클라이언트가 page_size를 조절할 수 있도록 값을 부여하는 것으로 기본 그대로 사용한다면 클라이언트가 pagination을 조절할 수 없다는 뜻이다.
공식문서와 같이 값을 지정한다면
page_size_query_param = 'page_size'
max_page_size = 1000 클라이언트는 'page_size'라는 파라미터를 사용해서 pagination을 조절할 수 있게 된다. max_page_size는 페이지의 크기를 제한하는 속성으로 설정한 값보다 큰 값을 요청하게 되면 제한된 만큼의 데이터를 반환하게 된다.
따라서 page_size_query_param값이 지정되지 않았다면 의미를 가지지 않게 되는 속성이다.
해당 기능이 필요하지 않다면 굳이 이 두가지는 오버라이딩 하지 않아도 된다.
- custom한 pagination 적용
(공식문서 예시에서는 generics import가 같이 적혀있지않다. import error가 나면 상단 import를 추가해준다.)
from rest_framework import generics
공식문서 예시
class BillingRecordsView(generics.ListAPIView):
queryset = Billing.objects.all()
serializer_class = BillingRecordsSerializer
pagination_class = LargeResultsSetPagination
코드 적용 예시
class ProductFeedView(generics.ListAPIView):
queryset = Product.objects.filter(
transaction_status=0).order_by('-refreshed_at')
serializer_class = ProductFeedSerializer
pagination_class = StandardResultsSetPagination공식문서와 코드 적용 예시를 비교해보면 알 수 있듯이 View 네이밍과 queryset조건은 필요에 맞게 작성해주고
serializer_class → 사용할 serializer를
pagination_class → 적용할 custom pagination_class를 적용해주면 된다.
적용
class StandardResultsSetPagination(PageNumberPagination):
page_size = 2
class ProductFeedView(generics.ListAPIView):
queryset = Product.objects.filter(
transaction_status=0).order_by('-refreshed_at')
serializer_class = ProductFeedSerializer
pagination_class = StandardResultsSetPagination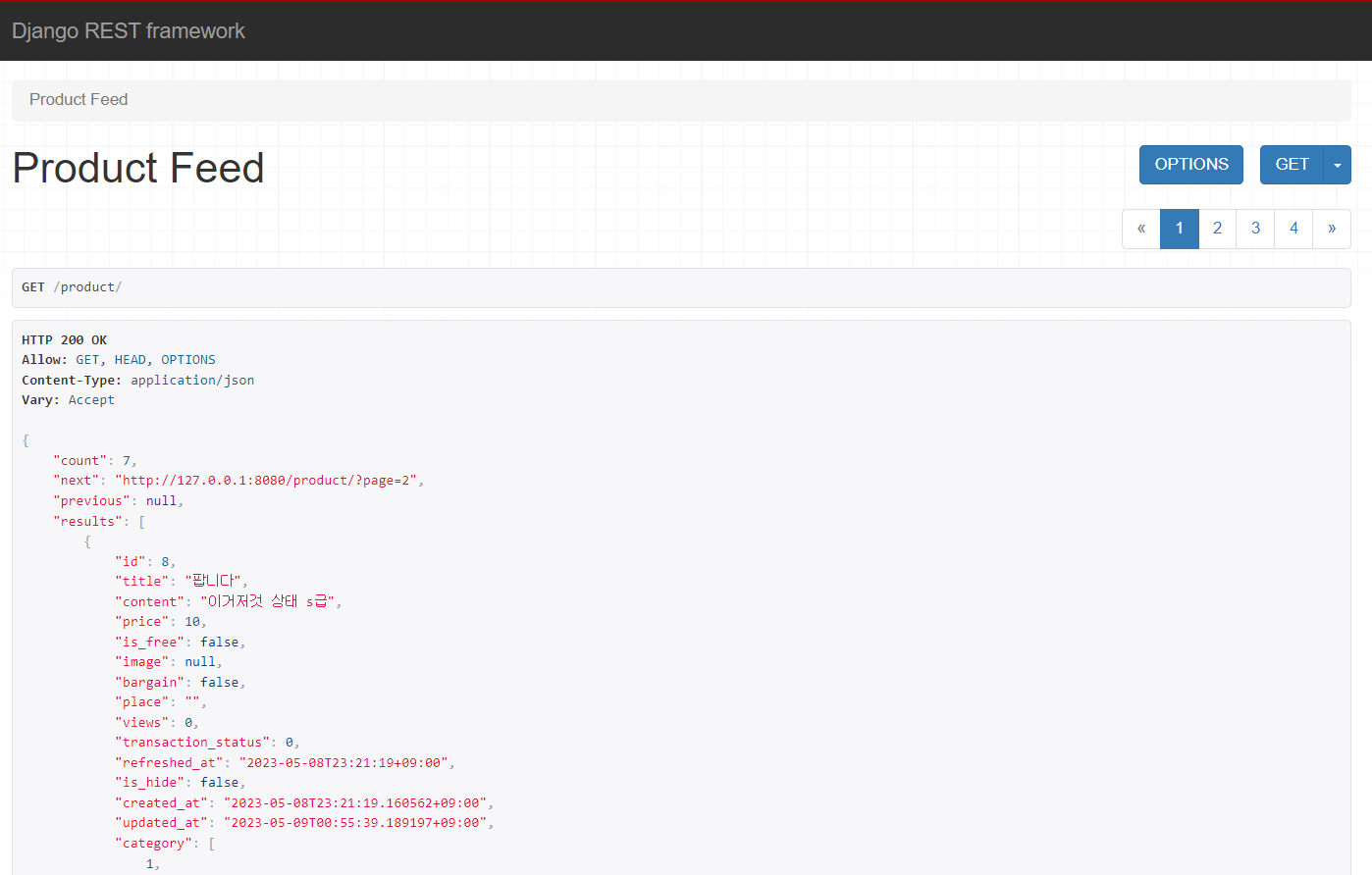
총 7개의 데이터를 page_size를 2로 설정했을때 body부분에서 count, next, previous, result가 생겼고 우측 상단에 페이지가 생긴 것을 볼 수 있다.
count는 데이터의 개수
next는 다음 페이지의 url
previous는 이전 페이지의 url
result는 현재 페이지에서 보여지는 데이터
에 해당한다.
7개의 데이터를 2개씩 보여주니 총 4개의 페이지가 만들어 졌고 page_size에 따라 페이지 수도 다르게 나오게 된다.
