자연어처리란?
- 인공지능 분야로부터 파생된 영역
- 기계가 스스로 생각하고 판단할 수 있도록 하는 인공지능 생성을 위해서는 기계가 인간의 언어를 이해할 수 있도록 하는 과정이 필수적이다.
따라서 컴퓨터가 인간의 언어인 자연어를 이해하고, 처리할 수 있도록 하는 자연어 처리 과정이 중요하게 되었다.
자연어 분석의 4단계
1) 형태소 분석 (Morphological Analysis)
2) 구문 분석 (Syntax Analysis)
3) 의미 분석 (Semantic Analysis)
4) 화용 분석 (Pragmatic Analysis)
1) 형태소 분석
: 입력된 문자열을 "형태소"라는 "최소 의미 단위로 분리"하는 단계
- 사전 정보와 형태소 결합 정보 이용
- 정규 문법으로 분석 가능
- 언어에 따라 난이도 다름
(영어,불어 : 쉬움 / 한국어,일본어,아랍어,터키어 : 어려움)
형태소 분석의 난점
- 고유명사, 사전에 등록되지 않은 단어를 처리하기 어려움
- 띄어쓰기가 없으면 형태소 분석이 어려워짐
- 접두사, 접미사 처리
- 중의성을 지님 (ambiguity)
ex) "감기는"의 분석 결과
=> (1) 감기(명사) + 는(조사)
(2) 감기(동사 어간) + 기(명사화 어미) + 는(조사)
(3) 감(동사 어간) + 기(어미)
--> 형태소 분석 단계와 관련된 자연어 처리 Task
- Word Segmentation (단어 분리)
- Morphological Analysis (형태소 분석)
- Part of Speech(POS) Tagging (품사 태깅)
2) 구문 분석
: 문자의 "구조를 분석" (=파싱(parsing))하는 단계
-> grammer rule에 따라 문장에 대한 문법 구조를 분석하여 구문 트리로 나타냄
ex) 문법 구조 분석 결과
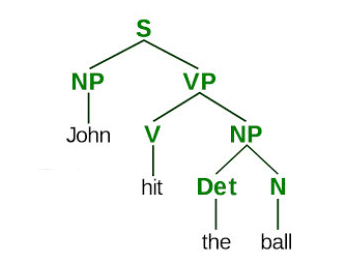
& 문장이 "문법적으로 옳은가" 판단.
단, 이 경우에는 어순이 문법에 틀리지만 않으면 틀린 문장으로 인식되지 않음.
ex)
(1) The dog bit the boy. (o)
(2) The boy bit the dog. (o)
(3) Bit boy dog the the. (x)
(2) 의 경우 의미는 이상하나, 문법 구조 자체는 틀리지 않으므로 올바른 문장으로 인식함.
--> 구문 분석의 난점
구조적 중의성(Structural Ambiguities)
: 하나의 문장이 다수의 구조로 해석될 수 있어, 어떠한 구문 분석기를 쓰는지에 따라 구문 분석의 결과가 달라질 수 있음.
--> 구문 분석 단계와 관련된 자연어 처리 Task
- Phrase Chunking (간단하게 문장을 잘라주는 것)
- Dependency Parsing (구문 분석)
3) 의미 분석 (Semantic Analysis)
: 통사 분석 결과에 "해석을 가하여" 문장이 가진 "의미를 분석"
- 형태소가 가진 의미를 표현하는 지식 표현 기법이 요구됨.
- 해당 단계에서는 위의 구문 분석에서는 옳다고 인식된 문장 (The boy bit the dog.)이 통사적으로는 옳으나 의미적으로는 틀린 문장으로 인식됨. => 구문 분석의 결과 보완 가능
- 동형이의어, 동음이의어, 다의어의 의미를 정확히 파악하여 문장 전체의 의미를 이해함
(같은 syntax tree 안에 있는 단서(단어 등)을 가지로 여러 동형이의어/동음이의어/다이어 중 의미가 맞는 경우의 의미를 채택)
--> 의미 분석 단계와 관련된 자연어 처리 Task
- Word Sense Disambiguation(WSD)
- Semantic Role Labeling(SRL)
- Semantic Parsing
- Textual Entailment
4) 화용 분석 (Pragmatic Analysis)
: 문맥을 통해 문장의 의미와 "화자의 의도"를 파악하는 분석
ex)
Q. '오늘 날씨 어때?'
A. '지금 비가 오는 중이야" -> (1) 질문에 대한 답변으로 "단순 사실 전달의 목적"
(2) 아침에 급히 집을 나서는 자녀에게 우산을 가져가라고 우회적으로 말하는 목적일수도
--> 화용 분석 단계와 관련된 자연어 처리 Task
- Co-reference/Anaphora Resolution(대명사의 지시 대상)
- Ellipsis Resolution
이와 같은 자연어처리 기법이 잘 적용되기 위해서는, 기계가 자연어를 잘 인식하여 분석할 수 있도록 용도에 맞게 텍스트를 처리하는 텍스트 전처리(preprocessing)과정이 필요하다.
해당 본문에서 의미하는 텍스트 전처리는 사전 크롤링 과정에서 이미 필요없는 url, hypertext 및 각종 특수문자들이 제거된 상태의 텍스트 전처리를 의미한다.
자연어처리를 위한 전처리(Preprocessing)
- 토큰화(Tokenization)
- 정제(Cleaning) & 정규화(Normalization)
- 원-핫 인코딩(One-hot Encoding)
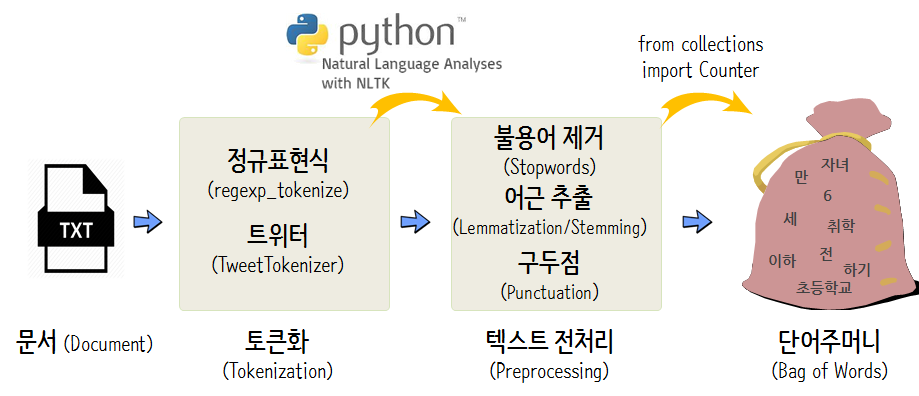
이미지 출처 ) http://aispiration.com/text/nlp-intro-python.html
크롤링된 자연어 데이터는 현재 문자열(string)형태일 것이다. 자연어처리를 진행하기 위해서는 해당 문자열(string) 데이터를 다차원 벡터(vector) 데이터로 변환해주어야 한다.
문자열(string) -> 벡터(vector) 변환은 one-hot-encoding을 통해 이루어질 수 있다. 이때, 문자열 벡터 변환은 크롤링한 문자열을 통으로 변환하는 것이 아닌, 문자열을 단어, 형태소 등의 토큰으로 분해한 후, one-hot-encoding 을 통해 각각의 토큰들을 벡터로 변환한다.
따라서 자연어처리를 위한 전처리 과정은 크게
1) 토큰화(tokenization) -> 2) 정제(cleaning) & 정규화(normalization) -> 3) 인코딩(원-핫 인코딩) 으로 진행된다고 이해할 수 있다.
1. 토큰화 (Tokenization)
(1) 단어 토큰화 (Word Tokenization)
- 토큰의 기준을 단어(word)로 하는 경우
Don't worry about studying python. BADA's sessions will lead you.
Q. 이와 같이 어퍼스트로피(')가 들어간 문장에서 Don't와 BADA's는 어떻게 토큰화할 수 있을까?
A. ex)Don't
Don t
Dont
Do n't
BADA's
BADA s
BADA
BADAs
위의 예시 정답 중 자신이 원하는 결과가 나오도록 직접 토큰화 도구를 설계할 수 있겠지만, 기존에 존재하는 도구들을 사용하였을 때의 결과가 자신의 목적과 동일하다면 기존의 도구를 활용할 수 있을 것이다.
from nltk.tokenize import word_tokenize
from nltk.tokenize import WordPunctTokenizer
from tensorflow.keras.preprocessing.text import text_to_word_sequenceNLTK ; 영어 코퍼스(corpus)를 토큰화하기 위한 도구 제공
1) word_tokenize
print('단어 토큰화_word_tokenize사용: ',
word_tokenize("Don't worry about studying python. BADA's sessions will lead you."))단어 토큰화_word_tokenize사용: ['Do', "n't", 'worry', 'about', 'studying', 'python', '.', 'BADA', "'s", 'sessions', 'will', 'lead', 'you', '.']word_tokenize는 Don't를 Do와 n't로 분리하였으며, 반면 BADA's는 BADA와 's로 분리한 것을 확인할 수 있다.
그렇다면, WordPunctTokenizer는 어퍼스트로피(')가 들어간 코퍼스(corpus)를 어떻게 처리할까?
print('단어 토큰화_WordPunctTokenizer 사용: ',WordPunctTokenizer().tokenize("Don't worry about studying python. BADA's sessions will lead you.") 단어 토큰화_WordPunctTokenizer 사용: ['Don', "'", 't', 'worry', 'about', 'studying', 'python', '.', 'BADA', "'", 's', 'sessions', 'will', 'lead', 'you', '.']WordPunctTokenizer는 구두점을 별도로 분류하는 특징을 갖고 있기때문에, 앞서 확인했던 word_tokenize와는 달리 Don't를 Don과 '와 t로 분리하였으며, 이와 마찬가지로 BADA's를 BADA, ', s로 분리한다.
tensorflow의 keras 또한 토큰화 도구로서 text_to_word_sequence를 지원한다.
print('단어 토큰화_text_to_word_sequence: ', text_to_word_sequence("Don't worry about studying python. BADA's sessions will lead you.") 단어 토큰화_text_to_word_sequence: ["don't", 'worry', 'about', 'studying', 'python', "bada's", 'sessions', 'will', 'lead', 'you']케라스의 text_to_word_sequence는 기본적으로 모든 알파벳을 소문자로 바꾸면서 마침표나 컴마, 느낌표 등의 구두점을 제거한다. 하지만 don't나 jone's와 같은 경우 아포스트로피는 보존하는 것을 확인할 수 있다.
정리)
** 토큰화
(1) word_tokenize :
Don't -> Do / n't
BADA's -> BADA / 's(2) WordPunctTokenizer().tokenize : 구두점 별도 분류
Don't -> Don / ' / t
BADA's -> BADA / ' / s(3) text_to_word_sequence : 모두 소문자로 변환 & 마침표, 컴마, 느낌표 등의 구두점 제거, 어퍼스트로피(') 보존
Don't -> don't
BADA's -> bdad's
SO, 토큰화에서 고려해야할 사항
- 위에서 각 3개의 토큰화 도구가 각기 다른 결과값을 보이는 것과 같이, 토큰화 작업은 단순히 corpus 에서 구두점을 제외하고 공백 기준으로 잘라내는 작업이 아니다.
그렇기에 토큰화 작업은 보다 섬세한 작업이 요구되는 데 대표적으로 고려해야할 사항은 다음과 같다.
1) 구두점 or 특수 문자를 단순 제외해서는 안된다.
- 구두점 : 문장의 종결을 표현하므로, 문장의 경계를 알 수 있다. 따라서 단어 토큰화 진행시 마침표를 제거하지 않을 수 있다.
문장의 종결 표현뿐만 아니라, 구두점은 ph.D와 같은 경우에도 사용될 수 있는데 이러한 경우에는 구두점을 무분별하게 제거할 경우, 내용이나 단어의 의미가 손실될 수 있으므로 주의해야 한다. - 특수문자 : $45.55의 경우, 45와 55를 따로 분류하는 것이 아닌 45.55 하나로 취급하고자 할 때가 있으므로 주의해야한다.
2) 줄임말 or 단어 내에 띄어쓰기가 있는 경우
- 어퍼스트로피(')는 주로 압축된 단어를 다시 펼치는 역할을 하기도 한다. 즉, 단어가 줄임말로 쓰이는 경우 어퍼스트로피가 쓰인다. 예를 들어 we're -> we are을 의미하는데, 'we', 're'로 토큰화를 진행하게 되면 그 의미가 손실될 수 있다.
ㅡ New York과 같이 단어 내 띄어쓰기가 있는 경우, 띄어쓰기까지 포함하여 하나의 토큰으로 봐야하는 경우도 있다.
그렇기에 토큰화 작업은 이러한 단어들도 하나로 인식할 수 있어야 한다.
(2) 문장 토큰화 (Sentence Tokenization) (=문장 분류(Sentence Segmentation)
: 토큰 단위가 문장(Sentence)인 경우
Q. 코퍼스(Corpus)로부터 문장 단위로 분류할 수 있을까?
A. (예상답변) 마침표(.)나 ?/! 등을 기준으로 문장을 자르면 되지 않을까?
Q. 그럼 "Since I'm actively looking for Ph.D. students, I get the same question a dozen times every year." or " IP 192.168.56.31 서버에 들어가서 로그 파일 저장해서 aaa@gmail.com로 결과 좀 보내줘. 그 후 점심 먹으러 가자." 이러한 문장들은 어떻게 토큰화될까?
이처럼 문장의 끝이 아님에도 마침표(.)가 사용되는 경우가 존재한다. 따라서 ./?/! 와 같은 문장 부호가 문장의 끝에 쓰인 것인지 기계학습 또는 규칙 기반으로 분류할 필요성이 있다.
이를 위해 앞/뒤글자(prefix/suffix)나 토큰이 문맥상으로 문장의 종결점에 있는 것인지의 여부를 판단해야한다.
단어 토큰화와 마찬가지로 이러한 조건들을 모두 포함한 토큰화 도구를 스스로 작성할 수 있지만, 영어의 경우 NLTK의 sent_tokenize / 한글의 경우 kss(Korean Sentence Splitter)를 사용하여 문장 토큰화를 진행하면 위와 같은 문제를 어느정도 고려하여 문장 토큰화를 진행하므로 기존의 툴을 사용하는 것도 추천한다.
(1) NLTK - sent_tokenize(text)
from nltk.tokenize import sent_tokenize text = "Since I'm actively looking for Ph.D. students, I get the same question a dozen times every year."
print('문장 토큰화 :', sent_tokenize(text))문장 토큰화 : ["Since I'm actively looking for Ph.D. students, I get the same question a dozen times every year."](2) kss - split_sentences(text)
pip install kss
import kss text = "딥 러닝 자연어 처리가 재미있지만, 문제는 영어보다 한국어로 전처리하는 것이 너무 어렵습니다. 자, 잘 모르시겠다고요? 이제 해보면 깨달을지도 몰라요...."
print('한국어 문장 토큰화 :', kss.split_sentences(text))한국어 문장 토큰화 : ['딥 러닝 자연어 처리가 재미있지만, 문제는 영어보다 한국어로 전처리하는 것이 너무 어렵습니다.', '자, 잘 모르시겠다고요?', '이제 해보면 깨달을지도 몰라요....']정상적으로 모든 문장이 분리된 것을 확인할 수 있다.
한국어 토큰화의 어려움
- 한국어의 경우 거의 대부분에서 단어 단위로 띄어쓰기가 이루어지지 않고, 다양한 조사(가/에게/를/와..)가 사용되기 때문에 자연어 처리를 하다보면 같은 단어임에도 서로 다른 조사가 붙어서 다른 단어로 인식이 되는 경우가 있다. 따라서 대부분의 한국어 NLP에서 조사는 분리해 줄 필요가 있다.
즉, 영어와 같이 띄어쓰기 단위가 독립적인 단어라면 띄어쓰기를 기준으로 토큰화를 진행하면 되지만, 한국어의 경우 어절이 독립적인 단어로 구성되는 것이 아닌 조사 등 무언가 결합되어 있는 경우가 많아 이를 전부 분리해주어야 한다는 것이다.
Q. 그렇다면 이러한 어려움을 어떻게 극복할 수 있을까?
품사 태깅 (POS tagging ; Part-of-speech tagging)
단어의 표기는 같아도 품사에 따라 단어 의미가 달라지기도 한다.
ex) fly (동사 ; 날다 / 명사 ; 파리 )
못 (명사 ; 망치를 사용하여 목재 따위를 고정하는 물건 / 부사 ; 동사를 할 수 없다 )
따라서 문맥 안에서 단어의 의미를 제대로 파악하기 위해서는 해당 단어가 어떤 품사로 쓰였는지 보는 것이 주요 지표가 될 수 있다. 그리고 이러한 각 단어가 어떤 품사로 쓰였는지를 구분하는 작업을 품사 태깅(POS tagging)이라고 한다.
품사태깅을 도와주는 도구
(영어) NLTK - Penn Treebank POS Tags
(한국어) KoNLPy - Okt, Kkma
(1) 영어 ; NLTK - pos_tag
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag text = "I am actively looking for Ph.D. students. and you are a Ph.D. student."
tokenized_sentence = word_tokenize(text)
# 단어 기준 토큰화 진행
tokenized_sentence = word_tokenize(text)
print('단어 토큰화 :',tokenized_sentence)
# 토큰화 된 단어에 품사 태깅
print('품사 태깅 :',pos_tag(tokenized_sentence))단어 토큰화 :
['I', 'am', 'actively', 'looking', 'for', 'Ph.D.', 'students', '.', 'and', 'you', 'are', 'a', 'Ph.D.', 'student', '.']
품사 태깅 :
[('I', 'PRP'), ('am', 'VBP'), ('actively', 'RB'), ('looking', 'VBG'), ('for', 'IN'), ('Ph.D.', 'NNP'), ('students', 'NNS'), ('.', '.'), ('and', 'CC'), ('you', 'PRP'), ('are', 'VBP'), ('a', 'DT'), ('Ph.D.', 'NNP'), ('student', 'NN'), ('.', '.')]*참고
Penn Treebank POG Tags에서 PRP는 인칭 대명사, VBP는 동사, RB는 부사, VBG는 현재부사, IN은 전치사, NNP는 고유 명사, NNS는 복수형 명사, CC는 접속사, DT는 관사를 의미
(2) 한국어 ; konlpy.tag - Okt, Kkma
한국어 자연어처리를 위해서는 KoNLPy(코엔엘파이)라는 파이썬 패키지 이용 가능
-
KoNLPy를 통해 사용가능한 형태소 분석기
: Okt(Open korean text), 메캅(Mecab), 코모란(Komoran), 한나눔(Hannanum), 꼬꼬마(Kkma)아래의 예시에서는 Okt와 Kkma(꼬꼬마) 두 개의 형태소 분석기를 사용하여 토큰화 수행
from konlpy.tag import Okt
from konlpy.tag import Kkma okt = Okt()
Kkma = Kkma()
print('OKT 형태소 분석:', okt.morphs('딥 러닝 자연어 처리가 재미있지만, 문제는 영어보다 한국어로 전처리하는 것이 너무 어렵습니다'))
print('OKT 품사 태깅 :', okt.pos('딥 러닝 자연어 처리가 재미있지만, 문제는 영어보다 한국어로 전처리하는 것이 너무 어렵습니다'))
print('OKT 명사 추출 :', okt.nouns('딥 러닝 자연어 처리가 재미있지만, 문제는 영어보다 한국어로 전처리하는 것이 너무 어렵습니다'))
OKT 형태소 분석:
['딥', '러닝', '자연어', '처리', '가', '재미있지만', ',', '문제', '는', '영어', '보다', '한국어', '로', '전', '처리', '하', '는', '것', '이', '너무', '어렵습니다']
OKT 품사 태깅 :
[('딥', 'Noun'), ('러닝', 'Noun'), ('자연어', 'Noun'), ('처리', 'Noun'), ('가', 'Josa'), ('재미있지만', 'Adjective'), (',', 'Punctuation'), ('문제', 'Noun'), ('는', 'Josa'), ('영어', 'Noun'), ('보다', 'Josa'), ('한국어', 'Noun'), ('로', 'Josa'), ('전', 'Modifier'), ('처리', 'Noun'), ('하', 'Suffix'), ('는', 'Josa'), ('것', 'Noun'), ('이', 'Josa'), ('너무', 'Adverb'), ('어렵습니다', 'Adjective')]
OKT 명사 추출 :
['딥', '러닝', '자연어', '처리', '문제', '영어', '한국어', '처리', '것']한국어 NLP 전처리에서 형태소 분석기를 사용하는 것은 굉장히 유용한데, 위 예제에서 형태소 추출과 품사 태깅 메소드의 결과를 보면 조사를 기본적으로 분리하고 있음을 확인할 수 있다.
이번에는 Kkma(꼬꼬마) 형태소 분석기를 사용하여 같은 문장에 대해 토큰화를 진행해보자.
print('꼬꼬마 형태소 분석:', kkma.morphs('딥 러닝 자연어 처리가 재미있지만, 문제는 영어보다 한국어로 전처리하는 것이 너무 어렵습니다'))
print('꼬꼬마 품사 태깅 :', kkma.pos('딥 러닝 자연어 처리가 재미있지만, 문제는 영어보다 한국어로 전처리하는 것이 너무 어렵습니다'))
print('꼬꼬마 명사 추출 :', kkma.nouns('딥 러닝 자연어 처리가 재미있지만, 문제는 영어보다 한국어로 전처리하는 것이 너무 어렵습니다')) 꼬꼬마 형태소 분석:
['딥', '러닝', '자연어', '처리', '가', '재미있', '지만', ',', '문제', '는', '영어', '보다', '한국어', '로', '전처리', '하', '는', '것', '이', '너무', '어렵', '습니다']
꼬꼬마 품사 태깅 :
[('딥', 'NNG'), ('러닝', 'NNG'), ('자연어', 'NNG'), ('처리', 'NNG'), ('가', 'JKS'), ('재미있', 'VA'), ('지만', 'ECE'), (',', 'SP'), ('문제', 'NNG'), ('는', 'JX'), ('영어', 'NNG'), ('보다', 'JKM'), ('한국어', 'NNG'), ('로', 'JKM'), ('전처리', 'NNG'), ('하', 'XSV'), ('는', 'ETD'), ('것', 'NNB'), ('이', 'JKS'), ('너무', 'MAG'), ('어렵', 'VA'), ('습니다', 'EFN')]
꼬꼬마 명사 추출 :
['딥', '러닝', '자연어', '처리', '문제', '영어', '한국어', '전처리'] 첫번째로 사용한 Okt 분석기와 형태소 분석/명사 추출에서 약간의 다른 결과를 가져온 것을 확인가능하다. 각 형태소 분석기는 성능과 결과가 다르게 나오기 때문에, 형태소 분석기의 선택은 사용하고자 하는 필요 용도에 따라 사용하면 된다.
ex) 속도를 중시할 경우 메캅 사용
*참고
한국어 형태소 분석기 성능 비교 : https://iostream.tistory.com/144
http://www.engear.net/wp/%ED%95%9C%EA%B8%80-%ED%98%95%ED%83%9C%EC%86%8C-%EB%B6%84%EC%84%9D%EA%B8%B0-%EB%B9%84%EA%B5%90/
윈도우10 메캅 설치 :
https://cleancode-ws.tistory.com/97
2. 정제(Cleaning) & 정규화(Normalization)
corpus에서 용도에 맞게 명사/형태소 등을 기준으로 토큰화를 진행하였다면, 이제 정제/정규화를 진행해보자.
정제(Cleaning) : 갖고 있는 corpus로부터 노이즈 데이터 제거
ex) 불필요한 단어(불용어) 제거
노이즈 데이터란 ?
아무 의미도 갖지 않는 글자들(특수 문자 등), 분석하고자 하는 목적에 맞지 않는 불필요한 단어들
-> 이러한 불필요 단어들을 제거하는 방법으로는
(1) 불용어 제거
(2) 등장 빈도가 적은 단어
(3) 길이가 짧은 단어
들을 제거하는 방법이 있다.
정규화(Normalization) : 표현 방법이 다른 단어들을 같은 단어로 통합
ex) US = USA / uh-huh = uhhuh => 어간 추출(stemming) & 표제어 추출(lemmatization)을 통해 해결가능
ex2) Apple = apple => 대/소문자 통합을 하여 단어의 개수를 줄일 수 있음.
이러한 정제와 정규화 과정은 사실 토큰화 작업 이전에 이루어지기도 하지만, 토큰화 이후에도 여전히 남아있는 노이즈를 제거하기 위해 지속적으로 진행되기도 한다.
(1) 어간 추출(Stemming) & 표제어 추출(Lemmatization)
-
정규화 기법 중 하나
-
corpus에 있는 단어의 개수를 줄일 수 있는 방법
어간 추출(Stemming)
ex) taking -> take
happily -> happy
allowance -> allow어간 추출(Stemming)
[예시 1. PorterStemmer]
어간 추출 알고리즘 중 하나인 포터 알고리즘 (Porter Algorithm) 사용
- 포터 알고리즘 규칙
ALIZE -> AL
ANCE -> 제거
ICAL -> IC
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
stemmer = PorterStemmer()
sentence = "With plans to release a star-studded lineup of original content, Disney+ and local streaming platform Tving -- among others -- are set to begin another round of competition in the streaming video and content production markets in South Korea."
# 단어 단위로 토큰화
tokenized_sentence = word_tokenize(sentence)
print('어간 추출 전: ', tokenized_sentence)
print('어간 추출 후: ', [stemmer.stem(word) for word in tokenized_sentence])
어간 추출 전:
['With', 'plans', 'to', 'release', 'a', 'star-studded', 'lineup', 'of', 'original', 'content', ',', 'Disney+', 'and', 'local', 'streaming', 'platform', 'Tving', '--', 'among', 'others', '--', 'are', 'set', 'to', 'begin', 'another', 'round', 'of', 'competition', 'in', 'the', 'streaming', 'video', 'and', 'content', 'production', 'markets', 'in', 'South', 'Korea', '.']
어간 추출 후:
['with', 'plan', 'to', 'releas', 'a', 'star-stud', 'lineup', 'of', 'origin', 'content', ',', 'disney+', 'and', 'local', 'stream', 'platform', 'tving', '--', 'among', 'other', '--', 'are', 'set', 'to', 'begin', 'anoth', 'round', 'of', 'competit', 'in', 'the', 'stream', 'video', 'and', 'content', 'product', 'market', 'in', 'south', 'korea', '.'][예시 2. LancasterStemmer]
- 두번째 어간 추출을 위한 알고리즘으로 NLTK의 랭커스터스테머 알고리즘 사용 (LancasterStemmer algorithm)
- PorterStemmer VS LancasterStemmer
from nltk.stem import PorterStemmer
from nltk.stem import LancasterStemmer
from nltk.tokenize import word_tokenize
porter_stemmer = PorterStemmer()
lancaster_stemmer = LancasterStemmer()
sentence = "With plans to release a star-studded lineup of original content, Disney+ and local streaming platform Tving -- among others -- are set to begin another round of competition in the streaming video and content production markets in South Korea."
# 단어 단위로 토큰화
tokenized_sentence = word_tokenize(sentence)
# 포터 스테머 - 어간 추출
print('포터 스테머 : ', [porter_stemmer.stem(word) for word in tokenized_sentence]
# 랭커스터 스테머 - 어간 추출
print('랭커스터 스테머 : ', [lancaster_stemmer.stem(word) for word in tokenized_sentence])
포터 스테머 :
['with', 'plan', 'to', 'releas', 'a', 'star-stud', 'lineup', 'of', 'origin', 'content', ',', 'disney+', 'and', 'local', 'stream', 'platform', 'tving', '--', 'among', 'other', '--', 'are', 'set', 'to', 'begin', 'anoth', 'round', 'of', 'competit', 'in', 'the', 'stream', 'video', 'and', 'content', 'product', 'market', 'in', 'south', 'korea', '.']
랭커스터 스테머 :
['with', 'plan', 'to', 'releas', 'a', 'star-studded', 'lineup', 'of', 'origin', 'cont', ',', 'disney+', 'and', 'loc', 'streaming', 'platform', 'tving', '--', 'among', 'oth', '--', 'ar', 'set', 'to', 'begin', 'anoth', 'round', 'of', 'competit', 'in', 'the', 'streaming', 'video', 'and', 'cont', 'produc', 'market', 'in', 'sou', 'kore', '.'] 동일한 단어들을 넣었으나 두 스테머를 사용하여 어간추출을 한 결과는 다르게 나타난다. 위의 예시에서는 랭커스터 스테머보다 포터 스테머가 보다 정확성을 가지고 있는 것처럼 보이는데, 이처럼 이미 알려진 알고리즘을 사용할 경우에는 사용하고자 하는 corpus에 각 stemmer를 적용해보고 어떤 stemmer가 해당 corpus에 적합한지 판단 후 사용해야 한다.
어간 추출 (Stemming) VS 표제어 추출 (Lemmatization)
(1) stemming
am -> am / the going -> the go / having -> hav
(2) lemmatization
am -> be / the going -> the going / having -> have
표제어 추출(Lemmatization)
-
일반적으로 어간 추출에 비해 표제어 추출이 보다 정학한 어근 단어를 찾아준다.
-
품사와 같은 문법적인 요소 & 의미적인 부분을 감안하기 때문에 어간 추출보다 정확하지만 추출에 있어 시간이 오래 걸린다.
[예시. NLTK - WordNetLemmatizer]
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
# 앞의 예시에서 단어 단위로 토큰화된 리스트 값 사용
print('표제어 추출 전 : ',tokenized_sentence)
#표제어 추출 후
print('표제어 추출 후 : ', [lemmatizer.lemmatize(word) for word in tokenized_sentence])
표제어 추출 전 :
['With', 'plans', 'to', 'release', 'a', 'star-studded', 'lineup', 'of', 'original', 'content', ',', 'Disney+', 'and', 'local', 'streaming', 'platform', 'Tving', '--', 'among', 'others', '--', 'are', 'set', 'to', 'begin', 'another', 'round', 'of', 'competition', 'in', 'the', 'streaming', 'video', 'and', 'content', 'production', 'markets', 'in', 'South', 'Korea', '.']
표제어 추출 후 :
['With', 'plan', 'to', 'release', 'a', 'star-studded', 'lineup', 'of', 'original', 'content', ',', 'Disney+', 'and', 'local', 'streaming', 'platform', 'Tving', '--', 'among', 'others', '--', 'are', 'set', 'to', 'begin', 'another', 'round', 'of', 'competition', 'in', 'the', 'streaming', 'video', 'and', 'content', 'production', 'market', 'in', 'South', 'Korea', '.']=> 앞의 어간 추출(stemming)에 비해 단어의 형태가 적절히 보존되는 양상을 보임.
하지만, 표제어 추출기(lemmatizer)의 경우 dies -> dy, has -> ha와 같이 의미를 알 수 없는 적절치 못한 단어를 출력하기도 한다.
이는 표제어 추출기(lemmatizer)가 본래 단어의 품사 정보를 알아야만 정확한 결과를 얻을 수 있기 때문이다.
따라서 lemmatizer.lemmatize사용시, 단어의 품사를 함께 입력해준다면, 표제어 추출기는 품사의 정보를 보존하면서도 보다 정확한 Lemma(표제어)를 추출한다.
> example
lemmatizer.lemmatize('dies','v')
'die'lemmatizer.lemmatize('has','v')
'have'(2) 불용어(Stopword)제거
: 자주 등장하지만, I, my, me,..조사,접미사와 같은 단어들은 실제 의미 분석에 있어 거의 기여하는 바가 없는 경우가 다수이다. 이러한 단어들을 불용어(Stopword)라고 하며, NLTK에서는 위와 같은 100여개 이상의 영어 단어들을 불용어로 패키지 내에서 미리 정의하고 있다.
이와 같이 이미 정의하고 있는 불용어 외에도 개발자가 불용어를 추가하여 제거할 수 있다.
*참고
NLTK실습의 경우 NLTK Data가 필요한데, 만약 데이터가 없다는 error 발생시, nltk.download(필요한 데이터) 커맨드를 통해 다운로드 하자.
from nlkt.corpus import stopwords
from nltk.tokenize import word_tokenize
from konlpy.tag import Okt
# NLTK에서 불용어 확인
stop_word_list = stopwords.words('english')
print('불용어 개수 : ', len(stop_word_list))
print('불용어 10개 출력 : ', stop_word_list[:10])
# NLTK를 통해 불용어 제거
text = "i love all the things on the earth. and i'm so lovely person."
stop_words = set(stopwords.words('english')
word_tokens = word_tokenize(text)
result = []
for word in word_tokens:
if word not in stop_words:
result.append(word)
print('불용어 제거 전 : ', word_tokens)
print('불용어 제거 후 : ', result)
179
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]
불용어 제거 전 :
['i', 'love', 'all', 'the', 'things', 'on', 'the', 'earth', '.', 'and', 'i', "'m", 'so', 'lovely', 'person', '.']
불용어 제거 후 :
['love', 'things', 'earth', '.', "'m", 'lovely', 'person', '.']- 참고
set() 함수 : :중복값 제거
set() 선언 ;
집합이라는 뜻을 가진 set -> 집합의 성질을 가지는 함수들을 비롯해 "중복되지 않은 원소(unique)"를 얻고자 할 때 사용할 수 있는 python 자체 내장 함수
한국어 불용어 제거
-> 한국어에서 불용어를 제거하는 방법은 간단히 토큰화 후, 조사/접속사 등을 제거하는 방법이 있다. 하지만, 불용어를 제거하려고 시도하다보니 조사/접속사 뿐만 아니라 명사/형용사와 같은 단어들 중 불용어로서 제거하고 싶은 단어들이 생겨나기도 한다.
이러한 경우, 사용자가 제거하고 싶은 불용어 사전을 만들어 불용어를 제거할 수 있다.
okt = Okt()
text = "고기를 아무렇게나 구우려고 하면 안 돼. 고기라고 다 같은 게 아니거든. 예컨대 삼겹살을 구울 때는 중요한 게 있지."
stop_words = "를 아무렇게나 구 우려 고 안 돼 같은 게 구울 때 는"
# 사용자가 정의한 불용어
stop_word = set(stop_words.split(' '))
# 형태소 기준 토큰화
word_tokens = okt.morphs(text)
results = [word for word in word_tokens if not word in stop_words]
print('불용어 제거 전 : ', word_tokens)
print('불용어 제거 후 : ', result)
불용어 제거 전 :
['고기', '를', '아무렇게나', '구', '우려', '고', '하면', '안', '돼', '.', '고기', '라고', '다', '같은', '게', '아니거든', '.', '예컨대', '삼겹살', '을', '구울', '때', '는', '중요한', '게', '있지', '.']
불용어 제거 후 :
['고기', '하면', '.', '고기', '라고', '다', '아니거든', '.', '예컨대', '삼겹살', '을', '중요한', '있지', '.']추가적인 내용은 다음 포스팅에서 다루겠습니다.
references
- 딥 러닝을 이용한 자연어 처리 입문
https://wikidocs.net/21698 - https://marketingscribbler.tistory.com/4
