Query Optimizer란?
- 옵티마이저는 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심 엔진! (DBMS의 두뇌는 옵티마이저라고 할 수 있음)
- SQL을 작성하고 나면 즉시 실행되는게 아니라 옵티마이저에서 실행 순서를 정하고 나서(실행 계획) 그에 따라 쿼리를 수행한다.
Query Optimizer 종류
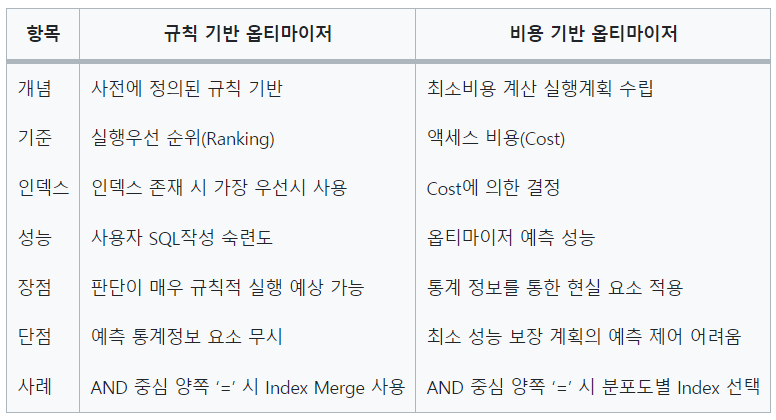
규칙 기반 옵티마이저(RBO : Rule-Based Optimizer)
실행 계획 결정시에 미리 정해둔 규칙에 따라 쿼리를 최적화함
SQL 구문(JOIN, WHERE 등)에 대한 고정 규칙을 적용
규칙을 세워둘 때 실행 속도가 빠른 순으로 규칙을 세워두고 우선순위가 높은 방법을 채택하여 실행계획을 세움
규칙이란 엑세스 경로별 우선순위로서, 인덱스 구조, 연산, 조건절 형태가 순위를 결정짓는 주요인이 됨

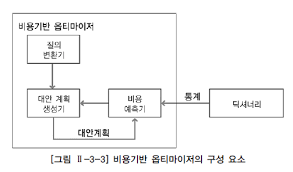
비용 기반 옵티마이저(CBO : Cost-Based Optimizer)
몇 개의 규칙만으로 현실의 모든 상황을 설명하기 어렵다는 규칙 기반 옵티마이저의 한계를 해결하기 위해 나옴
실행 계획을 선택하기 위해 쿼리를 수행하는데 소요되는 일 량 또는 시간을 기반으로 최적화하는 방식
실행 계획을 수립할 때 판단 기준이 되는 비용은 예상치임
비용을 예측하기 위해 테이블, 인덱스, 컬럼 등의 다양한 객체 통계정보 및 CPU 속도, 디스트 I/O 속도 등 시스템 통계정보를 이용
통계정보가 없는 경우 비효율적인 실행계획을 생성할 수 있으므로, 정확한 통계정보를 유지하는 것이 중요함
RBO VS CBO
SQL 최적화 과정
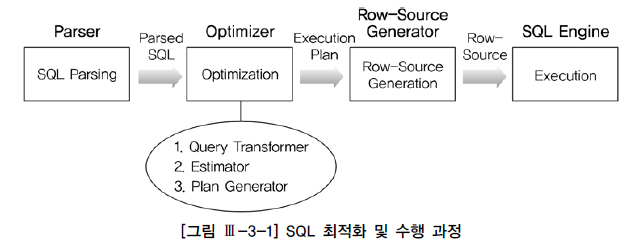
- Parser : SQL을 파싱해서 파싱 트리(내부적인 구조체)를 만든다. 문법적 오류나 의미상 오류를 체크한다.
- Optimizer :
- Query Transformer : 파싱된 SQL을 좀 더 일반적이고 표준적인 형태로 변환한다.
- Estimator : 객체, 시스템 통계정보를 활용해 쿼리 수행 각 단계의 선택도, 카디널리티, 비용을 계산하고 실행계획 전체에 대한 총 비용을 계산한다.
- Plan Generator : 하나의 쿼리를 수행하는 데 있어서 후보군이 될 만한 실행계획을 생성해낸다.
- Row-Source Generation : 옵티마이저가 생성한 실행계획을 SQL 엔진이 실제로 실행할 수 있는 코드(또는 프로시저)형태로 변환한다.
- SQL Engine : SQL을 실행한다.
Optimizer 행동에 영향을 미치는 요소
- SQL 연산자 형태
- SQL의 형태에 따라 다른 선택을 하고 쿼리 성능에 영향을 미침
- 옵티마이징 팩터
- 쿼리가 같아도 인덱스, 클러스터링, 파티셔닝 등의 구성 형태에 따라 실행계획과 성능이 달라짐
- DBMS 제약 설정
- PK, FK, NOT NULL과 같은 제약 설정 기능은 쿼리 성능 최적화에 중요한 정보를 제공함. 예를 들어서 인덱스 컬럼에 NOT NULL이 설정되어 있으면 옵티마이저는 전체 개수를 구하는 COUNT 쿼리에 이 인덱스를 활용할 수 있음
- 옵티마이저 힌트
- 사용자가 지정한 힌트를 우선함
- 통계정보
- CBO의 모든 판단 기준은 통계정보에서 기인함
- 옵티마이저 관련 파라미터
- SQL, 데이터, 통계정보, H/W 등의 모든 환경에 동일해도 DBMS 버전을 업테이드하면 옵티마이저가 다르게 작동할 수 있음. 옵티마이저 관련 파라미터가 변경되기 때문임
- DBMS 버전과 종류
- 옵티마이저 관련 파라미터가 같아도 버전에 따라서 실행계획이 달라질 수 있음
실행계획
실행계획은 SQL에서 요구한 사항을 처리하기 위한 절차와 방법을 의미한다. SQL을 어떤 순서로 어떻게 실행할지를 결정하는 작업인 것이다. 동일한 SQL에 대해 결과를 낼 수 있는 다양한 실행계획이 존재할 수 있으나 각 처리 방법마다 성능은 다를 수 있다. 옵티마이저는 다양한 처리 방법들 중 가장 효율적인 방법을 찾아준다. (최적의 실행 계획 생성)
이 실행 계획을 구성하는 요소는 다음과 같다.
- 조인 순서 : 조인 작업을 수행할 때 참조하는 테이블의 순서이다. A 테이블을 읽고 B 테이블을 읽는 작업을 수행한다면 조인 순서는 A->B이다.
- 조인 기법 : 두 개의 테이블을 조인할 때 사용할 수 있는 방법으로 NL Join, Hash Join, Sort Merge Join 등이 있다.
- NL Join : 선행 테이블과 후행 테이블을 조인하는 경우 선행 테이블의 조건을 만족하는 행 추출 후 후행 테이블 읽으면서 조인, 결과 해으이 수가 적은 테이블을 조인 순서상 선행 테이블로 두는 것이 유리
- Sort Merge Join : 조인 컬럼 기준으로 데이터를 정렬한 후 조인 수행, 정렬할 데이터가 많은 경우 성능 저하
- Hash Join : 조인 컬럼 기준으로 해시 함수를 수행하여, 동일한 해시 값을 갖는 경우에만 실제 값을 비교하여 조인 수행, 해시 테이블을 메모리에 생성해야 함. 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋음.
- 엑세스 기법 : 하나의 테이블을 엑세스할 때 사용할 수 있는 방법이다. 인덱스를 이용해 테이블을 엑세스하는 인덱스 스캔, 테이블 전체를 모두 읽으면서 조건을 만족하는 행을 찾는 전체 테이블 스캔 등이 있다.
- FTS를 택하는 경우
- SQL문에 조건이 존재하지 않는 경우
- SQL문 조건에 사용 가능한 인덱스가 없는 경우
- 조건을 만족하는 데이터가 매우 많은 경우 (인덱스 스캔은 한 블록씩 가져오지만 FTS는 여러 블록을 동시에 읽으므로)
- 병렬 처리 방식으로 처리하는 경우
- 인덱스 스캔의 유형
- 인덱스 유일 스캔
- Unique Index를 이용해서 단 하나의 데이터를 추출
- Index 구성 컬럼에 조건이 모두 =로 주어진 경우
- 인덱스 범위 스캔
- 한 건 이상의 데이터를 추출하는 방식
- Non Unique Index를 이용하는 경우
- Index 구성 컬럼에 = 이외의 조건이 주어진 경우
- 인덱스 유일 스캔
- FTS를 택하는 경우
- 최적화 정보 : 옵티마이저가 실행계획의 각 단계마다 예상되는 비용 사항을 표시하는 것이다. (실제 실행 결과가 아닌 통계 정보 바탕의 예측치)

- Cost : 상대적인 비용 정보 (숫자 낮을수록 유리)
- Card : 주어진 조건을 만족하는 행의 수
- Bytes : 결과 집합이 차지하는 메모리의 양
참고
https://velog.io/@chullll/DB-%EC%98%B5%ED%8B%B0%EB%A7%88%EC%9D%B4%EC%A0%80-%EC%8B%A4%ED%96%89%EA%B3%84%ED%9A%8D-INDEX
https://velog.io/@kwontae1313/%EC%98%B5%ED%8B%B0%EB%A7%88%EC%9D%B4%EC%A0%80
https://velog.io/@fud904/DB-%EC%98%B5%ED%8B%B0%EB%A7%88%EC%9D%B4%EC%A0%80%EC%99%80-%EC%8B%A4%ED%96%89%EA%B3%84%ED%9A%8D
https://coding-factory.tistory.com/743
