계수 정렬이란?
이름 그대로 배열 내에 특정한 값이 몇 번 등장했는지에 따라 정렬을 수행하기 때문에 비교 연산이 사용되지 않는 정렬이다. 배열의 인덱스를 이용하여 데이터를 저장할 것이기 때문에 배열의 인덱스는 양수만 존재해야 하므로 데이터는 양수여야 한다. 또한 값이 너무 커지만 메모리 영역을 너무 많이 할당해버려 문제가 생기므로 값의 범위가 너무 크지 않아야 한다.
계수 정렬의 단계
<초기 상태>

<과정 1>
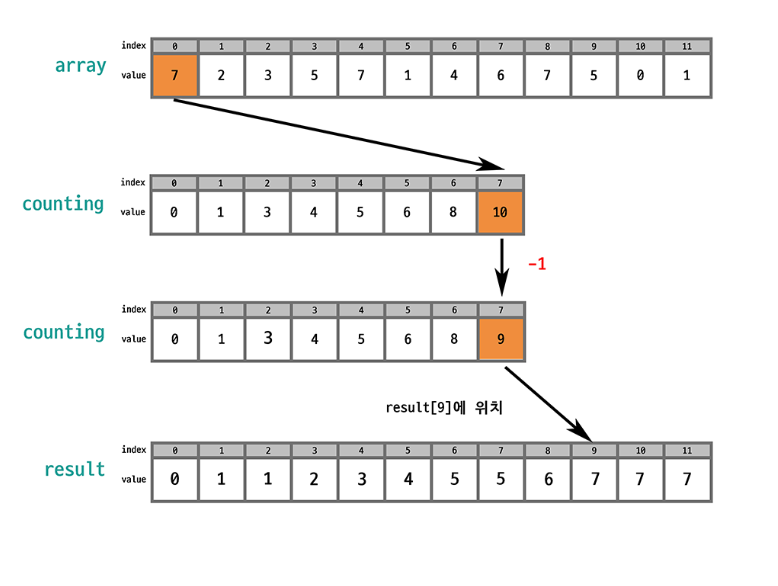
Array를 한 번 순회하며 각 값이 나올때마다 해당 값을 index로 하는 새로운 배열인 counting의 값을 1 증가시킴
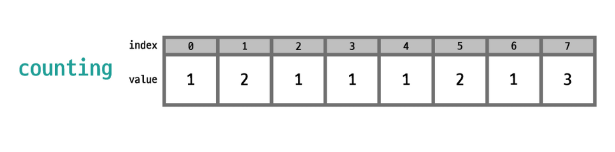
<과정 2>
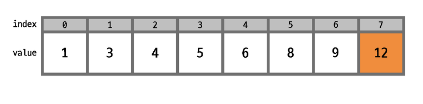
counting 배열의 각 값을 누적합으로 변환시킴
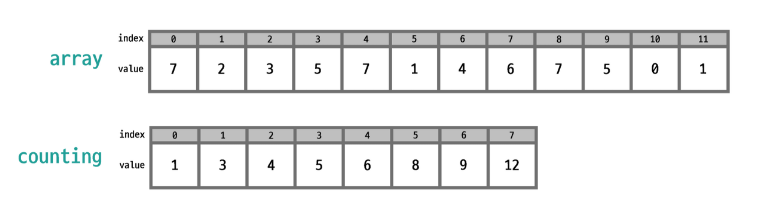
결과적으로 이 두 배열을 갖게 됨
counting 배열의 각 값은 (시작점 - 1)을 알려준다는 것을 알 수 있음. 즉, 각 값이 시작하는 위치(뒷쪽부터)를 알려준다는 것임.
누적합의 목적은 큰 인덱스에 큰 값이 들어가도록 하여 결과 배열의 뒷쪽에 큰 값이 가도록 하기 위함임
<과정 3>
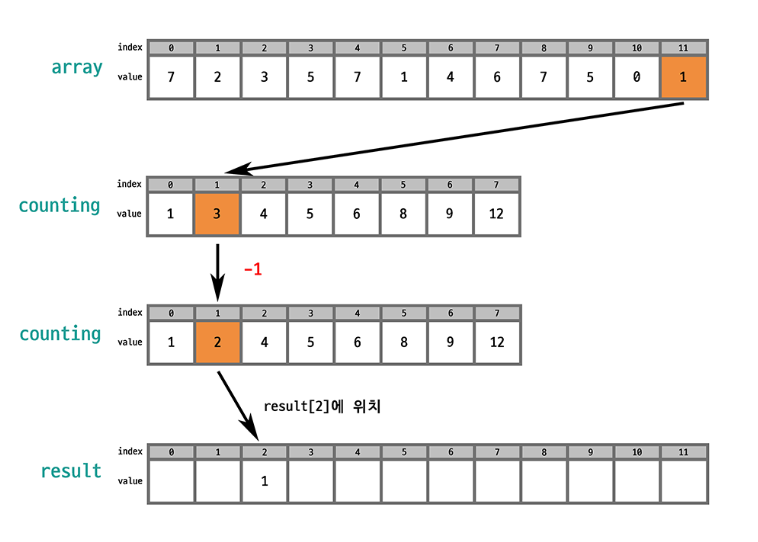
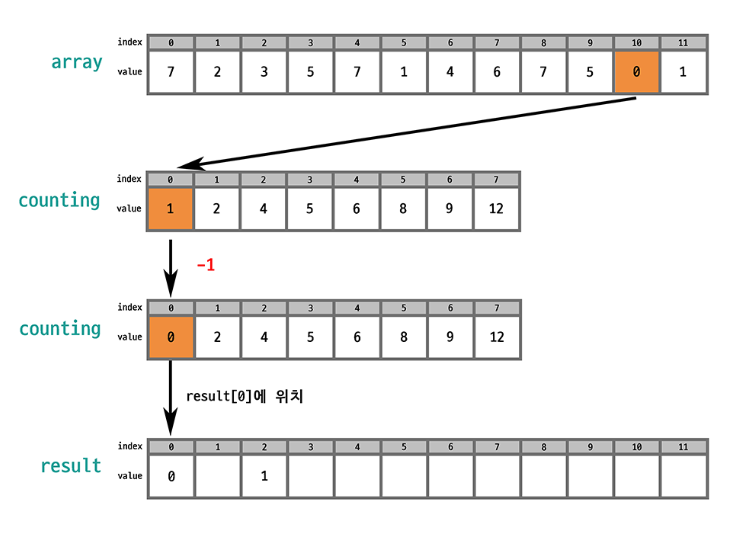
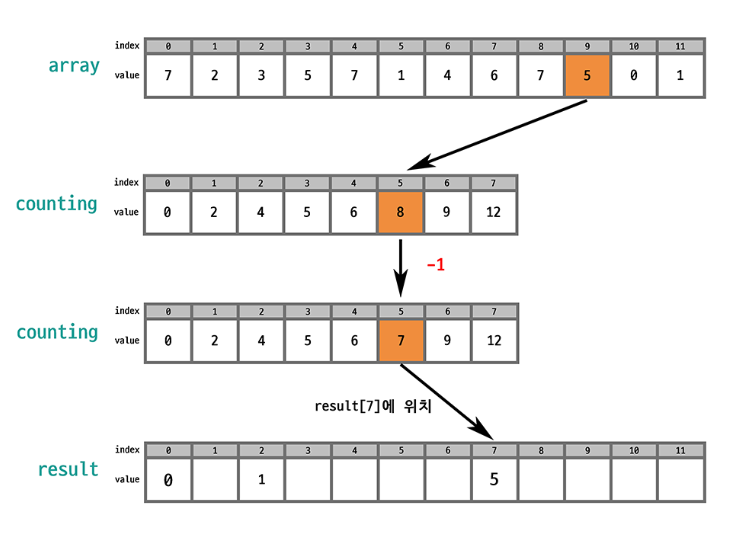
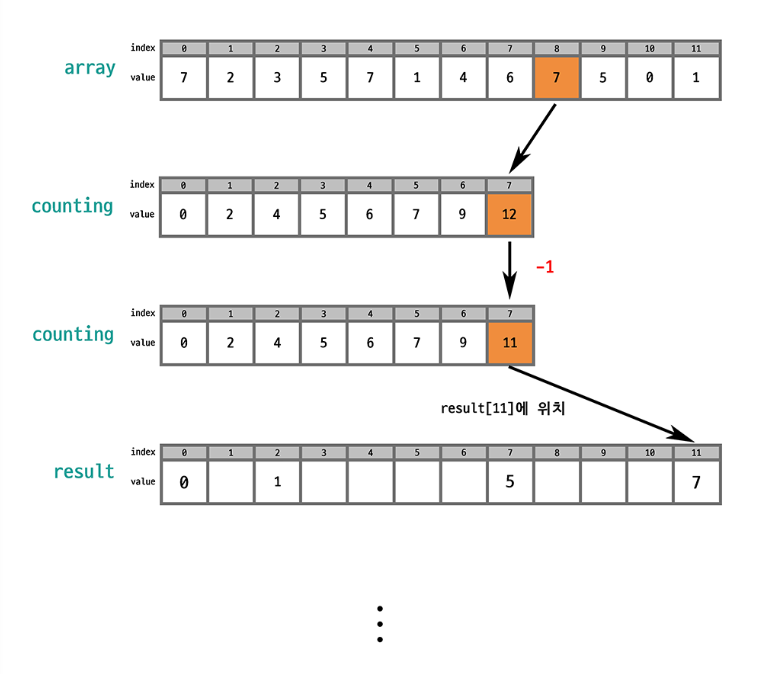
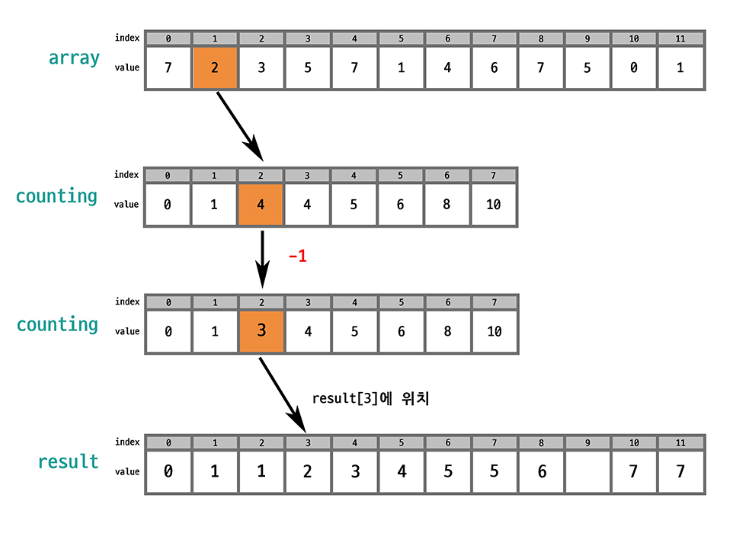
원본 배열에서 선택된 값의 인덱스를 counting 배열에서 찾으면 그 값의 개수를 알 수 있음. 누적합을 통해 counting 배열은 오름차순 상태로 바뀌었기 때문에 counting 배열의 값을 하나씩 줄이면서 (숫자 개수만큼) 결과 배열에 배치하면 결과 배열도 오름차순 상태가 됨!
이때 안정적으로 정렬하려면 array의 마직 index부터 순회하는 것이 좋음
...
배열을 사용한 구현
count = [0] * (max(arr) + 1)
# 1. 주어진 숫자들의 빈도수를 계산하여 count 리스트에 저장
for num in arr:
count[num] += 1
# 2. count 리스트를 누적합으로 업데이트
for i in range(1, len(count)):
count[i] += count[i-1]
result = [0] * (len(arr))
# 3. 주어진 숫자들을 count 리스트를 참조하여 정렬
for num in arr:
idx = count[num]
result[idx - 1] = num
count[num] -= 1
print(result)딕셔너리를 사용한 구현
count_dict = {}
# 1. 주어진 숫자들의 빈도수를 count_dict에 저장
for num in arr:
if num in count_dict:
count_dict[num] += 1
else:
count_dict[num] = 1
result = []
# 2. count_dict를 참조하여 정렬된 숫자 리스트를 생성
for num in range(max(arr) + 1):
# 3. 현재 숫자가 count_dict에 존재하고, 빈도수가 0이 아닐 때까지 반복
while num in count_dict and count_dict[num] != 0:
result.append(num)
count_dict[num] -= 1
print(result)계수 정렬의 특징
- 기본적으로 계수 정렬은 배열에 있는 원소들의 개수만 세고 작은 수부터 나열하므로 시간 복잡도는 O(n)임. 하지만 좀 더 구체적으로 보면 배열에 있는 최댓값에 영향을 받기 때문에 시간 복잡도를 O(n + k)라고 할 수도 있음
- k만큼의 배열을 추가로 만들어야 하기 때문에 O(k)의 공간복잡도를 가짐
- 데이터의 범위가 작으면 O(n) 시간 복잡도를 가지므로 매우 빠름
- 데이터의 범위가 크면 만들어야 하는 배열의 크기가 크기에 메모리 낭비가 심함
- 안정 정렬임
- 제자리 정렬이 아님 (숫자 개수를 저장할 공간과 결과를 저장할 공간이 필요함)
- 비교 정렬이 아님
참고
https://song-ift.tistory.com/238
https://m.blog.naver.com/jryoun1/222094707603
https://velog.io/@wndudrla1011/interview-algorithm-sort-counting
https://jeonyeohun.tistory.com/103
