codes for characters
codes for characters
- code: 특정 형태의 information을 다른 방법으로 표현하는 규칙 또는 규칙으로 표현된 결과물
- codes for characters는 우리가 사용하는 문자를 일종의 기호 또는 숫자로 표현하는 것을 의미한다.
- encoding: 대상 information을 code로 변환하는 과정 또는 규칙
- decoding: code로부터 원래의 information을 얻는 과정
- 대표적인 code를 시대 순으로 소개할 것이다.
American National Standard Code for Imformation Interchange(ASCII)
- 1963년 개발되었으며 지금도 사실상 표준으로 사용된다.
- 7bit만으로 다양한 숫자기호와 영문자들 그리고 특수문자 및 Control character(제어 문자)를 표현한다.
7bit만으로 표현되었지만 컴퓨터의 발전으로 한 번에 처리하는 단위가 byte가 되면서 ASCII를 사용하는 데이터 type의 크기가 1byte가 되었다.
ASCII의 상세 구성
- 34개의 Control character (
NUL포함) - 94개의 Printable character
52개의 알파벳 대소문자
10개의 숫자
* 32개의 특수문자ASCII 이름에도 나오듯 Infromation Interchange를 위한 code기 때문에 Control character의 상당수는 communication과 연관되어 있다. 현재 이들 중 많은 경우가 사용되지 않는다.
American National Standard Institute (ANSI)
- ASCII의 7bit를 기반으로 8bit로 확장을 한 code
- code page을 이용하여 한 번에 code page에 해당하는 나라의 문자를 표현하는 방식이다.
- 128개는 ASCII, 추가된 128개는 각국의 언어 기호들이 할당되는 방식이지만 한글같은 경우 8bit를 더 할당하여 2byte를 사용한다.
- e.g. 한글 code: CP949(949는 code page를 지칭), Microsoft에서 제안한 방식이기 때문에 MS949로도 불리며 Windows OS에서 주로 사용되는데 한국의 당시 OS는 거의 Windows로 사실상 한글 표준으로 사용되었다.
- ANSI 방식은 자국어만을 지원하는 경우에는 큰 문제가 없지만 다른 나라의 언어에서는 사용이 어렵다는 단점을 가진다.
ANSI는 미국 국가표준 협회의 역어로 다른 곳에서 사용될 때는 해당 협회를 가르키며 해당 협회가 정한 표준안을 ANSI라고 지칭한다.
Extended Unix Code-Korea (EUC-KR)
- Unic 계열에서 한글 지원을 위해 등장한 encoding 방식으로 2byte를 이용한 완성형 방식이다.
- CP949와 마찬가지로 ANSI를 한글 지원을 위해 확장한 형태로 완성형의 한계로 모든 한글을 표현하지 못한다.(ANSI의 단점을 그대로 가짐)
- CP949보다 먼저 개발되었고 표현할 수 있는 한글 문자 수는 CP949보다 적었으나 인터넷에서 서버로 사용되는 장비의 OS가 주로 Unix계열이었기 때문에 널리 사용되었다.
Unicode
- 전세계 문자와 기호를 하나의 테이블에 정리한 code로 전세계의 문자를 일관되게 표현하고 다룰 수 있게 해준다.
지원되는 문자가 계속 추가되면서 필요한 bit 수가 점점 늘어난다.
- 다른 code들과 달리 할당된 code와 다른 byte로 컴퓨터에서 저장된다. 때문에 Unicode를 컴퓨터에 저장되는 byte로 바꾸는 여러 encoding방식이 제안되었다.
byte라고 표현한 것은 컴퓨터에서 기본으로 byte단위오 저장하기 때문이다. 컴퓨터에서 실제로 저장되는 코드를 지칭한다고 보면된다.
code와 Encoding
- code: code: 특정 형태의 information을 다른 방법으로 표현하는 규칙 또는 규칙으로 표현된 결과물
- encoding: 특정 데이터(음성, 영상, 문자 등)를 code로 바꾸는 과정, 역의 과정은 decoding이라고 함
- Unicode는 엄밀하게 말하면 code로 Unicode의 글자 하나를 나타내는 code를 컴퓨터가 2진수로 바꿔 그대로 저장하지 않고 UTF-8, UTF-16, UTF-32 등의 encoding을 사용한다. encoding 방식에 따라 저장되는 byte가 달라지며 Uicode라 해도 실제 저장된 byte의 값을 보면 다를 수 있음을 유의해야 한다.
- ANSI 계열과 ASCII는 code에 해당하는 byte가 그대로 저장되기 때문에 code이자 encoding이라고 할 수 있다.
가변길이방식을 multi-bytes라고 부른다.
Encodings for Unicode
- Unicode의 encoding은 독특하다. Unicode는 요구되는 bit가 크다보니 그대로 컴퓨터에서 저장하기에 효율이 떨어진다. 때문에 Unicode를 컴퓨터에 저장하기 위한 byte 단위의 code로 변환해주는 encoding이 제안되었다.
- 초기에는 다국적 기업들이 적극적으로 사용한 UTF-16을 주로 사용하였지만 비영어권에서는 단점이 더 많아 자국 서비스만을 생각하는 경우에는 ANSI 계열의 encoding이 사용되었지만 UTF-8이 등장하면서 단일 encoding으로 다국어가 처리될 수 있어서 적극적으로 도입도었다.
- 한글만으로 한정짓는 UTF-8은 2byte로 처리되는 UTF-16, ANSI방식과 달리 3byte로 처리되기 때문에 효율성이 낮지만 실제적인 표준이 되어 주로 사용된다.
- 이 문서에서는 UTF-8만 다룬다.
- 한 문자를 표현하는데 1~4byte를 사용하며 하위 1byte 영역은 ASCII와 호한이 된다. ASCII로 충분한 영어권의 경우 Unicode encoder들을 제치고 사실상 ASCII가 표준이 되었다.
- 다음과 같은 규칙이 있다.
- 1byte만을 사용하는 경우 MSB가 0으로 시작한다.
- 2byte를 사용하는 경우 상위 byte는 110으로 시작하고 하위 byte는 10을 시작한다.
- 3byte를 사용하는 경우 상위 byte는 1110으로 시작하고 나머지 byte들은 10으로 시작한다.
- 4byte를 사용하는 경우 상위 byte는 11110으로 시작하고 나머지 byte들은 10으로 시작한다.
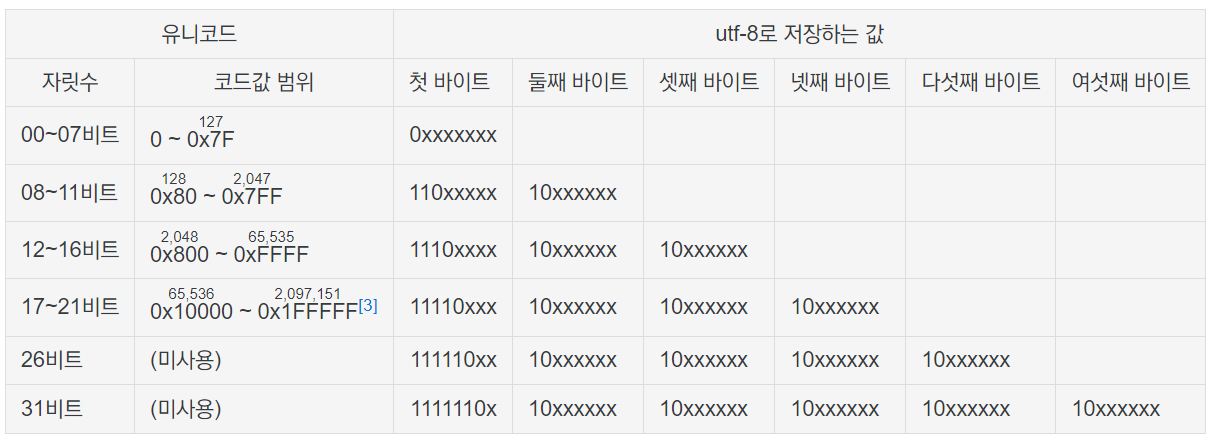
- 이는 규칙들을 정리한 표이다.
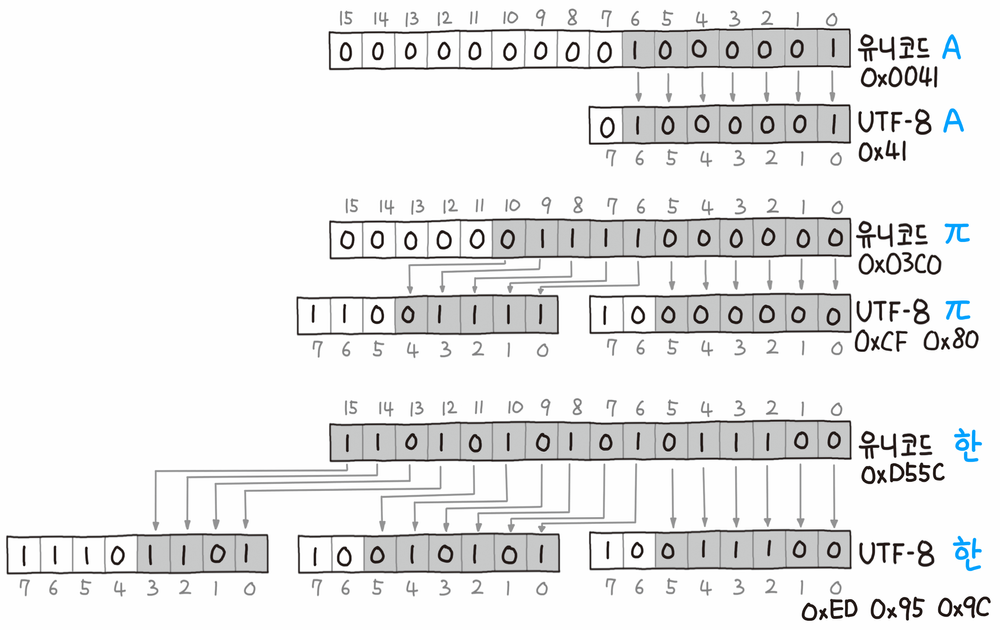
- 이는 한글에서 사용할 때의 예시이다.
encoding
Quoted-Printable Encoding (QP encoding)
- 과거 7bit만을 지원하는 통신 경로로 데이터 통신을 하던 시절에 개발된 encoding 방식이다. email 첨부파일 전송 등에서 아직도 사용된다.
- 다음은 encoding 방식이다.
- computer의 internal representation(메모리 등에 저장된 값)을 1byte로 나눈다.
- 각 1byte를 nibble로 쪼개고 각 nibble을 16진수로 표현한다. 이를 통해 2개의 symbol이 나온다.
- 해당 2개의 symbol 앞에
=을 붙인다. - 이를 모든 byte에 적용한다.
- 다음은 추가 규칙이다.
- ASCII에 있는 printable character들은 사실상 7bit이므로 그대로 전송된다.
- 단 공백문자에 해당하는
TAB,SPACE와 QP encoding에서 특별히 사용되는=는 예외로 ASCII 코드값에=을 붙여 전송한다.TAB:=09SPACE:=20=:=3D
- 1line이 76 character로 구성된다.
- 각 line은 soft linebreak인
=로 끝난다.
1byte에 3개의 글자로 표시되므로 전부 non-ascii인 한글의 UTF-8 encoding된 byte의 경우 25문자가 한 line에 표시된다.
에 soft linebreak를 더하면 76글자이다.
Base64 encoding
- QP encoding보다 효율이 좋은 encoding 방식으로 email의 첨부파일을 encoding하는데 사용된다.
- 3byte씩 묶어서 4개의 character로 encoding하는 방식이다.
= 3byte 즉 24bit를 4등분하여 6bit씩나누고 이들 6bit를 base64로 표햔한다. - 6bit는 64진수 한 글자로 표기되기에 3bytes가 4개의 character가 된다.
- 64진수는 Alphabet 대문자 26개, 소문자 26개, digit 10개 그리고 +, - 문자들을 언급한 순서대로 사용한다.
- 3byte씩 처리되는데 raw data가 3byte의 배수가 아니라면 끝에
=문자로padding을 하여 3의 배수로 맞춘다.
URL Encoding(=Percent Encoding)
- URL 주소에서는
/나=등의 문자는 특별한 의미를 가지기 때문에 문자 자체로 쓰려면 변환이 필요하다. - 여기서 사용되는 것이 URL encoding으로 특별한 의미를 가진 문자(=escape sequence)를 그냥 문자 그대로 사용하기 위해 해당 문자의 ASCII 값을 16진수로 표현하고
%뒤에 붙여서 기재한다. - URL에 한글이 있는 경우에도 자주 이용된다. 한글 한 글자는 3byte이므로 각 byte에 해단하는 16진수를 각각
%가 붙어져 변환된다.
- 한글을 UTF-8로 변환
- 해당 byte를 1byte씩 자른 후
- 이를
%와 16진수 숫자 2개로 바꾸어 처리
web browser
what is a web browser
- 가장 널리 사용되는 복잡한 SW중 하나로 매우 다양한 instruction set를 지원하고 이들을 조합하여 새로운 기능을 추가할 수 있는 일종의 Virtual Machine 또는 SW로만 구현된 Abstract computer
- 일반적으로 얘기하면 인터넷 망에서 정보를 검색하는데 사용되는 응용 프로그램 또는 인터넷에서 문자, 영상, 음향 등 다양한 현태로 저장되어 있는 정보를 찾아 접근, 열람할 수 있도록 해주는 SW라고 말할 수 있다.
Interpreter 또는 VM으로서의 Web browser
- Web browser는 일종의 interpreter로 매우 다양한 instruction set을 지원하며 이를 사용하여 다양한 프로그래밍 언어를 지원한다. 다양한 interpreter language의 source code를 원격지 등에서 읽어들여서 이들을 해석하고 대응하는 instruction들의 집합을 수행하는 interpreter라고 볼 수 있다.
interpreter
- 행, line 단위로 기계어로 번역해주는 프로그램
virtual machine
- 여러 OS를 단일 물리적 시스템에서 시분할로 실행하는 방법으로 HW의 발전으로 가능해졌다.
Web browser의 중요성
- 웹 브라우저의 점유 -> 인터넷의 점유
- e.g. 2000년 중반의 IE 등, 2020년대 초반의 Chrome
- 다양한 정보와 문서의 집합체인 internet에서 data를 열람하기 위해서 사실상 필수적인 SW이다.
- 특정 web browser의 독주 시 인터넷 전체 표준 마저도 흔들릴 수 있다.
reference
CE mkdocs
