컨슈머 poll 이 어떤 방식으로 진행되는지 테스트 후 동작방식을 정리해보겠다.
테스트
조건
partition 0 과 partition 1 에 각각 데이터가 20개씩 들어있는 상황
결과
-
여기서
limit=10으로 데이터를 컨슈밍했었다면?
✔️ 10개 데이터가 모두partition 0orpartition 1에서 컨슈밍 -
limit=20으로 데이터를 컨슈밍했었다면?
✔️ 20개 데이터가 모두partition 0orpartition 1에서 컨슈밍 -
limit=21이상으로 데이터를 컨슈밍했었다면?
✔️ 20개 데이터는 모두partition 0orpartition 1에서 컨슈밍
✔️ 그리고 나머지 1 이상은 또 다른 파티션에서 컨슈밍해온다.
Fetch, Poll
컨슈머가 카프카 브로커에서 레코드를 가져올 때에는 Fetcher 라는 클래스를 사용하게 된다.
클라이언트에서 poll() 을 호출하면 내부적으로는 fetch 된 레코드가 있냐, 없냐에 따라 두가지로 프로세스가 나뉜다.
-
레코드가 있냐 없냐는
✔️ 카프카 컨슈머가poll()요청이 올때마다
ConcurrentLinkedQueue<CompletedFetch> completedFetches를 확인해서 판단한다. -
fetch 된 레코드가 있을 경우
✔️completedFetches에서 최대max.poll.records만큼 데이터를 긁어온다. (디폴트 = 500)
✔️ 여기서 그걸 표현하고 있다.
-
fetch 된 레코드가 없을 경우
✔️ 카프카 브로커(파티션) 에 접근하여 레코드셋을 가져온다.
✔️ 얼만큼?
max.partition.fetch.bytes: 1개 파티션에서 이만큼 긁어오는데, 디폴트는 1048576 (10 MiB) 로 셋팅되어 있다. -
즉, 한마디로 정리하자면 fetch 된 레코드가 없을 경우
브로커에서 Fetch 해올때는 `max.partition.fetch.bytes` 만큼,
그리고 `poll()`로 가져가는건 `max.poll.records` 만큼.
그러므로 poll 할때마다 브로커로 접근하는 건 X
그럼 이런 결과가 발생한 이유는 무엇일까?
이 결과가 우연의 일치(?) 는 아닐지, 코드를 조금 분석해보았다.
-
결국
poll()을 부르면
✔️ 가장 먼저 가서 찾아보게 되는건ConcurrentLinkedQueue<CompletedFetch>타입 변수이다. -
이
LinkedQueue타입은 FIFO 방식으로, 저장된 순서대로 읽어올 수 있는 자료구조인데, -
따라서
poll()의 비밀을 알기 위해선 여기에 저장이 어떻게 되는가를 봐야한다고 생각했다! -
그럼 저장은..?
✔️ 브로커에서 Fetch 하면서 수행된다. -
그러므로 fetch 의 동작 과정을 보면 테스트 결과를 납득할 수 있을 것 같다
컨슈머 클라이언트에서 Fetch 요청을 전송하는 프로세스는 1) fetch request 구성 → 2) send << 이렇게 진행되고 있다.
-
Fetch Request 만들기
-
fetch request 는
Map타입인데,
분배받은 (assigned)TopicPartition하나가 -> 맵의 1개entry에 매핑되는 구조이다. -
fetch request 가 만들어지는 과정을 코드로 간단히 구성하면 이렇게 된다.
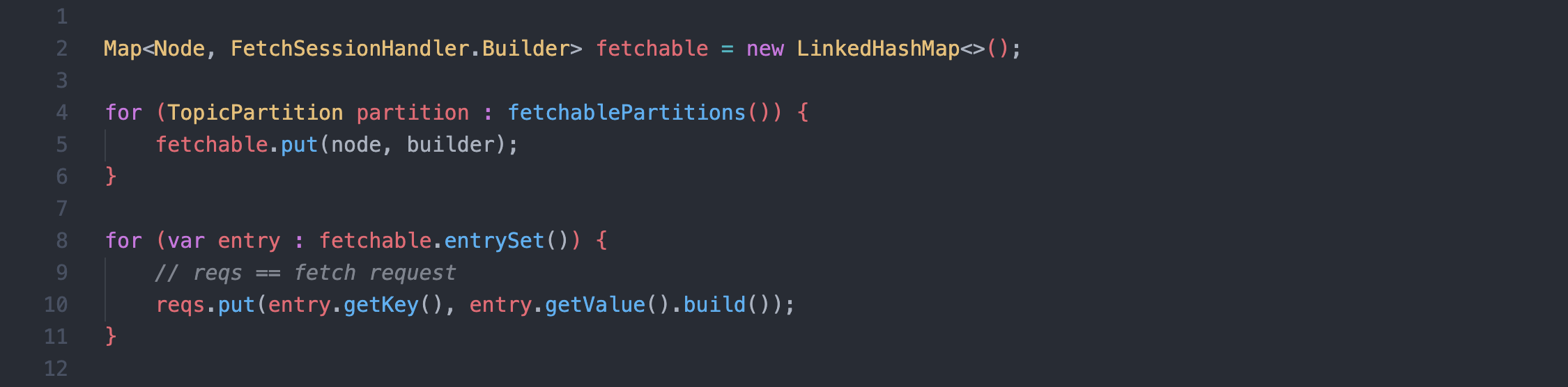
참고로, 여기서 호출하는fetchablePartitions()는SubscriptionState#assignment를 그냥 불러온건데,
이 변수는 리벨런싱 → 컨슈머 그룹 형성 → 파티션 분배 후 셋팅된다.그래서, fetch request 는 TopicPartition 별로 다른
request오브젝트가 만들어지는 것과 같다.1개의 맵으로 묶인걸
다른 request 오브젝트라고 표현한 이유는 2번 단계에서 설명된다.
-
-
요청 전송하기 :
client.send()
// fetchRequestMap = 위의 reqs 와 같은 값 = fetch request map
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
RequestFuture<ClientResponse> future = client.send(fetchTarget, request);
}-
Fetcher에서는 브로커에 요청을 전송하는 행위를 이렇게 루프를 돌면서 수행한다.-
1. Fetch Request 만들기에서 봤던 코드와 연관지어 생각한다면,
entry각각이 곧 1개TopicPartition에 매핑되고 있다. -
따라서
-
send로 쏘는 Fetch 요청 (브로커에서 직접 데이터를 꺼내오는 행위) 은 동시요청이 아니며 순차적으로 발생하고 있다. -
그리고 이렇게 전송한 요청에 대해서는
future event listener 를 걸어두어서 요청에 문제가 없었다면ConcurrentLinkedQueue<CompletedFetch> completedFetches에다가 뽑아온 레코드셋을 저장할 수 있도록 연계한다. -
이
listener를 걸어놓은것도 결국 위의 for 루프 내에서 하는 일이므로✔️ 결국 요청을 전송하는 단위, request map entry 하나 마다 리스너를 걸어놓은 셈이 된다.
✔️ 따라서TopicPartition하나에서 뽑아 온 데이터를 => 한번에 add 하는 과정이 될 것 같다.
-
-

10MiB -> 1MiB