트라이(Trie) 알고리즘
- 트라이는 문자열을 효율적으로 처리하기 위한 트리 자료구조로 아래는
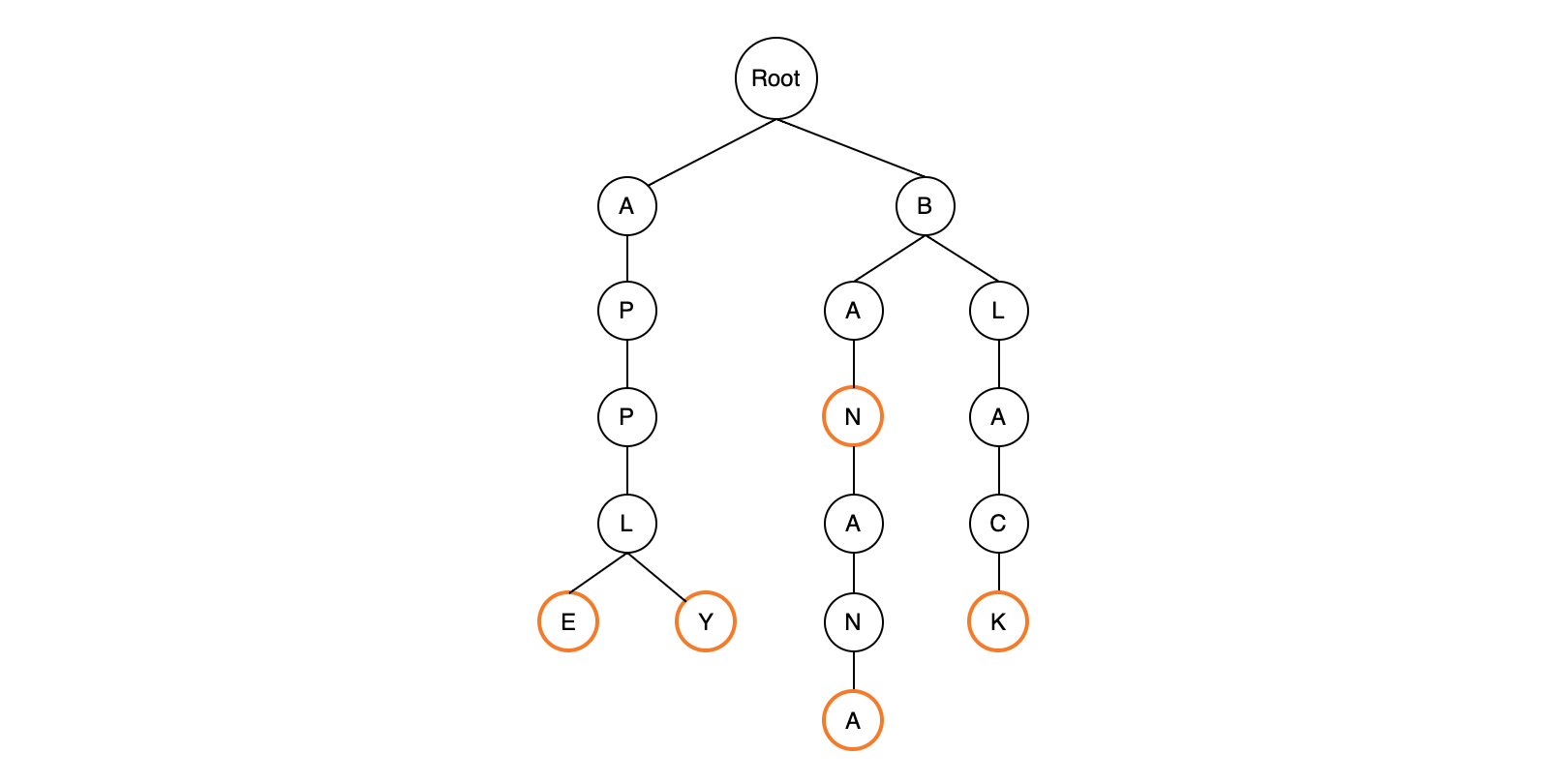
APPLE, APPLY, BAN, BANANA, BLACK문자열을 트라이로 저장했을 때의 자료구조
특징
- 기존에 단어가 얼마나 많이 저장되어 있는지 여부와 상관없이 무조건 삽입, 탐색, 삭제에
O(|S|)시간복잡도를 가진다.(|S| : 문자열 S의 길이) - 이진 검색 트리의 경우 삽입, 탐색, 삭제에
O(log N)번의 비교가 발생하기 때문에 최악의 경우O(|S| * log N)의 시간복잡도를 가질 수 있고 해시로 관리하더라도 해시 값을 계산할 때O(|S|)의 시간이 필요하며 실제로는 충돌에 따라 성능이 저하될 수도 있다. - 단점으로 메모리를 많이 차지한다. 단어를 평범하게 배열에 저장하는 것과 비교해서
4 * 글자의 종류배 만큼 더 사용한다. 예를 들어 각 단어가 알파벳 대문자로만 구성되어 있다면 글자의 종류가 26개이기 때문에 메모리를 104배 더 사용한다. - 이론과 다르게 실제 구현 시 트라이가 해시나 이진 검색 트리에 비해 훨씬 느리다. 따라서 일반적인 문자열의 삽입, 탐색, 삭제를 수행해야 하는 경우엔 트라이보다 해시나 이진 검색 트리를 사용하자.
기능
삽입

트라이에서 삽입 연산을 수행해보겠습니다. 먼저 루트만 있는 트리에서 시작합니다. 여기서 APPLE을 삽입하고 싶습니다. 참고로 트라이에서는 삽입, 탐색, 삭제의 모든 연산에서 정점을 옮겨다닙니다.
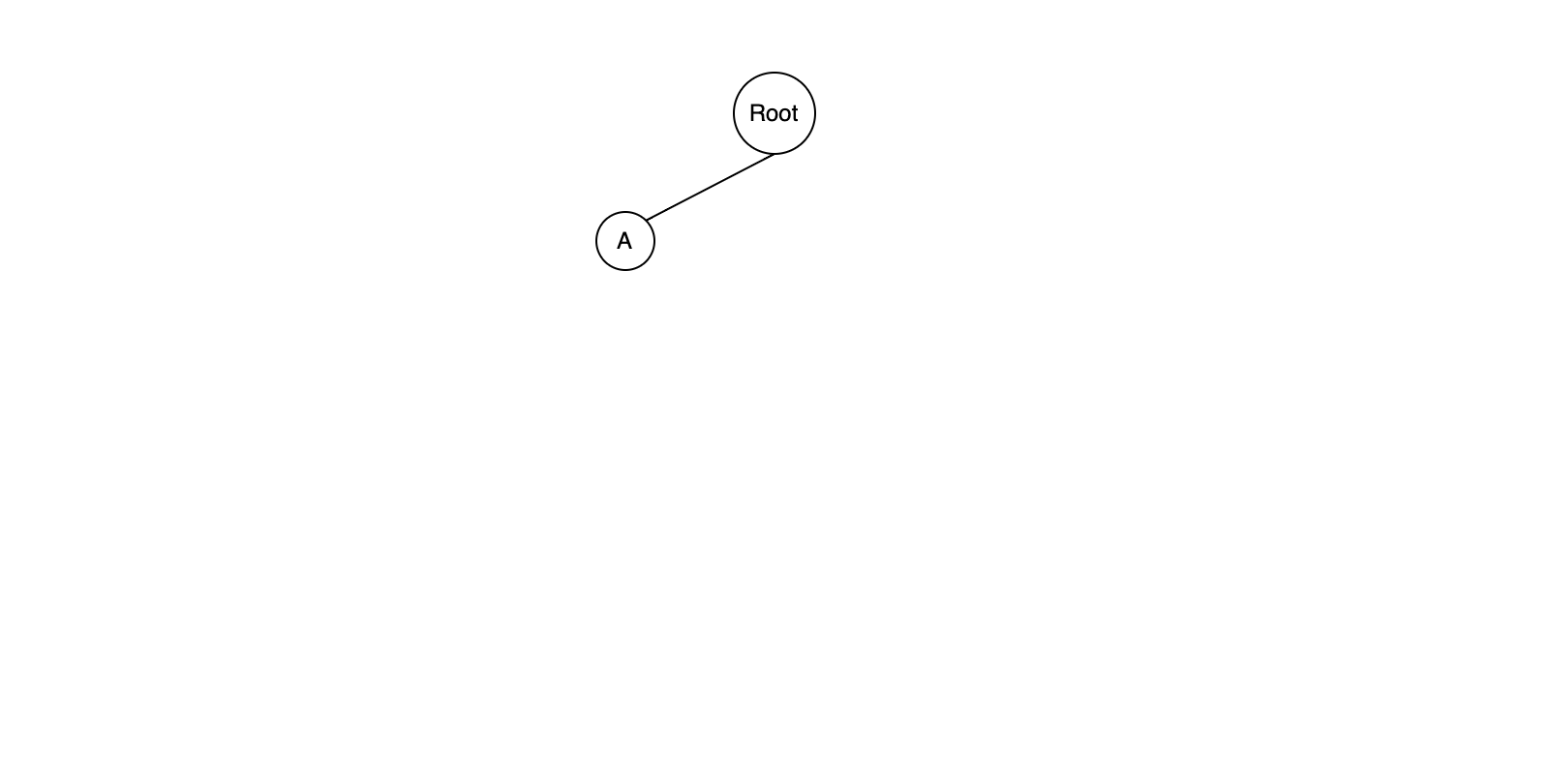
현재 보고 있는 정점인 Root에는 값이 A인 자식이 없습니다. 그렇기 때문에 A를 현재 보고 있는 정점의 자식에 추가하고 현재 보고 있는 정점을 Root에서 A로 옮깁니다. 이 과정을 반복하면서 PPLE 를 추가합니다.
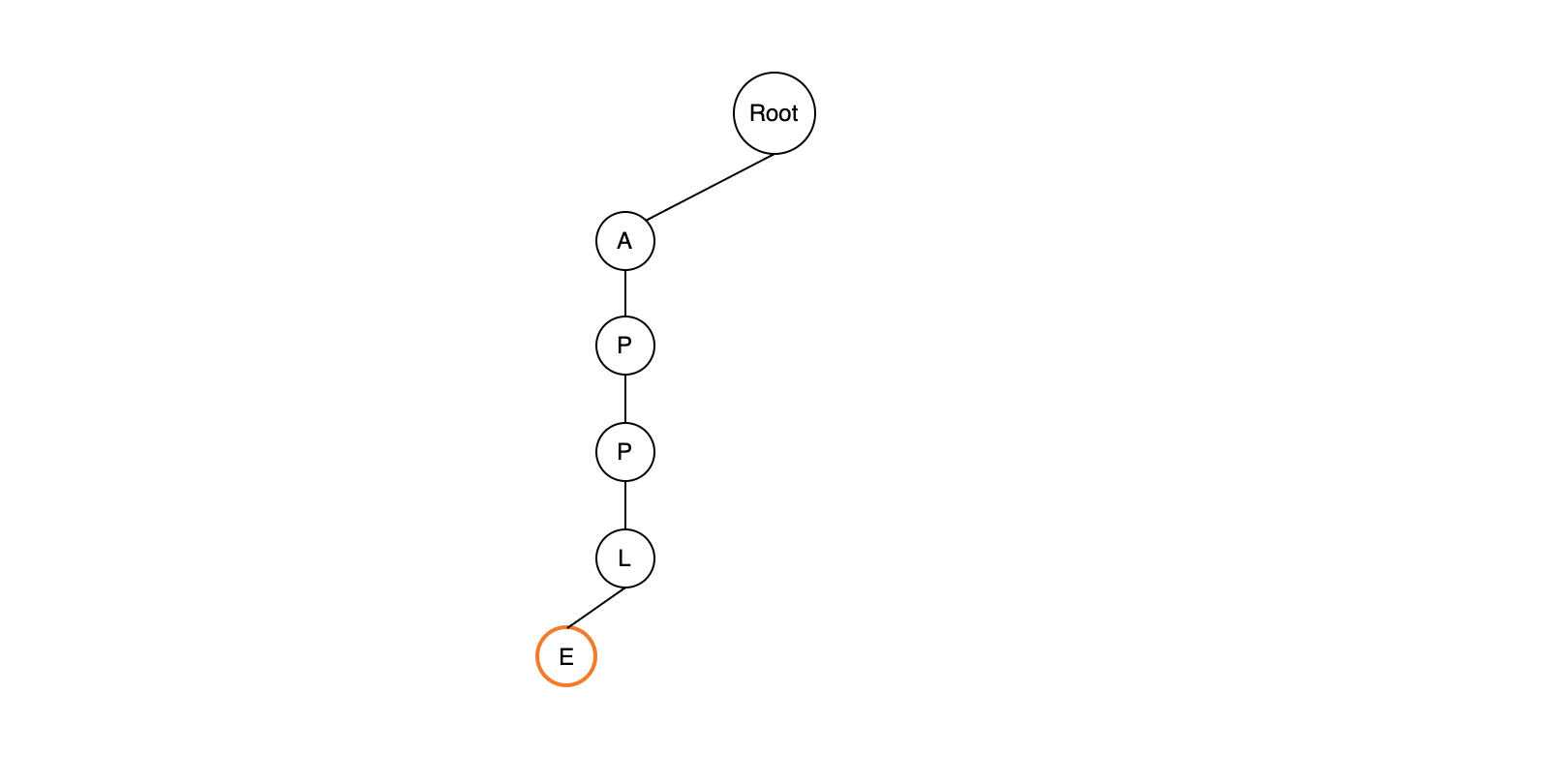
삽입이 끝난 후에는 마지막 글자에 별도의 표시를 해줍니다. 위와 같은 과정으로 APPLY 와 BANANA, BLACK, BAN 을 추가합니다.
위 그림에서 BAN을 삽입할 때 새로 추가되는 정점이 없고 기존에 있던 정점만을 그대로 타고 가게 됩니다. 트라이에서 단어를 삽입한 후에 마지막 글자에 별도의 표시를 해주는 이유를 여기서 알 수 있는데, 만약 별도의 표시가 없다면 단어 BAN과 BANANA가 모두 삽입된 상태와 BANANA만 삽입된 상태를 구분할 수 없습니다.
검색
검색은 삽입과 크게 다를게 없습니다. 검색하려는 단어가 APPLY라면 글자대로 정점을 타고 가다가 Y에 도달하면 Y에 단어가 있다는 표시를 확인합니다.
만약 APP이라는 단어를 검색한다면 정점을 그대로 타고 갈 수는 있지만 마지막 글자인 P에 별도의 표시가 없기 때문에 트라이에 해당 단어는 없습니다.
삭제
앞선 그림에서 BAN 을 삭제한다면 검색과 동일하게 해당 위치까지 일단 찾아갑니다. 그런 다음 N의 별도의 표시를 없애면 BAN이 삭제됩니다.
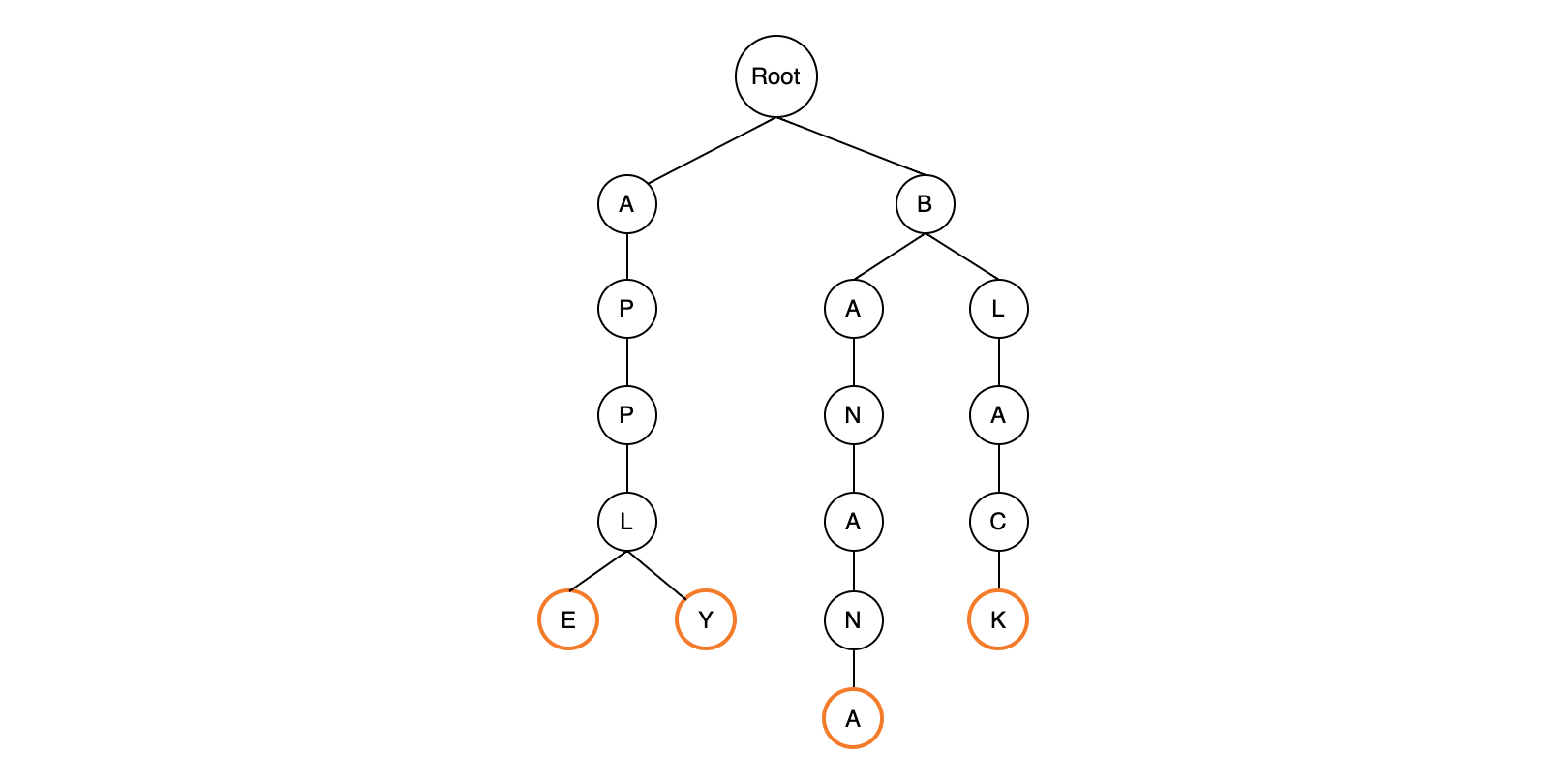
단, 트라이 구조를 망칠 수는 없기 때문에 정점 자체를 제거하면 안됩니다. 이로 인해 트라이는 삭제를 하더라도 이전에 삽입한 정점들은 계속 메모리에 남아 있게되어 메모리 측면에서 비효율적이고 삭제가 계속 발생하는 환경에서는 트라이가 적합하지 않습니다.
구현
LeetCode 의 208. Implement Trie 문제를 통해 트라이 알고리즘을 구현해봅니다. 문제 내용은 아래와 같습니다.
- 트라이의 insert, search, startsWith 메소드를 구현하라.
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // true
trie.search("app"); // false
trie.startWith("app"); // true
trie.insert("app");
trie.search("app"); // true
trie.search("appear"); // false위 문제를 풀기위해 먼저 트라이를 저장할 노드를 다음과 같이 별도의 클래스로 선언합니다. 트라이에 저장될 문자열은 알파벳 소문자로만 이루어져 있기 때문에 크기는 26으로 설정합니다.
class TrieNode {
boolean word;
TrieNode[] children;
TrieNode() {
children = new TrieNode[26];
word = false;
}
}이제 트라이 각각의 노드는 TrieNode라는 클래스가 되고, 자식 노드는 children이라는 멤버 변수에 묶이는 형태가 됩니다. 다음으로, 트라이 연산을 구현할 별도의 클래스를 선언하고 삽입 메소드부터 구현해봅니다.
class Trie {
TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
TrieNode cur = root;
for (char c : word.toCharArray()) {
if (cur.children[c - 'a'] == null) { // 자식 노드 중 해당 문자가 없는 경우
cur.children[c - 'a'] = new TrieNode();
}
cur = cur.children[c - 'a']; // 해당 문자의 노드로 정점 위치 변경
}
cur.word = true; // 마지막 문자 노드의 word 값 true 로 표시
}
}처음 Trie 클래스를 생성하면 로트 노드로 별도 선언한 TrieNode 클래스를 갖게 되고, 노드 추가 시 루트부터 자식 노드가 점점 깊어지면서 문자 단위의 앞서 살펴봤던 이미지와 같은 다진 트리 형태가 됩니다.
이제 search() 메소드와 startWith() 메소드를 구현해보겠습니다.
- search()
public boolean search(String word) {
TrieNode cur = root;
for (char c : word.toCharArray()) {
if (cur.children[c - 'a'] == null) { // 자식 노드 중 해당 문자가 없는 경우
return false;
}
cur = cur.children[c - 'a']; // 해당 문자의 노드로 정점 위치 변경
}
return cur.word;
}자식 노드 중 검색하려는 문자가 없다면 바로 false를 반환하고 검색하려는 단어의 마지막 문자까지 확인했다면 마지막 문자 노드의 word 값을 반환합니다.
- startWith()
public boolean startWith(String word) {
TrieNode cur = root;
for (char c : word.toCharArray()) {
if (cur.children[c - 'a'] == null) { // 자식 노드 중 해당 문자가 없는 경우
return false;
}
cur = cur.children[c - 'a']; // 해당 문자의 노드로 정점 위치 변경
}
return true;
}startWith() 메소드는 search() 메소드와 완전히 동일하고 마지막 문자 노드까지 확인됐다면 word 값을 확인하지 않고 바로 true 값을 반환하는 부분만 변경하면 됩니다.
