NTFS
NTFS(New Technology File System)는 Windows NT가 개발되면서 FAT의 구조상의 한계점을 개선하기 위해 개발되었다.
NTFS의 특징
NTFS는 처음 개발된 이후로 많은 기능들이 추가되었다. NTFS의 많은 기능들 중에 대표적인 기능만 살펴보자.
1. USN 저널 (Update Sequence Number Journal)
USN 저널은 NTFS의 메타데이터를 구성하는 파일로 $UsnJnrl 이라는 이름을 가진다. 이 파일은 파일시스템의 모든 파일 및 디렉터리의 변경 사항을 기록하는 로그이다.
USN 저널 파일은 최초에 빈 파일로 생성이 된다. 이후에 NTFS 볼륨에 변경이 생길때 마다 미리 정의된 레코드 형식으로 변경을 기록하여 저널 파일에 추가한다. 레코드에 기록되는 내용은 64 비트 USN(Update Sequence Number), 파일 이름, 변경에 관한 간략한 정보가 기록된다.
2. ADS (Alternate Data Stream)
ADS는 추가적으로 생성되는 데이터 스트림을 의미한다. 일반적으로 파일은 하나의 데이터 스트림만 가진다. 하지만 NTFS에서는 ADS라는 기능을 추가해 파일이 하나 이상의 데이터 스트림을 가지도록 지원한다.
추가적인 ADS 데이터 스트림들은 고유한 이름을 가진다. ADS는 기존 $DATA에 추가되기 때문에 고유한 이름을 통해 접근한다. 파일 이름은 "filename:streamname"과 같이 원본 파일 이름(filename)에 :(콜론)을 붙여 ADS(streamname)를 표현한다.
ADS 들의 크기는 파일 크기에 포함되지 않는다. 기존 파일이 1KB 였는데 이 파일에 1MB의 추가적인 데이터 스트림을 추가하더라도 파일 크기는 1KB이다. 뿐만아니라 탐색기를 통해 내용을 확인하는 것도 불가능하다.
3. Spare 특징
Sparse 특징은 파일의 데이터가 대부분 0으로 채워져 있는 경우, 실제 데이터를 기록하지 않고 크기만 유지하는 특징이다.
4. 파일 압축
NTFS에서는 파일시스템 수준의 압축을 지원한다. 파일 및 디렉터리 별로 압축하여 저장할 수 있는데 압축 방식은 LZ77의 변형된 방식을 사용한다.
5. VSS(Volume Shadow Copy System)
VSS는 새롭게 덮여 쓰여진 파일 및 디렉터리에 대해 백업본을 유지하는 기능이다. 이렇게 저장된 백업본은 비정상적인 종료시 부팅과정에서 시스템의 저널정보와 함께 안전한 복구를 할 수 있도록 도와준다.
6. EFS (Encrypting File System)
EFS는 NTFS 상에서 파일 및 디렉터리를 암호화 하는 기능으로 CryptoAPI와 EFS File System Run-Time Library(ESRTL)를 사용한 대칭키 방식으로 암호화 한다.
7. Quotas
Windows 서버형 제품군은 다중사용자를 위한 시스템이다. 다중 사용자를 지원할 경우 각 사용자의 디스크 사용량을 제한하기 위해 쿼터(Quotas) 기능을 사용한다.
8. 유니코드 지원
NTFS는 파일, 디렉터리, 볼륨 등의 이름을 지정할 때 모두 유니코드를 사용해 처리한다.
9. 동적 배드 클러스터 재할당
배드 섹터가 발생한 클러스터는 사용할 수 없다. 따라서 시스템 사용 중에 배드 섹터가 발생한 경우 자동으로 새로운 클러스터를 할당해 정상 데이터를 복사하는 기법이다. 이후 배드 섹터가 발생한 클러스터는 $BadClus 파일에 추가되어 더이상 사용되지 않도록 관리된다.
NTFS 구조
NTFS는 크게 VBR 영역, MFT 영역, 데이터 영역으로 나눌수 있다.

FAT 파일시스템에서 FAT 영역의 크기는 전체 볼륨의 클러스터 수에 따라 정해졌다. 따라서 파일시스템 생성시 전체 볼륨을 클러스터로 나눈 후, 클러스터의 갯수에 4 를 곱하면 FAT 영역의 크기가 나온다. 하지만 MFT 영역은 미리 계산되어 질 수 없다. MFT 에는 파일 및 디렉터리마다 하나 이상의 MFT Entry가 할당되는데 생성될 파일 및 디렉터리 수를 미리 예측할 수 없기 때문에다. 따라서 미리 할당된 MFT 영역을 모두 사용하여 MFT 영역이 더 필요하면 데이터 영역을 추가할당하여 사용한다.
구조로만 보면 FAT 파일시스템과 큰 차이가 없어 보인다. 하지만 NTFS는 앞서 언급한 다양한 특징들을 구현하기 위해 내부적으로 상당히 복잡한 구조를 가지고 있다.
NTFS - VBR
VBR(Volume Boot Record)는 NTFS 구조에서 가장 앞부분에 위치하는 영역이다. VBR은 FAT 예약된 영역과 유사하게 부트 섹터와 추가적인 부트 코드가 저장된다.

VBR의 크기는 고정된 크기를 가지지 않고 다음과 같이 클러스터 크기에 의존한다.
| Cluster Size(Byte) | VBR Size(Sector) |
|---|---|
| 512 | 1 |
| 1K | 2 |
| 2K | 4 |
| 4K | 8 |
부트 섹터 (Boot Sector)
VBR의 첫 번째 섹터는 부트 코드를 포함한 부트 섹터가 위치한다. FAT 파일시스템 예약된 영역의 부트 섹터와 그 내용이 같다고 이해하면 된다.
클러스터 크기가 512인 경우는 VBR 자체가 부트 섹터가 된다. VBR 크기가 1섹터를 넘는 경우, 나머지 섹터들은 추가적인 부트 코드를 저장하기 위한 용도로 사용되거나 NTLDR(NT Loader)을 빠르게 로드하기 위해 NTLDR의 위치를 저장하기 위한 용도로 사용된다.
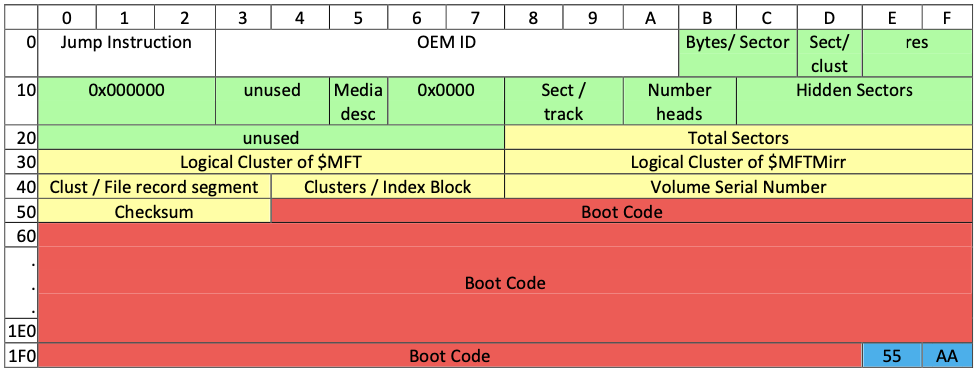
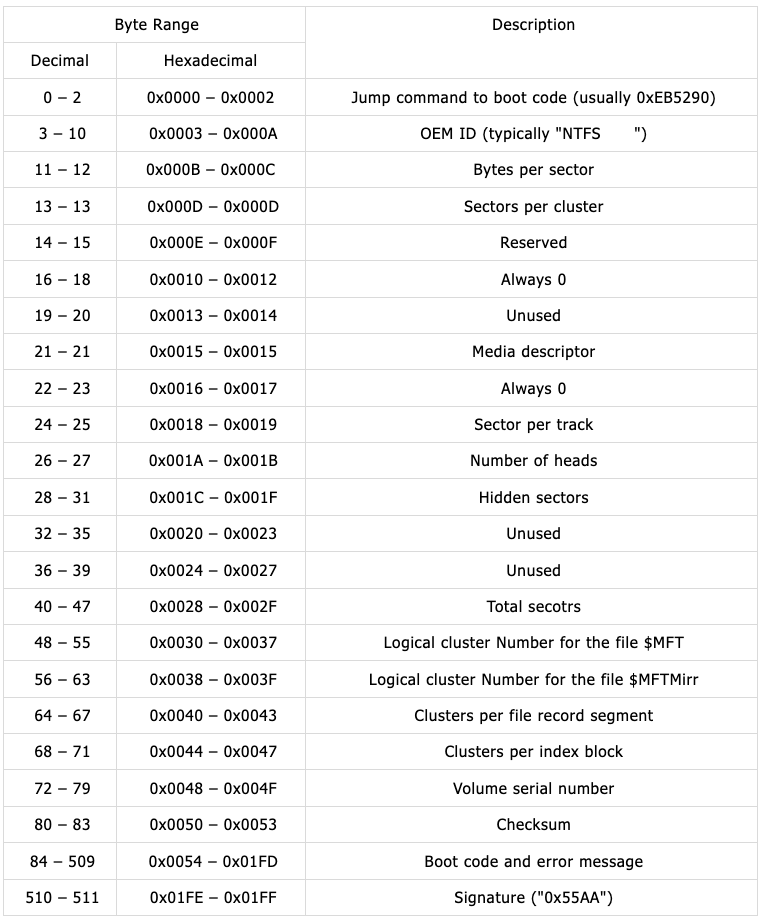
다음은 NTFS 부트 섹터를 덤프한 내용이다. 위의 데이터 구조와 함께 살펴보자.

MBR에서 부팅 가능한 파티션(볼륨)을 찾으면 해당 볼륨의 첫 섹터(부트섹터)를 메모리에 로드한 후 실행한다. 위 부트섹터 그림에서 첫 3바이트는 “EB 52 90″으로 되어 있는데 이 내용을 해석하면 다음과 같다.
EB 52 90 : JMP 52h + NOP (54h로 점프하여 BPB 이후의 부트 코드가 실행)
이후 BPB 항목을 참조하여 해당 볼륨의 운영체제를 로드하는 부트 코드가 실행된다.
NTFS - MFT

MFT(Master File Table)영역은 위 그림처럼 VBR영역 이후에 온다. 실제로는 그림과 다르게 VBR과 MFT 사이의 물리적인 공간이 존재한다. 또한 MFT의 위치는 고정적이지도 않다. 즉 VBR 이후의 모든 볼륨 영역 가운데 아무곳에나 존재 할 수 있다.
MFT의 위치는 VBR의 offset 48-55(logical cluster number for the file $MFT)를 통해 알 수 있다.
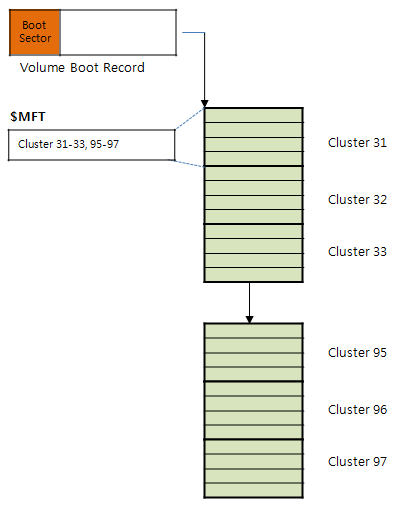
먼저 VBR의 부트 섹터에서 MFT 엔트리의 시작 위치를 얻어 이동한다. MFT영역은 MFT엔트리라는 1024 bytes로 이루어진 구조의 집합이다. MFT엔트리는 각 파일 및 디렉터리마다 하나씩 생성되어 해당 파일 및 디렉터리의 정보를 관리한다. 즉 실제 파일 및 디렉터리의 메타 정보 저장을 위해 사용된다.
MFT엔트리 0번은 $MFT파일이다. $MFT파일은 MFT 영역 자체의 정보를 담고 있다. MFT 영역 자체도 NTFS는 하나의 파일로 본다. 결국 $MFT는 전체 MFT 영역의 메타 정보를 유지하고 있는 엔트리이다.
$MFT 엔트리 정보를 읽어보면 전체 MFT가 할당하고 있는 클러스터 정보를 얻을 수 있다. 위에서는 간단한 예로 MFT가 6개의 클러스터만 할당하고 있을때는 나타낸 것이다. 위 처럼 MFT 영역은 서로 조각나 있을 수 있고 이러한 조각난 정보는 $MFT 엔트리를 통해 확인할 수 있다.
결과적으로 NTFS에 접근할 때 부트 섹터의 정보를 이용해 $MFT 엔트리 정보를 획득하면 전체 MFT 영역의 레이아웃을 알 수 있다. 전체 MFT 영역을 획득한다면 NTFS 내에 존재하는 모든 파일 및 디렉터리의 메타 정보(파일 이름, 시간 정보, 크기 등) 를 얻을 수 있을 것이다.
MFT Entry
MFT 영역은 MFT 엔트리(Entry)들의 집합이다. MFT 엔트리는 문서에 따라 MFT Record 또는 File Record 라고 부르기도 한다. MFT 엔트리는 1024 바이트의 크기로 각 파일 및 디렉터리의 위치, 시간 정보, 파일이름, 크기 등의 속성 정보를 담고 있다.
NTFS 내에 존재하는 모든 파일 및 디렉터리는 하나 이상의 MFT 엔트리가 할당된다. 이는 FAT 파일시스템의 FAT 영역과 유사할 수 있으나 FAT 영역은 전체 물리적인 볼륨을 클러스터 단위로 나누고 각 클러스터당 4바이트를 할당해 FAT 영역이 만들어 진다. 하지만 MFT 영역의 엔트리는 생성되는 파일마다 생성된다.
따라서 FAT 영역은 볼륨의 크기가 변하지 않는 이상, 항상 고정된 크기를 가지기 때문에 포맷시 일정한 영역을 할당할 수 있다. 하지만 MFT는 생성될 파일 수를 미리 예측할 수 없기 때문에 미리 고정된 크기를 생성할 수 없다. 그래서 일정 크기를 할당한 후 파일의 수가 늘어나 할당된 MFT 영역을 초과할 경우 데이터 영역의 일정부분을 MFT 영역으로 추가할당하여 사용한다.
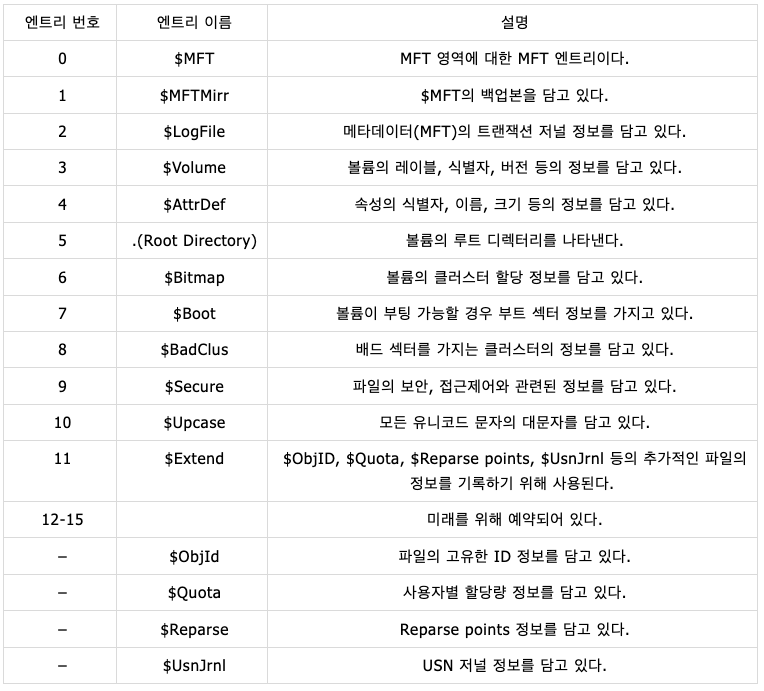
MFT 영역의 16개 엔트리는 파일시스템 자체의 메타 역할 및 추가적인 특성을 지원하기 위해 파일시스템 포맷시 미리 할당된다. 다음은 NTFS 포맷시 생성되는 예약된 MFT 엔트리이다.
MFT Entry 구조
MFT 엔트리는 다음 그림과 같은 구조를 가진다. 맨 앞부분에 48bytes 크기의 엔트리 헤더가 오고, 이어서 Fixup 값이 온다. 그리고 해당하는 파일의 특성에 따라 여러 개의 속성들이 따라온다.
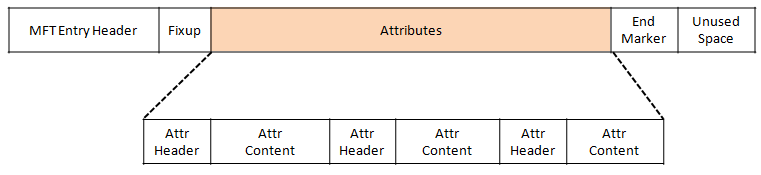
파일은 일반 파일, 심볼릭 파일, 보안 속성이 저장된 파일, 비트맵 파일 등에 따라 해당 MFT 엔드리에 존재하는 속성들이 다르다.
속성의 마지막에는 속성의 끝을 나타내는 End Marker가 온다. 이후의 값들은 MFT엔트리에서 사용되지 않는 값이다.
MFT 엔트리 헤더
MFT 엔트리 헤더는 모든 MFT 엔트리의 앞 부분에 위치하는 48 바이트 정보이다. 다음 MFT 엔트리 헤더의 데이터 구조이다.
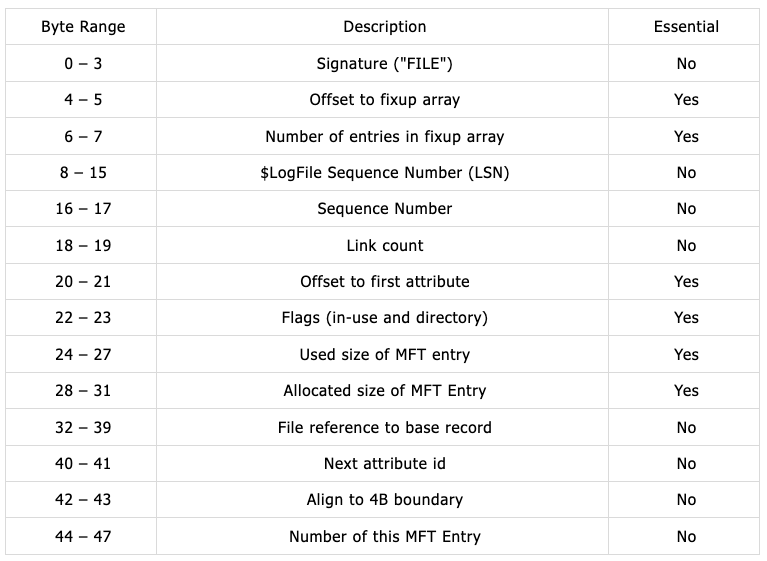
위의 데이터 구조와 같이 MFT 엔트리는 모두 "FILE"이라는 시그니처를 가진다. 중요한 값들의 내용을 살펴보면 다음과 같다.
- Offset to fixup array : fixup배열의 시작 위치
- Sequence Number : 해당 MFT 엔트리가 할당, 해제 될 때마다 1씩 증가하는 값
- Offset to first attribute : 첫 번째 속성의 위치
- Flags : MFT 엔트리의 속성
- Used size of MFT Entry : 실제 사용되는 크기
- Allocated size of MFT Entry : MFT 엔트리의 크기(1024 bytes)
- File reference to base record : base record의 MFT 엔트리 주소 값
다음은 $MFT 파일의 MFT 엔트리 내용이다. 여기서 기억해야 할 것은 NTFS를 접하면서 다들 많이 헷갈리는 부분이다. $MFT는 MFT 엔트리를 모아둔 파일이라고 했다. 그런데 $MFT 역시 하나의 파일이므로 해당 파일에 대한 정보를 가지는 MFT 엔트리도 존재할 것이다. 여기서 말하는 MFT 엔트리는 $MFT 파일의 내용 중 하나가 아닌 $MFT 파일 자체의 MFT 엔트리이다.

$MFT 파일의 MFT 엔트리를 위의 데이터 구조와 비교해보면 다음과 같다.
- Signature : "FILE"
- Offset to fixup array : 0x0030
- Number of entries in fixup array : 0x0003
- $LogFile Sequence Number (LSN) : 0x00000006 3B16F7D5
- Sequence Number : 0x0001
- Link count : 0x0001
- Offset to first attribute : 0x0038
- Flags : 0x0001
- Used size of MFT entry : 0x000001A8
- Allocated size of MFT Entry : 0x00000400 (1024 바이트)
- File reference to base record : 0x00000000 00000000
- Next attribute id : 0x0006
- Align to 4B boundary : 0x0000
- Number of this MFT Entry : 0x00000000
Fixup Array Values
Fixup이라는 것에 대해 살펴보자. Fixup은 해석하면 "수리(하다), 고치다" 등의 의미를 가진다. NTFS에서 Fixup이라는 구조를 둔 이유는 신뢰성을 높이기 위한 방안이다. MFT 엔트리는 기본적으로 1,024(1K) 바이트이므로 2개의 섹터를 사용한다. 이처럼 NTFS를 구성하는 데이터가 하나 이상의 섹터를 사용할 경우 섹터의 마지막 2 바이트 값을 별도로 저장하고, 해당 위치에는 Fixup 값 2바이트가 들어간다. 이로 인해 혹시나 섹터의 내용이 비정상적으로 변경될 경우, 해당 데이터를 해석하기 전, 오류를 사전에 찾아낼 수 있다. 다음은 Fixup 값의 활용을 그림으로 나타낸 것이다.
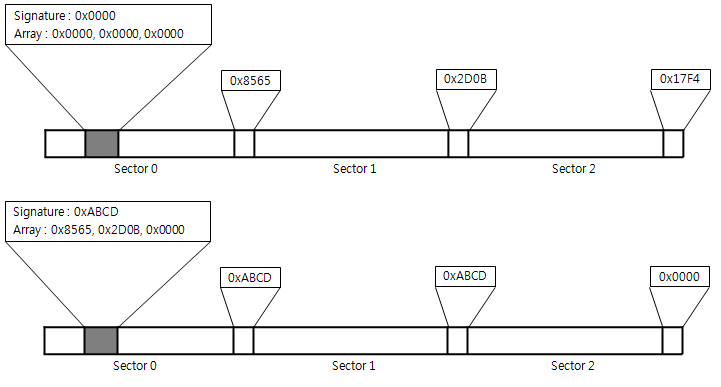
위의 그림은 Fixup이 사용되기 전의 모습이고, 밑에 모습은 Fixup이 적용된 모습이다.
MFT 엔트리 헤더에서 Fixup과 관련된 필드는 2개가 있다. 하나는 "Offset to fixup array"이고, 다른 하나는 "Number of entries in fixup array" 이다. 위의 $MFT 파일의 MFT 엔트리 헤더에서 이 값은 다음과 같다.
- Offset to fixup array : 0x0030
- Number of entries in fixup array : 0x0003
fixup 배열이 위치한 곳이 0x30(48) 이다. 데이터 구조는 2바이트를 사용하므로 Fixup 값을 살펴보면 "0xB76F" 값을 가진다. 즉, Fixup 값이 "B76F" 이다. 그리고 Number of entries in fixup array 값이 3이므로 Fixup 값 이후로 3*2바이트 (총 6바이트)가 Fixup 값에 의해 대체된 값을 저장하는 배열이 된다. 이 값은 기본 값이 3 이다. 3 이라는 의미는 전체 MFT 엔트리는 2개의 섹터를 사용하므로, MFT 엔트리 내에 존재하는 섹터의 마지막 2바이트와 추가적으로 하나를 더 준 셈이다.
하나의 파일이 MFT 엔트리를 2개 이상 쓴다면 물론 이 값도 거기에 맞게 증가할 것이다. 하지만, MFT 엔트리를 2개 이상 쓰는 파일은 매우 드믈다. 따라서, 기본적으로 3을 쓰는 것으로 판단된다. 1이 추가된 것은 그냥 여유롭게 하나 더 준게 아닐까? 그리고 3이 되어야만 위의 그림에서처럼 이어서 나오는 속성의 위치가 안정적으로 위치한다.
위의 Fixup 배열을 보면, 첫 번째 값이 "D585"이다. 즉, 해당 MFT 엔트리의 첫 섹터의 마지막 2바이트 실제 값이 "D585"이고, 거기에는 이 값 대신 "B76F"가 쓰여져 있을 것이다. 직접 확인해 보면 다음과 같이 "B76F"가 써 있는 것을 확인할 수 있다.

MFT Entry Flags
MFT 엔트리 헤더를 보면 엔트리의 속성을 나타내는 Flags 값이 존재한다. 엔트리 속성은 사용되고 있는 엔트리인지, 해당 MFT 엔트리가 디렉터리인지 나타낸다.
- In-use : 0x01
- Directory : 0x02
주의 해야 할점은 사용되는 디렉터리는 값이 0x03을 가진다는 점이다. 사용 중이면서 디렉터리이기 때문에 두 값을 더한 값이 오게 된다.
파일 참조 주소
NTFS에는 64비트로 이루어진 파일 참조 주소(File Reference Address)가 존재한다. 특정 MFT 엔트리를 찾고자 할 경우 MFT 엔트리의 주소만 있으면 되겠지만, NTFS는 파일 참조 주소를 사용해 해당 MFT 엔트리의 위치를 표현한다. 파일 참조 주소는 각 MFT 엔트리의 주소값과 MFT 엔트리의 순서 번호(Sequence Number)를 조합해서 만들어 진다. 우선 MFT 엔트리의 주소값을 살펴보자.
MFT 엔트리 주소값은 첫 번째 엔트리부터 마지막 엔트리 까지 순차적으로 매겨진 번호이다. 따라서, MFT 엔트리 0번인 $MFT의 주소값은 0이 된다. 마지막 MFT 엔트리 주소값은 $MFT 의 크기가 파일의 수에 따라 가변적이지만, MFT 엔트리 크기 (1,024 bytes)로 $MFT 파일 크기를 나누면 구할 수 있다. 그리고 MFT 엔트리 주소는 48비트로 표현된다.
파일 참조 주소는 48비트 MFT 엔트리 주소값 앞의 16바이트로 해당 MFT 엔트리의 순서 번호를 사용한다. 순서 번호는 위에서 살펴본 바와 같이, 해당 엔트리가 할당 또는 해제될 때마다 1씩 증가하는 값이다. 아래 그림에서 살펴보는 바와 같이 파일 참조 주소를 구성하는 64비트 중 앞의 16비트는 각 MFT 엔트리의 순서 번호를 사용하고, 나머지 48비트는 MFT 엔트리의 주소값을 사용한다.
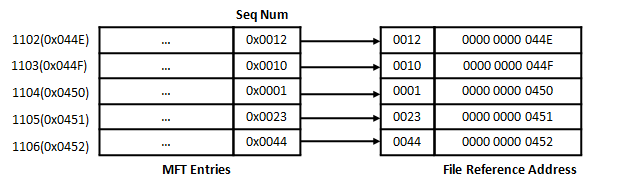
MFT 엔트리 주소만으로도 충분히 원하는 엔트리에 접근이 가능한데 왜 궂이 앞에 16바이트를 순서 번호로 사용했을까? 그 이유는 주소값만으로 해당 엔트리가 찾고자 하는 엔트리인지는 보장할 수 없기 때문이다. 순서 번호는 해당 엔트리의 고유한 값이므로, 만약 파일 참조 주소를 통해 찾은 엔트리의 순서 번호가 틀리다면, 파일시스템이 손상되었다고 판단할 수 있다. 따라서, 이 경우에는 적절한 오류를 발생시키거나 해당 파일을 참조할 수 없도록 해야 할 것이다.
그리고 할당, 해제될 때마다 1씩 증가한다는 것을 이용하면 한 가지 중요한 것을 생각해 낼 수도 있다. MFT 엔트리가 할당 되었다는 것은 특정 파일이 생성되고, 해당 MFT 엔트리를 사용한다는 것이고, 해제 되었다는 의미는 그 파일이 삭제되었다는 것을 의미한다. 그렇다면 순서 번호가 0보자 큰 짝수인 MFT 엔트리는 현재 사용되는 엔트리가 아닌 삭제된 파일로 간주 할 수 있을 것이다.
NTFS - MFT 속성
MFT 엔트리는 NTFS의 각 파일마다 하나씩 존재한다고 했다. 각 파일의 메타 정보 (특성, 위치, 크기, 시간정보 등)은 MFT 엔트리 내에 다양한 속성으로 표현된다. 다음은 MFT 엔트리의 구조이다.

속성은 MFT 엔트리 헤더, Fixup 배열 이후에 마지막 표시자(End Marker)가 올 때까지 연속적으로 온다. 각 속성은 크게 속성 헤더와 속성 내용으로 나누어진다.
속성 종류(Attribute Types)
NTFS는 기본적으로 17개의 속성을 가지고 있다. 다음은 17개의 속성들을 나열한 것이다.
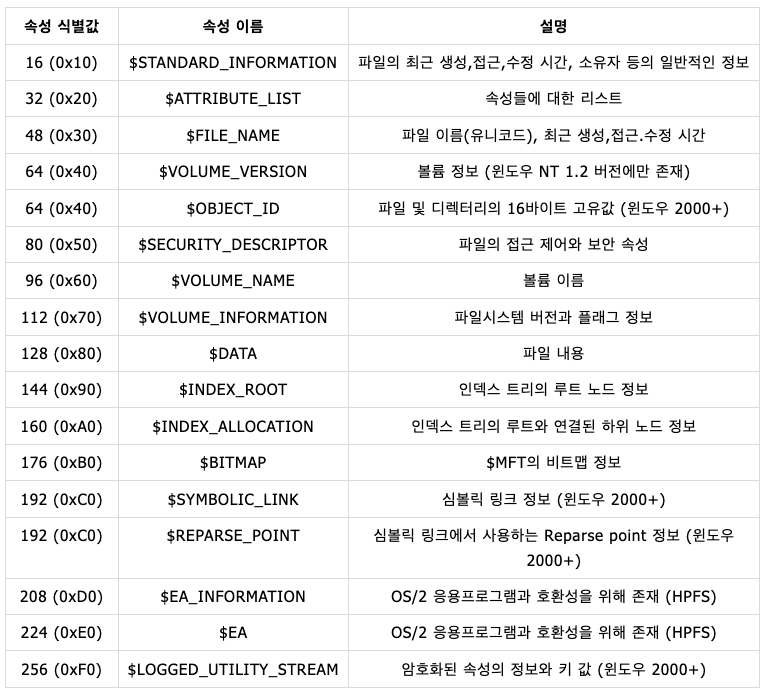
위의 속성들은 각 파일의 특성에 따라 MFT 엔트리 헤더, Fixup 배열 이후에 연속적으로 온다. 일반적인 파일의 경우에는 위의 많은 속성 중 아래 그림과 같이 $STANDARD_INFORMATION, $FILE_NAME, $DATA 속성만 온다.

따라서, 3가지 속성에 대해서만 잘 알고 있어도 대부분의 파일을 분석할 수 있다.
Resident 속성과 Non-resident 속성
속성들은 크게 Resident 속성과 Non-resident 속성으로 나뉜다.
Resident 속성은 속성의 내용이 속성 헤더 바로 뒤에 위치하는 속성이다. 이에 반해, Non-resident 속성은 속성 내용이 너무 커서 MFT 엔트리 (1,024 바이트) 내부에 넣지 못할 경우, 별도의 클러스터를 할당 받아 저장하는 방식이다. 이때, 속성 내용 위치에는 할당 받은 클러스터의 위치 정보가 저장되어 있다.
대부분의 속성은 모두 Resident 속성이고, $DATA, $ATTRIBUTE_LIST와 같은 속성은 Non-resident가 될 수 있다. $DATA는 파일의 내용을 표현하는 속성인데, 파일의 내용이 MFT 엔트리 내에 저장되지 못한다면 Non-resident 속성이 된다. 최근 대부분의 파일 크기가 크므로, 작은 파일(일반적으로 680 바이트 이하)이 아니라면 $DATA 속성은 대부분 Non-resident 로 존재한다.
그리고 $ATTRIBUTE_LIST 속성은 속성 들의 내용이 많아서 하나의 MFT 엔트리에 담지 못하는 경우, 여러 개의 엔트리를 사용하게 되는데 이때 흔어진 각 속성들의 정보를 저장하는 속성이다. 이 속성도 데이터의 내용이 커질 경우 Non-resident 가 될 수 있다. 다음은 Non-resident 속성의 모습을 보여준다.
클러스터 런(Cluster Runs)
속성이 Non-resident일 경우 별도의 클러스터를 할당 받아 내용을 저장한다고 했다. 할당 받는 클러스터가 내용의 크기에 따라 한, 두 개에서 수 천개가 될 수도 있다. 700메가의 동영상 파일이라고 하면, 4K의 클러스터를 사용할 경우 20만개의 클러스터가 사용된다. 이 클러스터들은 하드디스크의 여유 공간이 너무 많아 연속적으로 할당 될 수 있겠지만, 대부분은 비 연속적으로 할당 될 것이다.
이렇게 비 연속적으로 할당된 클러스터들은 효과적으로 관리하기 위한 것이 클러스터 런이다. 다음은 클러스터 런을 표현하는 런리스트(Runlist)의 예를 그림으로 나타낸 것이다.
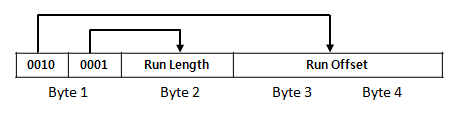
첫 바이트를 4비트 씩 나누어 각각 런 길이와 런 오프셋 값의 크기를 나타낸다. 다음 그림은 $MFT 파일의 MFT 엔트리에서 Non-resident 속성인 $DATA 속성의 런리스트를 보여준다. 런리스트 위쪽으로 $DATA 속성 식별자인 “0x00000080″을 확인할 수 있다. 그리고 빨간 박스로 표시한 부분이 $MFT의 내용을 담고 있는 클러스터의 런리스트이다.
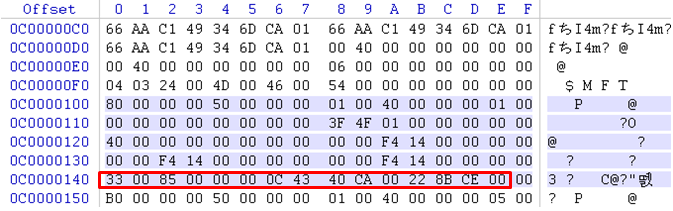
이 런리스트의 위의 구조대로 해석해보면 다음과 같다.
첫 번째 클러스터 런 : 33 00 85 00 00 00 0C
- 런 길이(3 bytes) : 0x008500
- 런 오프셋(3 bytes) : 0x0C0000
이것은 첫 번째로 클러스터들이 연결된 클러스터 런의 정보로, 총 34,048(0x008500)개의 클러스터가 오프셋 0x0C0000부터 $MFT를 위해 할당되어 있다는 의미이다.
두 번째 클러스터 런 : 43 40 CA 00 22 8B CE 00
- 런 길이(3 bytes) : 0x00CA40
- 런 오프셋(4 bytes) : 0x00CE8B22
두 번째 클러스터 런은 총 51,776(0x00CA40)개의 클러스터가 오프셋 0x00CE8B22 부터 $MFT를 위해 할당되어 있다는 의미이다. 런 오프셋은 파일시스템 맨 처음부터 순차적으로 부여한 클러스터의 위치이다. 다시 말해, 런 오프셋 0x10은 16번째 클러스터부터 데이터가 저장되어 있다는 의미이다.
속성 헤더
MFT 엔트리도 엔트리의 메타정보 표현을 위해 엔트리 헤더가 존재하는 것을 이미 살펴보았다. 이와 같이 각 속성에도 속성의 기본적인 메타정보를 표현하기 위해 속성 헤더를 사용한다.
속성 헤더 이후에는 앞서 살펴본 여러 가지 속성들($STANDARD_INFORMATION, $FILE_NAME, $DATA 등)이 따라온다.
공통된 헤더
앞서 속성은 크게 Resident와 Non-resident 형식으로 나눠진다고 언급했다. 속성 헤더 역시 각 속성 형식마다 다른 헤더를 가진다. 하지만 앞의 16바이트 영역은 두 형식 모두 동일하다. 다음은 16바이트의 공통된 헤더의 데이터 구조이다.
- 속성 타입 식별자 : 각 속성 타입에 대한 고유한 식별자로 이전 설명을 참조
- 속성 길이 : 속성 헤더를 포함한 속성의 전체 길이
- Non-resident 플래그 : “1” 값을 가진다면, 해당 속성은 Non-resident 속성
- 속성 이름 길이 : 자신의 속성 이름 길이
- 속성 이름 시작 위치 : 속성 이름이 저장된 곳의 시작 위치
- 상태 플래그 : 속성의 상태 표현
0x0001 : 압축 속성
0x4000 : 암호화된 속성
0x8000: Sparse 속성
속성 식별자는 속성의 고유한 식별자로 MFT 엔트리에 같은 속성이 여러 개일 때 서로 다른 값을 가진다. 16 바이트의 공통된 헤더 이후에는 Resident 인지 Non-resident 인지에 따라 나머지 속성 헤더의 내용이 달라진다. 결국, Resident 인지 Non-resident 인지에 따라 속성 헤더의 길이도 달라지게 된다.
Resident 속성 헤더
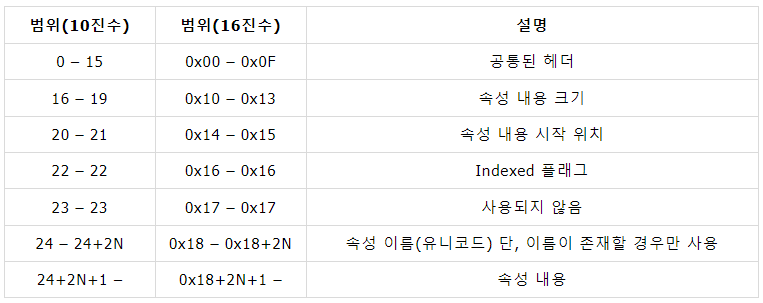
Resident 속성일 경우, 속성 헤더의 데이터 구조는 다음과 같다.
- 속성 내용 크기 : 헤더 뒤에 오는 속성 내용의 크기
- 속성 내용 시작 위치 : 속성 내용이 시작하는 시작 위치
- Indexed 플래그 : “1” 값을 가지면 Index 정보로 사용
(검색에 사용됨, 보통 $FILE_NAME 속성은 “1”로 설정)- 속성 이름 : 속성 이름이 있을 경우에만 존재
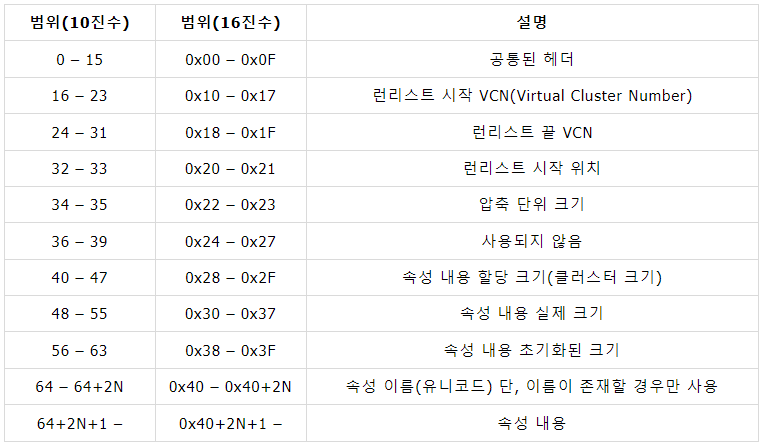
Non-Resident 속성 헤더
Non-Resident 속성일 경우, 속성 헤더의 데이터 구조는 다음과 같다.
Non-resident는 속성 내용이 외부 클러스터에 저장되어 있으므로 해당 클러스터 정보를 담고 있는 런리스트 정보가 필요하다.
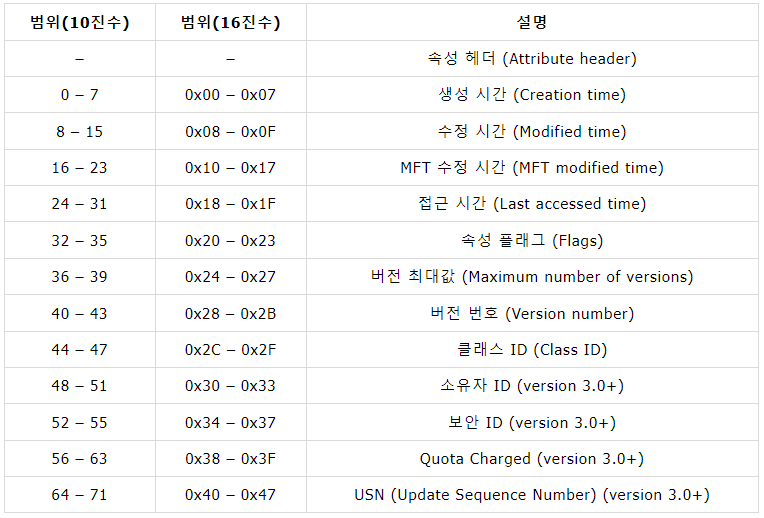
$STANDARD_INFORMATION 속성
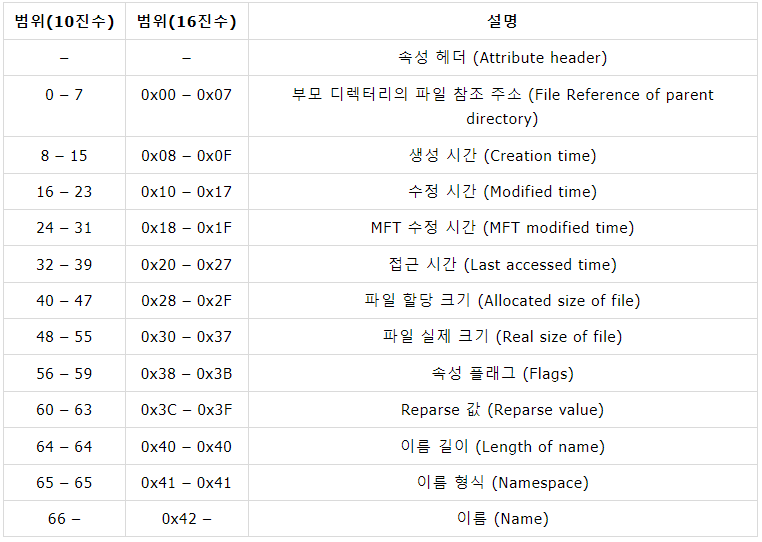
$STANDARD_INFORMATION 속성은 NTFS의 모든 파일에 기본적으로 존재하는 속성이다. 기본 속성인 만큼 파일의 시간정보, 파일특성, 소유자 및 보안 ID 등의 기본적인 속성 정보를 가지고 있다. 속성 타입 번호는 16번이다. 속성들 중 타입번호가 가장 낮기 때문에 MFT 엔트리 내의 속성들 중 가장 처음에 위치한다.
우선 기본적인 데이터 구조에 대해 살펴보자. 각 속성은 앞서 언급한대로 속성 헤더 이후에 나온다.

우선, 4개의 시간 정보는 모두 8바이트로 구성되어 있다. 즉, 시간 정보 표현을 위해 64비트를 사용한다. 64비트의 사용으로 인해 100 나노초(100 * 10^(-9))까지 표현이 가능하며, 1601년 1월 1일 00:00:00 UTC를 기준으로 한다.
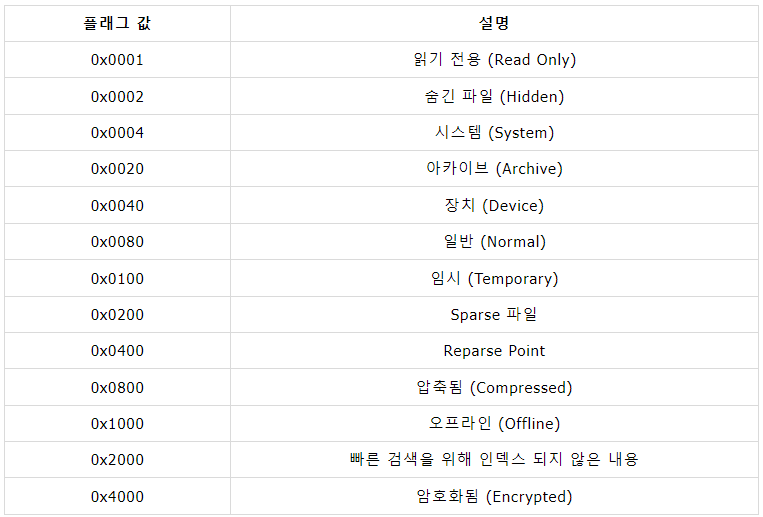
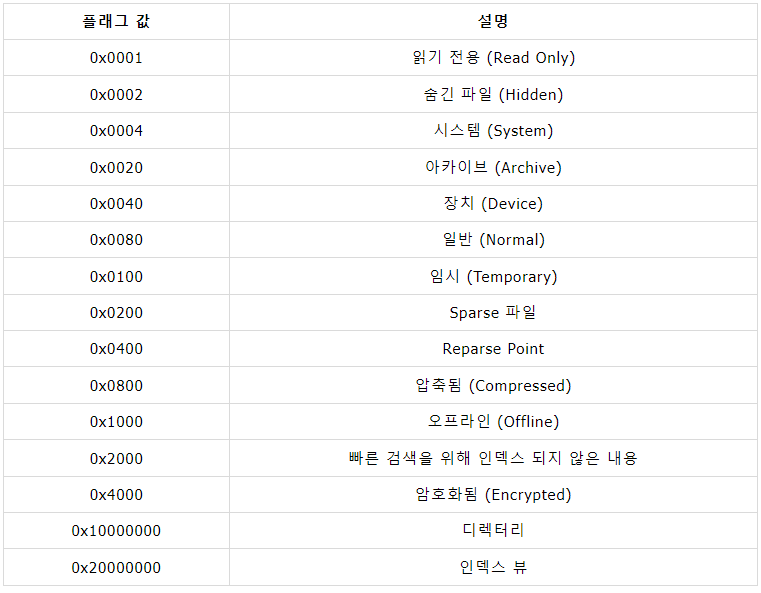
다음은 파일의 속성을 표현하는 속성 플래그 값에 대한 정보이다.
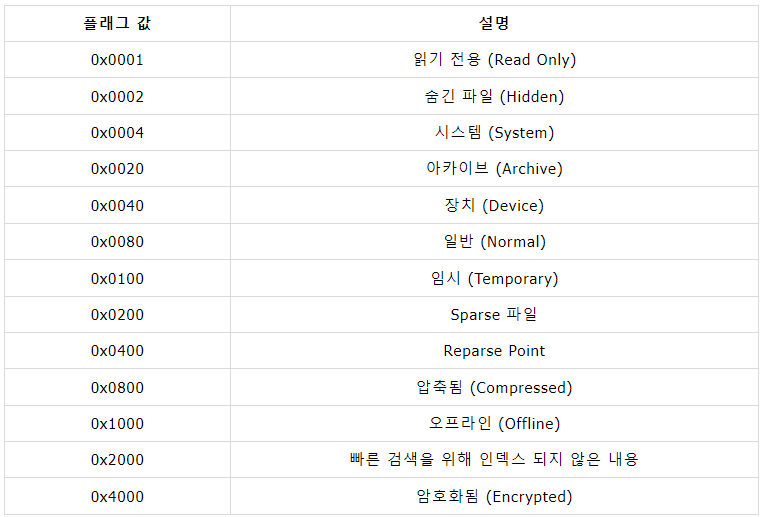
$STANDARD_INFORMATION 속성의 다양한 항목 중 보통 0으로 세팅되는 경우는 비활성화되어 있음을 의미한다.
제 $STANDARD_INFORMATION 속성 내용을 살펴보자. 다음은 임의의 파일의 MFT 엔트리 내용 중 해당 속성 부분만 덤프한 것이다.
하이라이트된 부분이 $STANDARD_INFORMATION 속성 부분이다. 속성 타입 번호로 0x00000010(16) 값을 가진다. 첫 16바이트가 속성 헤더이다. 해당 속성의 속성 타입(0x08 위치의 값)을 살펴보면 Resident 속성임을 알 수 있다. 따라서 속성 헤더는 24바이트(공통된 헤더 + Resident 헤더)를 사용한다. 그럼 8바이트로 이루어진 4개의 값이 연속으로 오는 것을 알 수 있다. 이 부분이 앞서 말한 4개의 시간 정보에 해당한다. 시간 정보를 확인하는 또다른 방법은 8바이트 시간 정보의 MSB 값은 항상 0x01 값을 가진다.
위의 덤프 내용을 속성 내용에 대응시켜보면 다음과 같다.
생성 시간 : 0x01CA043F7DCB4936
수정 시간 : 0x01CA043F7AA6B81A
MFT 수정 시간 : 0x01CA6D366440C1C8
접근 시간 : 0x01CA043F7AA6B81A
속성 플래그 : 0x00000020 (Archive)
버전 최대값 : 0x00000000 (사용하지 않음)
버전 번호 : 0x00000000 (사용하지 않음)
클래스 ID : 0x00000000 (사용하지 않음)
소유자 ID : 0x00000000 (사용하지 않음)
보안 ID : 0x00000279
Quota Charged : 0x00000000 (사용하지 않음)
USN : 0x00000000 008CAB38
$FILE_NAME 속성
$FILE_NAME(이하 $FNA)은 $STANDARD_INFORMATION(이하 $STDINFO) 와 함께 NTFS의 모든 파일에 기본적으로 존재하는 속성이다. 속성의 이름에서 알 수 있듯이 파일의 이름을 저장하기 위해 존재한다. 하지만 파일의 이름 외에도 다양한 부가 정보를 저장하고 있다.
파일이 생성될 경우 $FNA 속성은 해당 파일의 MFT 엔트리 뿐만아니라 인덱스 구조에도 생성이 된다. 일반적으로 파일 이름을 변경시키게 되면 두 속성이 모두 변경되지만 단순히 파일의 속성이 변경될 때에는 인덱스 구조의 $FNA만 변경된다. $FNA 속성은 항상 Resident 형태로 존재하고 크기는 이름의 크기가 가변적이기 때문에 최소 68바이트 이상을 가진다.
$FILE_NAME 속성의 데이터 구조
다음은 $FNA 속성의 데이터 구조이다.
속성 헤더 이후에 8바이트의 파일 참조 주소가 나온다. 그리고 이어서 8바이트의 Windows 64-bit 시간 형식으로 된 4개의 시간 정보가 나온다. 이 시간 정보는 $STDINFO 속성에도 존재한다. 인덱스 구조를 제외한다면 한 파일이 가지는 시간 정보는 기본적으로 8개가 된다.
그렇다면 $STDINFO 속성의 시간 정보와 $FNA 의 시간 정보는 어떻게 다른 것일까? 파일에 행하는 행위에 따라 조금 차이는 있지만 이해하기 쉽게 파일의 이름과 관련된 변경이 발생하면 $FNA의 시간 정보가 갱신되고 나머지는 $STDINFO의 시간 정보가 갱신된다고 생각하자. 자세한 내용은 추후에 살펴보겠다.
그리고 파일의 할당 크기와 실제 크기가 나온다. 할당 크기는 클러스터가 할당된 크기를 의미하고 실제 크기는 순수한 데이터의 크기를 의미한다.
이어서 속성 플래그 값이 나온다. 이 값은 $STDINFO의 속성 플래그와 거의 유사하다.
이어서 해당 속성이 Reparse point일 경우 어떤 형태인지를 나타내는 Reparse 값이 나온다. 그리고 이름의 길이와 형식, UTF-16으로 인코딩된 이름이 나온다.
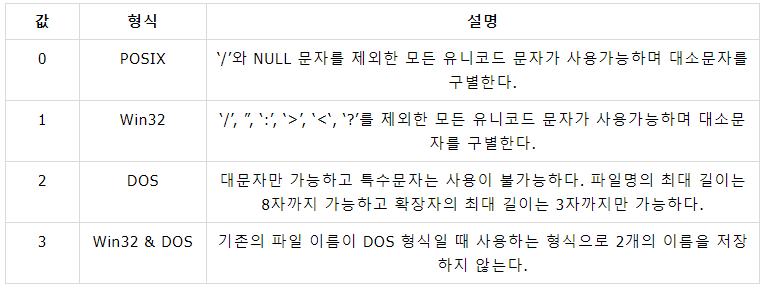
이름 형식(Namespace)은 저장된 이름이 어떤 형식인지를 나타낸다. 기본적으로 다음과 같은 4개의 형식을 가진다.

이름 형식 설명에서 살펴볼 수 있듯이 NTFS는 파일 이름을 저장할 때, DOS 형식에 맞지 않는다면 $FNA 속성을 2개 저장하여 파일 이름을 2개로 표현한다. 다시 말해, 원래 파일 이름을 저장하고 DOS 형식의 파일 이름을 추가로 더 저장한다.
$DATA 속성
$DATA 속성은 이름에서도 알 수 있듯이 파일의 데이터를 저장하는 속성이다. 일반적으로 파일 데이터가 약 700바이트 보다 크다면 Non-resident 속성으로 저장되므로 MFT 엔트리가 아닌 파일시스템 데이터 영역에 별도의 클러스터를 할당 받아 저장된다. 하지만, 700 바이트보다 적을 경우에는 Resident 속성이 되어 MFT 엔트리 내부에 데이터가 저장된다.
700 바이트라는 크기는 항상 고정된 크기는 아니다. MFT 엔트리의 크기는 1,024 바이트이다. 여기서 기본 속성을 가지는 파일일 경우, MFT 엔트리 헤더, $STDINFO, $FNA 속성을 제외하면 약 700바이트 정도가 남는다. 하지만 $STDINFO와 $FNA의 크기는 가변적이기 때문에 항상 700바이트라고 보기는 어렵다.
$DATA 속성의 데이터 구조
다음은 $DATA 속성의 데이터 구조이다. 속성 헤더 이후에 바로 데이터가 온다.

Resident 속성 예제
다음은 computer.lnk 파일의 MFT 엔트리 내용이다. 하이라이트 된 부분이 $DATA 속성이다. $DATA 속성 이전으로는 $STDINFO, $FNA, $OBJID 속성이 나온다.

우선 속성 헤더의 내용을 살펴봐야 한다. 속성 헤더는 Resident와 Non-resident 일 때 헤더 형식이 다르지만 16 바이트는 공통된 헤더 형식을 가진다.
공통된 헤더의 8번째 바이트가 세트(1) 되어 있다면 해당 속성은 Non-resident 속성이 된다. 하지만 위 속성은 세트가 되어 있지 않으므로 Resident 속성이다. 추가적으로 속성 내용 크기와 시작 위치가 나온 후 Resident 속성 내용이 나온다.
따라서, 속성 헤더 24바이트를 제외하면 실제 파일 데이터는 “4C 00 00 00” 부터 시작한다. 데이터의 시작 4바이트는 LNK 파일의 시그니처 값이다. 시그니처부터 $DATA 속성의 끝까지 덤프한 후 새로운 파일로 생성하면 정상적인 LNK 파일인 것을 확인할 수 있다. 해당 LNK 파일은 바탕화면의 “내컴퓨터” LNK 파일에 해당한다. 파일의 크기는 262 (0x106) 바이트이다. 이렇듯 파일의 데이터를 의미하는 $DATA 속성의 크기가 MFT 엔트리의 크기를 넘지 않을 경우 MFT 엔트리 내부에 데이터가 저장되는 Resident 속성 형태로 존재하게 된다.
Non-resident 속성 예제
다음은 No-resident 속성의 대표 예제인 $MFT의 MFT 엔트리이다. $MFT 데이터는 항상 Non-resident 속성으로 존재한다. 하이라이트 된 부분이 $DATA 속성이다.
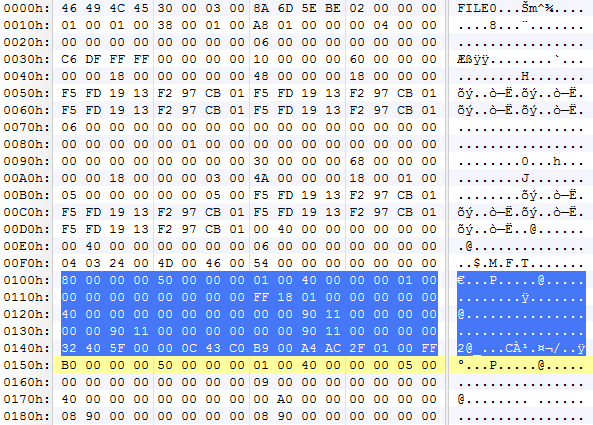
공통된 헤더(16 바이트)의 8번째 바이트가 세트(1) 되어 있으므로 해당 속성은 Non-resident 속성이다. Non-resident 속성일 경우에는 속성 내용이 저장되는 클러스터가 클러스터 런 구조로 표현된다.
NTFS에서는 파일이 가질 수 있는 $DATA 속성이 하나 이상이다. 즉, 하나의 파일에 여러 개의 $DATA 속성이 올 수 있다. 이렇게 추가적으로 오는 $DATA 속성을 NTFS에서는 ADS(Alternate Data Stream) 속성이라고 부른다.
